





nlp初学者代码
“Word means nothing until it is clubbed to represent the context and the right kind of human emotion apt for the given situation. ”
“词语直到它被用来代表上下文和适合给定情况的正确的人类情感之前,什么都没有。 ”
Welcome back folks,
欢迎大家,
To my 5th article in NLP series, earlier we covered
在我的NLP系列的第5篇文章中,我们前面已经介绍了
So, Before we go into understanding how words are represented in the form of vectors using word2vec it is important to understand
因此,在深入了解如何使用word2vec以向量形式表示单词之前,重要的是要理解
给定单词的含义是什么? (What is Meaning of Any Given Word?)
If we human have to express any idea we need to rely on giving some textual label to it which become words, or we create a phrase or we rely on some visual tool to do so. This representation of our idea is what can call a word meaning.
如果我们必须表达任何想法,则需要依靠给它提供一些文字标签来变成单词,或者我们创建一个短语或依靠某种视觉工具来做到这一点。 我们的想法的这种表述就是所谓的词义。
But in the field of textual computation, this meaning of words alone doesn’t help a lot, as the surrounding nuances of the context are often missing in those meanings. But we humans have come up with the technology to make this word meaning useful and most important one has been understanding the taxonomy of words which can help us answer some of the fundamental answers like
但是在文本计算领域,仅单词的这种含义并没有多大帮助,因为上下文中周围的细微差别经常在这些含义中缺失。 但是我们人类已经想出了使该词有意义的技术,最重要的是一直在理解词的分类法,这可以帮助我们回答一些基本的答案,例如
- Word Synonyms 单词同义词
- Words Antonyms 单词反义词
- Words hypernyms 单词上音
For example, the WordNet package in python helps us meet some of the above-mentioned objectives in word computational system.
例如,Python中的WordNet软件包可帮助我们满足文字计算系统中的一些上述目标。
单词离散表示的问题: (Problem With Discrete Representation of Words:)
The idea behind WordNet has some fundamental issues, though it is extremely useful in terms of giving multiple word representation of any given words for example synonyms :
WordNet背后的思想有一些基本问题,尽管在给定给定单词的多个单词表示形式(例如同义词)方面非常有用。
Beautiful: Alluring, appealing, charming, cure, dazzling, good-looking
美丽:诱人,诱人,迷人,治愈,耀眼,好看
Here the taxonomical representation of beautiful gives us a bunch of related words which actually can have a different meaning in the different context/situation. Here the required situational nuances are missing. The actual similarity between the word is not effectively represented here, which is kind of problematic when we are trying to make sense of any words or the phrases.
在这里,美丽的分类学表示法为我们提供了一系列相关的词,这些词实际上在不同的上下文/情况下可能具有不同的含义。 这里缺少所需的情境细微差别。 单词之间的实际相似性在这里无法有效表示,当我们试图理解任何单词或短语时,这是一种问题。
离散单词表示的解决方案是什么? (What Is The Solution To Discrete Word Representation?)
As we discussed above one can completely misread the actual meaning of any word if the accompanied nuances like situation, the emotion are not taken into consideration while establishing the relationship between a given set of words.
正如我们上面所讨论的,如果伴随着诸如情况之类的细微差别,人们可能会完全误读任何单词的实际含义,而在建立给定单词集之间的关系时就不会考虑情感。
The discrete word representation is extremely subjective which fails to compute the similarity between a given words and sometimes misses the nuances completely
离散的单词表示非常主观,无法计算给定单词之间的相似度,有时会完全忽略细微差别
To get rid of such issues the computational linguistics came up with idea of “Distributed represented of words”
为了摆脱这些问题,计算语言学提出了“ 单词的分布式表示 ”的思想
分布式单词表示背后的想法 (Idea Behind Distributed Word Representation)
“If you have no problem nothing new can be invented or discovered”
“如果没有问题,就不会发明或发现任何新事物”
So the above problem of discrete word representation which generally fails to capture the idea of similarity between the words to represent it effectively, is what has lead to the idea of the distributed word representation.
因此,上述离散单词表示的问题通常不能捕捉单词之间的相似性的概念来有效地表示它,这就是导致分布式单词表示的思想的原因。
Where we represent any given words based on the meanings of the neighboring words and end up extracting the real value out of it.
