





 本文介绍了Q学习的基础知识,它是强化学习中的一种基于价值的算法。Q学习结合了蒙特卡洛和动态规划方法,通过更新Q值来寻找最优策略。Q值表示从特定状态和动作开始的预期回报,Q表用于存储这些值,通过不断学习和更新,以达到最佳状态值函数。Q学习在离策略的TD学习中发挥作用,通过TD误差更新Q值,以找到最佳动作。
本文介绍了Q学习的基础知识,它是强化学习中的一种基于价值的算法。Q学习结合了蒙特卡洛和动态规划方法,通过更新Q值来寻找最优策略。Q值表示从特定状态和动作开始的预期回报,Q表用于存储这些值,通过不断学习和更新,以达到最佳状态值函数。Q学习在离策略的TD学习中发挥作用,通过TD误差更新Q值,以找到最佳动作。
Please follow this link to understand the basics of Reinforcement Learning.
请点击此链接以了解强化学习的基础知识。
Let’s explain various components before Q-learning.
让我们在Q学习之前解释各种组件。
基于策略的基于价值的RL (Policy-based vs value-based RL)
In policy-based RL, the random policy is selected initially and find the value function of that policy in the evaluation step. Then find the new policy from the value function computed in the improve step. The process repeats until it finds the optimal policy. In this type of RL, the policy is updated directly
在基于策略的RL中,首先选择随机策略,然后在评估步骤中找到该策略的价值函数。 然后从改进步骤中计算出的价值函数中找到新策略。 重复该过程,直到找到最佳策略为止。 在这类RL中,政策会直接更新

In a value-based approach, the random value function is selected initially, then find new value function. This process repeated until it finds the optimal value function. The intuition here is the policy that follows the optimal value function will be optimal policy. Here, the policy is implicitly updated through value function. In Q-learning updating the value function(Q-value) to find the optimal policy
在基于值的方法中,当前作随机值函数被选择最初,然后寻找新的值的功能。 重复此过程,直到找到最佳值函数为止。 直觉是遵循最优值功能的策略将是最优策略。 在这里,该策略通过值函数隐式更新。 在Q学习中更新值函数(Q值)以找到最佳策略
RL算法的三种基本方法(Three basic approaches of RL algorithms)

Temporal-Difference(TD) learning is a combination of Monte-Carlo and Dynamic Programming (DP) methods. Like the Monte-Carlo method, TD method can learn directly from raw experience without a model of the environment’s dynamics. Like DP, TD methods update estimates based in part on other learned estimates, without waiting for a final outcome (they call bootstrapping). Basically, in Q-learning, we are using 1 step TD learning approach. It means, we update the Q value by taking a single action, rather than waiting till the end of the episode to update the value function. This will be more clear when we introduce the equation later in the article.
时差(TD)学习是蒙特卡罗方法和动态编程(DP)方法的结合。 像蒙特卡洛方法一样,TD方法可以直接从原始经验中学习,而无需建立环境动力学模型。 像DP一样,TD方法也部分基于其他学习的估计来更新估计,而无需等待最终结果(它们称为自举)。 基本上,在Q学习中,我们使用1步TD学习方法。 这意味着,我们通过执行单个操作来更新Q值,而不是等到情节结束才更新值函数。 当我们在本文后面介绍方程式时,这一点将更加清楚。
价值功能 (Value functions)
The value function measures the goodness of the state(state-value) or how good is to perform an action from the given state(action-value)[1][2].
值函数可衡量状态(状态值)的优劣或根据给定状态(动作值)[1] [2]执行某项操作的质量。
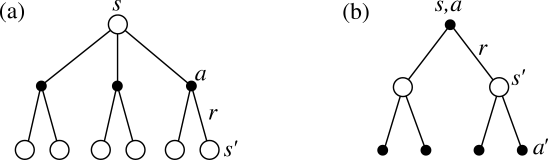
状态值函数 (state-value function)
The state-value Vπ(s) is the expected total reward, starting from state s and acts according to policy π.
状态值Vπ(s)是从状态s开始的预期总报酬,并根据策略π进行操作。
If the agent uses a given policy π to select actions, the corresponding value function is given by:
如果代理使用给定策略π选择操作,则相应的值函数由下式给出:

Optimal state-value function: It has high possible value function compared to other value function for all states
最佳状态值函数:与所有状态的其他值函数相比,它具有较高的可能值函数

In a value-based RL, If we know optimal value function, then the policy that corresponds to optimal value function is optimal policy 𝛑*.
在基于价值的RL中,如果我们知道最优价值函数,那么对应于最优价值函数的策略就是最优策略𝛑 *。

