





webpack代码拆分
So, you have a React application, understand the performance and therefore usability benefits of splitting the code you ship to your users into multiple smaller bundles (chunks) rather than one large bundle, and have heard of Webpack ‘dynamic imports’ but are not quite sure how to go about using them. This guide is for you!
因此,您拥有一个React应用程序,了解将您的用户代码拆分为多个较小的捆绑(块)而不是一个大型捆绑的性能以及因此带来的可用性好处,并且听说过Webpack的“动态导入”,但不太了解确定如何使用它们。 本指南适合您!
We’ll look at different techniques of implementing code splitting, explore how to use Loadable Components to manage these, and outline how Webpack ‘magic comments’ can be used to generate prefetch and preload resource hints (and how useful these actually are).
我们将研究实现代码拆分的各种技术,探索如何使用可加载组件来管理这些内容,并概述如何使用Webpack的“魔术注释”来生成预取和预加载资源提示(以及它们的实际用途)。
This post was written using webpack@4.28.3 and @loadable/component@5.13.0.
这篇文章是使用webpack@4.28.3和@loadable/component@5.13.0 。
First let’s ask a deceptively simple question: how big should each code bundle be?
首先,让我们问一个看似简单的问题:每个代码束应该有多大?
每个代码束应该有多大? (How big should each code bundle be?)
The Cost of JavaScript 2019 advises:
Avoid having just a single large bundle; if a bundle exceeds ~50–100 kB, split it up into separate smaller bundles. (With HTTP/2 multiplexing, multiple request and response messages can be in flight at the same time, reducing the overhead of additional requests.)
避免只装一个大捆; 如果捆束超过〜50–100 kB,则将其分成单独的较小的捆束。 (通过HTTP / 2复用,可以同时传输多个请求和响应消息,从而减少了其他请求的开销。)
There are many articles around this subject, but for the sake of brevity let’s take 100kb as a reasonable max size of any one bundle.
关于这个主题有很多文章,但是为了简洁起见,让我们将100kb作为任一捆绑包的合理最大大小。
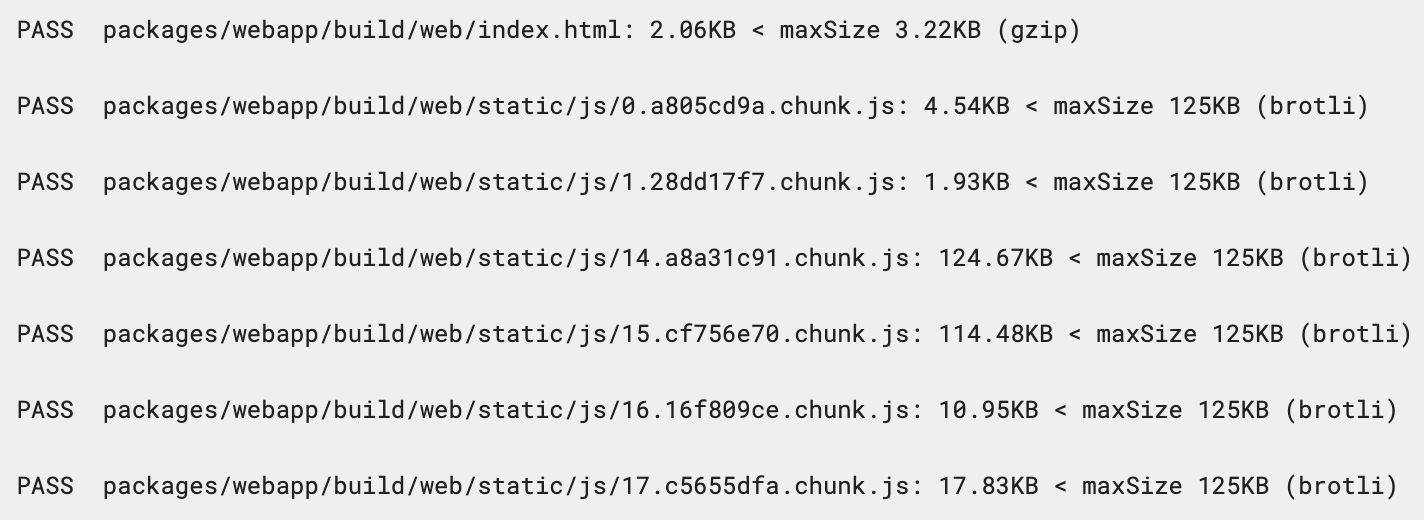
We can use bundlesize to measure this at build time. It analyses all bundles created and generates a report, and allows a max size of individual bundles to be specified as a pass/fail check.
