






nlp spacy
Named Entity Recognition is the most important, or I would say, the starting step in Information Retrieval. Information Retrieval is the technique to extract important and useful information from unstructured raw text documents. Named Entity Recognition NER works by locating and identifying the named entities present in unstructured text into the standard categories such as person names, locations, organizations, time expressions, quantities, monetary values, percentage, codes etc. Spacy comes with an extremely fast statistical entity recognition system that assigns labels to contiguous spans of tokens.
命名实体识别是最重要的,或者我想说这是信息检索中的起始步骤。 信息检索是从非结构化原始文本文档中提取重要和有用信息的技术。 命名实体识别NER的工作原理是将非结构化文本中存在的命名实体定位并识别为标准类别,例如人名,位置,组织,时间表达,数量,货币价值,百分比,代码等。Spacy带有非常快速的统计实体为标签的连续范围分配标签的识别系统。
Spacy Installation and Basic Operations | NLP Text Processing Library | Part 1
Spacy provides an option to add arbitrary classes to entity recognition systems and update the model to even include the new examples apart from already defined entities within the model.
Spacy提供了一个选项,可以向实体识别系统添加任意类,并更新模型,以包括模型中已定义的实体之外的新示例。
Spacy has the ‘ner’ pipeline component that identifies token spans fitting a predetermined set of named entities. These are available as the ‘ents’ property of a Doc object.
Spacy具有“内部”管道组件,该组件标识适合预定集合的命名实体的令牌范围。 这些可用作Doc对象的'ents'属性。
# Perform standard imports import spacy nlp = spacy.load('en_core_web_sm')# Write a function to display basic entity info: def show_ents(doc): if doc.ents: for ent in doc.ents: print(ent.text+' - ' +str(ent.start_char) +' - '+ str(ent.end_char) +' - '+ent.label_+ ' - '+str(spacy.explain(ent.label_))) else: print('No named entities found.')doc1 = nlp("Apple is looking at buying U.K. startup for $1 billion") show_ents(doc1)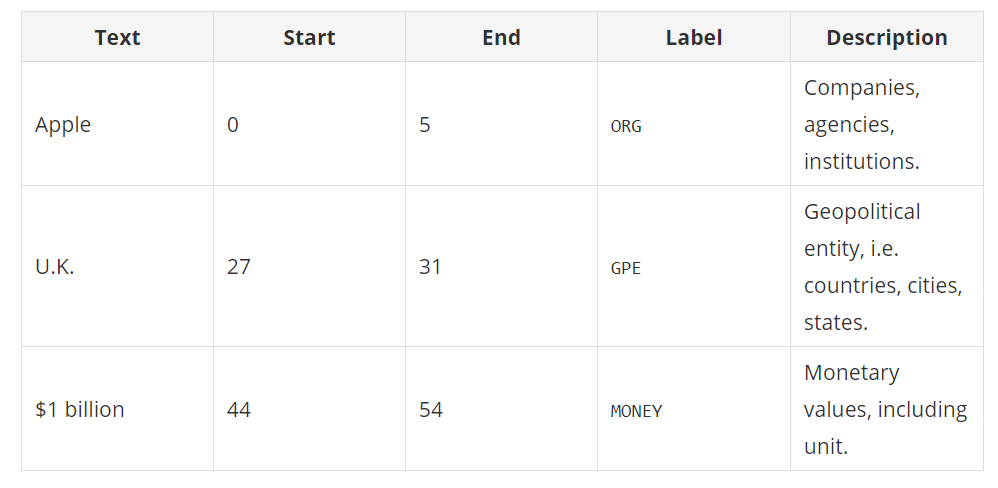
doc2 = nlp(u'May I go to Washington, DC next May to see the Washington Monument?') show_ents(doc2)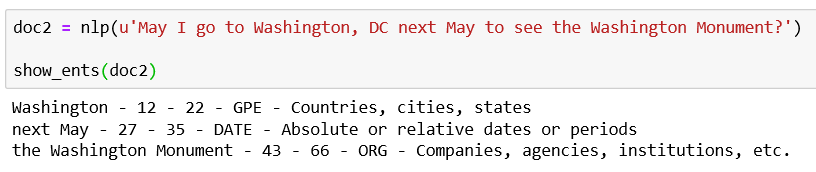
Here we see tokens combine to form the entities next May and the Washington Monument
在这里,我们看到代币结合在一起,形成了next May的实体和the Washington Monument
doc3 = nlp(u'Can I please borrow 500 dollars from you to buy some Microsoft stock?') for ent in doc3.ents: print(ent.text, ent.start, ent.end, ent.start_char, ent.end_char, ent.label_) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4134
4134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