我们根据相邻单词的含义表示任何给定的单词,最终从中提取出真正的价值。
For Example: Read the below para,
例如:阅读以下段落,
“ The world of online education will become extremely relevant and significant for students who are looking to acquire new skills and get a world-class education from world-class teachers. ”
“对于想要学习新技能并从世界级老师那里获得世界级教育的学生来说,在线教育的世界将变得极为重要,意义重大。 ”
So if we carefully process the above paragraph, we can easily represent the word education which will be represented by its other neighboring words like online, students, teachers, skills, etc…
因此,如果我们认真处理以上段落,就可以轻松地表示教育这个词,该词将由其邻近的其他词表示,例如在线,学生,教师,技能等。
This idea of representing any words has been extremely useful for computational linguistics and is the core concept behind the world of word embeddings in NLP
表示任何单词的想法对于计算语言学非常有用,并且是NLP中单词嵌入世界背后的核心概念
NLP中的单词嵌入? (Word Embeddings In NLP?)
So if one has to represent the given world which is represented by the accompanied neighboring word the best kind of representation is the Vector representation of those words.
因此,如果必须代表由伴随的相邻单词表示的给定世界,则最好的表示形式是这些单词的矢量表示。
什么是词嵌入? (What Is Word Embeddings?)
As per wiki:
根据维基:
Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers
单词嵌入是自然语言处理(NLP)中一组语言建模和功能学习技术的统称,其中词汇表中的单词或短语映射到实数向量
In a more simplified term :
用更简化的术语:
Word embeddings are a type of word representation in the form vector array, that allows words with similar meaning to have a similar representation.
词嵌入是形式向量数组中的一种词表示形式,它使含义相似的词具有类似的表示形式。
The idea was to come up with the dense representation of each word as a vector that can overcome the limitation of discrete one-hot encoding representation which was expensive, has dimensionality issues, and was extremely sparse.
想法是将每个单词的密集表示作为矢量,以克服离散的单热编码表示的局限性,后者昂贵,存在维数问题且极为稀疏。
Conceptually, word embeddings involve the concept of dimensionality reduction of the correlated words, the probabilistic language models, to capture the context of the words to be used in the neural network architecture.
从概念上讲,词嵌入涉及相关词降维的概念,即概率语言模型,以捕获要在神经网络体系结构中使用的词的上下文。
To sum up the idea of word embeddings, it would be apt to quote the famous lines said by John Firth:
概括一下词嵌入的概念,可以引用约翰·费斯所说的著名格言:
“You shall know a word by the company it keeps!”
“ 您将知道它所拥有的公司的一句话! ”
As per Tensorflow:
根据 Tensorflow :
An embedding is a dense vector of floating-point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way, a model learns weights for a dense layer).
嵌入是浮点值的密集向量(向量的长度是您指定的参数)。 它们不是可手动指定嵌入值的值,而是可训练的参数(模型在训练过程中学习的权重,以同样的方式,模型学习密集层的权重)。
Below is the 4-dimensional vector representation of word cat, mat, on :
以下是单词cat,mat的4维矢量表示形式:

NLP中最常用的词嵌入技术是什么? (What Are Some Of The Most Used Word Embeddings Techniques in NLP?)
- Word2Vec Word2Vec
- GloVe 手套
We will cover Word2Vec word embedding technique in details and will look into GloVe embeddings in the Next part of NLP series
我们将详细介绍Word2Vec词嵌入技术,并在NLP系列的下一部分中研究GloVe嵌入
Word2Vec嵌入: (Word2Vec Embeddings :)
It is one of the most established methods of generating word embeddings.
它是生成词嵌入的最成熟的方法之一。
Word2Vec was developed by Tomas Mikolov of Google in 2013, with an objective to make the bring efficiency in the Neural network-based model. Now it is the de facto standard for developing pre-trained word embedding.