我们可以在构建时使用bundlesize进行度量。 它分析所有创建的包并生成报告,并允许将单个包的最大大小指定为通过/失败检查。
This can even be enforced as a blocking check on pull requests if wanted, preventing code that would break any budget on the max size being merged. Importantly progressive improvements are possible here — if your application already exceeds a bundle of 100kb simply set it at the existing level, as this will ensure you don’t unknowingly degrade from the current size. Any time you make improvements you can then reduce this max size closer to 100kb.
如果需要,甚至可以将其强制执行为对拉取请求的阻止检查,以防止会破坏合并最大大小的任何预算的代码。 重要的是,这里可以进行逐步改进-如果您的应用程序已经超过了100kb,则只需将其设置为现有级别即可,因为这将确保您不会在不知不觉中从当前大小降级。 每次进行改进时,都可以将最大大小减小到接近100kb。
捆绑与大块 (Bundles vs Chunks)
You may have noticed that Bundlesize refers to ‘bundles’, but each bundle has the extension ‘.chunk.js’.
您可能已经注意到Bundlesize指的是“ bundles”,但是每个捆绑包都具有扩展名“ .chunk.js”。
These terms are nearly, but not completely, synonymous.
这些术语几乎(但不完全)是同义词。
With references to the Webpack Glossary this post explains the differences between bundles and chunks best. For now we can say that when we make new code split points we create new chunks, which are then used to output final bundles. These normally have a 1:1 mapping hence seeming synonymous, but it is good to know this is not always the case.
通过引用Webpack词汇表,这篇文章最好地解释了包和块之间的区别 。 现在我们可以说,当我们创建新的代码分割点时,我们创建了新的块,然后将这些块用于输出最终的包。 它们通常具有1:1映射,因此看起来是同义词,但是很高兴知道并非总是如此。
动态导入语法 (Dynamic import syntax)
Webpack ‘dynamic imports’ import a module as a runtime Promise, rather than the standard static build time module import. The syntax follows the ECMAScript proposal for adding import() to the core language, but it is currently Webpack specific.
Webpack的“动态导入”将模块作为运行时Promise导入,而不是标准的静态构建时模块导入。 该语法遵循ECMAScript提议,用于将import()添加到核心语言,但是当前特定于Webpack。
The React docs and Webpack docs have examples of this in its base form:
React文档和Webpack文档以其基本形式包含以下示例:
Before:
之前:
import { add } from './math';console.log(add(16, 26));After:
后:
import("./math").then(math => {
console.log(math.add(16, 26));
});This allows it to be handled asynchronously, requested at runtime from a user’s browser. When import() is used Webpack creates a new chunk for the imported code, splitting it from the main bundle. We need to handle its use knowing it will not be immediately available (it sends a separate network request), thinking about network errors and loading states.
这允许它在运行时从用户浏览器请求异步处理。 使用import() ,Webpack会为导入的代码创建一个新块,并将其与主捆绑包分开。 考虑到网络错误和加载状态,我们需要知道它不会立即可用(它发送单独的网络请求),以处理它的使用。
Handling Promises all over our app using .then() is a lot of mental overhead, and so for React specifically several libraries have been created that allow us to do this more efficiently. We will use @loadable/component here.
使用.then()在我们的应用程序中处理Promises的.then()很大,因此对于React来说,已经专门创建了多个库,这些库使我们可以更高效地执行此操作。 我们将在这里使用@loadable/component 。
If the first could be termed an ‘inline import()' the second could be an ‘assigned import()'.
如果第一个可以称为“内联import() ”,第二个可以称为“已分配import() ”。
import loadable from '@loadable/component';const OtherComponent = loadable(() => import(../components/OtherComponent'));// then within current component using normal component syntax...<OtherComponent />Libraries that allow us to pass in an import() statement in this way generally have guidance or APIs that show good error and loading practices.
允许我们以这种方式传递import()语句的库通常都具有指导或API,这些指南或API表现出良好的错误和加载惯例。
可加载组件 (Loadable Components)
The three most popular libraries for handling dynamic imports are React.lazy, @loadable/component, and react-loadable.
