





aws远程gui
GitHub Repo /源代码在这里!(GitHub Repo / Source Code Here!)
2020–09–10:布莱恩公园草坪公开赛吗? (2020–09–10: Is the Bryant Park Lawn Open?)
背景故事: (Backstory:)
When I used to work at a Data Analytics firm in Times Square, I’d frequently enjoy lunch on the beautiful Bryant Park Lawn. I could check https://bryantpark.org/ to see if the lawn was currently open, but the org page loaded somewhat slowly; it was full of images I didn’t care about.
当我以前在时代广场的一家数据分析公司工作时,我经常在美丽的布莱恩公园草坪上享用午餐。 我可以检查https://bryantpark.org/来查看草坪当前是否处于打开状态,但是组织页面的加载速度有些缓慢。 到处都是我不在乎的图像。
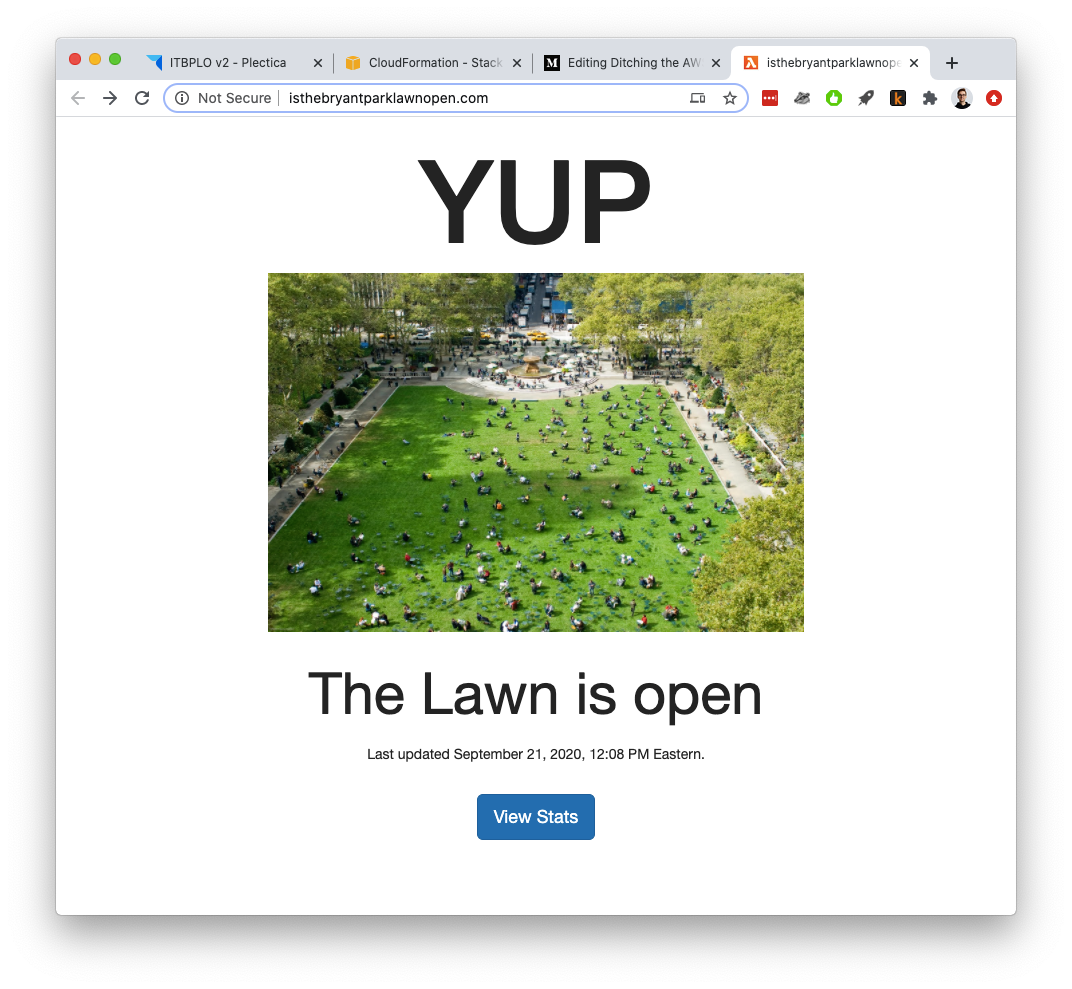
Because of this (and a desire to learn AWS things), I spun up a dumb single-serving website from an ec2 box, which just said whether or not the lawn was open. You’d go to “is the bryant park lawn open dot com” and see this:
因此(出于学习AWS事物的愿望),我从ec2盒中创建了一个愚蠢的单一服务网站,该网站仅说明草坪是否开放。 您将转到“是Bryant公园草坪开放点com ”,并看到以下内容:
In the malaise of the COVID pandemic, my humble site has fallen into disrepair, offering the opportunity to make some retrofits. The last time I worked on this, I relied heavily upon the clicking around in the AWS GUI console method, in a web browser—a behavior I’d like to get away from.
在COVID大流行的不景气中,我不起眼的站点已经失修,提供了进行一些改造的机会。 上次我在这工作,我很依赖的点击周围的AWS GUI控制台方法,我想从脱身的web浏览器的行为。
目标: (Goal:)
Today, I’m setting out to re-engineer this (whimsical, arguably “dumb” or “nobody-asked-for-this”) service as an AWS-based serverless infrastructure—leveraging the SAM CLI, provisioning with CloudFormation, and leaning on a variety of other code and infra tools. I want to do this without touching the GUI AWS console to the extent that I can: CLI and scripting all the way!