Word2Vec由Google的Tomas Mikolov于2013年开发,旨在提高基于神经网络的模型的使用效率。 现在,它已成为开发预训练单词嵌入的事实上的标准。
Word2Vec represents each distinct word with a particular list of numbers called a vector. It helps us to efficiently learn any given word embeddings from the set of a text corpus, using a neural network which learns word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence
Word2Vec用称为向量的特定数字列表表示每个不同的词。 它使用神经网络从大型文本语料库中学习单词关联,从而帮助我们从文本语料库集中有效地学习任何给定的单词嵌入。 一旦经过训练,这种模型就可以检测同义词或为部分句子建议其他词
Word2Vec uses the math of cosine similarity between the given sectors in such a manner that the words represented by those vectors are semantically similar.
Word2Vec使用给定扇区之间的余弦相似度数学,以使这些向量表示的单词在语义上相似。
Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space, such that words that share common contexts in the corpus are located close to one another in the space
Word2vec将一个大型文本语料库作为输入,并产生一个通常具有几百个维度的向量空间,该语料库中的每个唯一单词都在该空间中分配了一个对应的向量,从而可以找到在该语料库中共享公共上下文的单词在空间中彼此接近
A Simple Word2Vec NN Archtecture has,
一个简单的Word2Vec NN建筑,
- A single hidden layer, 单个隐藏层
- Fully connected neural network 全连接神经网络
- The neurons in the hidden layer are all linear neurons. 隐藏层中的神经元都是线性神经元。
- The input layer is set to have as many neurons as there are words in the vocabulary for training. 输入层设置为具有与词汇表中要训练的单词一样多的神经元。
- The hidden layer size is set to the dimensionality of the resulting word vectors. The size of the output layer is the same as the input layer 隐藏层的大小设置为所得单词向量的维数。 输出层的大小与输入层的大小相同

Word2Vec嵌入提出的模型体系结构类型: (Types Of Model Architecture Proposed By Word2Vec Embeddings :)
CBOW: Continuous Bag Of Words Model
CBOW :连续词袋模型
- Continuous Skip-gram model 连续跳过图模型
CBOW :连续词袋体系结构: (CBOW: Continuous Bag Of Words Architecture:)
The CBOW model learns the embedding by predicting the target word based on its context or we can say based on the surrounding words.
CBOW模型通过根据目标单词的上下文预测目标单词来学习嵌入,或者我们可以根据周围的单词说出来。
The context here is represented by multiple words for a given target word. The objective of the CBOW model is to learn to predict a missing word given the neighboring words
此处的上下文由给定目标单词的多个单词表示。 CBOW模型的目标是学习在给定相邻单词的情况下预测缺失单词
CBOW背后的直觉: (Intuition Behind CBOW:)
Let’s understand the main intuition behind CBOW model using the simple example, Suppose the phrase is : “ The black monkey went mad”
让我们通过一个简单的例子来了解CBOW模型背后的主要直觉,假设这句话是: “黑猴子发疯了”
Now CBOW has to predict the target word monkey based on the surrounding word {The, black, went, mad} which may look like the below combination of words:
现在,CBOW必须根据周围的单词{ The,black, god ,mad }来预测目标单词猴子,该单词可能类似于以下单词组合:
(The →monkey),(black →monkey), (went →monkey),(mad →monkey)
(→猴子),(黑色→猴子),(走→猴子),(疯→猴子)
The CBOW visualization for the above example will look like :
上面示例的CBOW可视化效果如下所示:

CBOW简单架构: (CBOW Simple Architecture :)

Where,
哪里,
- Input layer holds the possible surrounding context 输入层保存可能的周围环境
- The output layer hols the current word 输出层将当前字词
The hidden layer contains the number of dimensions in which we want to represent the target word present at the output layer. CBOW Uses both the n-words before and after the target word w(t) to predict
隐藏层包含我们要表示输出层上存在的目标单词的维数。 CBOW使用目标单词w(t)之前和之后的n个单词来预测
连续跳格模型: (Continuous Skip-Gram Model:)
It functions exactly the opposite of CBOW. In the skip-gram model, instead of using the surrounding words to predict the missing/target word, it uses the target word to predict the surrounding words or context.
它的功能与CBOW完全相反。 在跳过语法模型中,不是使用周围的单词来预测缺失/目标单词,而是使用目标单词来预测周围的单词或上下文。
The continuous skip-gram model learns by predicting the surrounding words given a current center word.
