






不平衡数据采样
Imbalance data is a case where the classification dataset class has a skewed proportion. For example, I would use the churn dataset from Kaggle for this article.
不平衡数据是分类数据集类具有不正确比例的情况。 例如,对于本文,我将使用Kaggle的客户流失数据集。
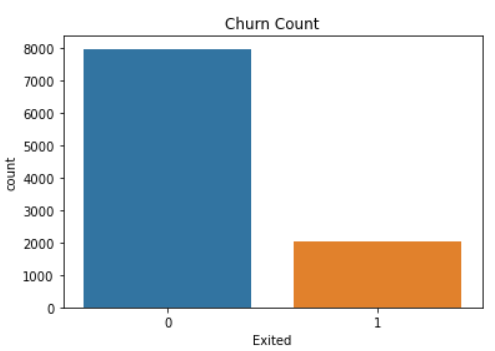
We can see there is a skew in the Yes class compared to the No class. If we calculate the proportion, the Yes class proportion is around 20.4% of the whole dataset. Although, how you classify the imbalance data? The table below might help you.
我们可以看到,“是”类与“否”类相比存在偏差。 如果我们计算比例,则“是”类别的比例约为整个数据集的20.4%。 虽然,您如何分类不平衡数据? 下表可能会对您有所帮助。

There are three cases of Imbalance — Mild, Moderate, and Extreme; depends on the minority class proportion to the whole dataset. In our example above, we only have a Mild case of imbalanced data.
有三种失衡情况:轻度,中度和极端; 取决于少数类在整个数据集中的比例。 在上面的示例中,我们仅遇到数据不平衡的轻微情况。
Now, why we need to care about imbalance data when creating our machine learning model? Well, imbalance class creates a bias where the machine learning model tends to predict the majority class. You don’t want the prediction model to ignore the minority class, right?
现在,为什么我们在创建机器学习模型时需要关心数据不平衡? 好吧,不平衡类别会产生偏差,机器学习模型倾向于预测多数类别。 您不希望预测模型忽略少数群体,对吗?
That is why there are techniques to overcome the imbalance problem — Undersampling and Oversampling. What is the difference between these two techniques?
这就是为什么有一些技术可以解决不平衡问题-欠采样和过采样。 这两种技术有什么区别?
Undersampling would decrease the proportion of your majority class until the number is similar to the minority class. At the same time, Oversampling would resample the minority class proportion following the majority class proportion.
采样不足会降低您多数群体的比例,直到人数与少数群体相似为止。 同时,过采样将按照多数类别比例对少数类别比例进行重新采样。
In this article, I would only write a specific technique for Oversampling called SMOTE and various variety of the SMOTE.
在本文中,我将只为过采样编写一种称为SMOTE和各种SMOTE的特定技术。
Just a little note, I am a Data Scientist who believes in leaving the proportion as it is because it is representing the data. It is better to try feature engineering before you jump into these techniques.
请注意,我是一名数据科学家,他相信保留比例不变,因为它代表数据。 在跳入这些技术之前,最好先尝试特征工程。
冒烟 (SMOTE)
So, what is SMOTE? SMOTE or Synthetic Minority Oversampling Technique is an oversampling technique but SMOTE working differently than your typical oversampling.
那么,什么是SMOTE? SMOTE或合成少数族裔过采样技术是一种过采样技术,但SMOTE的工作方式不同于典型的过采样。
In a classic oversampling technique, the minority data is duplicated from the minority data population. While it increases the number of data, it does not give any new information or variation to the machine learning model.
在经典的过采样技术中,少数数据是从少数数据总体中复制的。 虽然它增加了数据数量,但它并没有为机器学习模型提供任何新信息或变化。
For a reason above, Nitesh Chawla, et al. (2002) introduce a new technique to create synthetic data for oversampling purposes in their SMOTE paper.
由于上述原因, Nitesh Chawla等人。 (2002年)在他们的SMOTE论文中引入了一种新技术来创建用于过度采样目的的合成数据。
SMOTE works by utilizing a k-nearest neighbor algorithm to create synthetic data. SMOTE first start by choosing random data from the minority class, then k-nearest neighbors from the data are set. Synthetic data would then made between the random data and the randomly selected k-nearest neighbor. Let me show you the example below.
SMOTE通过使用k最近邻算法来创建合成数据。 SMOTE首先从少数类中选择随机数据开始,然后从数据中设置k个最近邻居。 然后将在随机数据和随机选择的k最近邻居之间生成合成数据。 让我向您展示以下示例。
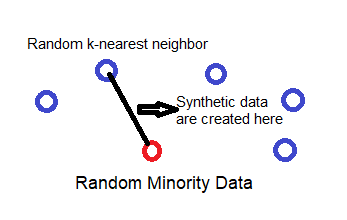
The procedure is repeated enough times until the minority class has the same proportion as the majority class.
重复该过程足够的次数,直到少数派与多数派的比例相同为止。
I omit a more in-depth explanation because the passage above already summarizes how SMOTE work. In this article, I want to focus on SMOTE and its variation, as well as when to use it without touching much in theory. If you want to know more, let me attach the link to the paper for each variation I mention here.
我省略了更深入的解释,因为上面的段落已经总结了SMOTE的工作方式。 在本文中,我想集中讨论SMOTE及其变体,以及何时使用它而又不涉及理论上的问题。 如果您想了解更多信息,请让我在本文中提及的每个变化形式都将链接附加到论文上。
As preparation, I would use the imblearn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