今天,我列明重新设计这个(异想天开,可以说是“哑”或“没人问的换本”)服务作为基于AWS-无服务器基础设施-leveraging的SAM CLI,与CloudFormation供应,并靠在在各种其他代码和基础工具上。 我希望做到这一点而又不触及GUI AWS控制台:我一直可以使用CLI和脚本!
架构流程图: (Architecture Flow Chart:)
Here’s a little map of the services I think I’ll need: It’s all centered around a little database, an s3 bucket website, and some AWS Lambda functions.
这是我认为我需要的服务的简要地图:所有这些都围绕一个小数据库,一个s3存储桶网站以及一些AWS Lambda函数。
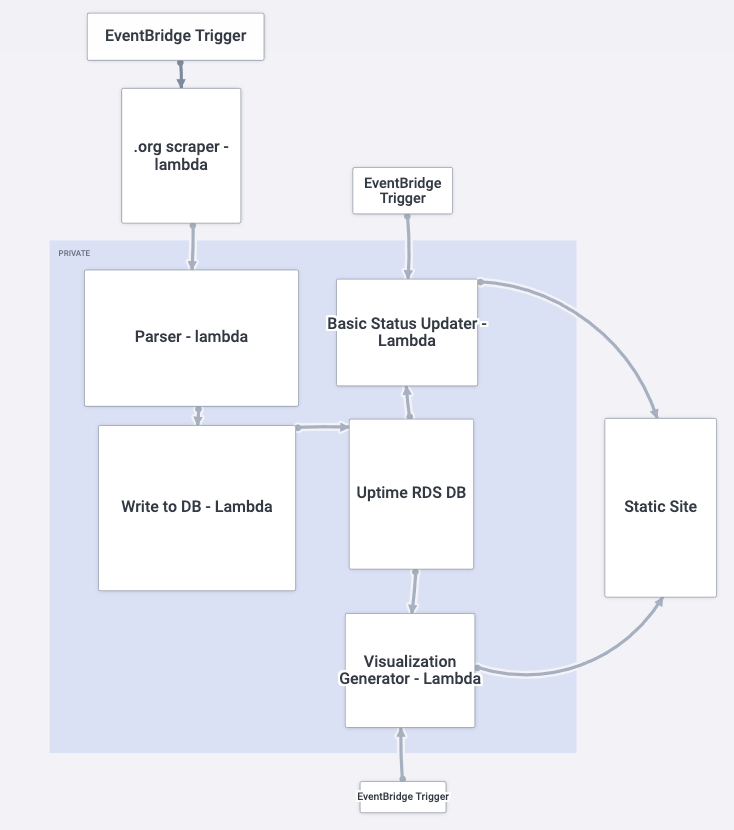
每个服务的使用方式:(How Each Service Will Be Used:)
CloudFormation: (CloudFormation:)
Provision all of the following services at once from YAML templates
从YAML模板一次配置以下所有服务
Be tracked in version control; be infrastructure-as-code
在版本控制中被跟踪; 基础架构即代码
- Learn good DevOps practices (this boy is looking for a new job)学习良好的DevOps做法(这个男孩正在寻找新工作)
RDS数据库: (RDS Database:)
- Warehouse our open/closed binary lawn data, plus minimal metadata 仓库我们的打开/关闭的二进制草坪数据,以及最少的元数据
- Be protected from the public by sitting in a private subnet, only accessible by Lambda functions通过坐在私有子网中仅受到Lambda函数访问,可以免受公众的攻击
- Discard old rows after we have ~35,040 data points. (Arbitrary…2 years) 在拥有约35,040个数据点后,丢弃旧行。 (任意... 2年)
S3存储桶: (S3 Buckets:)
Buckets are object storage containers. They can warehouse files, and also serve static websites. I’ll need buckets for the following:
桶是对象存储容器。 他们可以存储文件,还可以服务静态网站。 我需要以下桶:
Host a stupid simple static website made of HTML/CSS/ES6
托管一个由HTML / CSS / ES6组成的愚蠢的简单静态网站
- Warehouse code packages for Lambda functionsLambda函数的仓库代码包
Route53:(Route53:)
- At least give our stupid site a custom domain name 至少给我们的愚蠢站点一个自定义域名
EventBridge(以前称为CloudWatch):(EventBridge (formerly CloudWatch):)
Trigger Lambda functions on cron schedules
在Cron时间表上触发Lambda函数
Lambda函数(I)至(V):(Lambda Functions (I) thru (V):)
For getting some computin’ done, serverless functions-as-a-service bypass the cost overhead of commissioning cloud servers. You can just let AWS manage the server infra, and get billed only for when your code actually runs, as triggered by some event or schedule. Here are the functions I’ll need:
为了完成一些计算,无服务器功能即服务绕过了调试云服务器的开销。 您可以让AWS在下面管理服务器,并且仅在代码实际运行时(由某些事件或时间表触发)进行计费。 这是我需要的功能:
I) Scraper:
I)刮板:
- Every half hour, spin up a headless browser to scrape the Bryant park dot org site for a raw lawn-status string (and F° data, why not) 每半小时启动一个无头浏览器,以刮擦Bryant公园点组织站点以获得原始的草坪状态字符串(以及F°数据,为什么不这样)
- Pass the collected raw data to a subsequent parser function 将收集的原始数据传递给后续的解析器函数
II) Parser:
II)解析器:
- Accept raw data from the Scraper function 从Scraper功能接受原始数据
- Parse raw lawn status string into a binary variable将原始草坪状态字符串解析为二进制变量
- Generate other fun metadata like day-of-week and hour-of-day生成其他有趣的元数据,例如星期几和一天中的小时
- Pass the parsed data to the RDS writer将解析的数据传递给RDS编写器
