





机器学习遗传算法路径优化
In complex machine learning models, the performance usually depends on multiple input parameters. In order to get the optimal model, the parameters must be properly tuned. However, when there are multiple parameter variables, each ranging across a wide spectrum of values, there are too many possible configurations for each set of parameters to be tested. In these cases, optimization methods should be used to attain the optimal input parameters without spending vast amounts of time finding them.
在复杂的机器学习模型中,性能通常取决于多个输入参数。 为了获得最佳模型,必须正确调整参数。 但是,当有多个参数变量,每个参数变量的范围很广时,要测试的每组参数都有太多可能的配置。 在这些情况下,应使用优化方法来获得最佳输入参数,而无需花费大量时间来找到它们。
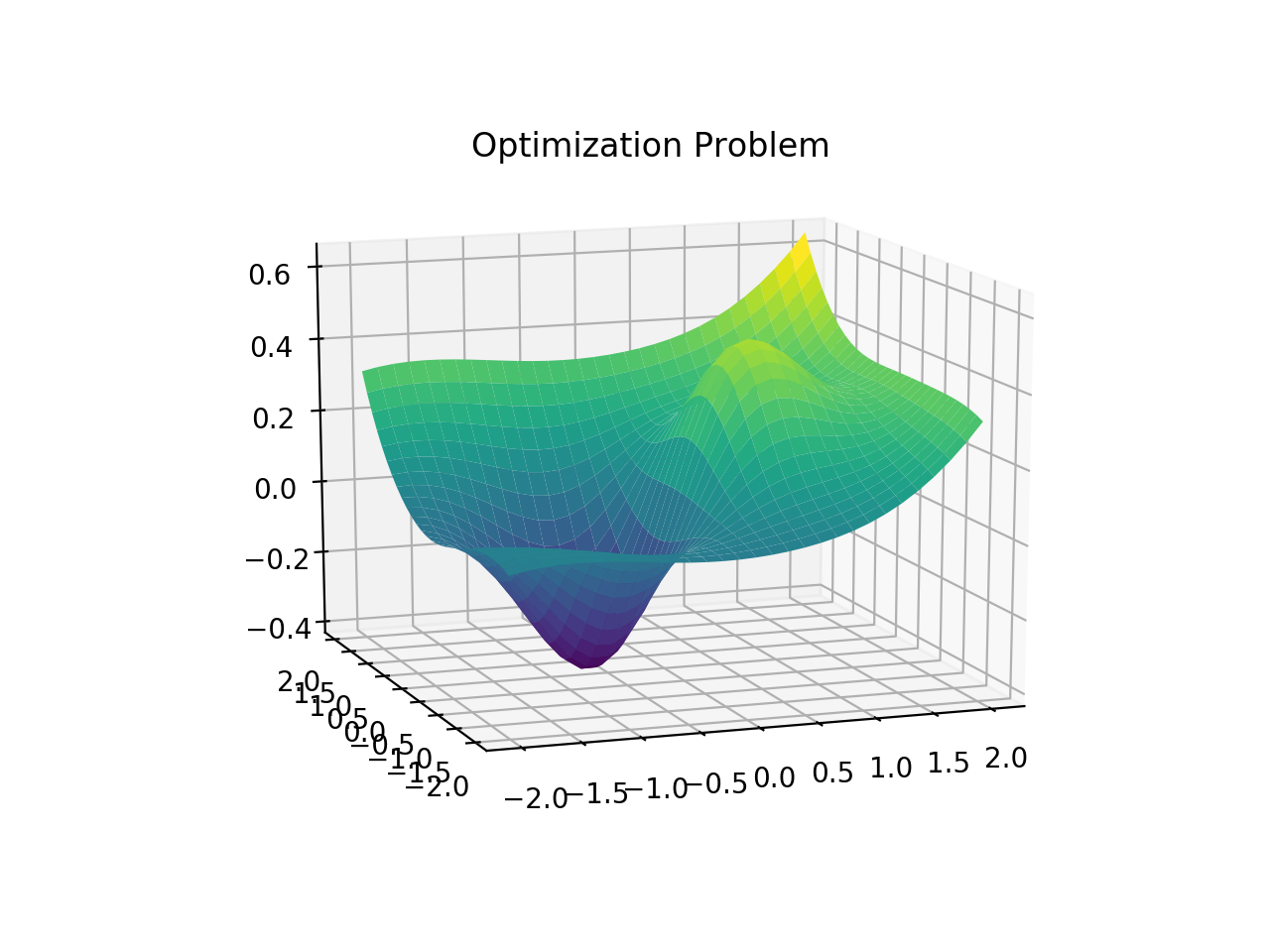
In the diagram above, it shows the distribution of the model based on only two parameters. As evident in the example shown, it is not always an easy task to find the maximum or minimum of the curve. This is why optimization methods and algorithms are crucial in the field of machine learning.
