





apache kafka
Apache Kafka is a distributed streaming platform with a lot of use cases including acting as a message broker between your applications and processes. Today, We’ll look at how we can implement a publisher/subscriber model with Apache Kafka using Node.js!
Apache Kafka是一个分布式流平台,具有许多用例,包括充当您的应用程序和进程之间的消息代理。 今天,我们将探讨如何使用Node.js在Apache Kafka上实现发布者/订阅者模型!
Apache Kafka的基本概念 (Basic Concepts of Apache Kafka)
Before we proceed with the code it is important to understand the basic concepts of Apache Kafka. Fortunately, there’s already tons of excellent resources available online that explain the basic concepts way better than I ever can!
在继续进行代码之前,了解Apache Kafka的基本概念很重要。 幸运的是,在线上已经有大量优秀的资源可以比我更好地解释基本概念!
This read up on Consumer Groups since that plays a major role in our pub/sub model
Do go through these before proceeding further in case you’re not aware of the underlying concepts of Kafka!
如果您不了解Kafka的基本概念,请在继续进行之前仔细阅读这些内容!
用例 (The Use Case)
Let's say we have an eCommerce website where every time a customer checks out an order, an event “orderCreated” will be generated. This event will be listened to by the following services:
假设我们有一个电子商务网站,每当客户签出订单时,都会生成一个“ orderCreated”事件。 以下服务将监听此事件:
Orders Service: This service is responsible for adding the order details to the Database
订单服务 :此服务负责将订单详细信息添加到数据库中
Payments Service: This service is responsible for deducting credits from the Customer’s wallet
付款服务 :此服务负责从客户的钱包中扣除信用额
Notifications Service: This service is responsible for notifying the customer that their order has been placed successfully.
通知服务 :此服务负责通知客户他们的订单已成功下达。
We can do these operations asynchronously in the background — The benefit of doing so is that we can quickly send a response back to the customer with the actual work being done in the background.
我们可以在后台异步执行这些操作-这样做的好处是,我们可以在后台完成实际工作的情况下Swift将响应发送回客户。
Now, there are 2 key challenges here:
现在,这里有两个主要挑战:
We want our messages to be processed at least once. The listeners need to acknowledge that they’ve processed the events. In case a consumer service fails to process an event successfully, the event needs to be retried. For example, we cannot afford to lose events of credits that need to be deducted from customers wallets. (Customers getting their orders for free!)
我们希望我们的消息至少被处理一次。 侦听器需要确认他们已经处理了事件。 如果使用者服务无法成功处理事件,则需要重试该事件。 例如,我们无法承受需要从客户钱包中扣除的信用事件的损失。 (客户免费获得订单!)
We also want our messages to be processed at most once. In today’s era, We usually have a lot of instances of our application running behind a load balancer. This means that in our scenario, There will be multiple instances of the payment service (as well as others) running. Therefore, we don’t want the event to be processed by each instance. (Customers getting charged double or triple times the order amount!)
我们还希望我们的消息最多处理一次。 在当今时代,我们通常有很多应用程序实例在负载均衡器后面运行。 这意味着在我们的方案中,将有多个支付服务实例(以及其他实例)在运行。 因此,我们不希望每个实例都处理该事件。 (向客户收取的费用是订单金额的两倍或三倍!)
Let's see how we can achieve this with Kafka!
让我们看看如何用Kafka做到这一点!
使用Docker设置Kafka (Setting up Kafka with Docker)
I will once again recommend an excellent piece of article here that I used myself for setting up Kafka locally with Docker.
我会在这里再次推荐一篇很棒的文章,我用我自己在Docker本地设置Kafka。
How to install Kafka using Docker
Here’s an updated version of the docker-compose.yml file:
这是docker-compose.yml文件的更新版本:
version: '3.7'
networks:
kafka-net:
driver: bridge
services:
zookeeper-server:
image: 'bitnami/zookeeper:latest'
networks:
- kafka-net
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka-server1:
image: 'bitnami/kafka:latest'
networks:
- kafka-net
ports:
- '9092:9092'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper-server:2181
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
- ALLOW_PLAINTEXT_LISTENER=yes
depends_on:
- zookeeper-serverJust run docker-compose up in the terminal and the kafka server should start running!
只需在终端中运行docker-compose up kafka服务器应开始运行!
You can set up Conduktor as well in case you want to set up a desktop client.