III) RDS Writer:
III)RDS编写器:
- Accept clean parsed data from the parser function. 从解析器功能接受干净的解析数据。
- Write a new row to the RDS DB 向RDS数据库写入新行
IV) Basic Status Updater:
IV)基本状态更新器:
- Every half hour, read the last couple rows of the RDS DB 每半小时读取一次RDS数据库的最后两行
- If the lawn status has changed (this condition will avoid unnecessarily frequent S3 puts), then update the S3 bucket site’s index page如果草坪状态已更改(这种情况将避免不必要地频繁放置S3),则更新S3存储桶站点的索引页
V) Viz Generator:
V)Viz生成器:
- Twice daily, load the entire table into memory and run some aggregations 每天两次,将整个表加载到内存中并运行一些聚合
- Generate Plotly HTML visualizations with aggregate data使用汇总数据生成Plotly HTML可视化
- Push those charts to a “stats” page on the simple S3 site将这些图表推送到简单S3网站上的“统计信息”页面
使用CloudFormation设置VPC / DB(Provisioning a VPC/DB with CloudFormation)
Time to start building our CloudFormation stack .yml! This is the document we submit over the CloudFormation CLI to stand up all of the resources we will need, all at once, in perfect orchestrated harmony. I’ve been poring over the CloudFormation docs on AWS to figure out what this should look like:
是时候开始构建我们的CloudFormation堆栈.yml了! 这是我们通过CloudFormation CLI提交的文档,旨在一次完美地协调协调我们将需要的所有资源。 我一直在研究AWS上的CloudFormation文档,以了解其外观:

# Excerpts from the .yml, provisioning more resources...lawnDBsubnetGroup: # RDS DB needs a subnet group. This is it
Type: AWS::RDS::DBSubnetGroup
Properties:
DBSubnetGroupDescription: The two private subnets
DBSubnetGroupName: lawn-DB-subnet-Group
SubnetIds:
- !Ref lawnSubnetPrivateA
- !Ref lawnSubnetPrivateBI haven’t had a chance to test and debug today, but I’ve gotten the ball rolling declaring my cloud infrastructure (network config, security rules, database instance) for this app. A crucial resource in setting up my network was this blog post about keeping your RDS instances private while still giving Lambda RDS access, without sacrificing web access for the Lambdas.
今天我还没有机会进行测试和调试,但是我已经宣布了此应用程序的云基础架构(网络配置,安全规则,数据库实例)。 设置我的网络的重要资源是此博客文章,内容涉及在保持RDS实例私有性的同时仍提供Lambda RDS访问权限,而不牺牲Lambda的Web访问权限。
The hard part of this (private subnet RDS + Lambdas with web access) is setting up a cheap NAT instance (the hard, manual way via ec2 AMI’s) rather than simply provisioning an expensive pre-baked NAT Gateway in CloudFormation. Going the easy way has cost me in the past, in dollars.
困难的部分(具有Web访问权限的私有子网RDS + Lambda)是设置便宜的NAT实例(通过ec2 AMI的困难的手动方式),而不是在CloudFormation中简单地配置昂贵的预烘焙NAT网关。 过去,走简单路已经花了我很多钱。
2020–09–11:部署试验和错误 (2020–09–11: Deployment Trial and Error)
I’m iteratively building this CloudFormation .yml template with (for now) just a fresh VPC, some subnets, security groups / subnet groups, and an RDS DB—no Lambda functions or S3 bucket site yet.