在上图中,它仅基于两个参数显示了模型的分布。 从所示示例中可以明显看出,找到曲线的最大值或最小值并不总是一件容易的事。 这就是为什么优化方法和算法在机器学习领域至关重要的原因。
遗传算法 (Genetic Algorithm)
The most commonly used optimization strategy are Genetic Algorithms. Genetic Algorithms are based off of Darwin’s theory of natural selection. It is relatively easy to implement and there is a lot of flexibility for the setup of the algorithm so that it can be applied to a wide range of problems.
最常用的优化策略是遗传算法。 遗传算法基于达尔文的自然选择理论。 它相对容易实现,并且算法的设置具有很大的灵活性,因此可以应用于各种各样的问题。
选择健身功能 (Choosing a Fitness Function)
To start off, there must be a fitness function that measures how well a set of input parameters perform. Solutions with a higher fitness derived from a fitness function will be better than ones with a lower fitness.
首先,必须有一个适应度函数,用于测量一组输入参数的执行情况。 由适应度函数得出的适应度较高的解决方案将比适应度较低的解决方案更好。
For example, if a solution has a cost of x + y + z, then the fitness function should try to minimize the cost. This can be done with the following fitness function:
例如,如果解决方案的成本为x + y + z,则适应度函数应尝试将成本降至最低。 可以使用以下适应度函数来完成此操作:
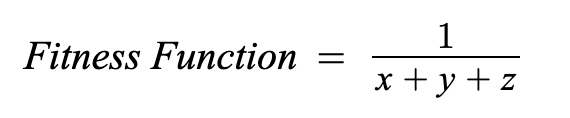
This fitness function will generate a fitness value for each set of input parameters and is used to evaluate how well each set of parameters perform.
该适应度函数将为每组输入参数生成适应度值,并用于评估每组参数的执行效果。
产生人口 (Generate a Population)
To run a genetic algorithm, first start off with a population of individuals where each individual is a solution. The solution is represented with a set of genes where each gene in the solution is a variable within the model. Each solution is randomly generated and evaluated against the fitness function to generate a fitness score. It is very important to choose an appropriate population size. If the population size is too low, then it is much harder to explore the entire state space of the problem. If the population is too large, then it will take a very long time to process each generation as system costs for calculating fitness and generating each population will take exponentially more time to process.
要运行遗传算法,首先要从一群人开始,每个人都是一个解决方案。 解决方案用一组基因表示,其中解决方案中的每个基因都是模型中的变量。 每个解决方案都是随机生成的,并根据适合度函数进行评估以生成适合度评分。 选择合适的人口规模非常重要。 如果人口数量太少,那么探索问题的整个状态空间就困难得多。 如果种群太大,那么处理每一代将花费很长时间,因为计算适应度和生成每个种群的系统成本将花费更多的时间进行处理。
家长选择 (Parent Selection)
Next, the population goes through a process called parent selection where the best solutions (most fit individuals) will be selected to create the next generation of solutions. There are many ways to do this, such as Fitness-Proportion Selection (FPS), Rank-Based Selection, and Tournament Selection. These methods all have their pros and cons and should be picked based on the model.