用于处理动态导入的三种最受欢迎的库是React.lazy , @loadable/component和react-loadable 。
React.lazy is part of React itself and is paired with <Suspense>, but is not recommended to use in production applications (though there is nothing technically stopping you). It does not support Server Side Rendering (SSR)
React.lazy是React本身的一部分,并与<Suspense>配对,但是不建议在生产应用程序中使用 (尽管从技术上讲,没有什么可以阻止您的)。 它不支持服务器端渲染(SSR)
The React team recommend @loadable/component as a third party solution that does support SSR and is production ready. It can be used with <Suspense> or have a fallback specified via a prop. In addition it supports code splitting of libraries, not just React components.
React团队推荐 @loadable/component作为第三方解决方案,该解决方案确实支持SSR并已投入生产。 它可以与<Suspense>一起使用,或者具有通过prop指定的后备 。 另外,它支持库的代码拆分,而不仅仅是React组件。

react-loadable is a very popular older third party library that also supports SSR. However it is now unmaintained, and has even closed the ability to raise new GitHub issues. The documentation around code splitting in its README is still excellent contextual reading however.
react-loadable是一个非常流行的较旧的第三方库,它也支持SSR。 但是,它现在无法维护,甚至已经关闭了引发新GitHub问题的功能。 但是,自述文件中有关代码拆分的文档仍然是出色的上下文阅读。
We are going to use Loadable Components here.
我们将在这里使用可加载组件。
命名块 (Naming chunks)
Webpack allows ‘magic comments’ to be placed within an import() statement. Multiple of these can be used in a comma separated list. One of these is webpackChunkName, which can be used to give a meaningful name to the output chunk.
Webpack允许将“ 魔术注释 ”放置在import()语句中。 其中的多个可以在逗号分隔的列表中使用。 其中之一是webpackChunkName ,可用于为输出块赋予有意义的名称。
For example, this import:
例如,此导入:
import(/* webpackChunkName: “LargeComponent” */ ‘../LargeComponent’);Would result in this chunk:
将导致此块:
build/static/js/LargeComponent.f391f849.chunk.jsWithout the webpackChunkName hint, we get a anonymous chunk ID which is difficult to identify:
如果没有webpackChunkName提示,我们将获得一个匿名块ID,该ID很难识别:
build/static/js/9.f391f849.chunk.jsLoadable Components assigns meaningful chunk names without this comment needing to be used, but are still compatible with it if we wanted to specify a different one.
可加载组件可分配有意义的块名称,而无需使用此注释,但如果我们要指定其他名称,则仍可与之兼容。
Examples here that use Loadable Components will not use webpackChunkName, as the autogenerated one is generally exactly what we want.
这里使用可加载组件的示例将不使用webpackChunkName ,因为自动生成的通常正是我们想要的。
策略 (Strategies)

There are four main ways of choosing where to code split within your application; route based, component at render time based, component behind an event handler based, and library use based.
选择应用程序中在何处进行代码拆分的方法主要有四种: 基于路由,基于渲染时间的组件,基于事件处理程序的组件以及基于库使用的组件。
Another strategy is Vendor chunking. This is an automatic strategy to pull out common node module dependencies into a ‘vendors’ chunk that is also used (and advised) but will not be covered here. It is enabled by default in Create React App, though a future post may look at how to customise this further.
另一个策略是供应商分块。 这是一种自动策略,可以将公共节点模块的依赖关系拉入“供应商”块,该块也已使用(并建议使用),但此处将不介绍。 默认情况下,它在Create React App中处于启用状态 ,尽管以后的文章可能会探讨如何进一步自定义。
基于路线 (Route based)
This is the easiest to achieve and can have a large immediate impact. A routing file and app entry point is needed by all users, but then depending on their URL a different bundle is requested. The experience of waiting for a page to load is familiar, so any latency requesting the second page’s bundle on navigation is not jarring to the user.
这是最容易实现的,并且会立即产生很大的影响。 所有用户都需要一个路由文件和应用程序入口点,但是然后根据他们的URL请求一个不同的捆绑包。 等待页面加载的经验很熟悉,因此,请求第二页捆绑导航的任何延迟都不会对用户造成影响。
If you were using React Router the split points could look like:
如果您使用的是React Router,则拆分点可能如下所示:
const Homepage = loadable(() => import('../Homepage'));
const SearchResults = loadable(() => import('../SearchResults'));
const Help = loadable(() => import('../Help'));
const DefaultRoute = loadable(() => import('../DefaultRoute'));const Routes = ({ history }) => (
<Router history={history}>
<Switch>
<Route exact path={HOMEPAGE} component={Homepage} />
<Route exact path={SEARCH} component={SearchResults} />
<Route exact path={HELP} component={Help} />
<Route render={() => <DefaultRoute />} />
</Switch>
</Router>
);export default Routes;A user landing on the homepage and making a search would never download the bundles for the help or default page, and so not suffer the performance hit of downloading and parsing unneeded JavaScript.