我正在迭代构建CloudFormation .yml模板,此模板(现在)仅包含一个新的VPC,一些子网,安全组/子网组和一个RDS数据库-尚无Lambda功能或S3存储桶站点。
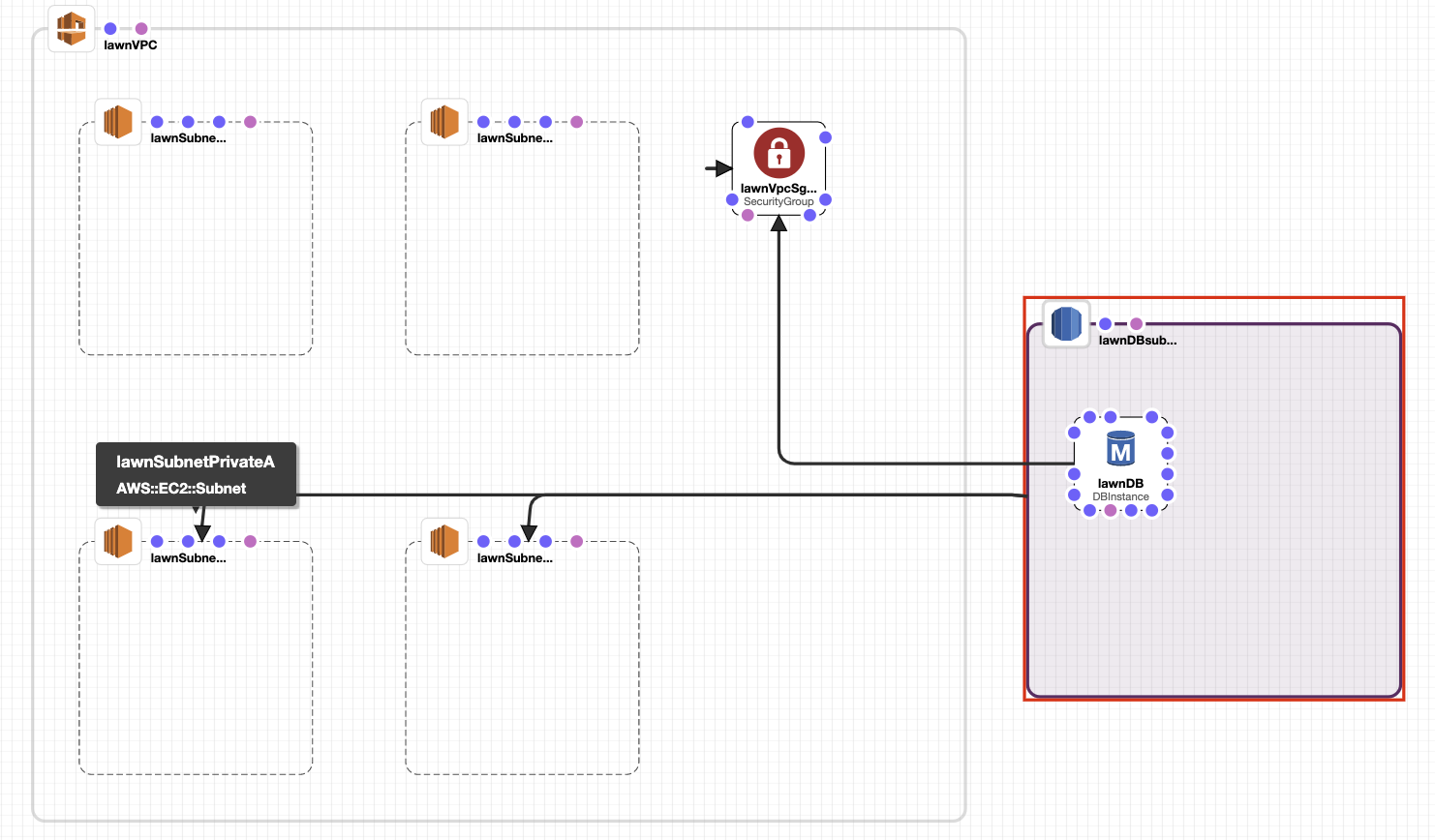
Initial attempts to deploy this stack .yml result in errors, because there’s no way I was going to do this right the first time:
最初尝试部署此堆栈.yml会导致错误,因为我没有办法第一次正确执行此操作:
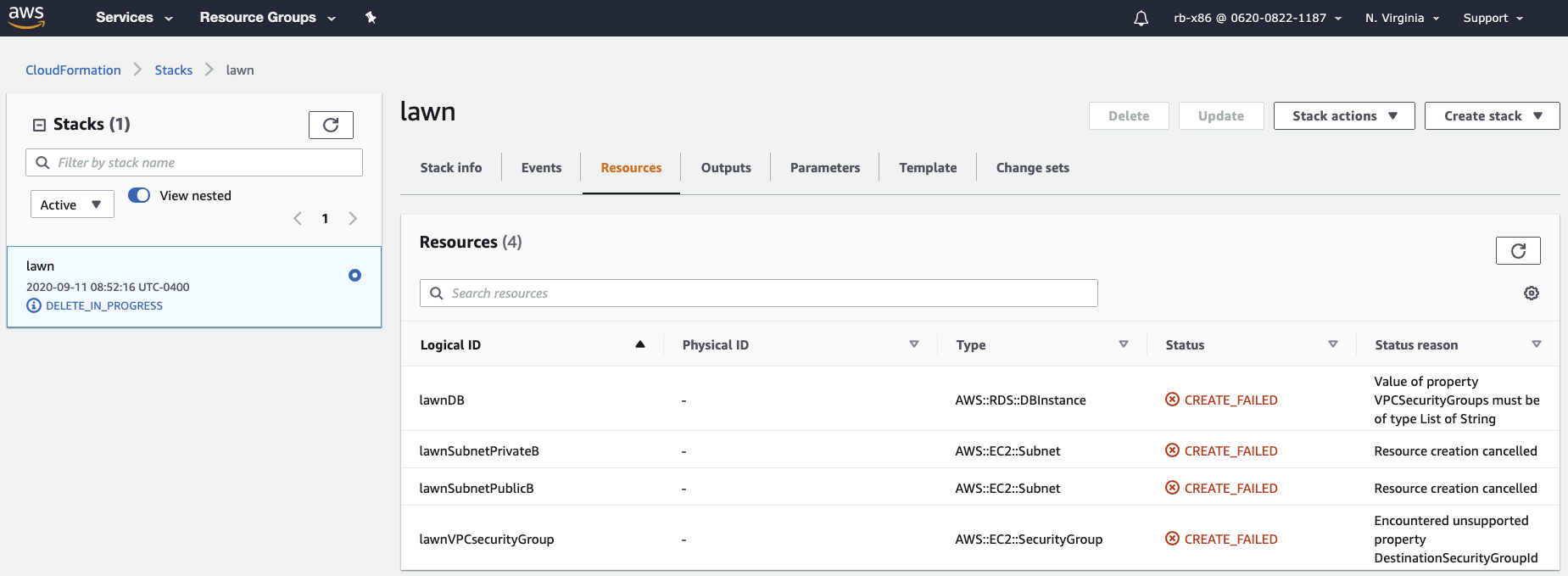
Ok, so we get some reasonable errors, e.g. for the “lawnDB” resource (my RDS database), it didn’t launch because I got Value of property VPCSecurityGroups must be of type List of String. Initially, I just gave it one string, not a list of strings, my error. I’ll recursively correct these errors and keep attempting to validate/deploy. I’m curious about the !ref function in CloudFormation now too…
好的,所以我们得到了一些合理的错误,例如,对于“ lawnDB”资源(我的RDS数据库),它没有启动,因为我得到Value of property VPCSecurityGroups must be of type List of String 。 最初,我只是给了我一个错误,而不是字符串列表。 我将递归纠正这些错误,并继续尝试验证/部署。 我现在也对CloudFormation中的!ref函数感到好奇…
It turns out that the !ref function is essential in CloudFormation. For example, if you provision a VPC and a subnet to go inside it, the subnet probably needs to !Ref the VPC’s logical name (the name you give it in the YAML) in order to belong to that VPC. Here’s what I mean:
事实证明,对!ref功能是必不可少的CloudFormation。 例如,如果您将VPC和一个子网置入其中,则该子网可能需要!Ref VPC的逻辑名(您在YAML中指定的名称)才能属于该VPC。 这就是我的意思:
# Inside the CF stack .yml:
# See bolded text for relevant bitsAfter getting the hang of CloudFormation templates, it seems like I have the beginnings of an infrastructure in place, just some network organization crap and a DB:
掌握了CloudFormation模板之后,似乎已经有了基础架构的开始,只是一些网络组织的废话和一个数据库:

This .yml is already getting to be a long file! Is there a way I can break it up? Evidently, yes. We can nest CF stacks or import/export values between stacks with Outputs. I’ll do that:
这个.yml已经很长了! 有办法分解吗? 显然,是的。 我们可以嵌套CF堆栈或使用Outputs在堆栈之间导入/导出值。 我会去做:
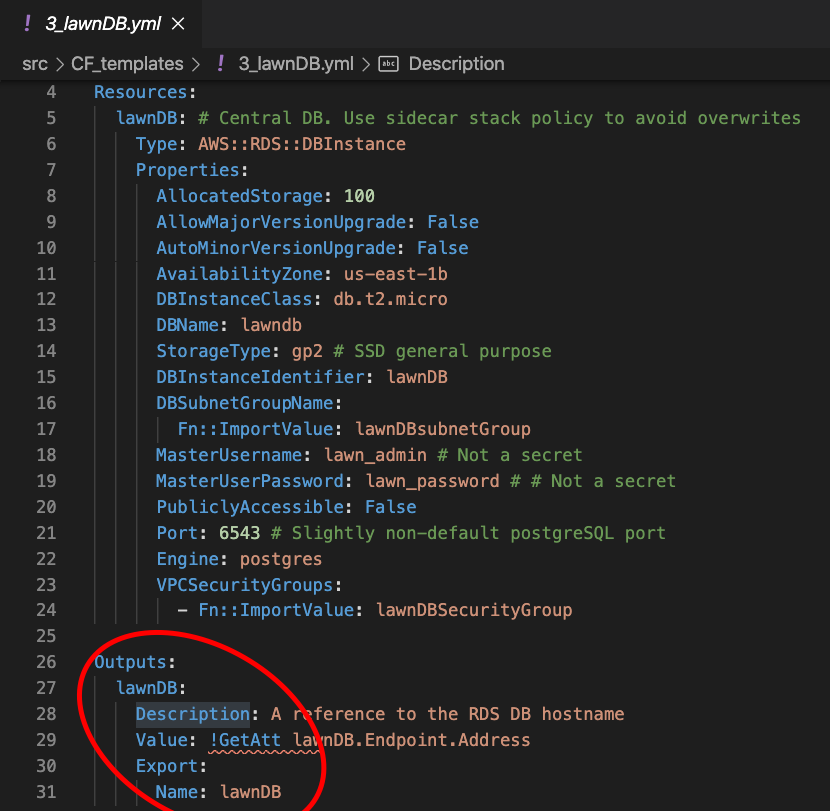
It feels good to modularize the CloudFormation templates, in the same way that we would break up ominously large Python modules into several.
模块化CloudFormation模板感觉很好,就像我们将庞大的Python模块分成几个模块一样。
Next, I’ll attempt to assemble the Lambda functions mentioned above. This is where I get to try debugging Lambda functions locally via the SAM CLI (and docker) for the first time!
接下来,我将尝试组装上述Lambda函数。 这是我第一次尝试通过SAM CLI(和docker)在本地调试Lambda函数的地方!
2020–09–16:Lambda和CloudFormation (2020–09–16: Lambda and CloudFormation)
How exactly does Lambda fit into this CloudFormation infrastructure-as-code model? I’ll just launch them into their own “stacks” and assign them IAM roles that give them permission to do things like write to RDS and call each other. In retrospect, maybe nested stacks would have been a better approach because now I’m cluttering up the exported variable namespace in this CloudFormation region.
