





nlp自然语言处理
Data is a chaos and perhaps in this chaos you would find the most wonderful patterns — venali sonone.
数据是一个混乱,也许在这种混乱中,您会发现最美妙的模式-venali sonone。

涵盖的主题: (Topics Covered:)
1. 什么是NLP? (1. What is NLP?)
- A changing field 不断变化的领域
- Resources 资源资源
- Tools 工具类
- Python libraries Python库
- Example applications 应用范例
- Ethics issues 道德问题
2. 使用NMF和SVD进行主题建模 (2. Topic Modeling with NMF and SVD)
part-1part-2 (click to follow the link to article)
- Stop words, stemming, & lemmatization 停用词,词干和词形化
- Term-document matrix 术语文档矩阵
- Topic Frequency-Inverse Document Frequency (TF-IDF) 主题频率-逆文档频率(TF-IDF)
- Singular Value Decomposition (SVD) 奇异值分解(SVD)
- Non-negative Matrix Factorization (NMF) 非负矩阵分解(NMF)
- Truncated SVD, Randomized SVD 截断SVD,随机SVD
3. 使用朴素贝叶斯,逻辑回归和ngram进行情感分类 (3. Sentiment classification with Naive Bayes, Logistic regression, and ngrams)
part -1(click to follow the link to article)
-1部分 (单击以跟随文章链接)
- Sparse matrix storage 稀疏矩阵存储
- Counters 专柜
- the fastai library 法斯特图书馆
- Naive Bayes 朴素贝叶斯
- Logistic regression 逻辑回归
- Ngrams 克
- Logistic regression with Naive Bayes features, with trigrams 具有朴素贝叶斯功能的逻辑回归,带有三字母组合
4.正则表达式(和重新访问令牌化) (4. Regex (and re-visiting tokenization))
5.语言建模和情感分类与深度学习 (5. Language modeling & sentiment classification with deep learning)
- Language model 语言模型
- Transfer learning 转移学习
- Sentiment classification 情感分类
6.使用RNN进行翻译 (6. Translation with RNNs)
- Review Embeddings 查看嵌入
- Bleu metric 蓝光指标
- Teacher Forcing 教师强迫
- Bidirectional 双向的
- Attention 注意
7.使用Transformer架构进行翻译 (7. Translation with the Transformer architecture)
- Transformer Model 变压器型号
- Multi-head attention 多头注意力
- Masking 掩蔽
- Label smoothing 标签平滑
8. NLP中的偏见与道德 (8. Bias & ethics in NLP)
- bias in word embeddings 词嵌入中的偏见
- types of bias 偏见类型
- attention economy 注意经济
- drowning in fraudulent/fake info 淹没在欺诈/虚假信息中
什么是NLP?
您可以使用NLP做什么? (What is NLP?
What can you do with NLP?)
NLP is a broad field, encompassing a variety of tasks, including:
NLP是一个广阔的领域,涵盖各种任务,包括:
- Part-of-speech tagging: identify if each word is a noun, verb, adjective, etc.) 词性标记:识别每个单词是否是名词,动词,形容词等)
- Named entity recognition NER): identify person names, organizations, locations, medical codes, time expressions, quantities, monetary values, etc) 命名实体识别(NER):识别人员姓名,组织,位置,医疗代码,时间表达,数量,货币价值等)
- Question answering 问题回答
- Speech recognition 语音识别
- Text-to-speech and Speech-to-text 文字转语音和语音转文字
- Topic modeling 主题建模
- Sentiment classification 情感分类
- Language modeling 语言建模
- Translation 翻译
Many techniques from NLP are useful in a variety of places, for instance, you may have text within your tabular data.
NLP的许多技术在很多地方都有用,例如,表格数据中可能包含文本。
There are also interesting techniques that let you go between text and images:
还有一些有趣的技术可以让您在文本和图像之间切换:

