





k8s grpc
One of the challenges some users (like me) face when trying to implement gRPC services into a Kubernetes cluster is to achieve a proper load balancing, and before diving into the way of balancing gRPC we first need to answer the question why do I need to balance the traffic if Kubernetes already does that job.
某些用户(如我)在尝试向Kubernetes集群中实现gRPC服务时面临的挑战之一是实现适当的负载平衡,在探讨平衡gRPC的方式之前,我们首先需要回答以下问题:为什么我需要如果Kubernetes已经完成了这项工作,则可以平衡流量。
this article is focused on Kubernetes and Golang.
本文重点介绍Kubernetes和Golang。
为什么Kubernetes中的gRPC流量无法正确平衡? (Why gRPC traffic is not properly balanced in Kubernetes?)
The main reason why is difficult to balance the gRPC traffic is that people see gRPC as HTTP and here is where the problem begins, by design they are different, while HTTP creates and closes connections per request, gRPC operates over HTTP2 protocol that works over a long lived TCP connection making more difficult the balancing since multiple requests go through the same connection thanks to the multiplexing feature. However, this is not the only reason why balancing issues happen when configuring gRPC services in Kubernetes and these are some of the common mistakes:
难以平衡gRPC流量的主要原因是人们将gRPC视为HTTP,这是问题开始的地方,根据设计,它们是不同的,尽管HTTP根据请求创建和关闭连接,但gRPC会通过HTTP2协议运行,该协议可在TCP连接寿命长,多路复用功能使多个请求通过同一连接,使平衡变得更加困难。 但是,这不是在Kubernetes中配置gRPC服务时发生平衡问题的唯一原因,这些是一些常见错误:
- Wrong gRPC client configuration gRPC客户端配置错误
- Wrong Kubernetes service configurationKubernetes服务配置错误
gRPC客户端配置错误(Wrong gRPC client configuration)
The common case when setting up a gRPC client is to choose the default configuration, which works perfectly for a 1–1 connection type, however, for a productive environment it does not work as we would like to. The reason behind this is because the default gRPC client offers the possibility to connect with a simple IP/DNS record which creates just one connection with the target service.
设置gRPC客户端的常见情况是选择默认配置,该配置非常适合1-1连接类型,但是,对于生产性环境,它不能像我们期望的那样工作。 其背后的原因是因为默认的gRPC客户端提供了连接简单IP / DNS记录的可能性,该记录仅与目标服务建立了一个连接。
That’s why a different set up needs to be done for connecting with multiple servers, so we move the connection type from 1-1 to 1-N.
这就是为什么需要进行不同的设置才能连接多个服务器的原因,因此我们将连接类型从1-1更改为1-N。
Default set up
默认设置
func main(){
conn, err := grpc.Dial("my-domain:50051", grpc.WithInsecure())
if err != nil {
log.Fatalf("error connecting with gRPC server: %v", err)
}
defer conn.Close()
cli := test.NewTestServiceClient(conn)
rs, err := cli.DoSomething(context.Background(), ...)
.
.
.
}New set up
新设置
func main() {
address := fmt.Sprintf("%s:///%s", "dns", "
conn, err := grpc.Dial(address,
grpc.WithInsecure(),grpc.WithBalancerName(roundrobin.Name))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
.
.
.
}there are two major changes to take a look here:
这里有两个主要变化:
the address: the final address parsed will look like dns:///my-domain:50051 and the reason why this format is used is that the Dial function allows us to use a target conformed by Scheme://Authority/Endpoint, in our case I am skipping the authority. So first I added dns as scheme because I want to resolve a domain and keep watching the changes over it, the resolver options are pass-through (default), dns, and manual, more details here.
地址:解析后的最终地址将类似于dns:/// my-domain:50051,并且使用此格式的原因是Dial函数允许我们使用Scheme:// Authority / Endpoint符合的目标我们的情况是我跳过了权限。 所以首先我添加了dns作为方案,因为我想解析一个域并一直关注它的变化,解析器选项是pass-through(默认),dns和manual,更多详细信息在这里。
balancer option: in the case our client gets connected with multiple servers now our gRPC client is able to balance the requests according to the balancing algorithm chosen.
