





Web scraping is one of the key elements to make your development in Data Science effective and fun. If you already learned the basics and feel stuck with another project on Titanic, California Housing, Iris, MNIST or Kaggle datasets this article is probably for you.
Web抓取是使您的数据科学开发有效且有趣的关键要素之一。 如果您已经学习了基础知识,并且对另一个与Titanic,California Housing,Iris,MNIST或Kaggle数据集有关的项目感到困惑,那么本文可能适合您。
1.为什么要进行网页爬取? (1. Why Web Scraping?)
When you begin your Data Science journey, for the first few weeks you are probably amazed how you can use your new amazing skills to predict housing prices in California, recognize hand-written digits or classify flowers.
当您开始数据科学之旅时,在头几周内,您可能会惊讶于如何使用新的惊人技能来预测加利福尼亚的房价,识别手写数字或对花朵进行分类。
But then you realize, that your skills are not so unique, there are hundreds of thousands of wannabe Data Scientists who worked on the same data sets and your work doesn’t distinguish you in any way.
但是随后您意识到,您的技能并不是那么独特,有成千上万的想要从事数据研究工作的数据科学家都在同一数据集上工作,而您的工作并没有以任何方式区分您。
The best way to hone your skills and build an outstanding portfolio is to work on something unique, something you are passionate about. The main obstacle you need to face at the current stage is data. You might be passionate about the pricing of vintage cars and it is quite a unique project idea, but that is not the sort of datasets you find on Kaggle.
磨练技能并建立出色的投资组合的最佳方法是从事一些独特的事情,而您对此充满热情。 当前阶段您需要面对的主要障碍是数据。 您可能对老式汽车的价格充满热情,这是一个非常独特的项目构想,但这并不是您在Kaggle上找到的那种数据集。
这是Web Scraping派上用场的地方,它使您可以在数据科学开发中迈出下一步—开始着手于独特而有趣的项目。 (This is where Web Scraping comes in handy and allows you to make the next big step in your Data Science development— start working on unique and interesting projects.)
I know what you’re thinking — you need to be some kind of hacker with mad coding skills to understand the thousands of lines of html that swarm you once you start web scraping. This is exactly what I thought before learning Beautiful Soup.
我知道您在想什么-您必须是具有某种疯狂的编码技能的黑客,才能理解开始抓取网页时会淹没您的数千行html。 这正是我学习美丽汤之前的想法。
Then I had a brief moment of hope while studying “Web Scraping with Python” by R.Mitchell, which I recommend to everyone wanting to learn Web Scraping. I Completed a few initial exercises, started to understand the simple training websites and decided to try what I learned in the real world…
然后,在学习R.Mitchell的“使用Python进行Web爬虫”时,我有了短暂的希望,我向所有想要学习Web爬虫的人推荐。 我完成了一些初步练习,开始了解简单的培训网站,并决定尝试在现实世界中学到的东西...
……起初,这是一场噩梦! (… and at first, it was a nightmare!)
It took me dozens of hours before I managed to learn a few tricks, which help to extract the data you need and open up endless data possibilities. In this article, I will share a few of them with you to help you launch your first web scraping project
我花了数十个小时才设法学习一些技巧,这些技巧有助于提取所需的数据并开辟无穷的数据可能性。 在本文中,我将与您分享其中的一些内容,以帮助您启动第一个Web抓取项目
2.简介(2. Introduction)
This article will focus on a step by step guide to Web Scraping with Beautiful Soup. I focus on websites with offers listings, using UKs largest home rental website: www.rightmove.co.uk as an example.
本文将重点介绍有关“使用美丽的汤进行网页爬取”的分步指南。 我以英国最大的房屋租赁网站(例如www.rightmove.co.uk)为重点,介绍提供报价的网站。
A similar approach can be used with any similar websites, which gives you access to data with car offers, home sales, whisky listings, or pretty much anything you can find on online marketplace.