登陆到首页并进行搜索的用户将永远不会下载用于帮助或默认页面的捆绑软件,因此不会遭受下载和解析不需要JavaScript所带来的性能损失。
When landing on the homepage (or whatever their first page may be) they download the main bundle that includes the Routes component, and a second bundle containing the Homepage route when the matching <Route> renders. As the other routes do not match, so do not execute a render, their bundles are not requested.
当着陆在主页上(或任何其第一页而定)下载它们的主束,其包括Routes组件,和包含一个第二束Homepage路线当匹配<Route>渲染。 由于其他路径不匹配,因此不执行渲染,因此不请求它们的束。
If then moving to the SearchResults URL the new route would match, render, and the new bundle would be requested.
如果然后移至SearchResults URL,则新路线将匹配,呈现并请求新的捆绑包。
基于组件 (Component based)
We can further optimise by splitting out individual components. This may be UI element that are initially not visible (modals, drawers, below-the-fold content) or that are not as high priority for the user (they can wait to see it without their experience suffering).
我们可以通过拆分单个组件来进一步优化。 这可能是最初不可见的UI元素(模式,抽屉,折叠式内容),或者对用户而言不是很高的优先级(他们可以等待看到它,而不会遇到任何痛苦)。
If these components are large then splitting them into separate chunks may make the central experience better as the central content loads faster.
如果这些组件很大,则将它们拆分为单独的块可以使中央体验更好,因为中央内容的加载速度更快。
However, be aware that this comes at a degradation of the loading experience of the second component — that modal will take slightly longer to load, or that lower priority component may have an initial loading spinner.
但是,请注意,这会降低第二个组件的加载体验—加载模式所需的时间会稍长一些,或者优先级较低的组件可能具有初始加载微调器。
The decisions of when this makes sense or not are entirely dependant on your specific app and the experience you prioritise. Do you want the first load to be faster, or do you want completely seamless navigation when moving around the page? A balance somewhere between the two is most common.
何时才有意义的决定完全取决于您的特定应用程序和您优先考虑的经验。 您希望第一次加载更快,还是要在页面上移动时完全无缝导航? 两者之间的某种平衡是最常见的。
Again the react-loadable documentation provides some great considerations here, despite it no longer being a recommended package due to no longer receiving updates.
尽管由于不再接收更新而不再是推荐的软件包,但react-loadable文档再次在此处提供了一些重要的注意事项。
One of these is to make sure to avoid flashes of loading components. A loading component shown for <200ms is more harmful to the perception of speed that showing nothing at all, and this should be taken into consideration when implementing loading states.
其中之一是确保避免加载组件闪烁 。 所示的小于200ms的加载组件对速度感知(根本什么也不显示)的危害更大,在实现加载状态时应考虑这一点。
Component based route splitting falls into two types: at render time and behind a DOM event.
基于组件的路由拆分分为两种类型:渲染时和DOM事件之后 。
At render time
在渲染时
The simplest form this could take is a large component at the bottom of the page being split out as below.
这可能采取的最简单形式是,页面底部的大组件如下所示。
import React from 'react';
import loadable from '@loadable/component';import ComponentOne from '../ComponentOne'
import ComponentTwo from '../ComponentTwo'import STYLES from './Homepage.scss';const ComponentThree = loadable(() => import('./ComponentThree'));const Homepage = () => (
<div className={STYLES.container}>
<ComponentOne />
<ComponentTwo />
<ComponentThree fallback={<div>Loading...</div>}/>
</div>
);The downloaded JavaScript for the bundle containing this page will not contain ComponentThree and instead when this file is executed the new bundle generated by the ComponentThree dynamic import will be requested. While waiting on the Promise to resolve (when the response is received) the fallback component will be shown.
为包含此页面的捆绑软件下载JavaScript将不包含ComponentThree ,而是当执行此文件时,将请求由ComponentThree动态导入生成的新捆绑软件。 在等待Promise解决(接收到响应)时,将显示后备组件。
On events
活动中
A component that is not shown until an event is triggered, for example a button click, can be even further split behind that event.