接下来,人口将经历一个称为“ 父母选择”的过程,其中将选择最佳解决方案(最适合的个体)以创建下一代解决方案。 有许多方法可以执行此操作,例如, 健身比例选择(FPS),基于排名的选择和锦标赛选择。 这些方法各有优缺点,应根据模型进行选择。
交叉 (Crossover)
Once the parents have been selected, the parents undergo a process called crossover. Crossover is when two parents crossover their genes in order to create a new solution (also known as a child). This promotes exploration in the state space of the problem and potentially generates new solutions that have never been tested before.
一旦选择了父母,父母将经历称为交叉的过程。 交叉是指两个父母交叉基因以创建新的解决方案(也称为孩子)。 这促进了对问题状态空间的探索 ,并有可能生成从未被测试过的新解决方案。
This is done differently based on the data types of the solutions. For solutions where the genes are represented in binary, there are methods such as 1-point crossover, n-point crossover, and uniform crossover.
根据解决方案的数据类型,此操作会有所不同。 对于以二进制表示基因的解决方案,可以使用1点交叉,n点交叉和均匀交叉等方法 。
For solutions where the genes are real-valued, there are methods such as single arithmetic crossover and whole arithmetic crossover.
对于基因是实数值的解决方案,有诸如单算术交叉和整个算术交叉的方法 。
Also, for permutation problems (such as the Traveling Salesman problem, etc) there are methods such as the Partially-Mapped Crossover (a.k.a. PMX), Edge crossover, Order 1 Crossover, and Cycle crossover.
同样,对于置换问题(例如Traveling Salesman问题等),有一些方法,例如部分映射的交叉(又名PMX),边交叉,阶1交叉和循环交叉 。
突变 (Mutation)
After the crossover phase, the children generated goes through a mutation phase. Mutation is when each gene could potentially change according to a random probability. This allows for exploitation as the children solution will not change as drastically as during the crossover phase but will still be able to explore around the neighbourhood of its current solution.
在交叉阶段之后,生成的子代将经历一个突变阶段。 突变是指每个基因有可能根据随机概率发生变化的时候。 这允许进行开发,因为子解决方案不会像跨阶段那样剧烈变化,但仍能够在其当前解决方案附近进行探索。
For binary solutions, the mutation process is relatively simple where each bit is toggled according to some mutation probability.
对于二元解,突变过程相对简单,其中根据某个突变概率切换每个位。
For real-valued solutions, the different genes can be chosen according to some acceptable range for that variable or by adding some noise that centers around 0 and varies according to some Gaussian distribution.
对于实值解决方案,可以根据该变量的某个可接受范围或通过添加一些以0为中心并根据某些高斯分布而变化的噪声来选择不同的基因。
Finally, for permutation problems, there are four main methods; insert mutation, swap mutation, inversion mutation, and scramble mutation.
最后,对于置换问题,有四种主要方法: 插入突变,交换突变,反转突变 和加扰突变 。
幸存者选择 (Survivor Selection)
Once the children population is created, the next stage is survivor selection. This is the stage that decides which individuals get to move on to the next generation. There are multiple ways to do this as the new generation can be selected from both the pool of parents and the pool of children. There are two main methods to select the survivors of each generation, Age-Based Selection and Fitness-Based Selection (FBS). In FBS, there is Elitism, where the most fit of every population is selected, and Genitor, where the worst fit of every population gets eliminated.
一旦建立了儿童群体,下一步就是幸存者的选择 。 这是决定哪些人继续前进到下一代的阶段。 有多种方法可以做到这一点,因为可以从父母和孩子中选择新一代。 选择每一代幸存者的主要方法有两种:基于年龄的选择和基于适合度的选择(FBS) 。 在FBS,有精英 ,其中选择每个人口中最适合,和生父 ,其中每一个人口最糟糕的配合被淘汰。
算法重复 (Algorithm Repetition)
Once the new generation is selected, this whole process repeats until the algorithm converges based off of some convergence criteria. After the whole algorithm runs, the best solution from all of the generations is returned.