连续跳跃语法模型通过在给定当前中心词的情况下预测周围词来学习。
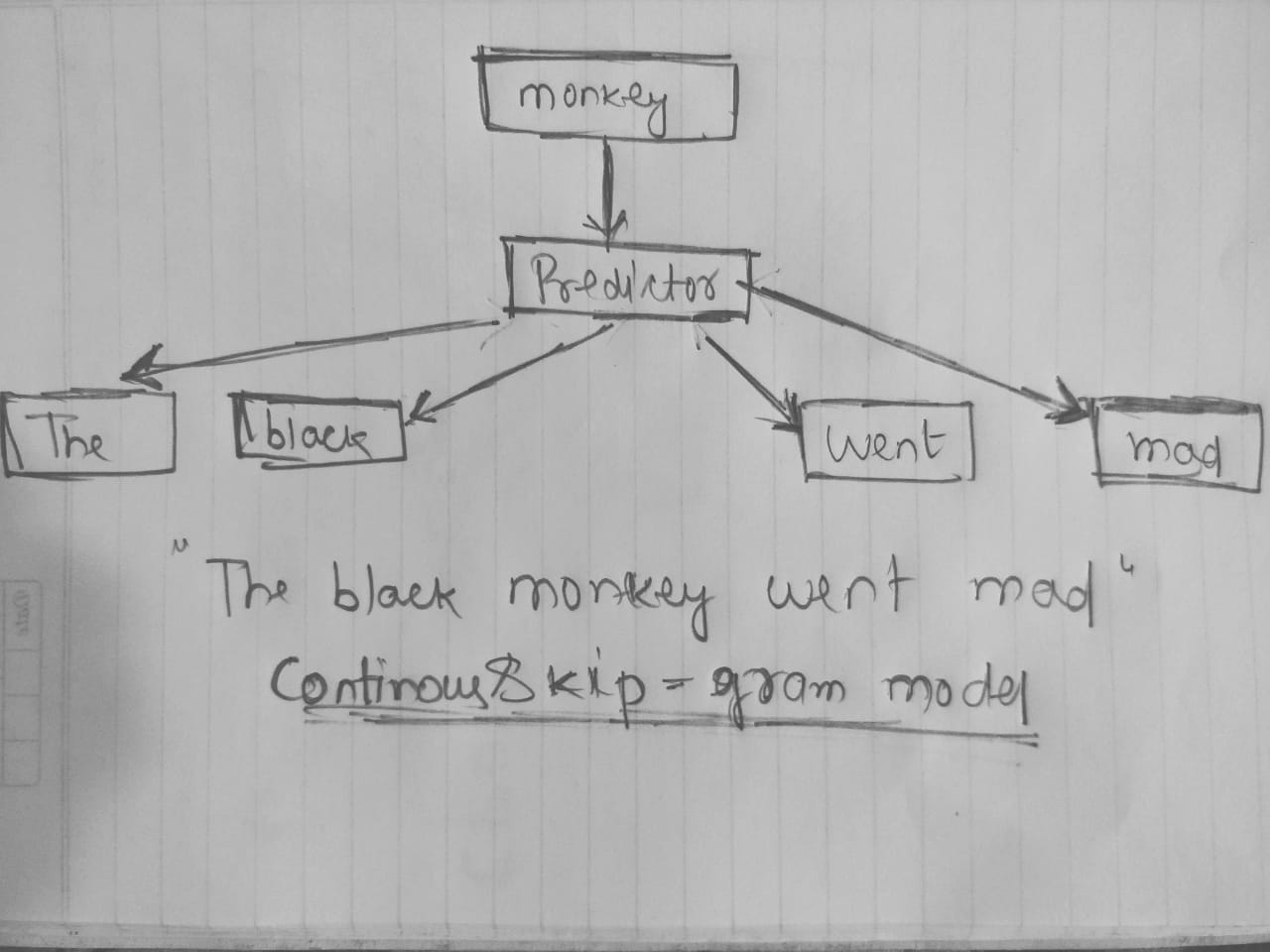
So, for the same phrase “ The black monkey went mad”
因此,对于同一句话“黑猴子发疯了”
Skip Gram model would look like :
Skip Gram模型如下所示:
Where,
哪里,
- We are trying to predict the context of the given target word monkey 我们正在尝试预测给定目标单词猴子的上下文
- Here the representation: 这里表示:
(monkey →The), (monkey →black), (monkey →went), (monkey-mad )
(猴子→的),(猴子→黑色的),(猴子→去的),(猴子疯狂的)
The Skip-gram model reverses the use of target and context words. In this case,
跳过图模型可逆转目标词和上下文词的使用。 在这种情况下,
跳过图模型的简单架构: (Simple Architecture of Skip-gram Model:)

- The target word is fed at the input layer as, w(t) 目标词在输入层被馈送为w(t)
- The hidden layer remains the same 隐藏层保持不变
- The output layer of the neural network is replicated multiple times to accommodate the chosen number of context words, represented as shown in the above image below. 神经网络的输出层被复制多次,以适应所选数量的上下文词,如下图所示。
The skip-gram objective thus sums the log probabilities of the surrounding n-words to the left and to the right of the target word wt to achieve the objective of finding the context.