如果您要设置桌面客户端,也可以设置Conduktor 。
编写代码的时间到了! (Time to Code!)
We’ll be using a package called kafkajs in order to interact with Kafka from Node.js.
我们将使用一个名为kafkajs的软件包,以便与Node.js中的Kafka进行交互。
As a first step, We’ll need to create a topic
orderCreatedwhich will be used by publishers and subscribers.第一步,我们需要创建一个主题
orderCreated,供发布者和订阅者使用。
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092']
});
const topicName = 'orderCreated';
const process = async () => {
const admin = kafka.admin();
await admin.connect();
await admin.createTopics({
topics: [{
topic: topicName,
numPartitions: 2,
replicationFactor: 1
}
],
});
await admin.disconnect();
};
process().then(() => console.log('done'));The main point to note here is the number of partitions — Which we’ve currently set to 2. The reason behind this will become clear as we proceed.
这里要注意的要点是分区的数量-我们目前已将其设置为2。随着我们的进行,其背后的原因将变得显而易见。
Copy and run this code as is and if everything runs perfectly, the console should output done indicating that the topic has been created. If you have conduktor set up, you can verify this as well:
按原样复制并运行此代码,如果一切正常运行,则控制台应输出done表明已创建该主题。 如果您已设置调节器,则也可以验证以下内容:
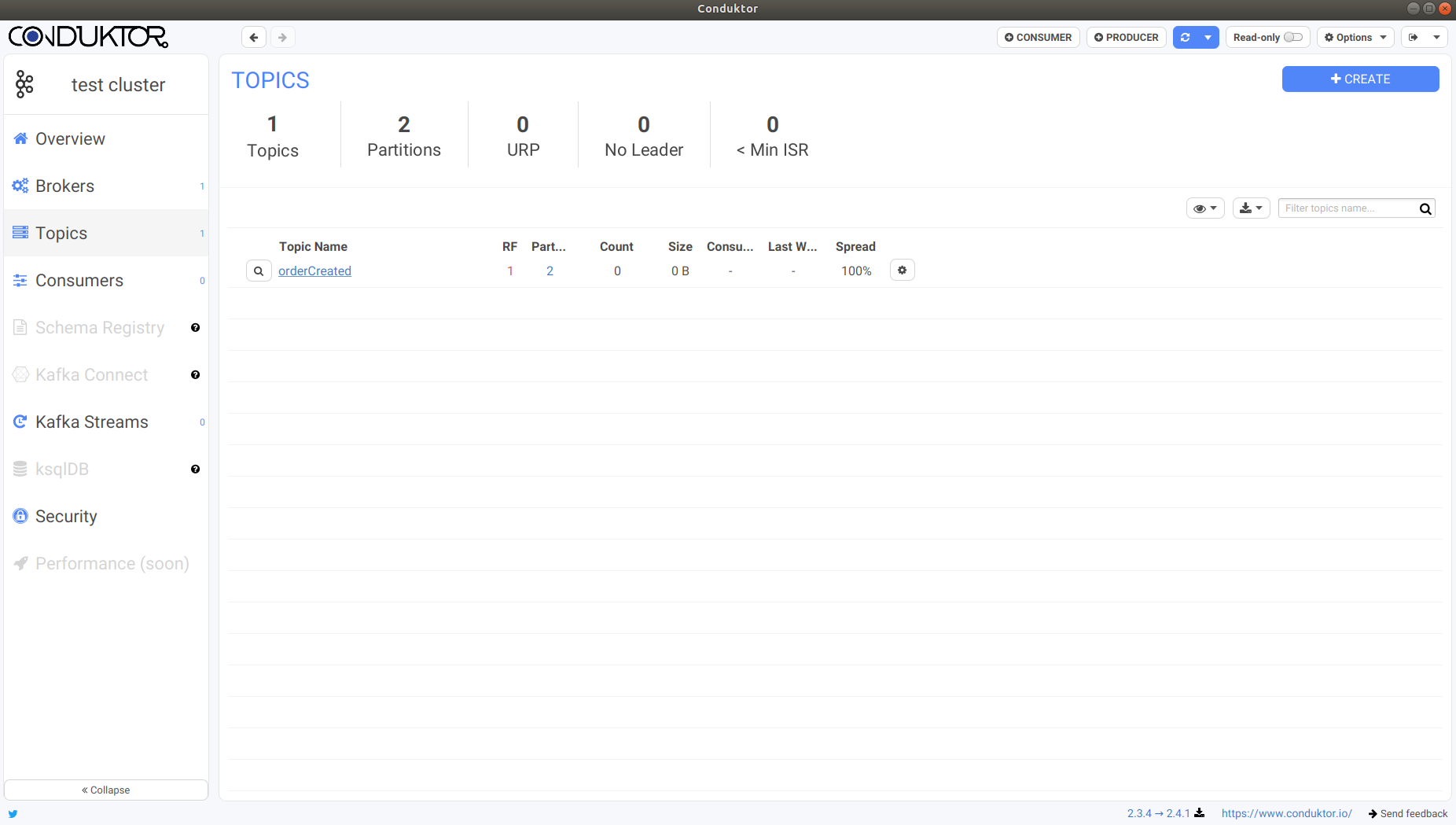
2. The next step is to write a consumer that will subscribe to this topic and listen for events.
2.下一步是编写一个将订阅该主题并监听事件的使用者。
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092']
});
const topicName = 'orderCreated';
const consumerNumber = process.argv[2] || '1';
const processConsumer = async () => {
const ordersConsumer = kafka.consumer({groupId: 'orders'});
const paymentsConsumer = kafka.consumer({groupId: 'payments'});
const notificationsConsumer = kafka.consumer({groupId: 'notifications'});
await Promise.all([
ordersConsumer.connect(),
paymentsConsumer.connect(),
notificationsConsumer.connect(),
]);
await Promise.all([
await ordersConsumer.subscribe({ topic: topicName }),
await paymentsConsumer.subscribe({ topic: topicName }),
await notificationsConsumer.subscribe({ topic: topicName }),
]);
let orderCounter = 1;
let paymentCounter = 1;
let notificationCounter = 1;
await ordersConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
logMessage(orderCounter, `ordersConsumer#${consumerNumber}`, topic, partition, message);
orderCounter++;
},
});
await paymentsConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
logMessage(paymentCounter, `paymentsConsumer#${consumerNumber}`, topic, partition, message);
paymentCounter++;
},
});
await notificationsConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
logMessage(notificationCounter, `notificationsConsumer#${consumerNumber}`, topic, partition, message);
notificationCounter++;
},
});
};
const logMessage = (counter, consumerName, topic, partition, message) => {
console.log(`received a new message number: ${counter} on ${consumerName}: `, {
topic,
partition,
message: {
offset: message.offset,
headers: message.headers,
value: message.value.toString()
},
});
};
processConsumer();Before executing this code, let's understand a bit what’s happening here.
在执行此代码之前,让我们了解一下这里发生的情况。
At the start of the process function, we’re creating 3 consumers to simulate our 3 services namely ordersConsumer, paymentsConsumer and notificationsConsumer. The groupId specifies the consumer group that these consumers will be a part of.
在process功能的开始,我们将创建3个使用者来模拟我们的3个服务,即ordersConsumer , paymentsConsumer和notificationsConsumer 。 groupId指定这些使用者将成为其一部分的使用者组。
Adding the 3 consumers to 3 different consumer groups will ensure that all the 3 consumers will get the messages (which is what we want). If we add all the consumers to the same group then only one of these will get the message.
将3个消费者添加到3个不同的消费者组将确保所有3个消费者都将收到消息(这是我们想要的)。 如果我们将所有使用者添加到同一组中,那么只有其中一个会收到消息。
Next we subscribe the consumers to our topic “orderCreated” .
接下来,我们使消费者订阅我们的主题“orderCreated” 。
Finally, we start the consumers with.run which enables them to listen to any messages that are published on their subscribed topics. Each consumer does a simple job of logging the message that they receive.
最后,我们使用.run启动使用者,这使他们能够收听在其订阅主题上发布的所有消息。 每个使用者都可以简单地记录他们收到的消息。
The consumer file also expects a command-line argument which tells us the consumer number. Since these are our first consumers, let's execute this script asnode mediumConsumer.js 1 .
