





神经网络 卷积神经网络
Imagine you’re in the year 2050 and you’re on your way to work in a self-driving car (probably). Suddenly, you realize your car is cruising at 100KMPH on a busy road after passing through a cross lane and you don’t know why.
想象一下,您现在正处于2050年,并且正在驾驶自动驾驶汽车(可能)工作。 突然,您发现您的汽车在通过十字路口后,在繁忙的道路上以100KMPH的速度行驶,而您不知道为什么。
PURE TERROR!
纯恐怖!
What could’ve happened?
会发生什么事?
Well, there might be many reasons. But in this article, we are going to focus on one particular reason — the car was fooled.
好吧,可能有很多原因。 但是在本文中,我们将重点关注一个特殊原因- 汽车被骗了 。
To be precise, the neural network that saw a signboard at the intersection was tricked into thinking a STOP sign as a 100KMPH sign and that resulted in its instantaneous acceleration.
确切地说,在交叉路口看到一个招牌的神经网络被欺骗,以为将STOP标志视为100KMPH标志,并导致其瞬时加速。
Is that even possible?
那有可能吗?
Yes, it is. But before getting deep into it first, let’s understand what a neural network sees after it gets trained. It is believed that every independent neuron in the network works similarly as of our biological neuron and we assume that the neural network thinks the same as of our brain when it looks at an image. Practically, it isn’t the case. Let’s look at it with an example.
是的。 但是在开始深入研究之前,让我们先了解一下神经网络在训练后会看到什么。 可以相信,网络中的每个独立神经元的工作方式都与我们的生物神经元类似,并且我们假设神经网络在查看图像时会认为与大脑相同。 实际上,并非如此。 我们来看一个例子。
Guess what the below image is.
猜猜下图是什么。

You guessed it right. It’s a temple and the neural network predicts it as a temple with 97% confidence.
你猜对了。 这是一座庙宇,神经网络将其预测为拥有97%置信度的庙宇。
Now, guess what this image is.
现在,猜猜这是什么图像。

Temple again?
再来一次圣殿?
They look identical but they aren’t. The above image is predicted as an ostrich with 98% confidence by the same model we used for the previous one. The network is fooled by this image now. But how?
它们看起来相同,但事实并非如此。 上面的图像被我们用于上一个模型的模型预测为具有98%的置信度的鸵鸟。 现在,该图像欺骗了网络。 但是如何?
This second image didn’t come from a real-world camera but instead, it was hand-engineered specifically to fool the neural network classifier while being the same to our visual system.
第二张图像不是来自真实世界的相机,而是经过手工设计,目的是欺骗神经网络分类器,同时使其与我们的视觉系统相同。