本博客系列 (This blog series)
In this series, we will cover these applications:
在本系列中,我们将介绍以下应用程序:
- Topic modeling 主题建模
- Sentiment classification 情感分类
- Language modeling 语言建模
- Translation 翻译
自上而下的教学方法 (Top-down teaching approach)
I’ll be using a top-down teaching method, which is different from how most CS/math courses operate. Typically, in a bottom-up approach, you first learn all the separate components you will be using, and then you gradually build them up into more complex structures. The problems with this are that students often lose motivation, don’t have a sense of the “big picture”, and don’t know what they’ll need.
我将使用自顶向下的教学方法,这与大多数CS /数学课程的操作方式不同。 通常,采用自下而上的方法,首先要学习将要使用的所有独立组件,然后逐步将它们构建为更复杂的结构。 问题在于,学生经常失去动力,对“全局”没有感觉,也不知道他们需要什么。
Harvard Professor David Perkins has a book, Making Learning Whole in which he uses baseball as an analogy. We don’t require kids to memorize all the rules of baseball and understand all the technical details before we let them play the game. Rather, they start playing with a just general sense of it, and then gradually learn more rules/details as time goes on.
哈佛大学教授戴维·珀金斯(David Perkins)有一本书,《 使学习变得完整 》,他以棒球为类比。 我们不要求孩子记住棒球的所有规则并了解所有技术细节,然后再让他们玩游戏。 相反,他们开始只是对游戏有一个大致的了解,然后随着时间的流逝逐渐学习更多的规则/细节。
All that to say, don’t worry if you don’t understand everything at first! You’re not supposed to. We will start using some “black boxes” that haven’t yet been explained, and then we’ll dig into the lower level details later. The goal is to get experience working with interesting applications, which will motivate you to learn more about the underlying structures as time goes on.
话虽如此,如果您一开始不了解所有内容,请不要担心! 你不应该这样 我们将开始使用一些尚未解释的“黑匣子”,然后稍后将深入研究底层细节。 目的是获得使用有趣的应用程序的经验,随着时间的流逝,这将激发您学习更多有关底层结构的知识。
To start, focus on what things DO, not what they ARE.
首先,专注于做什么,而不是做什么。
Build better voice apps. Get more articles & interviews from voice technology experts at voicetechpodcast.com
构建更好的语音应用。 在voicetechpodcast.com上获得语音技术专家的更多文章和访谈
不断变化的领域 (A changing field)
Historically, NLP originally relied on hard-coded rules about a language. In the 1990s, there was a change towards using statistical & machine learning approaches, but the complexity of natural language meant that simple statistical approaches were often not state-of-the-art. We are now currently in the midst of a major change in the move towards neural networks. Because deep learning allows for much greater complexity, it is now achieving state-of-the-art for many things.
从历史上看,NLP最初依赖于有关语言的硬编码规则。 在1990年代,使用统计和机器学习方法发生了变化,但是自然语言的复杂性意味着简单的统计方法通常不是最新技术。 目前,我们正在朝着神经网络迈进的重大变革中。 因为深度学习允许更大的复杂性,所以它现在在许多方面都达到了最先进的水平。
This doesn’t have to be binary: there is room to combine deep learning with rules-based approaches.
这不必是二进制的:可以将深度学习与基于规则的方法结合起来。
案例研究:拼写检查器 (Case study: spell checkers)
This example comes from Peter Norvig:Historically, spell checkers required thousands of lines of hard-coded rules:
此示例来自Peter Norvig:从历史上看,拼写检查器需要数千行硬编码规则:
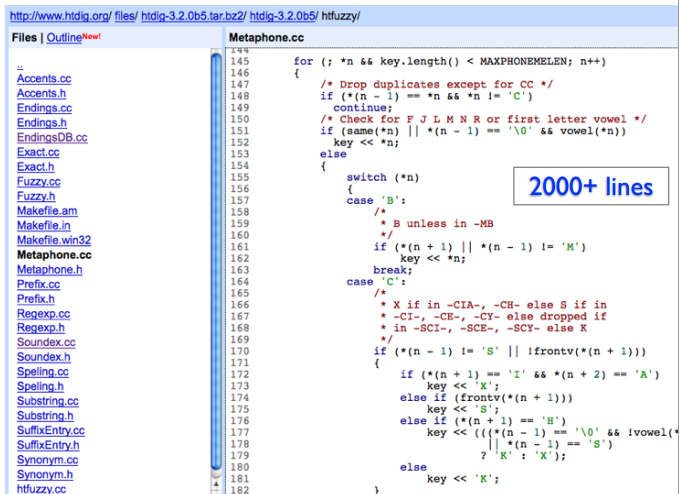
A version that uses historical data and probabilities can be written in far fewer lines:
使用历史数据和概率的版本可以用更少的行来编写:

通量场 (A field in flux)
The field is still very much in a state of flux, with best practices changing.
随着最佳实践的改变,该领域仍然处于不断变化的状态。

诺维格vs.乔姆斯基 (Norvig vs. Chomsky)
This “debate” captures the tension between two approaches:
这个“辩论”抓住了两种方法之间的张力:
- modeling the underlying mechanism of a phenomena 建模现象的潜在机制
- using machine learning to predict outputs (without necessarily understanding the mechanisms that create them) 使用机器学习来预测输出(不必了解创建它们的机制)
This tension is still very much present in NLP (and in many fields in which machine learning is being adopted, as well as in approachs to “artificial intelligence” in general).
在NLP中(以及在许多采用机器学习的领域,以及通常在“人工智能”的方法中),这种张力仍然非常明显。
Background: Noam Chomsky is an MIT emeritus professor, the father of modern linguistics, one of the founders of cognitive science, has written >100 books. Peter Norvig is Director of Research at Google.
背景:诺姆·乔姆斯基(Noam Chomsky)是麻省理工学院(MIT)的名誉教授,现代语言学之父,认知科学的奠基人之一,他撰写了超过100本书。 Peter Norvig是Google研究总监。
From MIT Tech Review coverage of a panel at MIT in 2011:
摘自《 麻省理工科技评论》 2011年麻省理工学院一个小组的报道 :
“Chomsky derided researchers in machine learning who use purely statistical methods to produce behavior that mimics something in the world, but who don’t try to understand the meaning of that behavior. Chomsky compared such researchers to scientists who might study the dance made by a bee returning to the hive, and who could produce a statistically based simulation of such a dance without attempting to understand why the bee behaved that way. “That’s a notion of scientific success that’s very novel. I don’t know of anything like it in the history of science,” said Chomsky.”
“乔姆斯基嘲笑机器学习的研究人员,他们使用纯粹的统计方法来产生模仿世界上某些事物的行为,但是却不试图理解这种行为的含义。 乔姆斯基将这类研究人员与科学家进行了比较,他们可能研究蜜蜂返回蜂巢后产生的舞蹈,并且可以在不试图理解蜜蜂为何如此行为的情况下,对此类舞蹈进行基于统计的模拟。 “这是科学成功的观念,这是非常新颖的。 我在科学史上一无所知,”乔姆斯基说。“
From Norvig’s response On Chomsky and the Two Cultures of Statistical Learning:
从Norvig对Chomsky和统计学习的两种文化的回应:
“Breiman is inviting us to give up on the idea that we can uniquely model the true underlying form of nature’s function from inputs to outputs. Instead he asks us to be satisfied with a function that accounts for the observed data well, and generalizes to new, previously unseen data well, but may be expressed in a complex mathematical form that may bear no relation to the “true” function’s form (if such a true function even exists). Chomsky takes the opposite approach: he prefers to keep a simple, elegant model, and give up on the idea that the model will represent the data well.”
“布雷曼邀请我们放弃这样的想法,即我们可以对从输入到输出的自然功能的真正基础形式进行唯一建模。 相反,他要求我们对能很好地说明观察到的数据的函数感到满意,并能很好地推广到以前从未见过的新数据,但是可以用复杂的数学形式表示,而该数学形式可能与“真实”函数的形式无关(甚至存在这样的真实功能)。 Chomsky采取相反的方法:他更喜欢保留一个简单,优雅的模型,而放弃了该模型将很好地表示数据的想法。”
Yann LeCun对阵Chris Manning (Yann LeCun vs. Chris Manning)
Another interesting discussion along the topic of how much linguistic structure to incorporate into NLP models is between Yann LeCun and Chris Manning:
关于将多少语言结构合并到NLP模型中的话题,另一个有趣的讨论是Yann LeCun和Chris Manning之间:
Deep Learning, Structure and Innate Priors: A Discussion between Yann LeCun and Christopher Manning:
深度学习,结构和先天先验:Yann LeCun和Christopher Manning之间的讨论 :
On one side, Manning is a prominent advocate for incorporating more linguistic structure into deep learning systems. On the other, LeCun is a leading proponent for the ability of simple but powerful neural architectures to perform sophisticated tasks without extensive task-specific feature engineering. For this reason, anticipation for disagreement between the two was high, with one Twitter commentator describing the event as “the AI equivalent of Batman vs Superman”.
一方面,曼宁(Manning)是将更多语言结构纳入深度学习系统的杰出倡导者。 另一方面,LeCun是简单但功能强大的神经体系结构执行复杂任务而无需进行大量特定于任务的特征工程的能力的领先支持者。 因此,人们对两者之间存在分歧的期望很高,一位Twitter评论员将该事件描述为“相当于蝙蝠侠对超人的AI”。
…
…
Manning described structure as a “necessary good” (9:14), arguing that we should have a positive attitude towards structure as a good design decision. In particular, structure allows us to design systems that can learn more from less data, and at a higher level of abstraction, compared to those without structure.
曼宁(Manning)将结构描述为“必需品”(9:14),认为我们应该对结构作为一种好的设计决策持积极态度。 尤其是,与没有结构的系统相比,结构允许我们设计一种系统,可以从更少的数据中学习更多信息,并具有更高的抽象水平。
Conversely, LeCun described structure as a “necessary evil” (2:44), and warned that imposing structure requires us to make certain assumptions, which are invariably wrong for at least some portion of the data, and may become obsolete within the near future. As an example, he hypothesized that ConvNets may be obsolete in 10 years (29:57).
相反,LeCun将结构描述为“必不可少的恶魔”(2:44),并警告说强加于结构要求我们做出某些假设,这对于至少部分数据而言总是错误的,并且可能在不久的将来变得过时。 。 例如,他假设ConvNets可能在10年后就过时(29:57)。
资源资源 (Resources)
Books
图书
We won’t be using a text book, although here are a few helpful references:
尽管这里有一些有用的参考文献,但我们不会使用教科书:
Speech and Language Processing, by Dan Jurafsky and James H. Martin (free PDF)
言语与语言处理 ,作者Dan Jurafsky和James H. Martin(免费PDF)
Introduction to Information Retrieval by By Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze (free online)
Christopher D. Manning,Prabhakar Raghavan和HinrichSchütze撰写的信息检索简介 (免费在线)
Natural Language Processing with PyTorch by Brian McMahan and Delip Rao (need to purchase or have O’Reilly Safari account)
Brian McMahan和Delip Rao 使用PyTorch进行自然语言处理 (需要购买或拥有O'Reilly Safari帐户)
Blogs
网志
Good NLP-related blogs:
良好的NLP相关博客:
NLP工具 (NLP Tools)
- Regex (example: find all phone numbers: 123–456–7890, (123) 456–7890, etc.) 正则表达式(例如:查找所有电话号码:123–456–7890,(123)456–7890等)
- Tokenization: splitting your text into meaningful units (has a different meaning in security) 令牌化:将您的文本分成有意义的单位(在安全性上有不同的含义)
- Word embeddings 词嵌入
- Linear algebra/matrix decomposition 线性代数/矩阵分解
- Neural nets 神经网络
- Hidden Markov Models 隐马尔可夫模型
- Parse trees 解析树
Example from http://damir.cavar.me/charty/python/: “She killed the man with the tie.”
来自http://damir.cavar.me/charty/python/的示例:“她用领带杀死了那个男人。”
Was the man wearing the tie?
那个人系着领带吗?

Or was the tie the murder weapon?
还是领带是谋杀武器?

