






java 数据建模
Modelling data is a crucial aspect of software engineering. Choosing appropriate data structures or databases is fundamental to the success of an application or a service.
数据建模是软件工程的关键方面。 选择合适的数据结构或数据库对于应用程序或服务的成功至关重要。
In this article, I will discuss some techniques related to modelling data domains with graphs. In particular, I will show how labelled property graphs, and graph databases, can be an effective solution to some of the challenges we sometimes encounter with other models, such as relational databases, when we deal with highly-connected data.
在本文中,我将讨论与使用图对数据域建模有关的一些技术。 特别是,我将展示带标签的属性图和图形数据库如何有效地解决我们在处理高度连接的数据时有时会与其他模型(例如关系数据库)一起遇到的一些挑战。
By the end of this article we will have a simple — but fully functional — implementation of an in-memory labelled-property graph in Java. We’ll use this graph to run some queries on a sample dataset.
到本文结束时,我们将在Java中实现内存中标记属性图的简单(但功能齐全)实现。 我们将使用此图在样本数据集上运行一些查询。
All the code presented here can be found on GitHub.
样本域:书评 (Sample domain: book reviews)
Before writing this article, I headed over to kaggle.com and browsed through some of the data sets available there. Eventually, I picked this book review data set which we’ll use as a running example throughout this article.
在撰写本文之前,我先去了kaggle.com并浏览了那里可用的一些数据集。 最终,我选择了本书的书评数据集,在本文中我们将其作为一个运行示例。
This data set contains the following CSV files:
该数据集包含以下CSV文件:
BX-Users.csv, with anonymised user data. Each user has a unique id, location and age.
BX-Users.csv ,带有匿名用户数据。 每个用户都有唯一的ID,位置和年龄。
BX-Books.csv, which contains each book’s ISBN, title, author, publisher and year of publication. This file also contains links to thumbnail pictures, but we won’t use those here.
BX-Books.csv ,其中包含每本书的ISBN,书名,作者,出版者和出版年份。 该文件还包含指向缩略图的链接,但是我们在这里不使用它们。
BX-Book-Ratings.csv, which contains a row for each book review.
BX-Book-Ratings.csv ,其中每个书评都包含一行。
If we picture this data set as an entity-relationship (ER) diagram, this is how it would look like:
如果我们将此数据集描绘为实体关系(ER)图,则它将是这样的:
Some fields are denormalized, e.g. Author, Publisher, and Location. While this might or might not be what we eventually want (depending on the performance characteristics of certain queries), at this point let's assume we want our data in normalized form. After normalization, this is our updated ER diagram:
一些字段是非规范化的,例如Author , Publisher和Location 。 尽管这可能不是我们最终想要的(取决于某些查询的性能特征),但在这一点上,让我们假设我们希望我们的数据采用规范化形式。 标准化之后,这是我们更新的ER图:
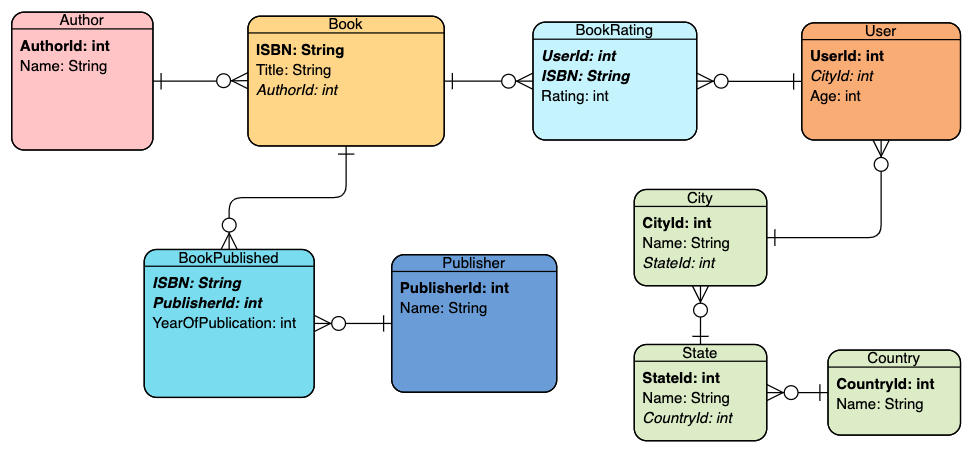
Note that we split Location into 3 tables (City, State, and Country) because the original field contained strings such as "San Francisco, California, USA".
请注意,由于原始字段包含诸如"San Francisco, California, USA"字符串,因此我们将Location分为3个表( City , State和Country )。
Now, suppose we store this data into a relational database. As a thought exercise, how easily can we express these two queries with SQL code?
现在,假设我们将这些数据存储到关系数据库中。 作为思想练习,我们如何轻松用SQL代码来表达这两个查询?
Query 1: get the average rating for each author.
查询1 :获取每个作者的平均评分。
Query 2: get all books reviewed by users from a specific country.
查询2 :获取来自特定国家/地区用户的所有图书。
If you’re familiar with SQL, you’re probably thinking joins: whenever we have relations that span multiple tables, we typically navigate the relations by joining pairs of tables via primary and foreign keys.
如果您熟悉SQL,那么您可能会想到联接:只要我们具有跨多个表的关系,通常就可以通过主键和外键联接成对的表来导航关系。
However, both queries involve a non-trivial amount of joins — especially the second one. This is not necessarily a bad thing — relational databases can be quite good at executing joins efficiently — but it might lead to SQL code that is difficult to read, maintain, and optimize.
但是,两个查询都涉及大量的联接,尤其是第二个联接。 这不一定是一件坏事-关系数据库可以很好地有效执行连接-但它可能导致难以读取,维护和优化SQL代码。
Moreover, in order to navigate many-to-many relationships, we had to create join tables (e.g. BookRating or BookPublished). This is a common pattern which, however, adds some complexity to the overall schema.
此外,为了导航多对多关系,我们必须创建BookPublished表(例如BookRating或BookPublished )。 这是一种常见的模式,但是,这会增加整个模式的复杂性。
We could denormalize some of the data, but this would have the side-effect of locking us into a specific view of our data and causing our model to be less flexible.
我们可以对某些数据进行非规范化,但这会产生副作用,将我们锁定在数据的特定视图中,导致模型的灵活性降低。
使用Java类进行领域建模 (Domain modelling with Java classes)
Now let’s suppose we want to store our entire data set in memory. The sample data set that we got from Kaggle contains less than a million entries, so it will easily fit in memory.
现在,假设我们要将整个数据集存储在内存中。 我们从Kaggle获得的样本数据集包含不到一百万个条目,因此很容易放入内存。
Storing our data in memory is a trivial but perfectly valid approach, especially if we want to support a read-only workload and we don’t need to guarantee write consistency and persistency. If we need to offer those guarantees, we can still store the data in memory, but we’ll probably need to ensure that our data structures are thread-safe and that we somehow persist the changes to non-volatile memory.
将我们的数据存储在内存中是一种琐碎但完全有效的方法,尤其是如果我们要支持只读工作负载并且不需要保证写入一致性和持久性时,尤其如此。 如果我们需要提供这些保证,我们仍然可以将数据存储在内存中,但是我们可能需要确保我们的数据结构是线程安全的,并且以某种方式将更改保留到非易失性内存中。
We’ll start with some classes, for example:
我们将从一些类开始,例如:
public class Book {
String isbn;
String title;
}
public class Author {
String name;
}Soon, though, we are confronted with a question: how do we link these class
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