平衡器选项:在我们的客户端与多台服务器连接的情况下,我们的gRPC客户端现在能够根据选择的平衡算法来平衡请求。
Summing up our gRPC client is now able to create different connections if and only if the domain resolves multiple A or AAAA records, and not just that, now is able to balance the request evenly to the different servers.
总结我们的gRPC客户端现在可以在以下情况下创建不同的连接:并且仅当该域解析多个A或AAAA记录时(不仅如此),现在它能够将请求平均分配给其他服务器。
Now let’s see the missing piece in the puzzle to make it work with Kubernetes.
现在,让我们看一下拼图中缺失的部分,以使其与Kubernetes一起工作。
Kubernetes服务配置错误 (Wrong Kubernetes service configuration)
Creating a service in Kubernetes is pretty straightforward we just need to define the service name, the ports, and the selector so the service can group the pods dynamically and automatically balance the request like so:
在Kubernetes中创建服务非常简单,我们只需要定义服务名称,端口和选择器,以便服务可以动态地对Pod进行分组并自动平衡请求,如下所示:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- name: grpc
protocol: TCP
port: 50051
targetPort: 50051so what is the problem with the previous set up?, it is simply that the default Kubernetes service creates a DNS record linking just one single IP, thus, when you do something like nslookup my-service.{namespace}.svc.cluster.local what is returned is a single IP, which makes the connection graph in a common gRPC implementation something like this:
那么以前的设置有什么问题呢?仅仅是因为默认的Kubernetes服务创建了一个DNS记录,该DNS记录仅链接了一个IP,所以当您执行nslookup my-service.{namespace}.svc.cluster.local返回的是单个IP,这使得通用gRPC实现中的连接图如下所示:
the green line means the active connection with the client, the yellow is the pods not active. The client creates a persistent connection with the Kubernetes service which at the same time creates the connection with one of the pods but this does not mean the service is not connected with the rest of the pods.
绿线表示与客户端的活动连接,黄线表示未激活的Pod。 客户端与Kubernetes服务创建一个持久连接,该服务同时与其中一个Pod建立连接,但这并不意味着该服务未与其余Pod连接。
Let’s solve it using a headless service:
让我们使用无头服务来解决它:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
clusterIP: None **this is the key***
selector:
app: my-app
ports:
- name: grpc
protocol: TCP
port: 50051
targetPort: 50051After creating the headless service the nslookup looks like a bit different, now it returns the records associated with it (the pods IPs grouped into the service) giving to the gRPC client better visibility of the number of servers that need to be reached.
创建无头服务后,nslookup看起来有些不同,现在它返回与其关联的记录(将pod IP分组到服务中),从而使gRPC客户端可以更好地了解需要访问的服务器数量。
Now that you have seen the gRPC client configuration you must know why it is important that the Kubernetes service returns the IPs associated with the set of pods, and the reason is that the client can have visibility all servers that need to establish the connections. There is one caveat that you probably already realized at this point and is that the balancing responsibility is now in the client part and not in the Kubernetes side, the main task we need from Kubernetes now is to keep up to date the list of pods associated to the service.