直到事件触发(例如按钮单击)才显示的组件甚至可以在该事件之后进一步拆分。
The advantage here is if the button if never clicked no request is even made, the disadvantage being the wait time if it is clicked. This can be optimised in some browsers using a ‘prefetch’ hint (covered later) but this does not work for all browsers. One additional strategy seen is, on desktop, to request the chunk on mouseover. You can see this navigating around the current Facebook desktop UI if you open the network tab and move the cursor around the page. On mobile however, where performance has the most impact, this has no effect.
这样做的好处是,如果按钮从未被单击过,甚至没有请求,那么缺点是等待时间被单击。 可以在某些浏览器中使用“预取”提示(稍后介绍)进行优化,但这不适用于所有浏览器。 在桌面上看到的另一种策略是在鼠标悬停时请求块。 如果打开“网络”选项卡并在页面上移动光标,则可以在当前的Facebook桌面UI上浏览。 但是,在性能影响最大的移动设备上,这没有影响。
Once the component is resolved the app then needs access to it to render it — unlike the component in the above example that was declared inline. One way of doing this is to store the component in state, and conditionally render the app based on it being there or not.
解决了组件后,应用程序需要访问它才能呈现它-与上述示例中声明为内联的组件不同。 一种方法是将组件存储在状态中,并根据是否存在状态有条件地渲染该应用程序。
A simple example of this is provided by Enmanuel Durán. This could look like:
EnmanuelDurán提供了一个简单的示例 。 可能看起来像:
import React, { useState } from 'react';
import loadable from '@loadable/component';import ComponentOne from '../ComponentOne';import STYLES from './Homepage.scss';const Homepage = () => {
const [dynamicComponentThree, setDynamicComponentThree] = useState(null);return (
<div className={STYLES.container}>
<ComponentOne />
<button
type="button"
onClick={async () => {
const ComponentThree = await loadable(() => import('./ComponentThree')); setDynamicComponentThree(ComponentThree);
}}
/>
{dynamicComponentThree && <DynamicComponentThree />}
</div>
);
};Please add any other good examples of this as comments to this post.
请为此添加其他任何好的示例作为注释。
基于图书馆 (Library based)
The final method is to split out large libraries that are not on the critical path of the app, requesting them just before they are actually needed.
最终的方法是拆分不在应用程序关键路径上的大型库,并在实际需要它们之前就请求它们。
This could be a library used for fetching advert data for example. Using inline imports and Promise chaining, or loadable.lib, these could be split out from the main app and the result of using them applied asynchronously.
例如,这可能是用于获取广告数据的库。 使用内联导入和Promise链或loadable.lib ,可以将它们与主应用程序分开,并且异步使用它们的结果。
This is the least common of all the above, but it is worth knowing it is possible. A future post may look more at this.
这是以上所有方法中最不常见的,但是值得知道这是有可能的。 以后的文章可能会更多地关注这一点。
导入级联 (Import cascades)
In the examples above we looked at one level deep of code splitting, e.g. a Route that import()s a screen. But what if that screen we import also has code split points within it?
在上面的示例中,我们研究了代码拆分的较深层次,例如,路线import()屏幕。 但是,如果我们导入的屏幕中也包含代码分割点,该怎么办?
If we combined the Route and component based splitting from the examples above we would have:
如果将上面示例中的Route和基于组件的拆分相结合,我们将获得:
Routes.jsconst Homepage = loadable(() => import('../Homepage'));
const SearchResults = loadable(() => import('../SearchResults'));
const Help = loadable(() => import('../Help'));
const DefaultRoute = loadable(() => import('../DefaultRoute'));const Routes = ({ history }) => (
<Router history={history}>
<Switch>
<Route exact path={HOMEPAGE} component={Homepage} />
<Route exact path={SEARCH} component={SearchResults} />
<Route exact path={HELP} component={Help} />
<Route render={() => <DefaultRoute />} />
</Switch>
</Router>
);
Homepage.jsimport React from 'react';
import loadable from '@loadable/component';import ComponentOne from '../ComponentOne'
import ComponentTwo from '../ComponentTwo'import STYLES from './Homepage.scss';const ComponentThree = loadable(() => import('./ComponentThree'));const Homepage = () => (
<div className={STYLES.container}>
<ComponentOne />
<ComponentTwo />
<ComponentThree fallback={<div>Loading...</div>}/>
</div>
);The code split points map to:
代码拆分点映射到:
- (A) Routes, renders:
- (B) Homepage, renders:
- (C) ComponentThree
- (D) SearchResultsIf a user lands on a Homepage URL then:
如果用户登陆主页URL,则:
- (A) will download, parse, and execute: this initiates the request for (B) as it matches that route (A)将下载,解析并执行:这将触发(B)与该路由匹配的请求
- (B) will download, parse, and execute: this initiates the request for (C) as it is not gated behind anything (interaction, switch statement) (B)将下载,解析并执行:这将启动对(C)的请求,因为它没有在任何事物后面进行交互(交互,switch语句)
- (D) will not be downloaded, as the JS in (A) never executes (renders) it (D)不会下载,因为(A)中的JS永远不会执行(渲染)它
We will look in a moment at how we could download (D) if we wanted to in a deliberate way using prefetch/preload.
