





什么是清单? (What is a list?)
Lists are simply a collection of elements. In Python, they are a type of data, denoted by brackets.
列表只是元素的集合。 在Python中,它们是一种数据类型,用方括号表示。
For example, [0, 1, 4] is a list with 3 elements. This is referred to as a one-dimensional list because each element of the list is a number.
例如,[0,1,4]是一个包含3个元素的列表。 这被称为一维列表,因为列表的每个元素都是一个数字。
In the case of 2D lists, each element is another list. Here’s an example:
对于2D列表,每个元素都是另一个列表。 这是一个例子:
[ [2,4,3,8], [8,6,4,0], [0,0,17, 3] ]
[[2,4,3,8],[8,6,4,0],[0,0,17,3]]
This 2D list also has 3 elements, but each of those elements is a list itself.
该2D列表也有3个元素,但是这些元素中的每一个都是列表本身。
遍历一维列表 (Iterating through a 1D list)
Let’s build on the list examples above. To iterate through the 1D list [0, 1, 4] and print each element separated by a space, you could use the following code:
让我们以上面的列表示例为基础。 要遍历一维列表[0,1,4]并打印每个由空格分隔的元素,可以使用以下代码:
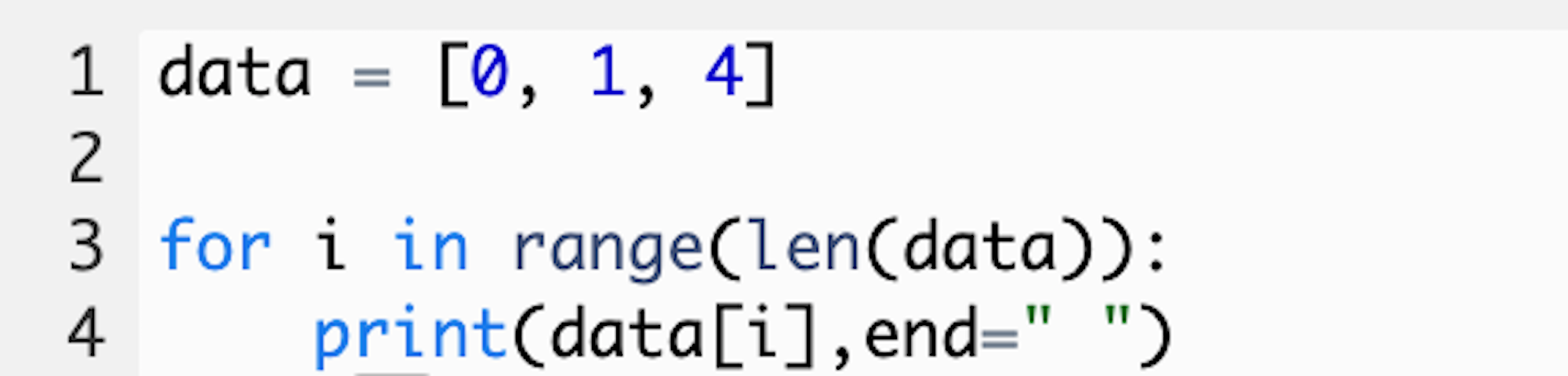
First, the list is assigned to a variable called data. Then we use a for loop to iterate through each element in the range of the list. Unless we specify a starting index for the range, it defaults to the first element of the list. This is index 0, and it’s what we want in this case.
首先,将列表分配给一个名为data的变量。 然后,我们使用for循环遍历列表范围内的每个元素。 除非我们为范围指定起始索引,否则它默认为列表的第一个元素。 这是索引0,在这种情况下,这就是我们想要的。
Thus, we are able to use the shorthand range(len(data)) instead of having to type range(0, len(data)).
因此,我们能够使用速记范围(len(data)),而不必键入range(0,len(data))。
Next, let’s discuss why we use len(data) as the ending index.
接下来,让我们讨论为什么我们使用len(data)作为结束索引。
The for loop goes up to the ending index, but it doesn’t include that index. len(data) is the count of elements in our list. We have 3 elements, so our range goes from index 0 to index 2, just like we want.
for循环上升到结束索引,但不包括该索引。 len(data)是列表中元素的数量。 我们有3个元素,所以我们的范围从索引0到索引2,就像我们想要的那样。
We could have used the syntax range(3), but hardcoding the range would make our for loop less flexible in case the variable data gets modified later on.
