





 本文探讨了在数据科学中,由于计算机无法直接分析文本,需要将文字转换为数字的问题。介绍了编码器的作用,以及它们在解决机器学习问题中的应用。通过编码器,可以将字符串数据转化为适合分析的形式。
本文探讨了在数据科学中,由于计算机无法直接分析文本,需要将文字转换为数字的问题。介绍了编码器的作用,以及它们在解决机器学习问题中的应用。通过编码器,可以将字符串数据转化为适合分析的形式。
从头开始 (From Scratch)
In a perfect world, all programmers, scientists, data-engineers, analysts, and machine-learning engineers alike dream that all data could arrive at their doorstep in the cleanest form possible. Unfortunately, humans went and developed the phonetic alphabet before they started talking in binary, or “ beep boop” speech. As a result, it is unfortunately incredibly common to come across words (or “ strings” in “ beep boop” language) rather than numbers when working with data-sets, and this is even true of the cleanest data-sets available today.
在理想的世界中,所有程序员,科学家,数据工程师,分析师和机器学习工程师都梦想着,所有数据都可以以最干净的形式到达他们的家门口。 不幸的是,人们开始以二进制或“哔哔”的声音说话之前就发展了语音字母表。 结果,不幸的是,在使用数据集时碰到单词(或“哔哔声”语言中的“字符串”)而不是数字是非常常见的,甚至对于当今最干净的数据集也是如此。
The problem with the combination of data and strings and words is that words cannot directly be analyzed by an artificial brain. Computers speak quantitatively, rather than qualitatively. Asking a computer to interpret words, especially sentences with subjective meaning or emotion is like having the Cookie monster eat celery;
数据与字符串和单词的组合存在的问题是单词不能被人工大脑直接分析。 计算机说的是定性的,而不是定性的。 让计算机解释单词,尤其是具有主观意义或情感的句子,就像让Cookie怪兽吃芹菜一样;
it’s just not going to happen.
只是不会发生。
Fortunately, there is a solution to this problem — there are many different ways that you can approach turning words into numbers for analysis! Though doing so might not allow a computer to analyze certain things about words, it can certainly help with solving common machine-learning problems that you may encounter in the educational grind that is Data-Science. Typically, whenever machine-learning is being done with strings, a Data-Scientist will be working with an encoder. Without further ado, let’s look at some encoders!
幸运的是,有一个解决此问题的方法-您可以采用多种不同的方法将单词转化为数字进行分析! 尽管这样做可能不允许计算机分析有关单词的某些内容,但它无疑可以帮助您解决在数据科学领域的教育中可能遇到的常见机器学习问题。 通常,每当使用字符串完成机器学习时,数据科学家都会使用编码器。 事不宜迟,让我们看一些编码器!
一站式编码器 (One-Hot-Encoder)

If you’re new to machine-learning, one trick you should definitely snatch up as soon as possible is the ability to One-Hot-Encode a Data-Frame. One-Hot-Encoding, also called One-Hot, or Dummy-Encoding takes a very radical approach to dealing with categorical variables. Typically, I use One-Hot in situations where I have as few categories as possible. This is because first and foremost, One-Hot-Encoded data takes up a lot of memory and disk space compared to the other algorithms available. Additionally, One-Hot really shines in this exact light.
如果您是机器学习的新手,那么一定要尽快掌握一个技巧,即可以对数据帧进行一次热编码。 单热编码(也称为单热编码或虚拟编码)采用了一种非常激进的方法来处理分类变量。 通常,在类别越少越好的情况下,我会使用One-Hot。 这是因为,与其他可用算法相比,单热编码数据首先要占用大量内存和磁盘空间。 此外,One-Hot确实可以在这种精确的光线下发光。
When working with large sets of categorical features, One-Hot can turn a 5 column dataframe into a 50 column dataframe, which is incredibly hard to work with! On top of that, typically with higher stakes in categories, One-Hot’s effectiveness may drop dramatically. To understand why this may happen, let’s write a One-Hot-Encoder, and see what happens when we use it. We’ll start by defining the function. When working with data-altering and data-destructive methods, it’s a good idea to at the very least do an assertion or shallow copy. Since we are working with dataframes, it would probably be a great idea to use a library like copy, especially in Python. For this example, I am not going to do so — as my intention is to add the columns onto my dataframe, and my data itself is extremely unimportant and only for demonstration purposes.