稍后,我们将探讨如果要使用预取/预加载来故意下载(D)。
If inline imports ( import() not passed in to a function) were used then all bundles would be downloaded, as since they are not gated behind a function being invoked they would trigger at parse time. This is a side effect to be aware of rather than a strategy to adopt.
如果使用内联导入( import()未传递到函数中),则将下载所有捆绑包,因为由于未在调用的函数后面设置它们,因此将在解析时触发。 这是要注意的副作用,而不是要采用的策略。
预取/预加载资源提示 (Prefetch/Preload resource hints)

‘prefetch’ and ‘preload’ are resource hints that can be added to the HTML link element. Webpack allows these to be specified at chunk declaration time using webpackPrefetch and webpackPreload magic comments.
“ prefetch”和“ preload”是可以添加到HTML link元素的资源提示。 Webpack允许使用webpackPrefetch和webpackPreload 魔术注释在块声明时指定这些内容。
The webpack docs explain the differences here quite well, but what is important to remember is that they are hints; not all browsers support them and they should be relied on as part of a core chunking strategy. They are a value add, not part of the core proposition.
Webpack文档在这里很好地解释了这些差异,但是要记住的重要一点是它们是提示 。 并非所有浏览器都支持它们,因此应该将它们作为核心分块策略的一部分。 它们是附加值,不是核心主张的一部分。
It’s worth noting that in my experience when experimenting with adding these hints in different places locally it was necessary to stop and restart the webpack dev server (ran with npm start in a Create React App app) to remove these — a frustrating lesson learning that on deleting a webpackPrefetch it was still being prefetched. Hopefully this is a ‘my machine’ problem, but worth testing.
值得注意的是,根据我的经验,尝试在本地不同位置添加这些提示时,有必要停止并重新启动webpack开发服务器(在Create React App应用程序中使用npm start来运行)以删除这些提示,这令人沮丧删除一个webpackPrefetch它仍然被预取。 希望这是一个“我的机器”问题,但值得测试。

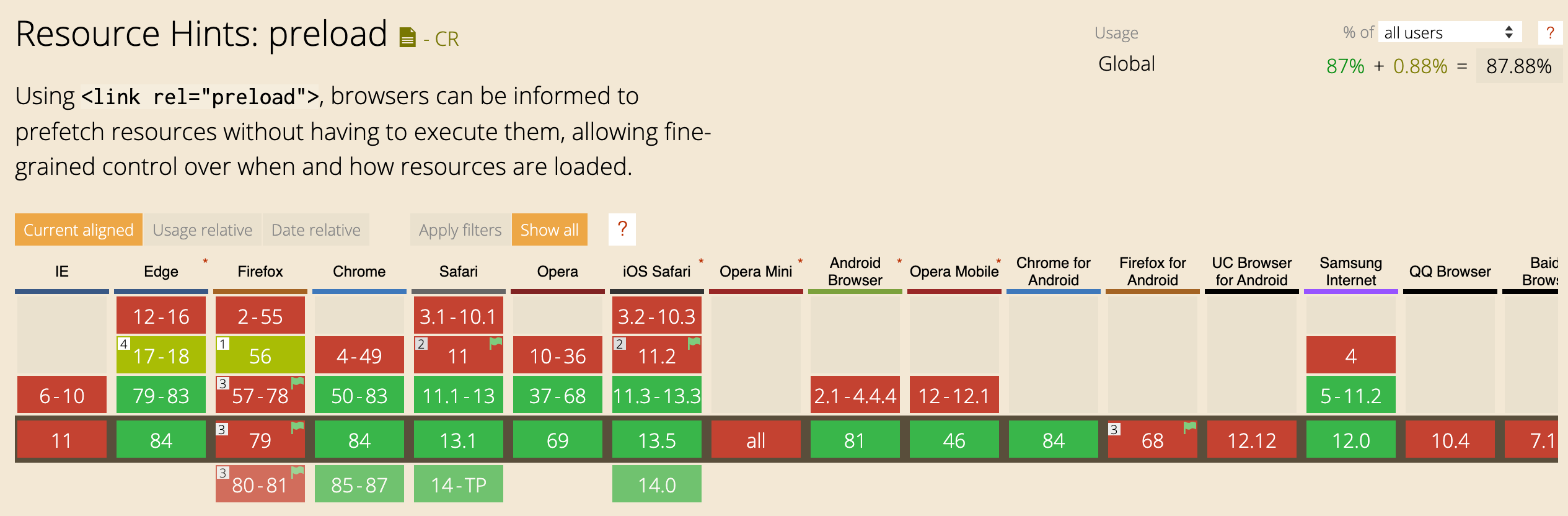
At the time of writing prefetch has no support in Safari, and preload has no support in Firefox.