一旦选择了新一代,整个过程将重复进行,直到算法基于某些收敛标准收敛为止。 整个算法运行后,将返回所有代的最佳解决方案。
实作 (Implementation)
from numpy import np
import random
class GeneticAlgorithm:
def __init__(self, createIndividual, mutateIndividual, fitnessFunction, crossoverFunction, population_size=1000, crossoverProb=0.6, mutateProb=0.4, alpha=0.5):
self.create = createIndividual
self.mutate = mutateIndividual
self.fitness = fitnessFunction
self.populationSize = population_size
self.crossoverProb = crossoverProb
self.mutateProb = mutateProb
self.crossoverAlpha = alpha
self.crossover = crossoverFunction
# create the population of solutions using the create function
self.population = [self.create() for i in range(population_size)]
def run(self, numGenerations):
bestSolution = []
for i in range(numGenerations):
# calculate the fitness of each individual in the population
fitness = self.population.map(lambda solution: (self.fitness(solution), solution))
# get the best 2 solutions
best = sorted(fitness, key=lambda x: x[0])[:2]
# put the best solution into the output
bestSolution.append(best[0])
# select the parents with Baker's Stochastic Universal Sampling Algorithm
totalFitness = sum(val for val, sol in fitness)
rouletteGap = totalFitness/(self.populationSize - 2)
randomOffset = random.uniform(0, 1) * rouletteGap
parents = []
for j in range(self.populationSize - 2):
rouletteValue = rouletteGap * j + randomOffset
currSum = 0
index = 0
while currSum < rouletteValue:
currSum += fitness[index]
index += 1
parents.append(self.population[index])
# perform crossover
children = []
for j in range(0, self.populationSize - 2, 2):
parents = self.population[j:j+2]
# if perform crossover, then get the new chromosomes using the alpha to mix parents
if random.uniform(0, 1) < self.crossoverProb:
childs = self.crossover(parents, self.crossoverAlpha)
# else append the parents as the next generation's children
else:
childs = parents[:]
children += childs
# perform mutation
for child in children:
# if perform mutation, mutate specific genes in the child
if random.uniform(0, 1) < self.mutateProb:
self.mutate(child)
# survivor selection using Elistism
self.population = children + best
return bestSolution结论 (Conclusion)
Genetic Algorithms are widely used due to its wide range of applicable problems. The simple version of a Genetic Algorithm is relatively easy to implement but there are more complex variations. For example, these Genetic Algorithms can be executed in parallel where the entire set of tunable parameters can be split across Parallel Genetic Algorithms. These parallel GAs can be then configured to be fine-grained or coarse-grained depending on the computational load of the problem. There can also be a Master-Slave approach to the algorithm where the slaves control the computation and the master controls the selection process. Additionally, the solutions can also be configured to incorporate different topologies and migration policies between different parallel genetic algorithms. All of these variations allow Genetic Algorithms to be widely flexible and is definitely an important algorithm to know.
遗传算法因其广泛的适用问题而被广泛使用。 遗传算法的简单版本相对容易实现,但存在更复杂的变化。 例如,这些遗传算法可以并行执行,其中整个可调参数集可以在并行遗传算法中拆分。 然后,根据问题的计算量,可以将这些并行GA配置为细粒度或粗粒度。 该算法也可以采用主从方法,其中从服务器控制计算,而主服务器控制选择过程。 此外,解决方案还可以配置为在不同的并行遗传算法之间合并不同的拓扑和迁移策略。 所有这些变化都使遗传算法具有广泛的灵活性,并且绝对是一个重要的算法。
机器学习遗传算法路径优化














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