This noisy guy is responsible for the misclassification by the model. The addition of this noise to the first image resulted in the modified second image and this is called an adversarial example. And the external noise added is called a perturbation.
这个嘈杂的家伙负责模型的错误分类。 将此噪声添加到第一图像会导致修改后的第二图像,这称为对抗示例。 加上的外部噪声称为扰动。

In the same way, the car might have misclassified the STOP sign with a 100KMPH sign in this manner.
同样,汽车可能会以这种方式将STOP符号归为100KMPH符号。
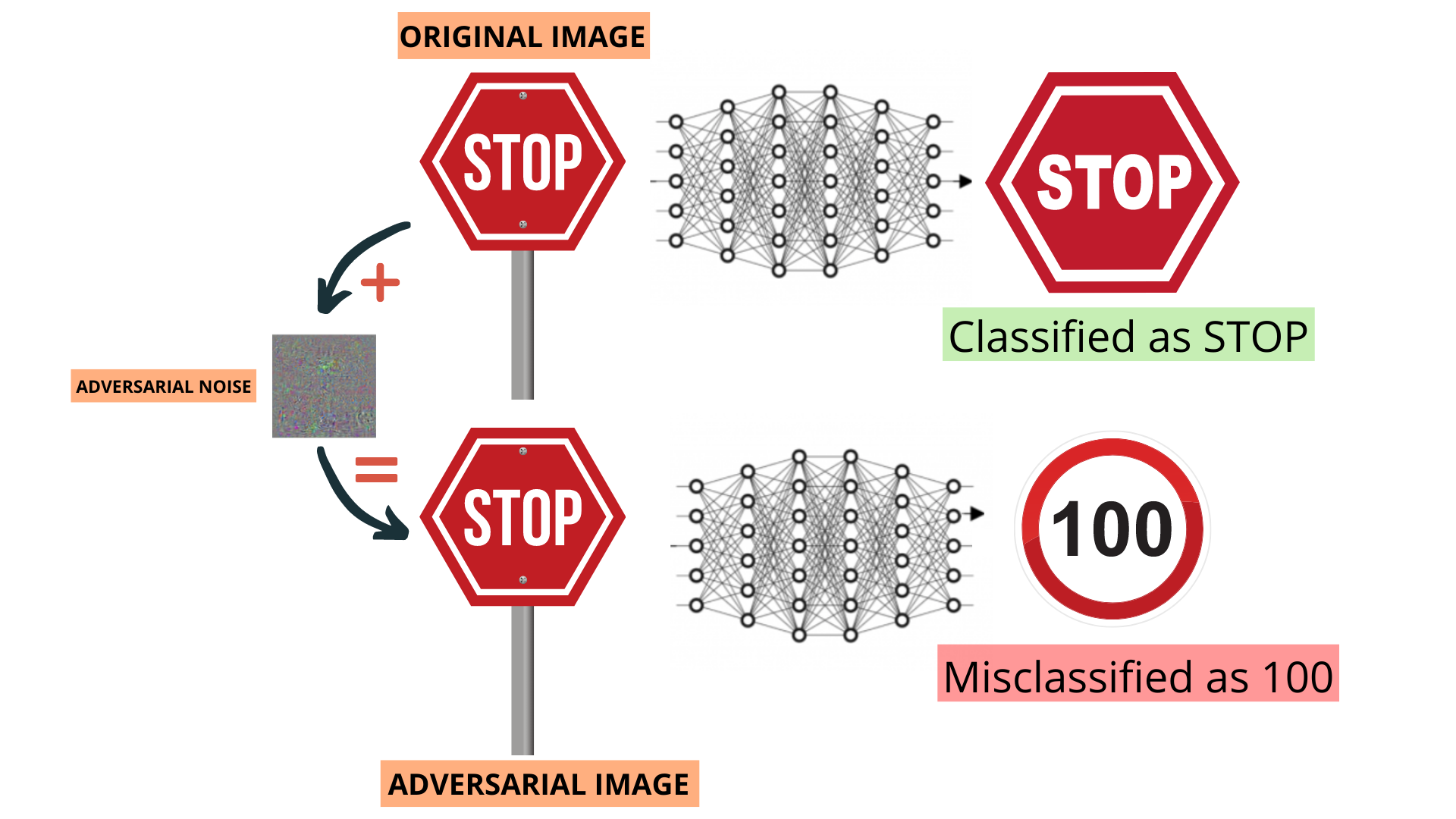
Let me give you an idea of why this is a very significant threat to a lot of real-world machine learning applications apart from the above self-driving cars case.
让我让您了解一下,除了上述自动驾驶汽车案例之外,为什么这对许多现实世界的机器学习应用程序构成了非常重大的威胁。
- It is also possible to create a pair of 3D printed glasses but when you put them on, all of a sudden you are unrecognizable to any existing facial recognition software. 也可以创建一副3D打印眼镜,但是当戴上它们时,突然之间您将无法识别任何现有的面部识别软件。

- Also, printing a custom license plate that looks perfectly normal but that gets misregistered by any existing traffic surveillance camera. 另外,打印自定义车牌看起来完全正常,但是任何现有的交通监控摄像头都会注册错误。
In this way, there are a ton of different attacks neural networks are prone to. There are white-box attacks, black-box attacks, physical attacks, digital attacks, perceptible and imperceptible attacks, and whatnot. While working under any real-world situation, the network must be robust to all such types of attacks.
这样,神经网络容易遭受大量不同的攻击。 有白盒攻击,黑盒攻击,物理攻击,数字攻击,可感知和不可感知的攻击等等。 在任何现实情况下工作时,网络都必须对所有此类攻击都具有鲁棒性。
这是如何运作的? (How does this work?)
There’s a very interesting blog on this written by Andrej Karpathy and you could read it here. Here’s a small sneak peek of it.
Andrej Karpathy在这方面有一个非常有趣的博客,您可以在此处阅读。 这是一个小小的偷看。
So what do we do in a traditional training process? We get the loss function, we backpropagate, calculate the gradient, take this gradient and use it to perform a parameter update, which wiggles every parameter in the model a tiny amount in the correct direction, to increase the prediction score. These parameter updates are responsible for increasing the confidence scores of the right class of the input image.
