





 本文介绍了如何运用多项式朴素贝叶斯分类器进行话题预测,详细阐述了该分类器在主题识别中的应用。
本文介绍了如何运用多项式朴素贝叶斯分类器进行话题预测,详细阐述了该分类器在主题识别中的应用。
多项式朴素贝叶斯分类器
In Analytics Vidhya, Hackathon, there was a problem statement for text prediction of topic/subject to which class it belongs basis on title and abstract. To solve this question of prediction problem I have applied Multinomial Naive Bayes classifier supervised algorithm.
在 Hackathon的Analytics Vidhya中,存在一个问题说明,用于根据标题和摘要对主题/主题进行文本预测。 为了解决这个预测问题,我应用了多项朴素贝叶斯分类器监督算法。
In this blog, I have covered the importance of the Naive Bayes classifier, its types, and the actual implementation of the algorithm for the given problem statement.
在此博客中,我介绍了朴素贝叶斯分类器的重要性,其类型以及针对给定问题陈述的算法的实际实现。
什么是朴素贝叶斯? 为什么? (What is Naive Bayes? and Why?)
Naive Bayes Classifier Algorithm is a family of probabilistic algorithms based on applying Bayes’ theorem with the “naive” on the basis of two following assumption:
朴素贝叶斯分类器算法是一系列概率算法,基于以下两个假设,将贝叶斯定理与“朴素”一起应用:
- Predictors are independent of each other. 预测变量彼此独立。
- All features have an equal effect on the outcome. 所有功能对结果都有同等的影响。
Bayes theorem calculates probability P(c|x) where c is the class of the possible outcomes and x is the given instance which has to be classified, representing some certain features.
贝叶斯定理计算概率P(c | x),其中c是可能结果的类别,x是必须分类的给定实例,代表某些特征。
P(c|x) = P(x|c) * P(c) / P(x)
P(c|x) = P(x|c) * P(c) / P(x)
Naive Bayes is mostly used in natural language processing (NLP) problems. Naive Bayes predicts the tag of a text. They calculate the probability of each tag for a given text and then output the tag with the highest one.
朴素贝叶斯主要用于自然语言处理(NLP)问题。 朴素贝叶斯(Naive Bayes)预测文本的标签。 他们计算给定文本的每个标签的概率,然后输出最高标签的标签。
朴素贝叶斯的类型 (Types of Naive Bayes)
- Multinomial Naive Bayes — Whether a document/topic belongs to a particular category. The features/predictors used by the classifier are the frequency of the words present in the document. 多项式朴素贝叶斯-文档/主题是否属于特定类别。 分类器使用的功能/预测词是文档中出现的单词的频率。
- Bernoulli Naive Bayes- Similar to above, but only predicts the boolean variables, The parameters are used to predict the class variable yes or no, For example, a word occurs in the text or not. Bernoulli Naive Bayes-与上面类似,但仅预测布尔变量,该参数用于预测类变量yes或no,例如,文本中是否出现单词。
- Gaussian Naive Bayes: When the predictors take up the continuous value and are not discrete, we assume that values are sampled from Gaussian distribution. 高斯朴素贝叶斯(Gaussian Naive Bayes):当预测变量采用连续值且不是离散值时,我们假设值是从高斯分布中采样的。
朴素贝叶斯的缺点: (Disadvantages of Naive Bayes:)
The requirement of predictors need to be independent.
预测变量的需求必须独立。
Hackathon问题: (Hackathon Problem:)
Given the abstract and title for a set of research articles, predict the topics for each article included in the test set. This can be read more into detail.
给定一组研究文章的摘要和标题,预测测试集中包含的每篇文章的主题。 这可以更详细地阅读。
So we have train.csv, test.csv, and sample_submission.csv. Now we have to build the model for prediction of the particular topic to which class it belongs.
因此,我们有了train.csv,test.csv和sample_submission.csv。 现在,我们必须构建模型以预测特定主题所属的类别。
Let’s see the actual implementation in detail. Code is available on Github
让我们详细了解实际的实现。 可以在Github上找到代码
import logging
import pandas as pd
import numpy as np
from numpy import random
import gensim
import nltk
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
import re
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
%matplotlib inline
#Input the filename
train=pd.read_csv('train.csv',index_col=0)
#Function to describe input data
def describe_data(df):
print("Data Types:")
print(df.dtypes)
print("Rows and Columns:")
print(df.shape)
print("Column Names:")
print(df.columns)
print("Null Values:")
print(df.apply(lambda x: sum(x.isnull()) / len(df)))
describe_data(train)In the below steps, we will train the model with text and for that, we need to convert it into the form of vectors.