动作值功能 (Action-value function)
It is the expected return for an agent starting from state s and taking an action a then forever after act according to policy 𝛑. The state can have multiple actions, thus there will be multiple Q value in a state.
根据状态starting,从状态s开始采取行动,然后永远采取行动,是代理商的预期收益。 状态可以有多个动作,因此一个状态中会有多个Q值。
The optimal Q-function Q*(s, a) means highest possible Q value for an agent starting from state s and choosing action a. There, Q*(s, a) is an indication for how good it is for an agent to pick action while being in state s.
最佳Q函数Q *(s,a)表示从状态s开始选择动作a的代理的最大可能Q值。 Q *(s,a)表示代理处于状态s时采取行动有多好。
Since V*(s) is the maximum expected total reward when starting from state s, it will be the maximum of Q*(s, a) over possible Q* value of other actions in the state s. Therefore, the relationship between Q*(s, a) and V*(s) is easily obtained as:
由于V *(s)是从状态s开始时的最大预期总奖励,因此它将是状态s中其他动作的可能Q *值的最大值Q *(s,a)。 因此,Q *(s,a)和V *(s)之间的关系很容易获得:

and If we know the optimal Q-function Q*(s, a), the optimal policy can be easily extracted by choosing the action a that gives maximum Q*(s, a) for state s.
如果我们知道最优Q函数Q *(s,a),则可以通过选择为状态s给出最大Q *(s,a)的动作a轻松提取最优策略。

Q学习 (Q-learning)
Q learning is a value-based off-policy temporal difference(TD) reinforcement learning. Off-policy means an agent follows a behaviour policy for choosing the action to reach the next state s_t+1 from state s_t. From s_t+1, it uses a policy π that is different from behaviour policy. In Q-learning, we take absolute greedy action as policy π from the next state s_t+1.
Q学习是一种基于价值的偏离策略的时间差异(TD)强化学习。 非政策手段 代理遵循一种行为策略,用于选择要从状态s_t到达下一个状态s_t + 1的动作。 从s_t + 1开始,它使用与行为策略不同的策略π。 在Q学习中,我们从下一个状态s_t + 1采取绝对贪婪行为作为策略π。
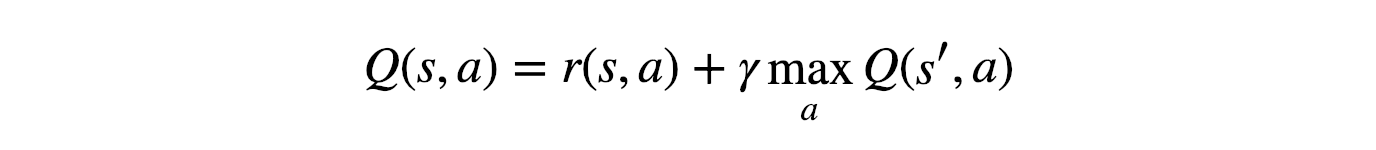
As we discussed in the action-value function, the above equation indicates how we compute the Q-value for an action a starting from state s in Q learning. It is the sum of immediate reward using a behaviour policy(ϵ-soft, ϵ-greedy or softmax) and from state s_t+1, it takes the absolute greedy action (choose the action that has maximum Q value over other actions).
正如我们在动作值函数中讨论的那样,上面的等式表明了我们如何从Q学习中的状态s开始计算动作a的Q值。 它是使用行为策略(ϵ-soft,ϵ-greedy或softmax)的立即奖励的总和,并且从状态s_t + 1开始,采取绝对贪婪操作(选择与其他操作相比具有最大Q值的操作)。

It is important to mention the update rule in Q-learning. New Q value is the sum of old Q value and TD error.
重要的是要在Q学习中提及更新规则。 新Q值是旧Q值与TD误差之和。

TD error is computed by subtracting the new Q value from the old Q value.
通过从旧Q值中减去新Q值来计算TD误差。

The above equation shows the elaborate view of the updating rule.
上面的等式显示了更新规则的详细视图。
Q表 (Q-table)
We are going to discuss the Q-learning using Q-table. When we use Neural Networks, it is called DQN and we can discuss that in another article.
我们将讨论使用Q表的Q学习。 当我们使用神经网络时,它称为DQN,我们可以在另一篇文章中进行讨论。

Q-table contains q values for each and every state-action pair. During the learning process, Q values in the table get updated.
Q表包含每个状态动作对的q值。 在学习过程中,表中的Q值会更新。
使用Q表在情节任务中进行Q学习的伪代码 (Pseudo-code for Q-learning in the episodic task using Q-table)
- Initialize with Q-table with zero value.用零值的Q表初始化。
- Episode begins 情节开始
- Perform action a_t from state st and observe the next state s_t+1 and reward r从状态st执行动作a_t并观察下一个状态s_t + 1并奖励r
- Compute the new Q value using the below equation and update the Q-table 使用以下等式计算新的Q值并更新Q表

5. s_t+1 is the new state s_t and repeat steps 3 to 4 until the s_t+1 reaches the terminal state
5. s_t + 1是新状态s_t,重复步骤3到4,直到s_t + 1达到终端状态为止。
6. Episode ends
6.情节结束
7. Repeat steps 2 to 6 until the optimal Q value is reached
7.重复步骤2至6,直到达到最佳Q值
In the next article, we can discuss the Deep Q-learning(DQN)
在下一篇文章中,我们将讨论深度Q学习(DQN)
If you like my write up, follow me on Github, Linkedin, and/or Medium profile.















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