那么我们在传统的培训过程中会做什么? 我们得到损失函数,反向传播,计算梯度,取该梯度并用它来执行参数更新 ,该更新将模型中的每个参数向正确的方向摆动一小部分,从而增加了预测得分。 这些参数更新负责增加输入图像的正确类别的置信度得分。
Notice how this worked. We kept the input image fixed, and we regulated the model parameters to increase the score of whatever class we wanted. On the other way round, we can easily flip this process around to create fooling images. That is, we will hold the model parameters fixed, and instead, we’re computing the gradient of all pixels in the input image on any class we wish. For example, we can ask a question that —
注意这是如何工作的。 我们保持输入图像固定不变,并调节模型参数以增加所需类别的分数。 另一方面,我们可以轻松地翻转此过程以创建欺骗图像。 也就是说,我们将固定模型参数,而要计算希望的任何类上输入图像中所有像素的梯度。 例如,我们可以问一个问题-
What happens to the score of (whatever class you want) when I tweak the pixels of the image instead?
当我调整图像的像素时,(无论您想要什么类)的分数会怎样?
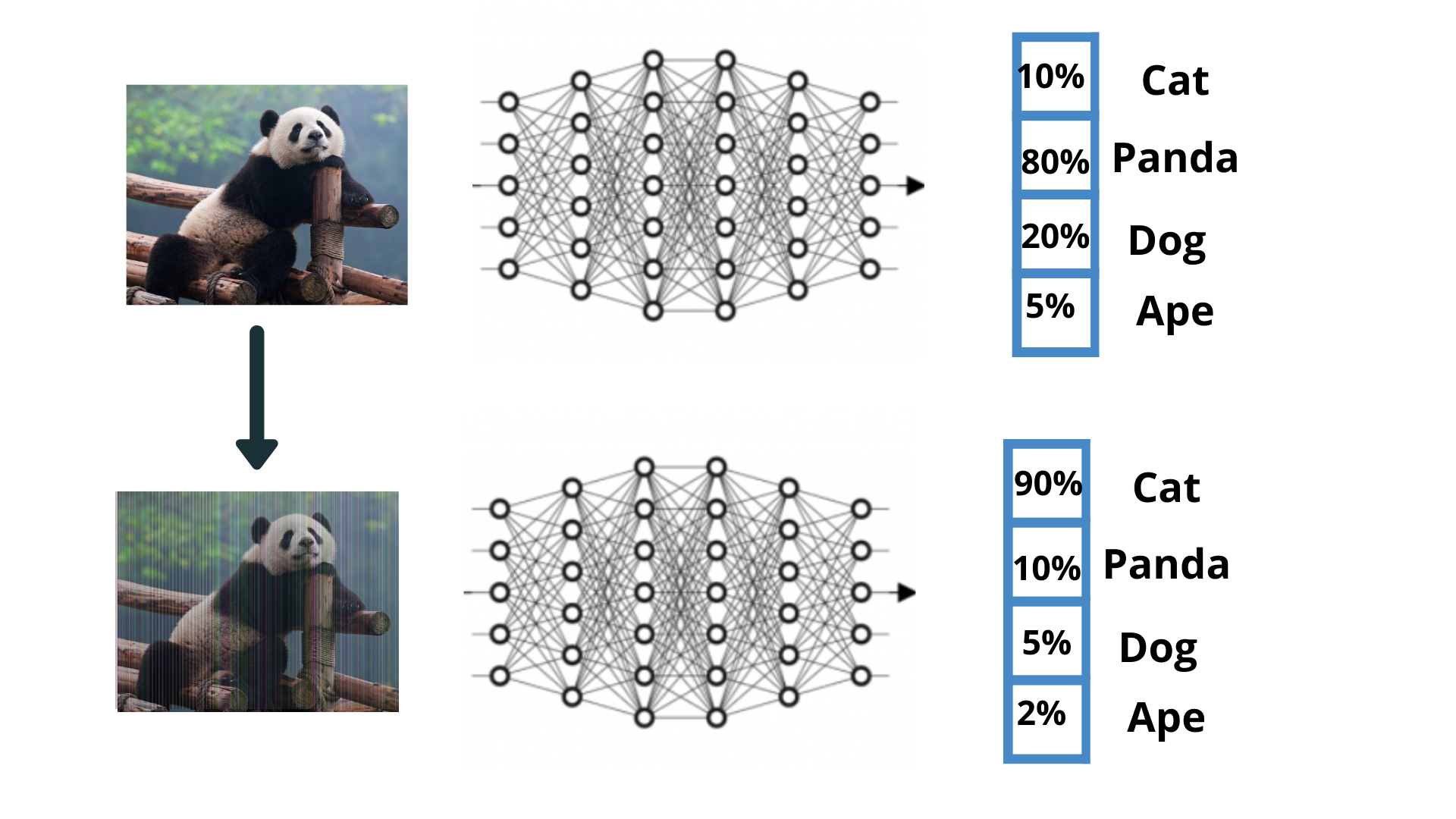
We compute the gradient just as before with backpropagation, and then we can perform an image update instead of a parameter update, with the end result being that we increase the score of whatever class we want. For example, we can take a panda image and regulate every pixel according to the gradient of that image on the cat class. This would change the image a tiny amount, but the score of the cat would now increase. Somewhat unintuitively, it turns out that you don’t have to change the image too much to toggle the image from being classified correctly as a panda to being classified as anything else (e.g. cat).