任何类似的网站都可以使用类似的方法,使您可以访问有关汽车报价,房屋销售,威士忌清单或几乎可以在在线市场上找到的任何内容的数据。
在从商品详情网站抓取数据时,我建议您遵循以下3个步骤: (While scraping the data from an offers listing website I recommend following these 3 steps:)
- A) Start with a single listing — analyze if you are able to extract desired data from it A)从一个清单开始-分析是否能够从清单中提取所需数据
- B) Go up a level in the hierarchy — extract hyperlinks to listings from one pageB)在层次结构中上一层楼-从一页提取到列表的超链接
- C) Create a list of pages for which you can repeat steps points B and A.C)创建一个页面列表,您可以针对其重复步骤B和A。
The roadmap above follows a bottom-up route, which might not seem most logical at the beginning. I will explain along the way how this can save you time.
上面的路线图遵循自下而上的路线,一开始似乎不太合乎逻辑。 我将一路说明如何节省时间。
The full code for this article can be found on GitHub.
3.美丽的汤 (3. Beautiful Soup)
Beautiful Soup is one of the most popular Python libraries for web scraping. At least a basic understanding of this library is required to fully understand the following part of the article. If you need some catching up I recommend the library documentation, which is a great introduction to the library.
Beautiful Soup是用于Web抓取的最受欢迎的Python库之一。 要完全理解本文的以下部分,至少需要对该库有一个基本的了解。 如果您需要一些帮助,我建议您提供库文档,这是对该库的出色介绍。
4.让我们开始编码-从单个清单中提取数据 (4. Let’s start coding — extracting data from a single listing)
We start with the most detailed component of the whole website — a single listing. The reason for starting at the bottom is the fact, that in some cases the data we are interested in might not be accessible. We want to avoid wasting time on building the whole pipeline of scraping multiple pages and listing hyperlinks to find out we are not able to make any use of the offers itself.
我们从整个网站最详细的部分开始-一个清单。 从底部开始的原因是这样的事实,在某些情况下,我们可能无法访问我们感兴趣的数据。 我们希望避免浪费时间来构建刮刮多个页面和列出超链接的整个管道,以发现我们无法充分利用优惠本身。
The moment of truth comes down to a few lines of code:
关键时刻归结为以下几行代码:
# url of first listing
listing_url = 'https://www.rightmove.co.uk/properties/97077389#/'requests.get(listing_url)<Response [200]> — this is what we really want to see. Anything different means that the access for web scraping this page is limited.
<响应[200]>-这是我们真正想要看到的。 任何不同方式都意味着对Web抓取此页面的访问受到限制。
Once we are sure, that we have access to the listing, let’s process the URL with Beautiful Soup.
一旦确定可以访问列表,就可以使用Beautiful Soup处理URL。
page = requests.get(listing_url)
bs = BeautifulSoup(page.text, 'lxml')
bs.prettify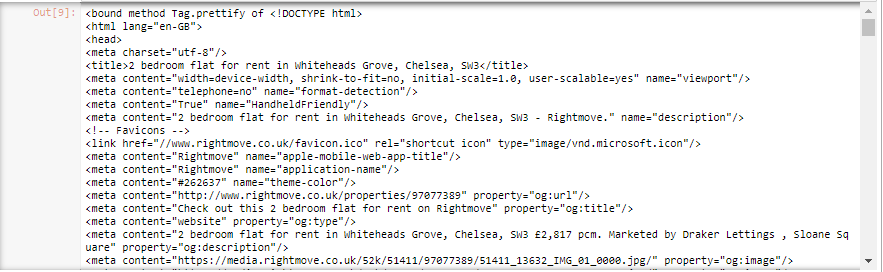
Calling prettify on bs object allows us to make the html code slightly more readable, but we are still left with thousands of lines, which we can scroll through for hours… This is when we need to think of something clever.
在bs对象上调用prettify可以使html代码更具可读性,但是我们仍然剩下数千行,可以滚动几小时……这是我们需要思考一些聪明的时候。
At this stage, I use a trick, which is far from a best coding practice, and will not work in large scale production code, but helps to get off the ground on your initial web scraping projects.
在这个阶段,我使用了一个技巧,它与最佳编码实践相去甚远,并且不能在大规模生产代码中使用,但是可以帮助您进行最初的Web抓取项目。
During WWII Breaking the Enigma, which was one of the first great achievements of Computer Science, started with looking for common phrases in German messages such as the Natzi greeting: “Heil Hitler”… we have a much easier task here, but that doesn’t mean we can’t use the same approach.