现在,您已经看到了gRPC客户端配置,您必须知道Kubernetes服务返回与Pod集合相关联的IP的重要性,并且原因是该客户端可以查看所有需要建立连接的服务器。 此时您可能已经意识到一个警告,那就是平衡责任现在在客户端而不是Kubernetes端,我们现在需要Kubernetes的主要任务是保持最新的Pod列表服务。
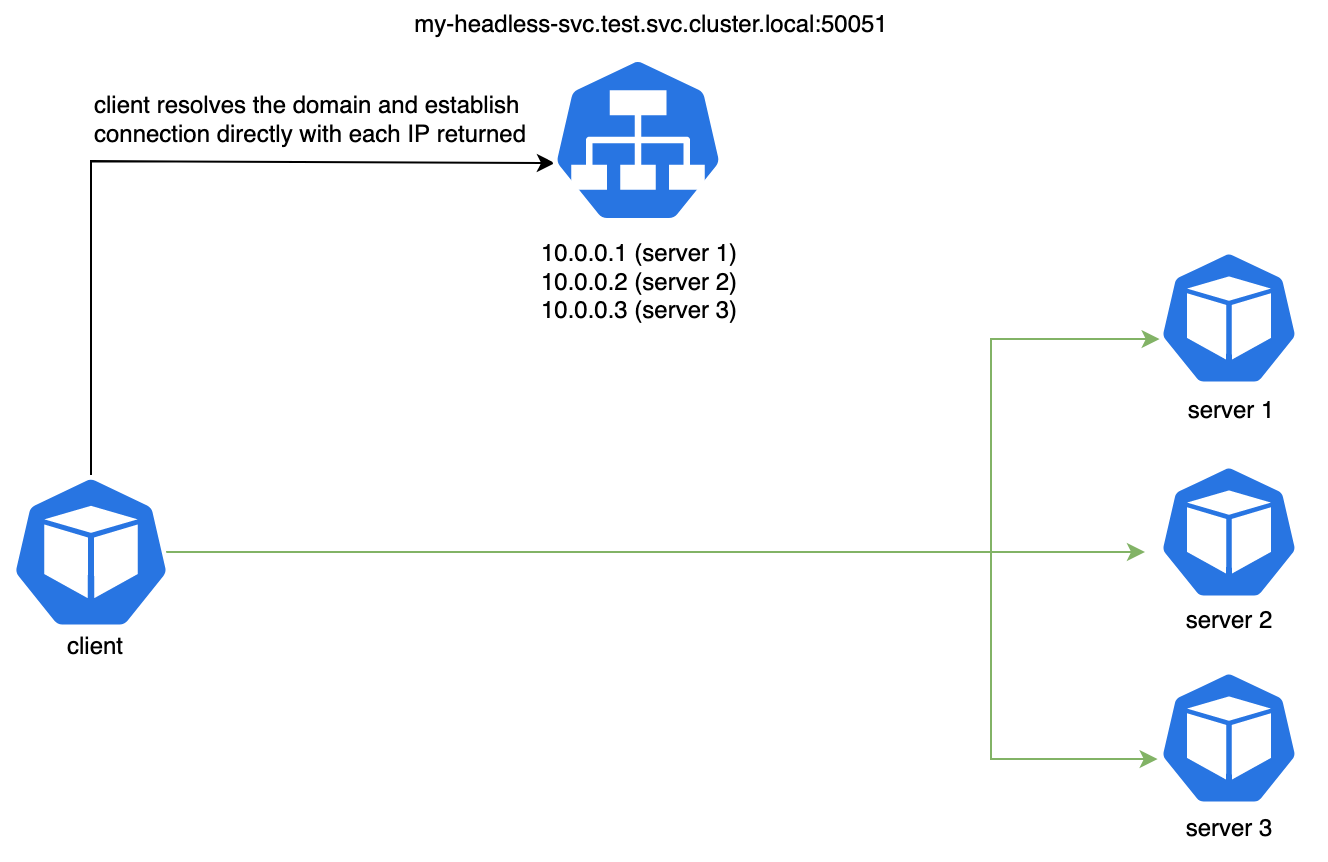
As you can see in the picture the connection changes a little bit, now we do not go through the Kubernetes service to reach the pod, instead we use the Kubernetes service to retrieve the list of pods linked to the domain and then we make the connection directly with the pods, but do not get scared about connecting directly to the pods since we set the DNS resolver type in the client that will keep watching the changes against the headless service, and will keep up to date the connections with the pods available.
如您在图片中看到的那样,连接发生了一点变化,现在我们不再通过Kubernetes服务来访问Pod,而是使用Kubernetes服务来检索链接到域的Pod列表,然后进行连接直接在Pod上进行操作,但不要担心直接连接到Pod,因为我们在客户端中设置了DNS解析器类型,该类型将继续监视无头服务的更改,并保持与可用Pod的连接的最新状态。
为什么不使用服务网格? (Why not using then a service mesh?)