因此,跳过语法表目标将目标单词wt左右两侧周围n个单词的对数概率相加,以实现查找上下文的目的。
现实世界中的Word2Vec应用程序: (Word2Vec Applications In Real World:)
分析逐字注释: (Analyzing Verbatim Comments:)
Many big and small organizations use the power of word2vec embeddings to analyze the customer comments to find verbatim in it. When you’re analyzing text data, an important use case is analyzing verbatim comments. In such cases, the data engineers are given a task to come up with an algorithm that can mine customers’ comments or reviews.
许多大型和小型组织都使用word2vec嵌入的功能来分析客户评论以逐字查找。 当您分析文本数据时,一个重要的用例就是分析逐字注释。 在这种情况下,数据工程师要承担一项任务,即想出一种算法,该算法可以挖掘客户的评论或评论。
建筑产品/电影/音乐推荐: (Building Product/Movie/Music Recommendation:)
The returning or new customer coming to any eCommerce portal, or media content portal gets the personalized recommendation not only based on what another customer whose behavior of content browsing is similar to them, but also based on, what kind of content/product is being experienced by the customers in the given situation together. This information will add value to offer better customer offerings and an awesome user experience.
进入任何电子商务门户网站或媒体内容门户网站的回头客或新客户不仅根据内容浏览行为与他们相似的另一位客户,还根据正在体验哪种内容/产品来获得个性化推荐由客户在给定的情况下在一起。 这些信息将增加价值,以提供更好的客户服务和出色的用户体验。
Some more common applications are
一些更常见的应用是
Sentiment analysis
情绪分析
Document classification
文件分类
and many more.
还有很多。
NLP系列的下一步是什么? (What’s Next In NLP Sereies ?)
Well, we will go hands-on to understand how one can implement CBOW and Skip-gram Word2Vec model using the python and gensim word2vec model. Also, we will cover, GloVe embeddings
好吧,我们将动手实践一下如何使用python和gensim word2vec模型来实现CBOW和Skip-gram Word2Vec模型。 另外,我们将介绍GloVe嵌入
深思熟虑地签字: (Signing-off with food for thought:)
“Our existence as human beings is nothing without the nature in which we exist. Our life will become lifeless, if we are not taking good care of our surroundings which mother nature has bestowed on us . Same goes with linguistic computation, the words will have no meaning until the surrounding words come together to extract the meaningful relationship and eventually helps us make sensible and meaningful predictions. ”
“我们作为人类的生存离不开我们生存的本性。 如果我们不善待大自然赋予我们的环境,我们的生活将变得毫无生气。 语言计算也是如此,除非周围的单词聚集在一起以提取有意义的关系并最终帮助我们做出明智而有意义的预测,否则单词将没有任何意义。 ”
Thanks a lot and look forward see you all, in Part 6 of the NLP series…..
非常感谢,并期待在NLP系列的第6部分中与大家见面.....
翻译自: https://medium.com/predict/intuition-behind-word-embeddings-in-nlp-for-beginners-284dfd14ec86
nlp初学者代码















 5097
5097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