在第二次世界大战期间,计算机科学的首批重大成就之一《打破谜团》始于在德语消息中寻找常用短语,例如纳粹(Natzi)问候:“希特勒(Heil Hitler)”……我们这里的任务要简单得多,但这并没有。并不意味着我们不能使用相同的方法。
We know that one of the most important values we want to find is the monthly rent price. I use the listing_url link to look it up directly on the website: it turns out to be 2,817.
我们知道,我们想找到的最重要的价值之一就是月租金。 我使用listing_url链接直接在网站上查找:结果为2,817。
Now, all we need to do is a simple action, which would probably make most software engineers cry… search for phrase ‘2,817’ within the html code. We can find 5 such instances. This is not good enough…
现在,我们要做的只是一个简单的动作,这可能会使大多数软件工程师哭泣……在html代码中搜索短语“ 2,817”。 我们可以找到5个此类实例。 这还不够好……
We have one more tip, which will lead us towards the desired data — it will probably be stored in JSON, so we want to find something similar to “price”:”2,817". We can see, that the 5th instance found during the search looks like “primaryPrice”:”£2,817 pcm”. Let’s investigate what the body of text storing this value look like.
我们还有另外一个技巧,可以将我们引向所需的数据-它可能会存储在JSON中,因此我们想找到类似于“ price”的内容:“ 2,817”。我们可以看到,在搜索看起来像“ primaryPrice”:“ 2,817 pcm”。让我们研究一下存储此值的文本主体是什么样的。

After scrolling to the 5th occurrence of ‘2,817’ in the listing HTML, at first glance we only see a body of text… but after some investigation, we can see that this text is actually some sort of a dictionary, which hints we are getting closer to our desired JSON.
滚动到列表HTML中第5个出现的“ 2,817”之后,乍一看,我们只看到了一段文本……但是经过一番调查,我们发现该文本实际上是某种字典,这暗示着我们正在更接近我们所需的JSON。
The values we are interested in are stored within script tag, which has “text/javascript” type. Let’s extract just the script elements with such properties.
我们感兴趣的值存储在script标记中,该标记具有“ text / javascript”类型。 让我们仅提取具有此类属性的脚本元素。
bs.findAll("script",{'type':"text/javascript"})[0]It seems that the first extracted element contains the data that we are looking for. At this stage we want to drill down to the JSON data and are not interested in HTML elements, so let’s get rid of them using .text and create script_text variable.
似乎第一个提取的元素包含我们正在寻找的数据。 在此阶段,我们想深入研究JSON数据,并且对HTML元素不感兴趣,因此让我们使用.text摆脱它们,并创建script_text变量。
script_text=bs.findAll("script",{'type':"text/javascript"})[0].text
script_text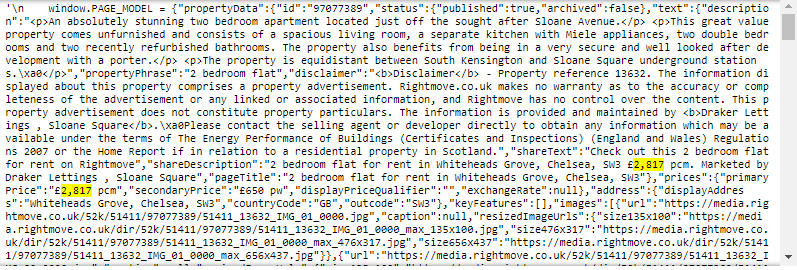
It seems we are getting closer to pure JSON data, which can easily be analyzed in Python. The last obstacle is the ‘ window.PAGE_MODEL =’ string before the opening “{”. Let’s REGEX it out and see if this solves our problem.
看来我们越来越接近可以在Python中轻松分析的纯JSON数据。 最后一个障碍是在开头“ {”之前的'window.PAGE_MODEL ='字符串。 让我们对其进行正则表达式,看看是否可以解决我们的问题。
# Use regex to extract json data from the script text
script_json=re.findall(("(?<=window.PAGE_MODEL = )(?s)(.*$)"), script_text)[0]# Transforming json data within string into dictionary
json_dict=json.loads(script_json)# We managed to succesfully extract json data into a Python dict
type(json_dict)dict
字典
We managed to sucessfully extract the data from the script text, convert it to json and into a Python dictionary. This is actually the majority of the work done. Let’s see what is the content of the extracted dictionary.