当使用大量分类功能时,One-Hot可以将5列数据框转换为50列数据框,这很难使用! 最重要的是,通常在类别中的赌注较高,One-Hot的有效性可能会急剧下降。 为了理解为什么会发生这种情况,让我们编写一个“一键编码器”,然后看看使用它时会发生什么。 我们将从定义函数开始。 当数据改变和数据破坏性的方法工作,这是一个好主意, 至少是做一个断言或浅拷贝。 由于我们正在使用数据帧,因此最好使用像copy这样的库,尤其是在Python中。 在此示例中,我不会这样做–因为我的意图是将列添加到数据框中,并且数据本身极其不重要,仅用于演示目的。
function onehot(df,symb)
copy = dfNext, we are going to need to loop through the unique values in our dataframe:
接下来,我们将需要遍历数据帧中的唯一值:
for c in unique(copy[!,symb])Next, we’ll use a little bit of clever iterative syntax to create a one-line One-Hot algorithm in this loop:
接下来,在此循环中,我们将使用一些聪明的迭代语法来创建单行One-Hot算法:
copy[!,Symbol(c)] = copy[!,symb] .== cBasically what this does is loops through all of the values on the “ symb” column of copy. Symb in this example of course represents the column that is the key for our dictionary. We are adding a new key with copy[!, Symbol(c)] and then setting it equal to a condition. The .== operand in Julia is the same thing as the == operand, just for an entire array. As a result, this will fill the new column with booleans, true or false values, that correspond with whether or not the value in our original column corresponds with our new column’s value. Now we will return the copy dataframe and end our function.
基本上,这是遍历副本“ symb”列上的所有值。 当然,此示例中的Symb代表列,这是我们字典的键。 我们使用copy[!, Symbol(c)]添加一个新键,然后将其设置为等于条件。 Julia中的。==操作数与==操作数相同,仅适用于整个数组。 结果,这将用布尔值(真或假值)填充新列,这些值与我们原始列中的值是否与我们新列的值相对应。 现在,我们将返回复制数据帧并结束我们的功能。
function onehot(df,symb)
copy = df
for c in unique(copy[!,symb])
copy[!,Symbol(c)] = copy[!,symb] .== c
end
return(copy)
endWhat does this look like in practice?
实际上这是什么样的?
Have a look:
看一看:
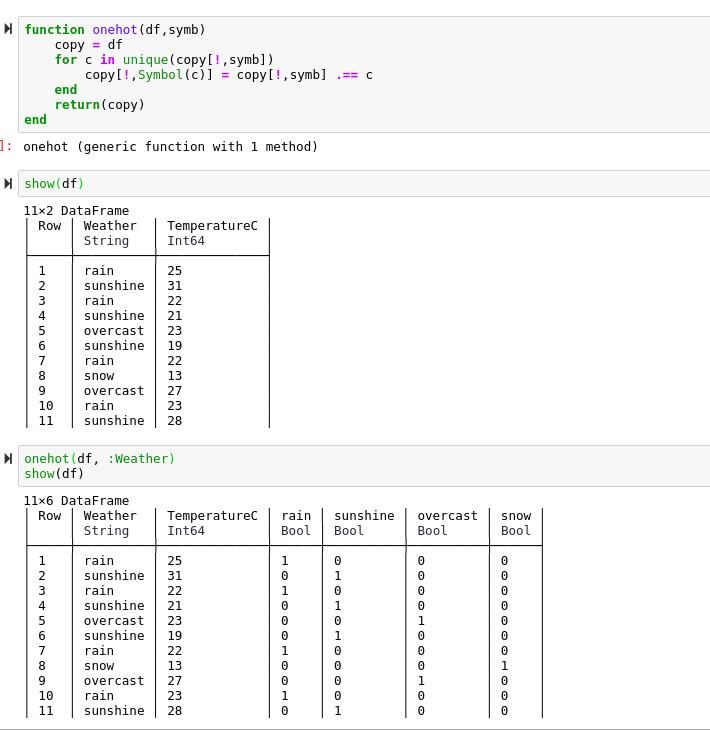
As you can see, we now have four boolean columns. There is one column for each unique string inside of the Weather column.
如您所见,我们现在有四个布尔列。 Weather列中的每个唯一字符串都有一个列。
序数编码 (Ordinal Encoding)
An entirely different approach to take to making categorical features numeric is Ordinal Encoding. Rather than taking the One-Hot approach of using booleans to represent values, an ordinal encoder instead uses integers —
使分类特征成为数字的一种完全不同的方法是“序数编码”。 序数编码器不是采用使用布尔值表示值的一站式方法,而是使用整数-
who would have thought?!
谁曾想到?!
Ordinal Encoding is far less CPU and more importantly memory intensive than One-Hot. Ordinal Encoding really outshines One-Hot whenever the categories are very high. At a certain point, One-Hot just can’t keep up and Ordinal Encoding is the way to go. How exactly does an ordinal encoder turn strings into integers?
顺序编码比单热编码要少得多的CPU,更重要的是要占用大量内存。 每当类别非常高时,顺序编码确实比一键编码好。 在某个时候,单步操作无法跟上,而序编码是必经之路。 序数编码器如何精确地将字符串转换为整数?