我们本可以使用语法range(3),但是对该范围进行硬编码将使我们的for循环较不灵活,以防以后修改变量数据 。
The end= “ ” in the print statement allows you to print on the same horizontal line with a space separating each printed element. If you don’t add this code, your output will appear as a vertical line.
通过打印语句中的end =“” ,您可以在同一水平线上打印,并用空格隔开每个打印的元素。 如果不添加此代码,则输出将显示为垂直线。
The code above outputs 0 1 4.
上面的代码输出0 1 4。
现在让我们遍历2D列表 (Now let’s iterate through a 2D list)
This time, let’s work with the 2D list from above.
这次,让我们从上方处理2D列表。
Here’s the list: [ [2,4,3,8], [8,6,4,0], [0,0,17, 3] ]
列表如下:[[2,4,3,8],[8,6,4,0],[0,0,17,3]]
To run the same code for this 2D list as we did for our 1D list, we would need to update the data variable.
为了对此2D列表运行与对1D列表相同的代码,我们需要更新data变量。

This time, we would print out each nested list separated by a space.
这次,我们将打印出每个用空格隔开的嵌套列表。
[2, 4, 3, 8] [8, 6, 4, 0] [0, 0, 17, 3]
[2,4,3,8] [8,6,4,0] [0,0,17,3]
In order to iterate through these nested lists, we must use a nested for loop, which is just another for loop inside of the original one. We will use j as our index placeholder for the nested for loop.
为了遍历这些嵌套列表,我们必须使用嵌套的for循环 ,它只是原始嵌套循环中的另一个for循环 。 我们将使用j作为嵌套for循环的索引占位符。
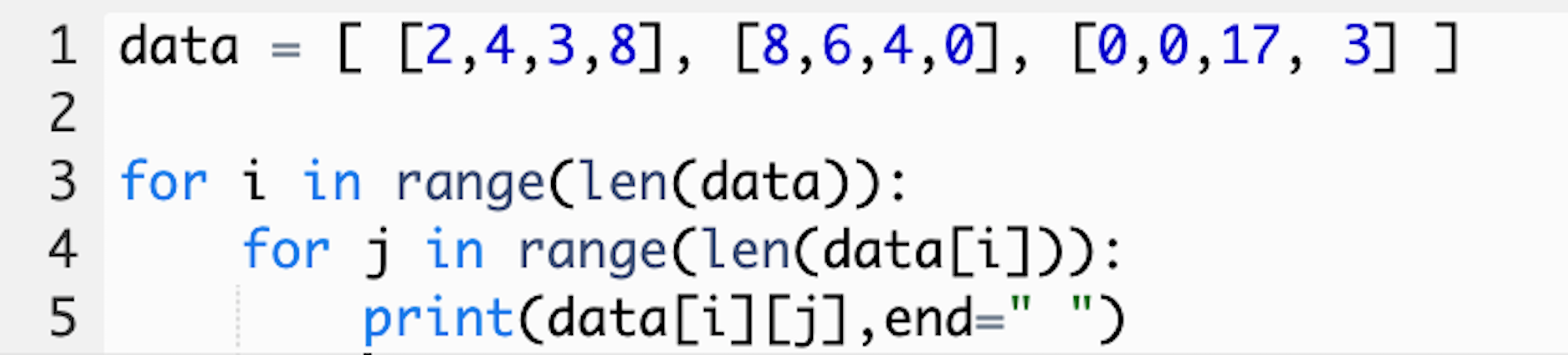
这是发生了什么 (Here’s what happens)
The first for loop takes us into the first nested list. Then, the second for loop iterates through each element of that first nested list. The print statement includes the syntax data[i][j], which is providing the computer with instructions on what to print.
第一个for循环将我们带入第一个嵌套列表。 然后,第二个for循环遍历该第一个嵌套列表的每个元素。 打印语句包括语法数据[i] [j] ,该语法数据为计算机提供有关打印内容的指令。
Here’s an example of what occurs. For i=0, the computer prints the element at index [0][0], then it prints the element at index [0][1], then it prints the element at index [0][2], and finally it prints the element at index [0][3].
这是发生情况的一个例子。 对于i = 0 ,计算机在索引[0] [0]处打印元素,然后在索引[0] [1]处打印元素,然后在索引[0] [2]处打印元素,最后打印索引为[0] [3]的元素。
After these elements have been printed, the first cycle through the nested for loop is complete. The first for loop kicks in again with i now equal to 1. This cycle continues until all elements in the 2D list have been printed.