我们成功地从脚本文本中提取了数据,将其转换为json并转换为Python字典。 这实际上是完成的大部分工作。 让我们看看提取的字典的内容是什么。

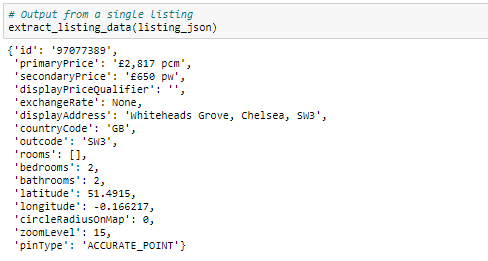
After some investigation, I realized that all the data that we are interested in is stored within the ‘propertyData key’. I created a function ‘extract_listing_data’ which can be investigated in more detail within the code available on GitHub. Here are the results scrapped from a single offer:
经过一番调查,我意识到我们感兴趣的所有数据都存储在“ propertyData键”中。 我创建了一个函数'extract_listing_data',可以在GitHub上的代码中进行更详细的研究。 以下是从单个报价中删除的结果:
5.从一页提取列表超链接(5. Extracting listing hyperlinks from one page)
Once we are confident, that we can extract desired data from a single listing, all we need to do is to extract hyperlinks to listings on one page and then repeat it for multiple pages.
一旦我们确信可以从单个列表中提取所需的数据,我们要做的就是提取到一页上列表的超链接,然后在多个页面上重复进行。
We start by looking for hyperlinks to listings from the first page. The link to the first page should already contain all the filters and sorting options, which you are interested in — I recommend setting them directly using the website.
我们首先从首页查找到列表的超链接。 指向首页的链接应该已经包含了所有感兴趣的过滤器和排序选项-我建议直接在网站上进行设置。
first_page_url='https://www.rightmove.co.uk/property-to-rent/find.html?locationIdentifier=REGION%5E87490&minPrice=1000&sortType=1&propertyTypes=&includeLetAgreedpage = requests.get(first_page_url)
bs = BeautifulSoup(page.text, 'lxml')
bs.prettifyThis time our search is easier, as we know that we are only interested in hyperlinks, which have an “a” tag. We can search for them using the following bs function.
这次,我们的搜索更加容易,因为我们知道我们只对带有“ a”标签的超链接感兴趣。 我们可以使用以下bs函数搜索它们。
bs.findAll("a",href=True)To find which links really interest us, all we need to do is to use the same method of searching for a known phrase. In this case, I used a part of the title of one of the listings, which contained “Belvedere”. After a quick search, I realized that all the ‘a’ tags, containing listing hyperlink have a class=’propertyCard-link’. We can use this to extract them using Beautiful Soup.
要找到真正使我们感兴趣的链接,我们要做的就是使用相同的方法搜索已知短语。 在这种情况下,我使用了其中一个清单的标题的一部分,其中包含“眺望楼”。 快速搜索后,我意识到包含清单超链接的所有'a'标签都有一个class ='propertyCard-link'。 我们可以使用它来使用美丽汤提取它们。
bs.findAll("a",{'class':'propertyCard-link'})[0].attrs['href']To find the exact hyperlink, we need to extract the “href” key from attrs dictionary. After adding the base website address of ‘https://www.rightmove.co.uk' to each href we have a list of all 25 hyperlinks from a single page.
要找到确切的超链接,我们需要从attrs词典中提取“ href”键。 在将基本网站地址“ https://www.rightmove.co.uk”添加到每个href之后,我们将在一个页面中列出所有25个超链接。
6.获取以下n页的列表 (6. Getting a list of n following pages)
The last task is rather trivial compared to the previous two. All we need to do is to analyze how the link we see in the browser changes once selecting page:2 option while browsing the website. In the case of rightmove website, it seems that the only change is within the ‘&index’ variable in the GET part of the URL address. All we needed to do is to create a function, which creates a list of the following pages.