Let’s look at some code to find out!
让我们看一些代码找出答案!
As I explained prior to the One-Hot example, it would be wise to copy your variables here. It’s much better to add a simple copy than have to backtrack or restart your work because of some messed up data, and this is especially true if you’re working in a REPL. The first thing I’m going to do in this function is create a set.
正如我在“一键通”示例之前所解释的那样,在此处复制变量是明智的。 添加一个简单的副本比由于某些混乱的数据而不得不回溯或重新启动工作要好得多,尤其是在REPL中工作时。 我要在此函数中做的第一件事是创建一个集合。
function OrdinalEncoder(array)
uni = Set(array)A set is a fantastic type that is available in both Julia and Python that will make getting unique values far quicker and simpler than it would be otherwise. After we get our set, we’ll create a new dictionary:
集合是一种出色的类型,在Julia和Python中都可以使用,这将比其他方式更快,更简单地获得唯一值。 设置好集合后,我们将创建一个新的字典:
lookup = Dict()This is not only a dictionary in the “ type” sense, but also a very real dictionary that is used to look up values that correspond to keys. Before we can go searching for our favorite words in the dictionary, however, we are going to need to populate it. We can do this by enumerating our set iteratively and adding those keys and corresponding values to our dictionary:
这不仅是“类型”意义上的字典,还是非常真实的字典,用于查找与键对应的值。 但是,在我们要在字典中搜索最喜欢的单词之前,我们需要填充它。 我们可以通过迭代枚举我们的集合并将这些键和相应的值添加到字典中来实现:
for (i, value) in enumerate(uni)
push!(lookup, (value => i))
endNext, we will create a new array:
接下来,我们将创建一个新数组:
newarray = []And then iteratively we will append our values back to it after checking to see which key it corresponds with in our dictionary:
然后,我们将在检查字典中对应于哪个键之后,反复将其值附加回它:
for row in array
newvalue = lookup[row]
append!(newarray, newvalue)
endThen i’m going to add my predict() function and return a type to facilitate the use of it.
然后,我将添加我的prepare()函数并返回一个类型,以方便使用它。
predict() = newarray
()->(predict)Here is the function as a whole:
这里是整体功能:
function OrdinalEncoder(array)
uni = Set(array)
lookup = Dict()
for (i, value) in enumerate(uni)
push!(lookup, (value => i))
end
newarray = []
for row in array
newvalue = lookup[row]
append!(newarray, newvalue)
end
predict() = newarray
()->(predict)
endNotice anything fishy?
注意到有什么腥吗?
Fortunately, this function can also be simplified to a painful degree. Check this out:
幸运的是,此功能也可以简化到一个痛苦的程度。 看一下这个:
function OrdinalEncoder(array)
uni = Set(array)
lookup = Dict()
[push!(lookup, (value => i)) for (i, value) in enumerate(uni)]
predict() = [row = lookup[row] for row in array]
()->(predict)
endThat’s a lot better!
好多了!
Now let’s test it out on that data-set.
现在让我们在该数据集上进行测试。
oe = OrdinalEncoder(df[:Weather])
df[:OrdinalEncoded] = oe.predict()
As you can see, the Ordinal Encoder simply enumerates all of the unique values in the dataframe and then reapplies that value across all of the observations in the column. Pretty simple, but easily the most versatile and effective of the three encoders I am going over today. The great thing about this encoder is that it is for the most part a “ one size fits all” experience. This is because performance isn’t necessarily of great concern and it works well with large categories as well as small categories, though it may lose some accuracy depending on the situation it is found in.
如您所见,“顺序编码器”仅枚举数据框中的所有唯一值,然后将该值重新应用于列中的所有观察值。 很简单,但是很容易,我今天要介绍的三种编码器中功能最丰富,最有效。 这款编码器的妙处在于,它在很大程度上是“一种尺寸适合所有人”的体验。 这是因为性能不一定会引起很大的关注,并且它适用于大型类别和小型类别,尽管根据所处的情况它可能会失去一些准确性。
标签编码器 (Label Encoder)
What is a Label Encoder? Chances are that anyone reading this article knows exactly what a Label Encoder is — because we just created one from scratch! That’s right, the Label Encoder is the same exact thing as the Ordinal Encoder — at least in function. No, this is not quite the same situation that we have seen with Dummy Encoding VS. One-Hot Encoding. The entire reason that both of these terms exist is because of the way Sklearn built their pre-processing package. In order to have both the Label Encoder and the Ordinal Encoder work very effectively at their tasks, they needed to be separate. The big difference between these two is that the Label Encoder is typically used for targets, whereas the Ordinal Encoder is typically used to encode features — that’s it! So if you’re wondering what the code looks like, just cover up the function definition here and pretend it says “ LabelEncoder.”