打印完这些元素后,将完成嵌套的for循环的第一个循环。 第一个for循环再次开始,现在i等于1。该循环继续进行,直到2D列表中的所有元素都已打印。
The final output is: 2 4 3 8 8 6 4 0 0 0 17 3
最终输出为:2 4 3 8 8 6 4 0 0 0 17 3
我们可以对2D列表执行其他操作 (We can perform other operations on 2D lists)
We aren’t just limited to printing the elements. We could do other things, like add all the elements in the 2D list.
我们不仅限于打印元素。 我们可以做其他事情,例如在2D列表中添加所有元素。
To do this, we will make two modifications.
为此,我们将进行两个修改。
First, we will initialize a count variable. We will just set this equal to 0. We’ll have this count get updated through each iteration.
首先,我们将初始化一个计数变量。 我们将其设置为0。每次迭代都会更新此计数。
Note that while we are summing, we should refrain from using sum as a variable name because sum is an inbuilt Python function. It’s best to avoid using function names as variable names.
请注意,在求和时,应避免使用sum作为变量名,因为sum是内置的Python函数。 最好避免使用函数名作为变量名。
Second, we will change our print statement so that it outputs the final count instead of each element. Here’s the syntax:
其次,我们将更改打印语句,以便输出最终计数而不是每个元素。 语法如下:
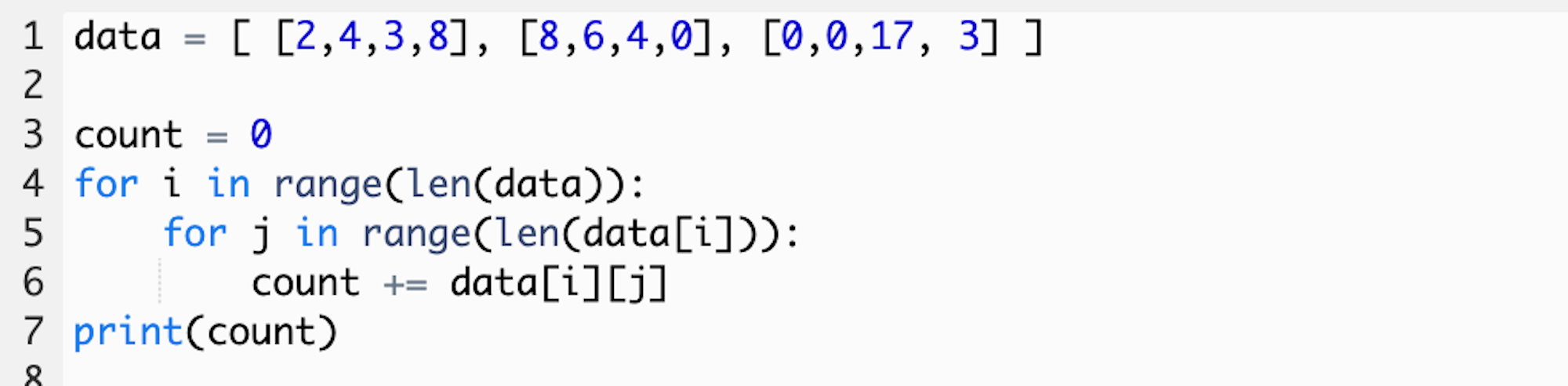
As you can see, this is very similar to just iterating through each element of the 2D list.
如您所见,这与仅遍历2D列表的每个元素非常相似。
You may be unfamiliar with the syntax count += data[i][j]. This is the same as using count = count +data[i][j]. Both simply add the current element to the existing count. The syntax I used is common shorthand.
您可能不熟悉语法count + = data [i] [j] 。 这与使用count = count + data [i] [j]相同。 两者都简单地将当前元素添加到现有计数中。 我使用的语法是常用的简写。
Your final output is 55, which is the sum of all elements in the 2D list.
最终输出为55,它是2D列表中所有元素的总和。
If you want more practice with nested for loops, I highly suggest iterating through a simple 2D list using a pencil and paper. Write down what happens for each cycle. This will help you understand what the code is doing overall.
如果您想使用嵌套for循环进行更多练习,我强烈建议您使用铅笔和纸遍历一个简单的2D列表。 写下每个周期发生的事情。 这将帮助您了解代码的整体功能。
翻译自: https://medium.com/an-amygdala/how-to-iterate-through-a-2d-list-in-python-5a90693f3a15

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