Lambda如何完全适合此CloudFormation基础架构代码模型? 我将它们启动到自己的“堆栈”中,并为其分配IAM角色,以授予他们执行写RDS和互相调用之类的权限。 回想起来,也许嵌套堆栈会是一种更好的方法,因为现在我在这个CloudFormation区域中整理了导出的变量名称空间。
功能一:刮板 (Function I: Scraper)
I found a handy repo that generates a lambda function that can scrape the web with a headless selenium browser. Thanks, Christopher! Now to adapt it into my own scraper function, to collect info about the park lawn:
我找到了一个方便的仓库,可以生成lambda函数,该函数可以使用无头的Selenium浏览器抓取Web 。 谢谢克里斯托弗! 现在将其调整为我自己的刮板功能,以收集有关公园草坪的信息:
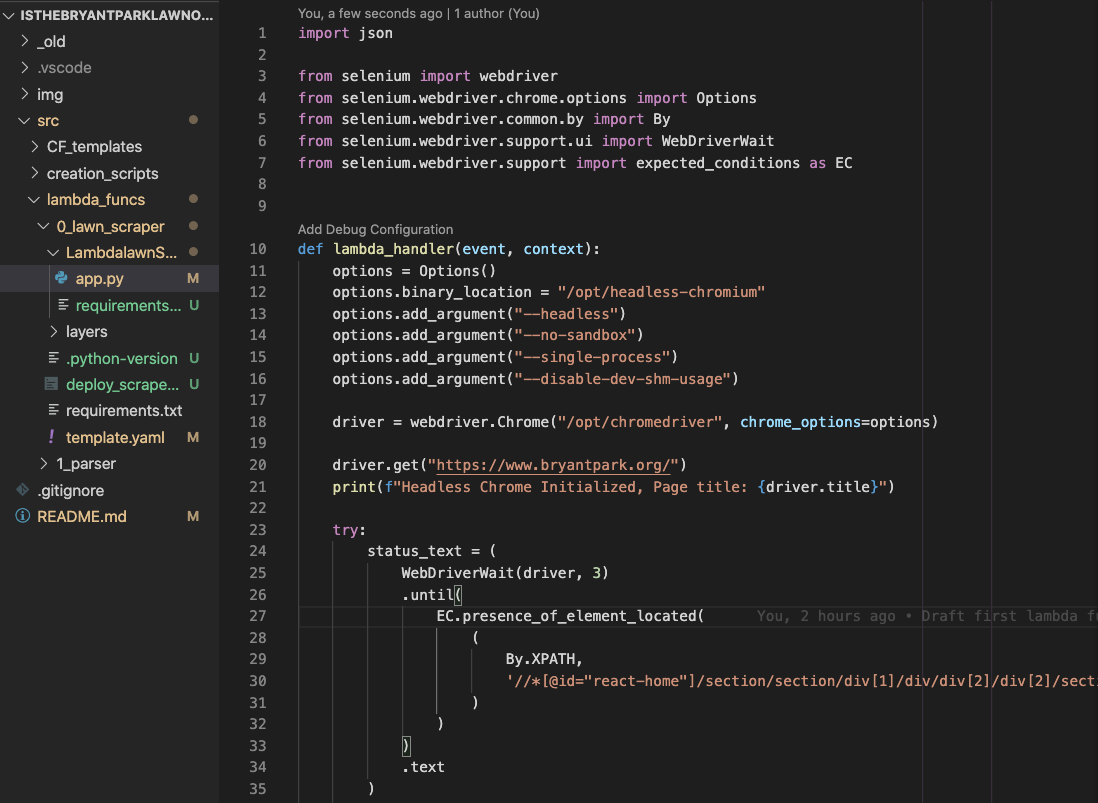
Using the SAM (Serverless Application Model) CLI from AWS, I was able to quickly re-use and debug this code to scrape for the text fields I wanted from the .org website. $ sam build -u && sam local invoke is my new jam.
使用来自AWS的SAM(无服务器应用程序模型)CLI ,我能够快速重用和调试此代码,以从.org网站中抓取所需的文本字段。 $ sam build -u && sam local invoke是我的新手。
功能二:解析器 (Function II: Parser)
This is the bit that translates the scraped string from the .org website into a binary variable. I have a feeling this is the least durable part of my “app,” since I don’t know the range of possible values that might exist for this scraped text field. So far all I’ve seen is “lawn is open” and “lawn is closed.” I will continually update this function when new possible values arise. The nice thing is that it is its own lambda function, with its own logs and failure rates. Maybe I’ll set up text message failure notifications later with AWS SNS.