在以下步骤中,我们将使用文本训练模型,为此,我们需要将其转换为向量形式。
#Consider the input values for X and y
X=train['TITLE']
y=train['Quantitative Finance']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
#Convert the text into vector form
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(strip_accents='ascii', token_pattern=u'(?ui)\\b\\w*[a-z]+\\w*\\b', lowercase=True, stop_words='english')
X_train_cv = cv.fit_transform(X_train)
X_test_cv = cv.transform(X_test)
#Calculate the Word_freq count
word_freq_df = pd.DataFrame(X_train_cv.toarray(), columns=cv.get_feature_names())
top_words_df = pd.DataFrame(word_freq_df.sum()).sort_values(0, ascending=False)
print(top_words_df)Now, we will define the Multinomial model and train it. Also print classification report, Precision score, Recall, and accuracy.
现在,我们将定义多项式模型并对其进行训练。 还可以打印分类报告,精度得分,召回率和准确性。
#Training the model
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(X_train_cv, y_train)
predictions = naive_bayes.predict(X_test_cv)
#Accuracy and Classification report
from sklearn.metrics import accuracy_score, precision_score, recall_score,classification_report
print('Accuracy score: ', accuracy_score(y_test, predictions))
print('Precision score: ', precision_score(y_test, predictions))
print('Classification_report',classification_report(y_test,predictions))
print('Recall score: ', recall_score(y_test, predictions))
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
cm = confusion_matrix(y_test, predictions)
sns.heatmap(cm, square=True, annot=True, cmap='RdBu', cbar=False,
xticklabels=['0', '1'], yticklabels=['0', '1'])
plt.xlabel('true label')
plt.ylabel('predicted label')
testing_predictions = []
for i in range(len(X_test)):
if predictions[i] == 1:
testing_predictions.append('1')
else:
testing_predictions.append('0')
check_df = pd.DataFrame({'actual_label': list(y_test), 'prediction': testing_predictions, 'TITLE':list(X_test)})Accuracy score: 0.9876042908224076
Precision score: 0.75
Classification_report precision recall f1-score support
0 0.99 1.00 0.99 4141
1 0.75 0.06 0.10 54
accuracy 0.99 4195
macro avg 0.87 0.53 0.55 4195
weighted avg 0.98 0.99 0.98 4195
Recall score: 0.05555555555555555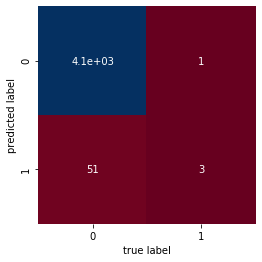
Now it’s time to apply the prediction for unknown data i.e test file. For that, we will pickle the model initially and then will load the model and save the predictions to the .csv file.
现在是时候对未知数据(即测试文件)应用预测了。 为此,我们将首先对模型进行酸洗,然后加载模型并将预测结果保存到.csv文件中。
#import the model in form of pickle
import pickle
with open('text_classifier', 'wb') as picklefile:
pickle.dump(naive_bayes,picklefile)
#Load the model
with open('text_classifier', 'rb') as training_model:
model = pickle.load(training_model)
#input the test file for prediction
test=pd.read_csv('n5.csv',error_bad_lines=False,skipinitialspace=False)
test
label=test['TITLE']
#transform the text into label
new_test = cv.transform(label)
predictions2=model.predict(new_test)
testing_predictions2 = []
for i in range(len(label)):
check_df2 = pd.DataFrame({'Quantitative Finance':predictions2})
test = test.set_index(check_df2.index)
test['Quantitative Finance']=check_df2
test
test.to_csv('Submission.csv',index=False)In the end, the submissions are submitted in the prescribed format.
最后,提交内容以规定的格式提交。
Enjoy predicting!!!
享受预测!
多项式朴素贝叶斯分类器















 4152
4152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