什么是标签编码器? 阅读本文的任何人都有可能确切地知道标签编码器是什么-因为我们只是从头开始创建的! 没错,至少在功能上,标签编码器与顺序编码器完全相同。 不,这与我们在Dummy Encoding VS中看到的情况不太一样。 一键编码。 这两个术语同时存在的全部原因是因为Sklearn构建其预处理程序包的方式。 为了使标签编码器和顺序编码器在各自的任务中都能非常有效地工作,必须将它们分开。 两者之间的最大区别在于,通常将Label Encoder用于目标,而Ordinal Encoder通常用于对要素进行编码-就是这样! 因此,如果您想知道代码是什么样子,只需在此处覆盖函数定义并假装其为“ LabelEncoder”即可。
function OrdinalEncoder(array)
uni = Set(array)
lookup = Dict()
[push!(lookup, (value => i)) for (i, value) in enumerate(uni)]
predict() = [row = lookup[row] for row in array]
()->(predict)
endASCII编码器 (ASCII Encoder)
An ASCII Encoder, also known as a Float Encoder (why do all encoders need two names?) uses the ASCII system of numbering the phonetic alphabet and symbols to create unique categories based on the chars contained inside of a string. This is both effective, and versatile, as this system can not only apply to standard categorical problems, but also natural language processing! On top of that, it is also incredibly easy to do, and can be very effective, especially when working with a data-set with many different values.
ASCII编码器,也称为浮动编码器(为什么所有编码器都需要两个名称?)使用对语音字母和符号进行编号的ASCII系统,基于字符串内部包含的字符创建唯一的类别。 这既有效又通用,因为该系统不仅可以应用于标准分类问题,还可以应用于自然语言处理! 最重要的是,它也非常容易实现,并且非常有效,尤其是在处理具有许多不同值的数据集时。
The first step in creating an ASCII encoder is to split up your strings into chars. This can be done with the split() method, or an iterative loop over the string. While the latter is more intensive it is what I usually prefer.
创建ASCII编码器的第一步是将字符串拆分为char。 这可以通过split()方法或字符串的迭代循环来完成。 尽管后者更加密集,但这是我通常更喜欢的。
for dim in array
newnumber = 0
for char in dimNext, you have a manipulative decision to make. If we were attempting to perform some sort of natural language processing on these chars, or if we had an absolutely enormous number of categories, it might be wise to go char-by-char and create a new integer that is a series of numbers to represent individual characters in the string. However, since we are just trying to categorize a very small data-set, instead I would advise adding the numbers, like so:
接下来,您需要做出操纵性的决定。 如果我们试图对这些字符进行某种自然语言处理,或者我们有绝对数量的类别,那么逐个字符地创建一个新的整数是一个明智的选择。代表字符串中的各个字符。 但是,由于我们只是试图对一个很小的数据集进行分类,所以我建议添加数字,如下所示:
newnumber += Float64(char)Then we’ll append it to our new list of numbers and create our predict function just like before, and here we go:
然后,将其添加到新的数字列表中,并像以前一样创建我们的预测函数,然后开始:
function FloatEncoder(array)
encoded_array = []
for dim in array
newnumber = 0
for char in dim
newnumber += Float64(char)
end
append!(encoded_array, newnumber)
end
predict() = encoded_array
()->(predict)
enddf[:FloatEncoder] = fe.predict()
As you can see, you get a dramatically different result, and the algorithm can also be manipulated to achieve a lot more goals than just categorical encoding.
如您所见,您将获得截然不同的结果,并且该算法还可以进行操作以实现比分类编码更多的目标。
结论 (Conclusion)
Encoders. Are. Awesome! Learning to read data and use the correct encoder is likely the biggest problem associated with using each encoder. Fortunately, understanding how they work and being able to write them makes it far easier to imagine what encoder might work really well in your particular situation. No matter what situation you might find yourself in with that regard, you will always learn from it and be able to apply your newly found skill in a new way. Thank you for reading my article, and have a great rest of your day (or night!)
编码器。 是。 太棒了! 学习读取数据并使用正确的编码器可能是与使用每个编码器相关的最大问题。 幸运的是,了解它们的工作原理并能够编写它们可以使您更轻松地想象一下哪种编码器在您的特定情况下可能确实工作得很好。 无论您在哪种情况下都处于这方面,您都将始终从中学习并能够以新的方式应用新发现的技能。 感谢您阅读我的文章,并度过了愉快的一天(或夜晚)!
翻译自: https://towardsdatascience.com/encoders-how-to-write-them-how-to-use-them-d8dd70f45e39















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