这是将.org网站中抓取的字符串转换为二进制变量的位。 我觉得这是我的“应用”中最不耐用的部分,因为我不知道此抓取文本字段可能存在的值范围。 到目前为止,我所看到的只是“草坪是开放的”和“草坪是封闭的”。 当出现新的可能值时,我将不断更新此功能。 令人高兴的是它是自己的lambda函数,具有自己的日志和故障率。 也许稍后我将使用AWS SNS设置短信失败通知。
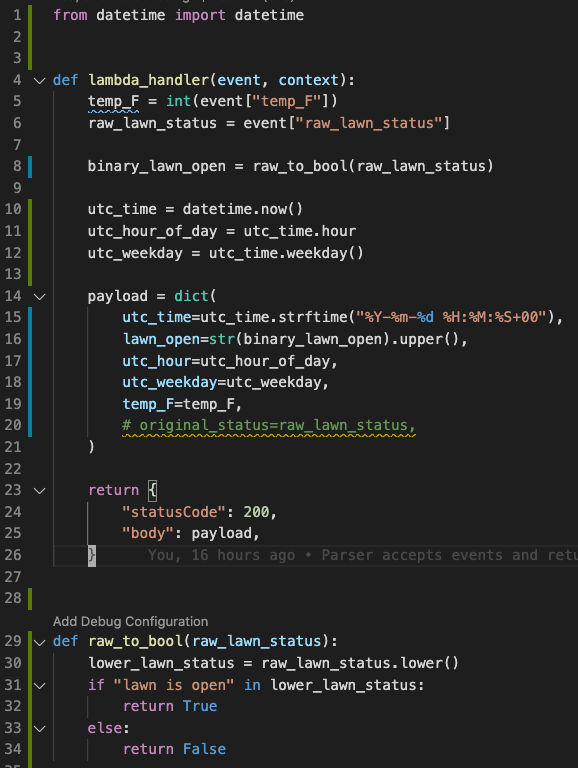
By the way, all of the original code for this is public on GitHub, if you missed that earlier!
顺便说一下,如果您之前错过了它,那么所有的原始代码都将在GitHub上公开!
功能三:RDS Writer (Function III: RDS Writer)
Ultimately, I decided that the RDS writer function will be one to run on a schedule, and call child functions I (scraper) and II (parser) synchronously via boto3:
最终,我决定将RDS编写器函数按计划运行,并通过boto3同步调用子函数I(抓取器)和II(解析器):
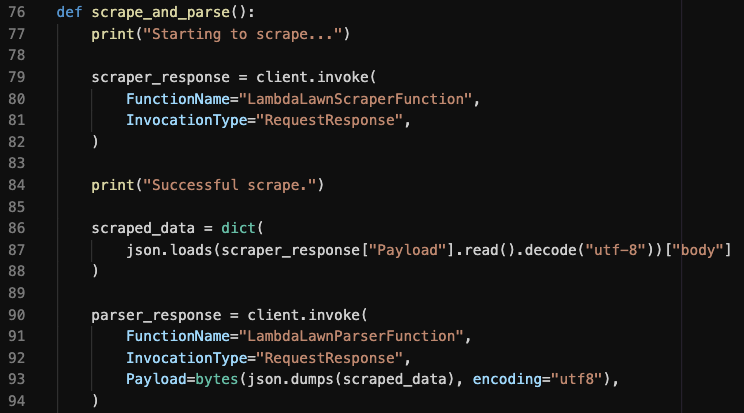
This Lambda function has permission to call other lambda functions and modify the RDS database we provisioned in the CloudFormation templates. It is ultimately responsible for getting new data and writing it to the database. I read somewhere that it’s a good idea to make sure the parent Lambda function doesn’t time out before its child functions complete their work.
此Lambda函数有权调用其他lambda函数并修改我们在CloudFormation模板中设置的RDS数据库。 它最终负责获取新数据并将其写入数据库。 我在某处读到,确保父Lambda函数在其子函数完成工作之前不会超时是个好主意。
功能四:站点更新器 (Function IV: Site Updater)
This is the function that reads from the DB, spits out one of two possible HTML documents (based on the binary “open” or “closed” lawn status), and pushes that document to the s3 bucket serving our humble site:
该函数从数据库读取,吐出两个可能HTML文档之一(基于二进制的“打开”或“关闭”草坪状态),然后将该文档推送到服务于我们不起眼站点的s3存储桶:
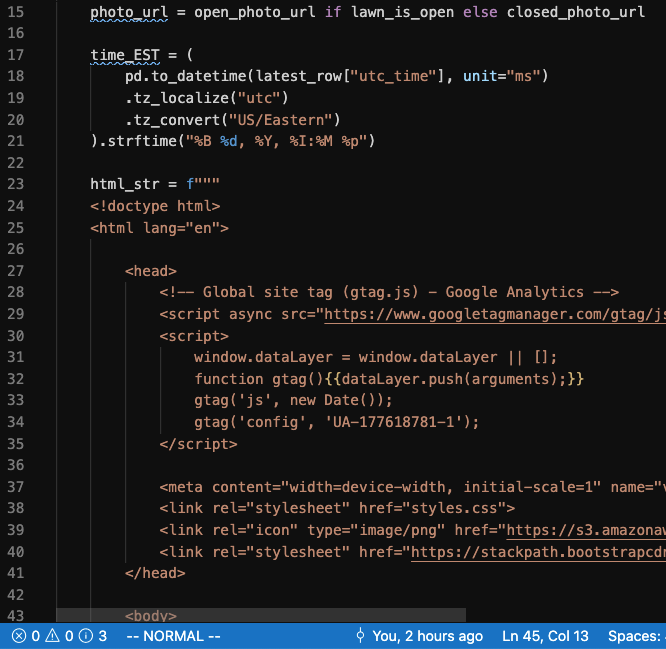
2020–09–21:网站备份 (2020–09–21: Site Back Up)
Now that we’re scraping data, squirreling it away into a database, and referencing that DB to write HTML to a static S3 bucket site…we have a living, breathing web service!
现在,我们正在抓取数据,将其存储到数据库中,并引用该数据库以将HTML写入静态S3存储桶站点中……我们拥有了一个充满活力的Web服务!