使用者文件还需要一个命令行参数来告诉我们使用者编号。 由于这些是我们的第一个使用者,因此让我们将此脚本作为node mediumConsumer.js 1执行。
If everything works fine, we should see a lot of logs from Kafka saying that consumers have joined the group. This can be verified from Conduktor as well:
如果一切正常,我们应该会看到卡夫卡(Kafka)的很多日志说消费者已经加入了该小组。 这也可以从Conduktor进行验证:

One log that is important to note here is this one:
这里需要重点注意的一本日志是:
{"level":"INFO","timestamp":"2020-08-17T14:54:40.237Z","logger":"kafkajs","message":"[Runner] Consumer has joined the group","groupId":"notifications","memberId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","leaderId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","isLeader":true,"memberAssignment":{"orderCreated":[0,1]},"groupProtocol":"RoundRobinAssigner","duration":20}Under memberAssignment, We see that both of our partitions (0, 1) are assigned to this single consumer i.e. any message that lands on either of these partitions will be received by this consumer. This log is for our “notifications” consumer. We should see the same log for the remaining consumers as well.
在memberAssignment下,我们看到我们的两个分区(0,1)均已分配给该单个使用者,即,落在这些分区中的任何一个上的任何消息都将被该使用者接收。 该日志供我们的“通知”使用者使用。 对于其余的使用者,我们也应该看到相同的日志。
3. The final step is to write the publisher that will publish our messages:
3.最后一步是编写将发布我们的消息的发布者:
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092']
});
const topicName = 'orderCreated';
const msg = JSON.stringify({customerId: 1, orderId: 1});
const processProducer = async () => {
const producer = kafka.producer();
await producer.connect();
for (let i = 0; i < 3; i++) {
await producer.send({
topic: topicName,
messages: [
{ value: msg },
],
});
}
};
processProducer().then(() => {
console.log('done');
process.exit();
});The publisher’s code is very straightforward. We initialize a producer, connect it, and then send 3 messages on our topic in a loop.
发布者的代码非常简单。 我们初始化一个生产者,连接它,然后循环发送有关我们主题的3条消息。
With the consumer open in another terminal, execute the producer by running node mediumProducer.js which should publish all 3 messages then exit after outputting “done” . If everything works fine, the output on the consumer should be similar to this:
在另一个终端打开消费者的情况下,通过运行node mediumProducer.js执行生产者,该node mediumProducer.js应发布所有3条消息,然后在输出“done”后退出。 如果一切正常,则使用者的输出应与此类似:

Since we have not specified which partition we want to send the message on, Kafka uses a Round Robin technique to send messages that’s why 2 messages were sent on partition 0 and 1 was sent on Partition 1.
由于未指定要在哪个分区上发送消息,因此Kafka使用循环技术来发送消息,这就是为什么在分区0上发送2条消息,在分区1上发送1条消息的原因。
So far so good. Let's run 2 consumers!
到目前为止,一切都很好。 让我们运行2个消费者!
与两个使用者一起实现“最多一次”消息处理 (Achieving “at most once” message processing with 2 consumers)
As mentioned initially under the use case section, we want to run multiple consumers in order to manage load however, we also want that our messages are only processed once.
就像在用例部分最初提到的那样,我们想要运行多个使用者以管理负载,但是,我们也希望消息仅被处理一次。
To do this, we let our previous consumer keep running in a terminal and in another terminal, we start another consumer with the command node mediumConsumer.js 2 . Here 2 is indicating that this is our second consumer.
为此,我们让先前的使用者继续在终端中运行,并在另一个终端中,使用命令node mediumConsumer.js 2启动另一个使用者。 这里2表示这是我们的第二个消费者。
As soon as we execute the command, We should start to see some logs in the Consumer#1’s terminal indicating that the group is rebalancing:
执行命令后,我们应该开始在Consumer#1的终端上看到一些日志,表明该组正在重新平衡:
{"level":"ERROR","timestamp":"2020-08-17T15:01:04.683Z","logger":"kafkajs","message":"[Runner] The group is rebalancing, re-joining","groupId":"orders","memberId":"my-app-e866f23c-53a4-4405-97b6-c49cd2b5b99b","error":"The group is rebalancing, so a rejoin is needed","retryCount":0,"retryTime":319}Once the rebalancing is complete, We should see this log:
重新平衡完成后,我们将看到以下日志:
{"level":"INFO","timestamp":"2020-08-17T15:01:14.697Z","logger":"kafkajs","message":"[Runner] Consumer has joined the group","groupId":"notifications","memberId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","leaderId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","isLeader":true,"memberAssignment":{"orderCreated":[0]},"groupProtocol":"RoundRobinAssigner","duration":7}This time around, If we look at the memberAssignment property, we see that only 1 partition is assigned to Consumer#1. This is the log for our “notifications” consumer. We should see the same log for “orders” and “payments” as well. If we head over to the terminal of Consumer#2, we should see that Partition 1 has been assigned to Consumer#2.