我们像以前一样通过反向传播计算梯度,然后可以执行图像更新而不是参数更新,最终结果是我们增加了所需类别的分数。 例如,我们可以拍摄熊猫图像,并根据猫类上该图像的梯度来调整每个像素。 这会稍微改变图像,但是猫的分数现在会增加。 有点不直观,事实证明,您不必更改图像就可以将图像从正确地分类为熊猫分类为其他分类(例如cat )。
Now that you have got a basic idea of how this works, there’s one popular technique you should know called the Fast Gradient Sign Method, used to generate adversarial examples, which was discussed by Ian J. Goodfellow in Explaining and Harnessing Adversarial Examples.
现在您已经知道了它是如何工作的基本概念,您应该知道一种流行的技术,称为快速梯度符号法,用于生成对抗性示例,Ian J. Goodfellow在解释和利用对抗性示例中进行了讨论。
快速梯度符号法 (Fast Gradient Sign Method)
In this method, you take an input image and use the gradients of the loss function with respect to the input image to create a new image that maximizes the existing loss. In this way, we achieve an image with the change that is almost imperceptible to our visual system but the same neural network could see a significant difference. This new image is called the adversarial image. This can be summarised using the following expression:
在这种方法中,您将获取一个输入图像,并使用损失函数相对于输入图像的梯度来创建一个使现有损失最大化的新图像。 通过这种方式,我们获得了视觉系统几乎察觉不到的变化的图像,但是相同的神经网络可能会看到很大的差异。 该新图像称为对抗图像。 可以使用以下表达式进行总结:
adv_x = x + ϵ * sign(∇x * J(θ,x,y))where
哪里
- adv_x: Adversarial image. adv_x:对抗图像。
- x: Original input image. x:原始输入图像。
- y: Original input label. y:原始输入标签。
- ϵ: Multiplier to ensure the perturbations are small. ϵ:乘数可确保扰动很小。
- θ: Model parameters. θ:模型参数。
- J: Loss. J:亏损。
You can play around with this method by generating your own adversarial examples for images in this notebook. Here, you’ll find a model trained on the MNIST dataset and you can see how the confidence scores change while tweaking the ϵ(epsilon) parameter.
您可以通过为笔记本中的图像生成自己的对抗示例来使用此方法。 在这里,您将找到在MNIST数据集上训练的模型,并且可以看到在调整ϵ (ε)参数时置信度得分如何变化。

For any x → y, x indicates actual class and y indicates the predicted class.
对于任何x→y,x表示实际类别,y表示预测类别。
As you can see, if you increase the epsilon value, the perturbations become more evident and it becomes a perceptible change to our visual system. Nevertheless, our neural system is robust enough to predict the correct class.
如您所见,如果增加epsilon值,则扰动会变得更加明显,并且对我们的视觉系统也会产生明显的变化。 但是,我们的神经系统足够强大,可以预测正确的类别。
This method achieves this by finding how much each pixel in the given input image contributes to the loss value, and it adds the perturbation accordingly.
该方法通过找到给定输入图像中的每个像素对损耗值有多大贡献来实现这一目标,并相应地增加了扰动。
Not only the Fast Gradient Sign Method, but we also have some other popular methods called the adversarial patch method, the single-pixel attack method, creating 3D models by adversarially perturbating them, and many more. Let’s take a look at some of them.