Python库 (Python Libraries)
nltk: first released in 2001, very broad NLP library
nltk :2001年首次发布,非常广泛的NLP库
spaCy: creates parse trees, excellent tokenizer, opinionated
spaCy :创建分析树,出色的标记器,自以为是
gensim: topic modeling and similarity detection
gensim :主题建模和相似度检测
specialized tools:
专用工具:
general ML/DL libraries with text features:
具有文本功能的常规ML / DL库:
sklearn: general purpose Python ML library
sklearn :通用Python ML库
fastai: fast & accurate neural nets using modern best practices, on top of PyTorch
fastai :在PyTorch之上,使用现代最佳实践实现快速,准确的神经网络
fast.ai学生的一些NLP应用程序 (A few NLP applications from fast.ai students)
Some things you can do with NLP:
您可以使用NLP执行以下操作:
How Quid uses deep learning with small data: Quid has a database of company descriptions, and needed to identify company descriptions that are low quality (too much generic marketing language)
Quid如何使用少量数据进行深度学习 :Quid拥有公司描述的数据库,需要识别质量低下的公司描述(太多的通用营销语言)

- Legal Text Classifier with Universal Language Model Fine-Tuning: A law student in Singapore classified legal documents by category (civil, criminal, contract, family, tort,…) 具有通用语言模型微调功能的法律文本分类器:新加坡的一名法律系学生按类别(民事,刑事,合同,家庭,侵权等)对法律文件进行分类


Democrats ‘went low’ on Twitter leading up to 2018: Journalism grad students analyzed twitter sentiment of politicians
截至2018年,民主党人在Twitter上``走得很低'' :新闻专业的研究生分析了政客的Twitter情绪

Introducing Metadata Enhanced ULMFiT, classifying quotes from articles. Uses metadata (such as publication, country, and source) together with the text of the quote to improve accuracy of the classifier.
引入元数据增强型ULMFiT ,对文章引用进行分类。 将元数据(例如出版物,国家/地区和来源)与报价文字一起使用,以提高分类器的准确性。

道德问题
偏压 (Ethics issues
Bias)

How Vector Space Mathematics Reveals the Hidden Sexism in Language
Semantics derived automatically from language corpora contain human-like biases
Word Embeddings, Bias in ML, Why You Don’t Like Math, & Why AI Needs You

面包店 (Fakery)

OpenAI’s New Multitalented AI writes, translates, and slanders
He Predicted The 2016 Fake News Crisis. Now He’s Worried About An Information Apocalypse. (interview with Avi Ovadya)
他预测了2016年的假新闻危机。 现在,他担心信息启示录。 (Avi Ovadya访谈)
- Generate an audio or video clip of a world leader declaring war. “It doesn’t have to be perfect — just good enough to make the enemy think something happened that it provokes a knee-jerk and reckless response of retaliation.” 生成世界领导人宣战的音频或视频剪辑。 “它不一定是完美的-足以使敌人认为发生了会激起报复行为的鲁kneeReact。”
- A combination of political botnets and astroturfing, where political movements are manipulated by fake grassroots campaigns to effectively compete with real humans for legislator and regulator attention because it will be too difficult to tell the difference. 政治僵尸网络和草拟运动的结合,在政治运动中通过假的基层运动来操纵政治运动,以有效地与真实的人竞争,以争取立法者和监管者的注意,因为很难分辨出两者之间的区别。
- Imagine if every bit of spam you receive looked identical to emails from real people you knew (with appropriate context, tone, etc). 想象一下,如果您收到的每封垃圾邮件看上去都与您认识的真实人的电子邮件相同(带有适当的上下文,语气等)。

How Will We Prevent AI-Based Forgery?: “We need to promulgate the norm that any item that isn’t signed is potentially forged.”
我们将如何防止基于AI的伪造? :“我们需要颁布规范,任何未签名的物品都可能被伪造。”
只为你的东西 (Something just for you)
翻译自: https://medium.com/voice-tech-podcast/fast-nlp101-2179178d725b
nlp自然语言处理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}