





scikit keras
Hi All, In the last blog I went over how to use ensemble methods with both Scikit-learn models and Keras model for classification.
大家好,在上一个博客中,我介绍了如何在Scikit学习模型和Keras模型中使用集成方法进行分类。
In this blog I want to show you how to do this for regression problems. I thought it wouldn’t be much useful till I was toiling around with the regression problems esp. using different ensemble methods that I realized this blog could be useful esp. to look at the different ensemble methods and see which one is the best.
在此博客中,我想向您展示如何解决回归问题。 我以为直到我专门研究回归问题,它才有用。 使用不同的集成方法,我意识到这个博客特别有用。 看一下不同的集成方法,看看哪种是最好的。
Before we dive in a quick reminder of what ensemble methods are. Imagine you work for a big tech firm that specializes in machine learning and there is a very important task that you want to done perfectly. Ideally, as this is a big tech firm, there would be more than just one or two machine learning engineers working on this, you would have teams of engineers working on it.
在我们快速提醒您什么是合奏方法之前。 想象一下,您在一家专门从事机器学习的大型技术公司工作,并且有一项非常重要的任务要完美完成。 理想情况下,由于这是一家大型技术公司,因此将不止一个或两个机器学习工程师在从事此工作,您将拥有工程师团队在为此工作。
Now imagine there are say five best models that work really well, now you can choose one of them and put in production or if you are a little risk averse as I am you would rather use all five models and take an average of them. Remember the premise was that this is an important task and you can run these models in parallel if you need to so the overhead of running five models is not that critical if this improves accuracy.
现在想象一下,有说好的五个最佳模型确实运行良好,现在您可以选择其中一种并投入生产,或者如果您像我一样有点厌恶风险,则宁愿使用这五个模型并取其平均值。 请记住,前提是这是一项重要的任务,如果需要,您可以并行运行这些模型,因此,如果这可以提高准确性,则运行五个模型的开销并不是那么关键。
As you might have guessed this is what ensemble does. It takes an (weighted) average of a few models to come up the final answer and since this is running based on more than one model the accuracy usually improves. If this all sounds familiar, I apologize for the repetition but I really want to hammer in the concept of average different models to improve accuracy.
您可能已经猜到这就是合奏的功能。 需要几个模型的(加权)平均值才能得出最终答案,并且由于此模型基于多个模型运行,因此准确性通常会提高。 如果这一切听起来都很熟悉,我对此重复表示歉意,但我真的想敲定平均不同模型的概念以提高准确性。
We are going to use both Scikit learn based models and deep neural network models from Keras. As always we follow the below steps to get this done.
我们将同时使用基于Scikit学习的模型和来自Keras的深度神经网络模型。 与往常一样,我们按照以下步骤进行操作。
1. Dataset: Load the data set, do some feature engineering if needed. 2. Build Models: Build a TensorFlow model with various layers. 3. Fit Models: Here we finally train the model using the training data and get some metrics. 4. Evaluate Models: We check our model performance on the validation data.
1.数据集:加载数据集,必要时进行一些功能设计。 2.建立模型:建立具有不同层的TensorFlow模型。 3.拟合模型:在这里,我们最终使用训练数据来训练模型并获得一些指标。 4.评估模型:我们根据验证数据检查模型性能。
Dataset:We use the inbuilt and readily available Boston housing dataset from Scikit learn.
资料集: 我们使用来自Scikit学习的内置且随时可用的波士顿住房数据集。
First, let’s look at how to load data. Since this is an in-built data set from Scikit learn we just call the function from Scikit-learn. You can read more about the data from here.
首先,让我们看一下如何加载数据。 由于这是Scikit学习的内置数据集,因此我们仅从Scikit-learn调用该函数。 您可以从此处阅读有关数据的更多信息。
#Usual Imports
import pandas as pdfrom sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.experimental import enable_hist_gradient_boostingfrom sklearn.ensemble import VotingRegressor,GradientBoostingRegressor,HistGradientBoostingRegressor,StackingRegressorfrom sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error,accuracy_scorefrom sklearn.ensemble import AdaBoostRegressor,BaggingRegressor,ExtraTreesRegressorfrom xgboost import XGBRegressorimport tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.layers import Dense,Dropout
from tensorflow.keras.models import Sequential
from keras.metrics import RootMeanSquaredErrorimport warnings
warnings.filterwarnings('ignore')#load the Boston housing dataset
from sklearn.datasets import load_boston
boston_dataset = load_boston()X = pd.DataFrame(boston_dataset.data,
columns=boston_dataset.feature_names)
y = boston_dataset.targetBuild Models:
构建模型:
#Scikit-learn Models
lin_reg= LinearRegression()
rnd_reg =RandomForestRegressor(n_estimators=100, random_state=42)
svr_reg = SVR(gamma="scale")#Keras Model
def build_nn():
model= Sequential(
[Dense(512,activation='selu',input_shape=[13]),
Dense(256,activation='selu'),
Dropout(0.2),
Dense(128,activation='selu'),
Dense(64,activation='selu'),
Dense(1)
]) model.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['RootMeanSquaredError']) return modelTill now there is nothing new as we plainly building models from Scikit-learn and Keras. Here comes the magic line that changes everything.
到现在为止,没有什么新鲜的东西,因为我们简单地从Scikit-learn和Keras构建模型。 改变一切的魔术线来了。
keras_reg = tf.keras.wrappers.scikit_learn.KerasRegressor(
build_nn,epochs=1000,verbose=False)This one line wrapper call converts the Keras model into a Scikit-learn model that can be used for Hyperparameter tuning using grid search, Random search etc. but it can also be used, as you guessed it, for ensemble methods.