不仅快速梯度符号方法,而且我们还有其他一些流行的方法,称为对抗补丁方法,单像素攻击方法,通过对抗性干扰来创建3D模型等。 让我们看看其中的一些。
对抗补丁 (Adversarial Patch)
Google in the year 2018, came up with a unique idea of placing an adversarial patch in the image frame in the following way.
Google在2018年提出了一个独特的想法,可以通过以下方式在图像帧中放置一个对抗性补丁。
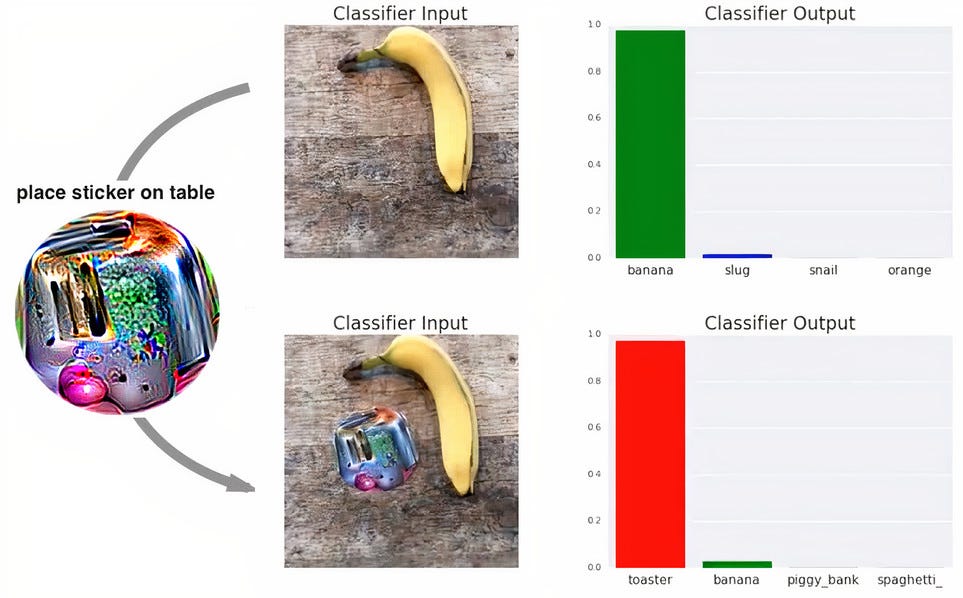
This paper shows how it is possible to show the model any image and it classifies the given image as a toaster. This patch is designed in such a way that it can fool any underlying neural network that is responsible for classification into thinking it as a toaster, no matter what image you give it. You just need to place this sticker beside the object. It works pretty well and is capable enough to fool models which are not robust enough.
本文展示了如何向模型显示任何图像,并将给定图像分类为烤面包机 。 该补丁的设计方式使其可以欺骗任何负责分类的底层神经网络,将其视为烤面包机,无论您提供什么样的图像。 您只需要将此标签放在对象旁边。 它工作得很好,并且足以欺骗不够鲁棒的模型。
打印对抗性干扰的3D模型 (Printing a 3D Model which is Adversarially Perturbated)
Not only images, but you can also create a 3D model that is specifically designed to fool the model at any angle.
不仅是图像,而且您还可以创建3D模型,该3D模型专门设计用于以任何角度欺骗模型。
Now that we’ve seen how these adversarial examples fool a neural network, the same examples can also be used to train the neural network to make the model robust from attacking. This could also act as a good regularizer.