在撰写本文时,Safari不支持预取,而Firefox不支持预载。
These do not mean they should not be used, just that they should not be relied on.
这些并不意味着不应该使用它们,而只是不应该依赖它们。
They are defined in the Webpack docs as:
它们在Webpack文档中定义为:
- prefetch: resource is probably needed for some navigation in the future, fetches in network idle time prefetch:将来可能需要一些导航资源,以获取网络空闲时间
- preload: resource might be needed during the current navigation, fetches at the same time 预加载:在当前导航期间可能需要资源,同时获取
- A preloaded chunk starts loading in parallel to the parent chunk. A prefetched chunk starts after the parent chunk finishes loading. 预加载的块开始并行于父块加载。 父块完成加载后,将开始预提取块。
- A preloaded chunk has medium priority and is instantly downloaded. A prefetched chunk is downloaded while the browser is idle. 预加载的块具有中等优先级,可以立即下载。 浏览器空闲时,将下载预提取的块。
- A preloaded chunk should be instantly requested by the parent chunk. A prefetched chunk can be used anytime in the future. 父块应立即请求预加载的块。 预取的块可以在将来的任何时候使用。
- Using webpackPreload incorrectly can actually hurt performance, so be careful when using it. 错误地使用webpackPreload实际上会影响性能,因此使用时请务必小心。
预取 (Prefetch)
const OtherComponent = loadable(() =>
import(/* webpackPrefetch: true */ './OtherComponent'),
);The above would trigger a prefetch of the bundle at the time the file containing it was executed.
上面的代码将在执行包含捆绑软件的文件时触发该捆绑软件的预取。
It does this by adding a link to the head of the document, which then triggers a request. This means there are two areas to look to see if it is working — the head and the network panel.
它通过在文档的开头添加一个link来完成此操作,然后触发一个请求。 这意味着需要检查两个区域是否正常工作—机头和网络面板。
It is important to note that the Webpack docs refer to it being used to load a component that is hidden behind an interaction handler — i.e. a component that is loaded only on being clicked. This is a great use case.
重要的是要注意,Webpack文档指的是它用于加载隐藏在交互处理程序后面的组件,即仅在单击时才加载的组件。 这是一个很好的用例。
const [dynamicComponentThree, setDynamicComponentThree] = useState(null);return (
<div className={STYLES.container}>
<ComponentOne />
<button
type="button"
onClick={async () => {
const ComponentThree = await loadable(() => /* webpackPrefetch: true */ import('./ComponentThree'));setDynamicComponentThree(ComponentThree);
}}
/>
{dynamicComponentThree && <DynamicComponentThree />}
</div>
);
};Here when the file is parsed the prefetch is assigned to the ComponentThree chunk, meaning it has a chance to be already downloaded if it is clicked on (if there has been browser idle time to do it in).
在这里,当文件被解析时,预取被分配给ComponentThree块,这意味着如果单击它(如果有浏览器空闲时间可以下载文件),它就有可能已经被下载。
Using our Routes example from before, imagine we updated to:
使用之前的“路线”示例,假设我们已更新为:
Routes.jsconst Homepage = loadable(() => /* webpackPrefetch: true */ import('../Homepage'));
const SearchResults = loadable(() => import('../SearchResults'));const Routes = ({ history }) => (
<Router history={history}>
<Switch>
<Route exact path={HOMEPAGE} component={Homepage} />
<Route exact path={SEARCH} component={SearchResults} />
</Switch>
</Router>
);If a user landed on Homepage this would have no impact, the prefetch would be picked up at the time Routes.js was executed, but the Homepage component would be matched and executed before the prefetch had any time to be useful.