这个单行包装调用将Keras模型转换为Scikit-learn模型,可通过网格搜索,随机搜索等将其用于超参数调整,但正如您猜到的那样,它也可用于集成方法。
Since this is a regressor we need one additional line to get this working.
由于这是一个回归器,因此我们需要额外的一行来使其正常工作。
keras_reg._estimator_type = "regressor"#https://stackoverflow.com/questions/59897096/votingclassifier-with-pipelines-as-estimators/59915844#59915844Finally we define the voting regressor using the below code.
最后,我们使用以下代码定义投票回归器。
voting_reg = VotingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('Dense',keras_reg)])This is pretty much what we did in the last blog but modified for regression. This week I want to go further and use “Stacking” ensemble method.
这几乎是我们在上一个博客中所做的,但为回归进行了修改。 本周,我想走得更远,并使用“堆叠”合奏方法。
Stacking is an ensemble method where instead of taking a weighted average, we just train a model to perform the final aggregation. Since our problem at hand is a regression one, we can use any of the regressors available from Scikit learn. What’s more interesting we can even use XGBoost regressor to be our final regressor. Here is how I did.
堆叠是一种集成方法,其中我们无需训练加权平均值,而只是训练模型以执行最终聚合。 由于我们面临的问题是回归问题,因此我们可以使用Scikit learning提供的任何回归变量。 更有趣的是,我们甚至可以使用XGBoost回归器作为最终回归器。 这是我做的。
#Default: RidgeCVst_reg=StackingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('Dense',keras_reg)])Fit Models:
拟合模型:
Now that we have all our regressors setup and ready, lets fit the models.
现在我们已经准备好所有回归器,让我们拟合模型。
for reg in (lin_reg, rnd_reg, svr_reg,keras,voting_reg,st_reg):
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
print(reg.__class__.__name__,
mean_squared_error(y_test, y_pred,squared=False)) print('R2 score: {:.2f}'.format(r2_score(y_test, y_pred)))Evaluate Models:Now the final step to see how these models performed.
评估模型: 现在是最后一步,看看这些模型的性能如何。
Default: Stacking with no final estimator, ie default RidgeCV
默认值:没有最终估计量的堆叠,即默认的RidgeCV
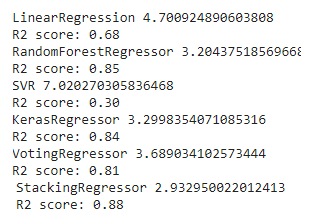
GradientBoostingRegressor: Stacking with final estimator GradientBoostingRegressor.
GradientBoostingRegressor: 与最终估计量GradientBoostingRegressor叠加。
st_reg=StackingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('Dense',keras)], final_estimator=
GradientBoostingRegressor(random_state=42))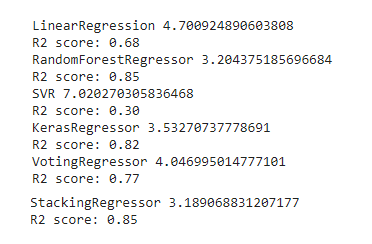
ExtraTreesRegressor: Stacking with final estimator ExtraTreesRegressor.
ExtraTreesRegressor: 与最终估计量ExtraTreesRegressor堆叠。
st_reg=StackingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('Dense',keras)], final_estimator=
ExtraTreesRegressor(random_state=42))
HistGradientBoostingRegressor:Stacking with final estimator HistGradientBoostingRegressor.
HistGradientBoostingRegressor: 与最终估计量HistGradientBoostingRegressor叠加。
st_reg=StackingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('Dense',keras)], final_estimator=
HistGradientBoostingRegressor(random_state=42))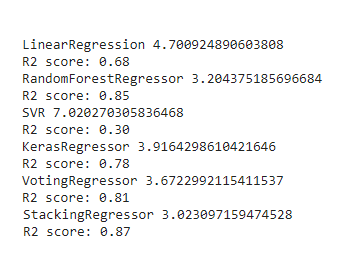
XGBoost:Finally using XGBoost as the regressor and the final regressor
XGBoost: 最终使用XGBoost作为回归器和最终回归器
import xgboost as xgb
xgb_reg=xgb.XGBRegressor(random_state=42)st_reg=StackingRegressor(
estimators=[('lr', lin_reg),
('rf', rnd_reg),
('svr', svr_reg),
('xgb', xgb_reg),
('Dense',keras)], final_estimator=
XGBRegressor(random_state=42))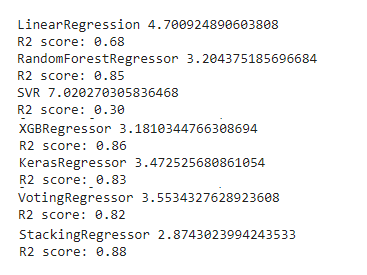
All of this code is available here at my Github repository.
所有这些代码都可以在我的Github存储库中找到。
Finally, I want to take this opportunity to thank Aurelien Geron for his excellent book “Hands-on Machine Learning with Scikit-Learn, Keras & Tensorflow”. Hope you would find this blog useful.
最后,我想借此机会感谢Aurelien Geron的出色著作“ Scikit-Learn,Keras和Tensorflow的动手机器学习”。 希望您会发现此博客有用。
Good luck !!!
祝好运 !!!
Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurelien Geron
Aurelien Geron的Scikit-Learn,Keras和TensorFlow进行动手机器学习
翻译自: https://medium.com/@sailaja.karra/ensemble-scikit-learn-and-keras-part2-regressors-2c0ae19ff25b
scikit keras















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