既然我们已经看到了这些对抗性示例如何欺骗神经网络,那么同样的示例也可以用于训练神经网络,以使模型在攻击中变得强大。 这也可以充当良好的调节器。
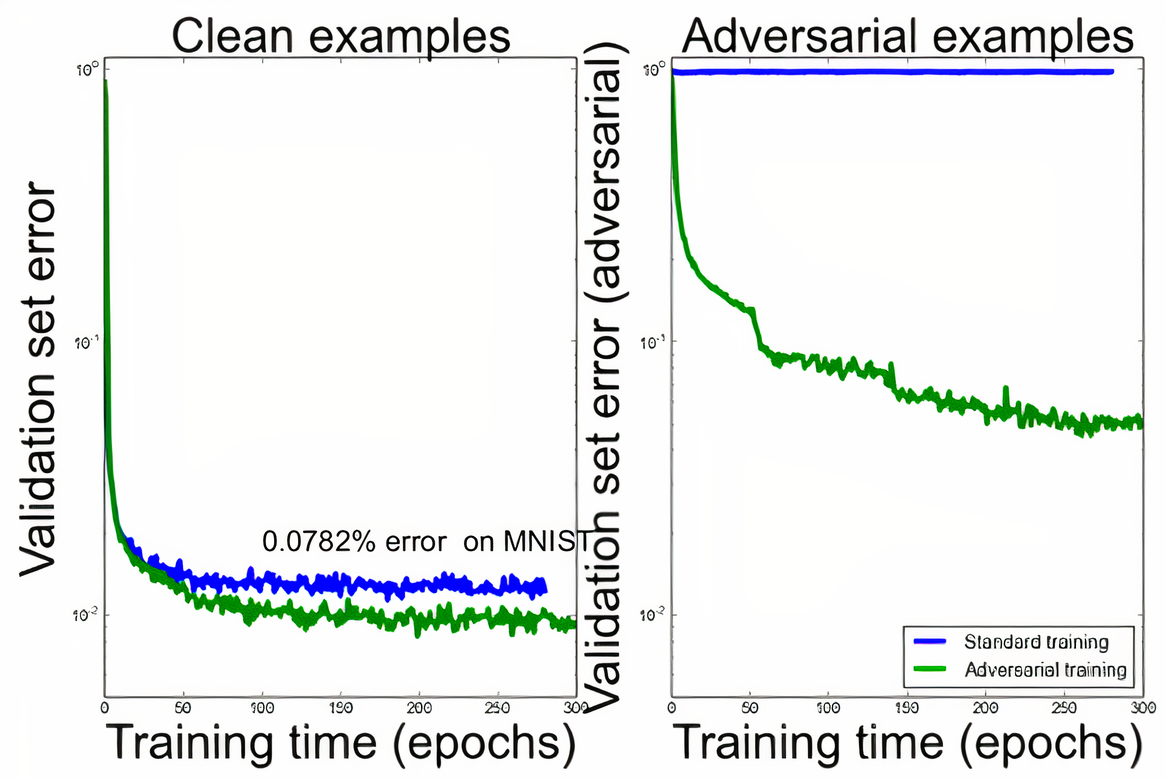
From the above graph, it is evident that after training with adversarial examples the model is now less prone to get fooled.
从上图可以看出,经过对抗性示例训练后,该模型现在更不容易被愚弄。
And now the final question.
现在是最后一个问题。
Do we humans have adversarial examples ourselves?
我们人类自己有对抗性的例子吗?
And I think the answer is Yes! For example, if you look at some optical illusions like this,
我认为答案是肯定的! 例如,如果您看到类似这样的错觉,

You’ll notice that the lines don’t look parallel at first. But when closely observed these lines are parallel to one another.
您会注意到这些线起初看起来并不平行。 但是当仔细观察时,这些线是彼此平行的。
And yes, these are exactly what the adversarial examples are. They are the images where we see something that we shouldn’t be seeing. So, we can see that our human visual system can also be fooled with certain examples but very clearly we are robust to adversarial examples that fool our neural networks.
是的,这些正是对抗性例子。 它们是我们看到不该看到的图像的地方。 因此,我们可以看到,我们的人类视觉系统也可能被某些示例所迷惑,但是非常明显地,我们对于使我们的神经网络蒙蔽的对抗性示例具有鲁棒性。
结论 (Conclusion)
These adversarial examples are not just limited to images. Any model from a simple perceptron to models of natural language processing is prone to such attacks. But these can be curbed to an extent with some strategies such as Reactive and Proactive Strategies which will be discussed in detail in my upcoming articles.
这些对抗性例子不仅限于图像。 从简单的感知器到自然语言处理的任何模型都容易受到此类攻击。 但是,可以通过一些策略(例如“ React式”和“ 主动式策略”)在一定程度上抑制这些问题,这些策略将在我的后续文章中进行详细讨论。
On a brighter side, I think these adversarial examples hint at some very interesting new research directions that we can use to improve our existing models. I hope you’ve got to learn something new today!
从好的方面来说,我认为这些对抗性例子暗示了一些非常有趣的新研究方向,我们可以使用这些研究方向来改进现有模型。 希望您今天学到一些新知识!
If you’d like to get in touch, connect with me on LinkedIn.
如果您想取得联系,请通过LinkedIn与我联系。
翻译自: https://towardsdatascience.com/how-to-fool-a-neural-network-958ba5d82d8a
神经网络 卷积神经网络















 4079
4079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}