如果用户登陆到Homepage上不会产生任何影响,则在执行Routes.js时将进行预取,但是Homepage组件将被匹配并在预取有任何可用时间之前执行。
However, if a user landed on SearchResults then the prefetch (for browsers that support it) would fetch the other chunk in idle time — useful if there is a strong likelihood that in our app a user would go to that page next.
但是,如果用户登陆到SearchResults,则预取(对于支持它的浏览器)将在空闲时间内获取其他块-如果很有可能用户在我们的应用程序中接下来将转到该页面,则很有用。
Firefox is the best browser for seeing if this is working, as it helpfully adds a X-moz: prefetch header to any prefetched request.
Firefox是查看它是否有效的最佳浏览器,因为它有助于在任何预取请求中添加X-moz: prefetch标头。
Chrome currently seems flakey for honouring this hint, despite claiming to have full support. It is always possible to see Webpack add it to the head, but Chrome does not always initiate a request.
尽管声称有全力支持,Chrome当前似乎很荣幸兑现这一提示。 总是可以看到Webpack将其添加到头部,但是Chrome并不总是启动请求。
预载 (Preload)
This is the more aggressive of the two, and can harm performance if over used for pages a user does not actually visit. Say we preloaded all the routes in Routes.js — it seems unlikely a user will visit all of these, so we have clogged up network and parse time for bundles that will not be used.
这是两者中比较激进的一种,如果过度使用了用户实际上未访问的页面,则会损害性能。 假设我们在Routes.js中预加载了所有路由-用户似乎不太可能访问所有这些路由,因此我们已经阻塞了网络并解析了将不使用的捆绑包的时间。
However, say the Homepage was made of two large components, it may be useful to download these in parallel — so creating two chunks and preloading them could result in a better experience. This is application specific knowledge of your user patterns.
但是,假设首页是由两个大组件组成的,则并行下载它们可能会很有用-因此创建两个块并将它们预加载可以带来更好的体验。 这是您的用户模式的特定于应用程序的知识。
If you remember how we mentioned doing inline imports in the ‘Import cascades’ section we can see this is a manual, cross browser support, way of essentially triggering preload behaviour. When this is parsed it will immediately be executed, starting a network request. This is not however recommended as it is not semantically clear why it is being done.
如果您还记得在“导入级联”一节中提到过进行内联导入的方式,我们可以看到这是一种手动的,跨浏览器的支持,实质上是触发预加载行为的方式。 解析后,将立即执行,启动网络请求。 但是不建议这样做,因为在语义上尚不清楚为什么要这样做。
Loadable Components has an extra trick here to get around inconsistent browser support.
可加载组件在这里还有一个额外的技巧,可以避免浏览器支持不一致。
const OtherComponent = loadable(() =>
import('./OtherComponent'),
);OtherComponent.preload()It has a cross browser supported .preload() that can be used to force a network request — more consistent than using the webpackPreload magic comment if you happen to be using this library.
它具有跨浏览器支持的.preload() ,可用于强制网络请求-如果您恰巧正在使用此库,则比使用webpackPreload魔术注释更一致。
最后的想法 (Final Thoughts)
Creating different bundles is an extremely powerful way of increasing performance for your users. It benefits everyone, but particularly those on low powered mobile devices on non 4G networks — on slower networks large bundles can render apps completely unusable.
创建不同的捆绑包是提高用户性能的一种非常强大的方法。 它使所有人受益,尤其是那些非4G网络上低功耗移动设备上的设备-在较慢的网络上,大捆绑包可能会使应用程序完全无法使用。
There is also a monetary cost to your users of downloading data — which again can exclude the less privileged of us.
您的用户在下载数据时也要付出金钱的代价 -这又可以排除我们特权较少的人。
There are some very easy wins for nearly all applications (Route based splitting) as well as micro optimisations for those with the time available (prefetching).
几乎所有应用程序(基于路由的拆分)都有一些非常轻松的优势,而那些可用时间(预取)的应用程序则可以进行微优化。
Where exactly to split your app and how to handle the split points is a choice individual to your app — you know your users best and what is important to them at any point in a given flow.
应用程序的具体选择是在哪里精确拆分应用程序以及如何处理拆分点-您最了解用户,并且在给定流程中的任何时候对用户而言重要的是什么。
Hopefully this helps with how to define the split points, and links to other posts or resources are completely welcomed as comments.
希望这有助于如何定义分割点,并链接到其他岗位或资源完全欢迎的意见。
Thanks for reading!
谢谢阅读!
webpack代码拆分















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