A friend brought TerraForm to my attention, which I did not know existed since I’ve been stuck in my AWS fanboy bubble. TerraForm seems like the next natural thing to learn (after e.g. AWS CloudFormation or Google Cloud Deployment Manager) for anybody curious about infrastructure-as-code.
一个朋友引起了我的注意,因为我一直陷在AWS迷迷中,所以我不知道TerraForm的存在。 对于任何对基础架构即代码感到好奇的人,TerraForm似乎是接下来要学习的自然知识(例如,AWS CloudFormation或Google Cloud Deployment Manager之后)。
功能V:图形统计生成器 (Function V: Graphical Stats Generator)
The idea is to build a little Plotly dashboard page showing aggregate historical data on lawn open-ness by day-of-week and hour-of-day.
这个想法是建立一个小小的Plotly仪表盘页面,该页面按星期和一天中的小时显示草坪开放度的总历史数据。
Before I can build a summary stats page, I’ll let my lambda functions scrape about a week’s worth of data to the RDS database while I apply for jobs, cook lasagna and various hearty soups, and play through Breath of the Wild.
在构建摘要统计信息页面之前,我将让我的lambda函数将大约一周的数据抓取到RDS数据库中,同时我申请工作,烹饪烤宽面条和各种丰盛的汤,并玩遍野生呼吸。
I will come back to this on ~2020–09–28.
我将在〜2020–09–28再次讨论。
2020–09–28:统计页面 (2020–09–28: Stats Page)

The simple stats page is working! For now, it’s just one Plotly heatmap showing the Bryant Park Lawn’s historical average open-ness at different times of day and days of the week, based on my 2x/hour sampling.
简单的统计信息页面正在运行! 目前,这只是一张Plotly热图,根据我的2x /小时采样,它显示了布莱恩公园草坪在一天中的不同时间和一周中的几天的历史平均开放度。
To add this page, first I wrote a lambda function to exfiltrate the entirety of my RDS SQL DB/table to a .csv in an S3 bucket, so I could download it and experiment with throwing it at Plotly in a Jupyter notebook. Sometimes it’s really helpful to be able to debug locally as much as possible, thus the experimentation with SAM in this small project.
要添加此页面,首先,我编写了一个lambda函数,将我的RDS SQL DB /表的整个内容提取到S3存储桶中的.csv中,因此我可以下载它并尝试在Jupyter笔记本中将其扔到Plotly。 有时,尽可能地进行本地调试确实很有帮助,因此在这个小项目中进行SAM实验。
Then I adapted the resulting working viz generator code from Jupyter to go back into the Lambda function (V), which updates the new “stats” page every 12 hours.
然后,我从Jupyter修改了生成的工作viz生成器代码,以返回到Lambda函数(V),该函数每12小时更新一次新的“统计信息”页面。
Something that bugged me was that adding another .HTML page to my s3 bucket site did not automatically make that page “loadable” in the browser. When I was debugging, my browser kept trying to download the .HTML document to my local drive instead of just rendering it. Annoying!
让我感到困扰的是,向我的s3存储桶站点添加另一个.HTML页面并没有自动使该页面在浏览器中“可加载”。 当我进行调试时,我的浏览器一直在尝试将.HTML文档下载到本地驱动器上,而不仅仅是呈现它。 烦人!
At first, I thought this was happening because S3 bucket sites don’t support server-side scripting, and maybe I had accidentally included some server-responsible code..? But no. A web search made me realize that I just needed to make sure to include the “content-type” of the s3 object on upload (put) in order for it to be served properly:
起初,我以为是因为S3存储桶站点不支持服务器端脚本,所以可能发生了,也许我不小心包含了一些服务器负责的代码。 但不是。 通过网络搜索,我意识到我只需要确保在上载(放置)时包含s3对象的“内容类型”即可正确投放:

结论(Conclusion)
With that, I’m feeling ready to move on to perhaps a less hello-worldy project! In the future, I’d like to investigate: Nested CloudFormation stacks, getting away from the “stock” web stack of HTML/CSS/ES6 (TypeScript? Node? React?), and leveraging some machine learning (regression/classification) in more of my future projects, which is something I’m already pretty familiar with. I’m also curious about Kafka/SQS, DynamoDB, and managing user credentials and sessions; I know very little of those things, as of this writing.
有了这一点,我已经准备好继续进行也许不太现实的项目! 将来,我想研究:嵌套的CloudFormation堆栈,摆脱HTML / CSS / ES6的“常规” Web堆栈(TypeScript?Node?React?),并利用其中的一些机器学习(回归/分类)我未来的更多项目,这是我已经很熟悉的东西。 我也对Kafka / SQS,DynamoDB以及管理用户凭据和会话感到好奇; 在撰写本文时,我对这些事情知之甚少。
What I’m most excited about is the chance to solve some real-world problems! Look me up if you think I might be able to develop some software that would make (repetitive, annoying parts of) your life easier, or if you’re building something yourself (a developer team?) and you think I could be of assistance.
我最兴奋的是有机会解决一些现实世界中的问题! 如果您认为我可能能够开发出一些可以使您的生活(重复的,令人讨厌的部分)变得更轻松的软件,或者您自己(开发人员团队)建立了某种东西,并且您认为我可以提供帮助,请来找我。
翻译自: https://towardsdatascience.com/ditching-the-aws-gui-console-ac77f46a05fa
aws远程gui















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