这次,如果我们查看memberAssignment属性,则会看到只有1个分区分配给Consumer#1。 这是我们的“通知”使用者的日志。 我们也应该在“订单”和“付款”中看到相同的日志。 如果我们转到Consumer#2的终端,则应该看到分区1已分配给Consumer#2。
What happened here is that during rebalancing, Kafka tried to divide all the partitions among the consumers equally. Since we had 2 partitions and 2 consumers, Kafka divided them equally among the 2 consumers. This also brings us to another important point:
这里发生的是,在重新平衡期间,Kafka尝试将所有分区平均分配给消费者。 由于我们有2个分区和2个消费者,因此Kafka将其平均分配给2个消费者。 这也将我们带到另一个重要点:
If we have more consumers and less partitions for e.g. 3 consumers and 2 partitions then the extra number of consumers will be idle and no partition will be assigned to them.
如果我们有更多的使用者,而较少的分区(例如3个使用者和2个分区),那么多余的使用者数量将处于空闲状态,并且不会分配任何分区。
Now that both our Consumers are up and running, lets publish another message by executing the command node mediumProducer.js . After done is outputted on the console, head over to the consumers to examine the ouput:
现在我们的使用者都已经启动并正在运行,让我们通过执行命令node mediumProducer.js来发布另一条消息。 在控制台上输出done后,前往消费者检查输出:
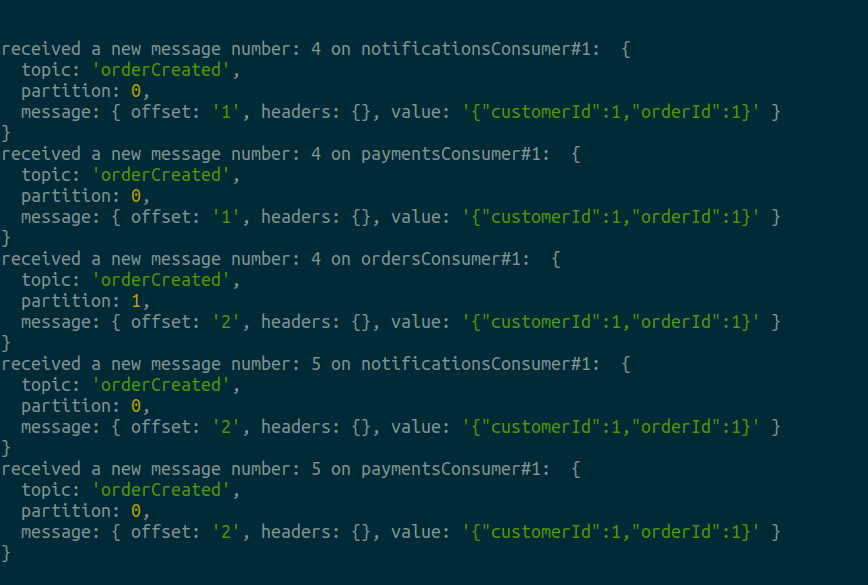

The output on your terminals can be different from the above depending on the assignment of partitions by Kafka. The important thing to note here is that our load has been divided between 2 consumers and each consumer processes only the messages that are sent on the partitions assigned to them. And this is how we achieve “at most once” processing with 2 or more consumers!
根据Kafka分配的分区,终端上的输出可能与上述输出不同。 这里要注意的重要一点是,我们的负载已在2个使用者之间分配,每个使用者仅处理在分配给它们的分区上发送的消息。 这就是我们如何与2个或更多消费者实现“最多一次”处理!
与2个使用者实现“至少一次”消息处理 (Achieving “at least once” message processing with 2 consumers)
Our 2nd objective as mentioned under the use case is that we want our messages to be processed at least once i.e. if any consumer fails to process a message due to any reason, the message should be retried until it is successful.