与前两个任务相比,最后一个任务微不足道。 我们需要做的就是分析在浏览网站时选择page:2选项后在浏览器中看到的链接如何变化。 对于rightmove网站,似乎唯一的更改是在URL地址的GET部分的'&index'变量内。 我们需要做的就是创建一个函数,该函数创建以下页面的列表。
7.从多个列表中提取数据并将其转换为DataFrame (7. Extracting data from multiple listings and converting it to DataFrame)
We have all the components we need:
我们拥有所需的所有组件:
- A list of n following page URLs 以下n个页面URL的列表
- Listings URLs extracted from the page URLs从页面URL中提取的列表URL
- Function to extract data from a single listing URL 从单个列表URL提取数据的功能
All that is left is to combine data from all the listings into a suitable format: a data frame as preferred for further analysis.
剩下的就是将所有清单中的数据组合成合适的格式:数据框是进行进一步分析的首选。
We will do that in two steps. First append each listings JSON to a list, having one list entry containing data in JSON format for each offer.
我们将分两个步骤进行操作。 首先,将每个列表JSON附加到列表中,每个列表包含一个列表项,其中包含JSON格式的数据。
Then we use json.dumps and json.loads to convert the list of JSON instances into a df. Please investigate the GitHub code for more detail.
然后,我们使用json.dumps和json.loads将JSON实例列表转换为df。 请调查GitHub代码以获取更多详细信息。
8.将所有内容汇总为易于使用的Class (8. Summarizing everything into an easy to work with Class)
The 3 steps described in the article, can be summarized into a simple to use Class. Executing 4 consecutive functions allows extracting data from JSON to a ready DataFrame. Now you can analyze it however you like!
本文中描述的3个步骤,可以概括为一个易于使用的Class。 执行4个连续的函数可以将数据从JSON提取到就绪的DataFrame中。 现在,您可以按自己的意愿进行分析!
class Scrape_Rightmove:
'''
Class to extract data from listings featured on Rigthmove and convert it to DataFrame.
All functions should be executed from top to bottom as they are dependent on each other.
'''
def __init__(self, first_page_url, pages_count):
self.pages_count=pages_count
self.pages_urls_list=get_n_page_urls(first_page_url,pages_count)
print("Initialized class to scrape {} pages starting with {}".format(pages_count,first_page_url))
def extract_listings_ulrs(self):
self.listings_urls_list=extract_listing_url(self.pages_urls_list)
print("Extracted {} listings from {} pages".format(len(self.listings_urls_list),self.pages_count))
def extract_listings_data(self):
self.json_list=extract_multiple_listings_data(self.listings_urls_list)
def convert_json_to_df(self):
data_json=json.dumps(self.json_list)
self.df_data=pd.read_json(data_json, orient='id')
return(self.df_data)9.总结(9. Summary)
I hope that this article will help you to get off the ground with web scraping and extract the data you are really interested in. This skill will allow you to really stand out and work on unique projects.
我希望本文将帮助您开始进行网络抓取,并提取您真正感兴趣的数据。此技能将使您真正脱颖而出,并从事独特的项目。
Believe me, if you are a beginning Data Scientist during a recruitment process, even a simple analysis of a 1000 local Real Estate prices dataset you created yourself, will make you stand out more than a DNN trained using the 60k MNIST dataset.
相信我,如果您是招聘过程中的新手数据科学家,即使对您自己创建的1000个本地房地产价格数据集进行简单分析,也将使您脱颖而出,胜过使用60k MNIST数据集训练的DNN。
Furthermore, with access to a nearly limitless stream of data, you will be able to use your data science skills to solve your real-life problem and feel their impact. No matter if it’s buying a car, renting an apartment, or planning a holiday, with Web Scrapping you will be able to access better data and make better decisions.
此外,通过访问几乎无限的数据流,您将能够使用数据科学技能来解决您的现实问题并感受到其影响。 无论是买车,租房还是计划度假,使用Web Scrapping都可以访问更好的数据并做出更好的决策。














 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