If you can, please do it, with a service mesh all this set up is transparent, and the best part is that it is language agnostic. The key difference is that the service mesh leverage the sidecar pattern and a control plane to orchestrate the inbound and outbound traffic also has visibility of all the network and traffic type (HTTP, TCP… etc) being is able to balance the request properly. In a nutshell, if you are not using a service mesh you need either to get connected to multiple servers directly form each client or to connect to an L7 proxy to help to balance the requests.
如果可以的话,请使用服务网格来做到这一点,所有这些设置都是透明的,最好的部分是它与语言无关。 关键区别在于,服务网格利用边车模式和控制平面来协调入站和出站流量,还具有所有网络和流量类型(HTTP,TCP…等)的可见性,能够适当地平衡请求。 简而言之,如果您不使用服务网格,则需要直接从每个客户端连接到多个服务器,或者需要连接到L7代理以帮助平衡请求。
奖金 (Bonus)
Although the previous set up works I had a problem trying to re-balance the connections when pod rotation or scales-up happened in the cluster in alpine linux images, and after some research, I realized that I was not the only with the same kind of problem, check here and here some github issues related. That’s why I decided to create my own resolver that you can take a look here, the custom resolver I created is a very basic but functional now the gRPC clients were able to listen for domain changes again, adding to the library a configurable listener that does X period of time a lookup to the domain and updates the set of IPs available to the gRPC connection manager, more than welcome if you want to contribute.
尽管先前的设置可以解决问题,但是当在高山linux映像中的集群中发生pod旋转或放大时,我尝试重新平衡连接时遇到了问题,经过一番研究,我意识到我并不是唯一一个拥有相同种类的人问题,请在此处和此处检查一些与github有关的问题。 这就是为什么我决定创建自己的解析器的原因,您可以在此处查看,我创建的自定义解析器是一个非常基本的功能,但是现在gRPC客户端能够再次侦听域更改,从而向库中添加了一个可配置的侦听器X时段查找域并更新gRPC连接管理器可用的IP集,如果您想贡献的话,欢迎您。
On the other hand, since I wanted to go deeper I decided to create my own gRPC proxy (and I learned a lot), leveraging the http2 foundation that gRPC has I could create a proxy without changing the proto payload message or without even knowing the proto file definition (also using the customer resolver aforementioned).
另一方面,由于我想更深入,所以我决定创建自己的gRPC代理(并且学到了很多东西),利用http2基础,即gRPC可以创建代理,而无需更改原始有效负载消息,甚至不知道原型文件定义(也使用前面提到的客户解析器)。
As a final comment, I would like to say that If your gRPC client needs to get connected with many servers I highly recommend using a proxy as a mechanism of balancing since having this in the main application will increase the complexity and resource-consuming trying to keep many open connections and re-balancing them, picture this, having the final balancing in the app you would have 1 instance connected to N servers (1-N), yet with a proxy, you would have 1 instance connected to M proxies connected to N servers (1-M-N) where for sure M<N since each proxy instance can handle a lot of connections to the different servers.
最后,我要说的是,如果您的gRPC客户端需要与许多服务器建立连接,我强烈建议您使用代理作为一种平衡机制,因为在主应用程序中使用代理会增加复杂性和资源消耗,保持许多打开的连接并重新平衡它们,如图所示,在应用程序中达到最终平衡后,您将有1个实例连接到N个服务器(1-N),但是如果使用代理,您将有1个实例连接到M个代理到N个服务器(1-MN),因为每个代理实例都可以处理到不同服务器的大量连接,所以确保M <N。
翻译自: https://medium.com/@cperez08/balancing-grpc-traffic-in-k8s-without-a-service-mesh-7005be902ef3
k8s grpc

















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