如用例所述,我们的第二个目标是希望我们的消息至少处理一次,即,如果任何使用者由于任何原因未能处理消息,则应重试该消息,直到成功为止。
To simulate a failing consumer, let's modify our consumer’s code:
为了模拟失败的使用者,让我们修改使用者的代码:
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['localhost:9092']
});
const topicName = 'orderCreated';
const consumerNumber = process.argv[2] || '1';
const processConsumer = async () => {
const ordersConsumer = kafka.consumer({groupId: 'orders'});
const paymentsConsumer = kafka.consumer({groupId: 'payments'});
const notificationsConsumer = kafka.consumer({groupId: 'notifications'});
await Promise.all([
ordersConsumer.connect(),
paymentsConsumer.connect(),
notificationsConsumer.connect(),
]);
await Promise.all([
await ordersConsumer.subscribe({ topic: topicName }),
await paymentsConsumer.subscribe({ topic: topicName }),
await notificationsConsumer.subscribe({ topic: topicName }),
]);
let orderCounter = 1;
let paymentCounter = 1;
let notificationCounter = 1;
await ordersConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
logMessage(orderCounter, `ordersConsumer#${consumerNumber}`, topic, partition, message);
orderCounter++;
},
});
await paymentsConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
logMessage(paymentCounter, `paymentsConsumer#${consumerNumber}`, topic, partition, message);
paymentCounter++;
},
});
await notificationsConsumer.run({
eachMessage: async ({ topic, partition, message }) => {
throw new Error('some error got in the way which didnt let the message be consumed successfully');
logMessage(notificationCounter, `notificationsConsumer#${consumerNumber}`, topic, partition, message);
notificationCounter++;
},
});
};
const logMessage = (counter, consumerName, topic, partition, message) => {
console.log(`received a new message number: ${counter} on ${consumerName}: `, {
topic,
partition,
message: {
offset: message.offset,
headers: message.headers,
value: message.value.toString()
},
});
};
processConsumer();Most of the code is the same except for lines 42–48 where before logging our message, we throw an error. This way, the consumer won't be able to complete the message successfully and it will be retried again by Kafka.
除了第42–48行外,大多数代码都是相同的,在第42–48行中,在记录消息之前,我们将引发错误。 这样,使用者将无法成功完成该消息,Kafka将再次尝试该消息。
To try this out, stop the Consumer#2 in the 2nd terminal, modify the consumer’s code as mentioned above and restart it with node mediumConsumer.js 2 . Again, we will see a lot of logs from Kafka indicating that it is rebalancing the topic and equally assigning the partitions among the 2 consumers.
要尝试此操作,请在第二个终端中停止Consumer#2,如上所述修改消费者的代码,然后使用node mediumConsumer.js 2重新启动它。 同样,我们会从Kafka看到许多日志,表明它正在重新平衡主题并在2个使用者之间平均分配分区。
Publish another message by executing the command node mediumProducer.js . After done is outputted on the console, check the Consumer#2’s output:
通过执行命令node mediumProducer.js发布另一个消息。 在控制台上输出done之后,请检查Consumer#2的输出:
{"level":"ERROR","timestamp":"2020-08-17T16:29:21.569Z","logger":"kafkajs","message":"[Runner] Error when calling eachMessage","topic":"orderCreated","partition":1,"offset":"3","stack":"Error: some error got in the way which didnt let the message be consumed successfully\n ....We should see this message 6 times — One message for the initial attempt and the remaining for 5 retries. After this:
我们应该看到此消息6次-一次尝试一条消息,其余5次重试。 在这之后:
{"level":"ERROR","timestamp":"2020-08-17T16:29:31.309Z","logger":"kafkajs","message":"[Consumer] Crash: KafkaJSNumberOfRetriesExceeded: some error got in the way which didnt let the message be consumed successfully","groupId":"notifications","retryCount":5,"stack":"KafkaJSNonRetriableError\n Caused by: Error: some error got in the way which didnt let the message be consumed successfully\n ...{"level":"INFO","timestamp":"2020-08-17T16:29:31.318Z","logger":"kafkajs","message":"[Consumer] Stopped","groupId":"notifications"}This indicates that our consumer has crashed and stopped. If during the 5 retries, if the consumer successfully processes the message, then it won't crash (which in our case is not possible)`. By default, any crashing consumer will try to rejoin the consumer group, and surely enough, we see the log of consumer rejoining the group:
这表明我们的消费者已经崩溃并停止。 如果在5次重试期间,如果使用者成功处理了消息,则消息不会崩溃(在我们的情况下是不可能的)。 默认情况下,任何崩溃的使用者都将尝试重新加入使用者组,并且确实,我们看到了使用者重新加入组的日志:
{"level":"INFO","timestamp":"2020-08-17T16:29:41.602Z","logger":"kafkajs","message":"[Runner] Consumer has joined the group","groupId":"notifications","memberId":"my-app-bde3d21a-4c83-4c03-9b04-0a26ee227c74","leaderId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","isLeader":false,"memberAssignment":{"orderCreated":[1]},"groupProtocol":"RoundRobinAssigner","duration":1933}But where did the message go if it wasn’t processed by Consumer#2? For that, let's look at Consumer#1’s logs:
但是,如果消费者2没有处理该消息,该消息会发送到哪里? 为此,让我们看一下Consumer#1的日志:
{"level":"ERROR","timestamp":"2020-08-17T16:29:31.573Z","logger":"kafkajs","message":"[Connection] Response Heartbeat(key: 12, version: 1)","broker":"localhost:9092","clientId":"my-app","error":"The group is rebalancing, so a rejoin is needed","correlationId":2325,"size":10}{"level":"ERROR","timestamp":"2020-08-17T16:29:31.574Z","logger":"kafkajs","message":"[Runner] The group is rebalancing, re-joining","groupId":"notifications","memberId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","error":"The group is rebalancing, so a rejoin is needed","retryCount":0,"retryTime":258}{"level":"INFO","timestamp":"2020-08-17T16:29:31.579Z","logger":"kafkajs","message":"[Runner] Consumer has joined the group","groupId":"notifications","memberId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","leaderId":"my-app-2d62f453-edd1-4b3f-a2ac-b926abcd9e12","isLeader":true,"memberAssignment":{"orderCreated":[0,1]},"groupProtocol":"RoundRobinAssigner","duration":5}Once the Notifications Consumer in our Consumer#2 crashed, Kafka initiated a rebalancing of the group and reassigned the partition that was left by Consumer#2 to Consumer#1. And sure enough, we can see the message processed by Consumer#1:
一旦我们的Consumer#2中的Notifications Consumer崩溃,Kafka将开始重新平衡该组,并将由Consumer#2留下的分区重新分配给Consumer#1。 确实,我们可以看到由Consumer#1处理的消息:

This way we can ensure “at least once” message processing for all our messages.
这样,我们可以确保对所有消息进行“至少一次”消息处理。
但是,有一个重要警告! (However, there is one important caveat!)
Our 2 consumers ran 2 different codes which is why one consumer was able to process the message while the other could not. This is a highly unlikely scenario. In the real world, this will not be the case and the codebase would be consistent across all the consumers.
我们的2个使用者运行了2个不同的代码,这就是为什么一个使用者能够处理消息而另一个使用者不能处理消息的原因。 这是极不可能的情况。 在现实世界中,情况并非如此,并且代码库在所有使用者之间都是一致的。
This means that if there is a bug in the code that does not allow the message to be consumed successfully, the message will keep on circling between the consumers and never be processed successfully!
这意味着,如果代码中存在无法成功使用消息的错误,则消息将继续在使用者之间循环,并且永远不会成功处理!
To handle this, we will need to implement a custom retry strategy that ignores a message /adds to a dead letter queue after a certain number of retries. But that is a topic for another day.
要解决此问题,我们将需要实现自定义重试策略,该策略将在重试一定次数后忽略消息/添加到死信队列。 但这是另一天的话题。
For now, what’s important is that Kafka ensures that all our messages are processed at least once and will keep on being retrying until they’re successful.
就目前而言,重要的是Kafka确保我们的所有消息至少被处理一次,并会继续重试直到成功。
结论 (Conclusion)
And that’s all there is to it! I have tried to keep the implementation simple but these basic concepts can be tweaked easily depending on the use cases! Please provide feedback if there’s anything in the article that’s incorrect or that can be improved. Let me know if you run into any issues while following this and I’ll gladly help!
这就是全部! 我试图使实现保持简单,但是可以根据用例轻松调整这些基本概念! 如果文章中有任何不正确或可以改进的地方,请提供反馈。 如果您在执行此操作时遇到任何问题,请告诉我,我们将竭诚为您服务!
As mentioned above, We still need to implement a retry mechanism that handles messages which cannot be consumed by the consumers — We will look into that in the next part!
如上所述,我们仍然需要实现一个重试机制来处理消费者无法使用的消息-我们将在下一部分中进行研究!
apache kafka















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









