





深度学习cnn人脸检测
介绍 (Introduction)
CNN’s have been extensively used to classify images. But to detect an object in an image and to draw bounding boxes around them is a tough problem to solve. To solve this problem, R-CNN algorithm was published in 2014. After R-CNN, many of its variants like Fast-R-CNN, Faster-R-CNN and Mask-R-CNN came which improvised the task of object detection. To understand the latest R-CNN variants, it is important to have a clear understanding of R-CNN. Once this is understood, then all other variations can be understood easily.
CNN已被广泛用于图像分类。 但是要检测图像中的物体并在其周围绘制边界框是一个难题。 为了解决这个问题,R-CNN算法于2014年发布。继R-CNN之后,它的许多变体,如Fast-R-CNN , Faster-R-CNN和Mask-R-CNN都改进了目标检测的任务。 要了解最新的R-CNN变体,必须对R-CNN有清晰的了解。 一旦理解了这一点,便可以轻松理解所有其他变体。
This post will assume that the reader has familiarity with SVM, image classification using CNNs and linear regression.
本文将假定读者熟悉SVM,使用CNN进行图像分类和线性回归。
总览 (Overview)
The R-CNN paper[1] was published in 2014. It was the first paper to show that CNN can lead to high performance in object detection. This algorithm does object detection in the following way:
R-CNN论文 [1]于2014年发表。这是第一篇表明CNN可以提高目标检测性能的论文。 该算法通过以下方式进行对象检测:
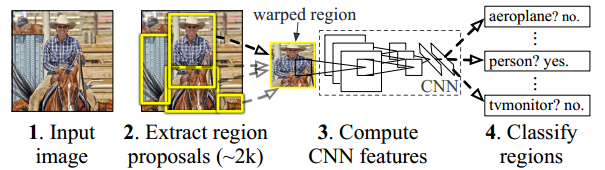
- The method takes an image as input and extracts around 2000 region proposals from the image(Step 2 in the above image). 该方法以图像为输入,并从图像中提取大约2000个区域建议(上图中的步骤2)。
- Each region proposal is then warped(reshaped) to a fixed size to be passed on as an input to a CNN. 然后,将每个区域提议弯曲(变形)为固定大小,以作为CNN的输入传递。
- The CNN extracts a fixed-length feature vector for each region proposal(Step 3 in the above image). CNN为每个区域建议提取固定长度的特征向量(上图中的步骤3)。
- These features are used to classify region proposals using category-specific linear SVM(Step 4 in the above image). 这些功能用于使用类别特定的线性SVM对区域提议进行分类(上图中的步骤4)。
- The bounding boxes are refined using bounding box regression so that the object is properly captured by the box. 边界框使用边界框回归进行精炼,以使对象可以被框正确捕获。
Now the post will dive into details explaining how the model is trained and how it predicts the bounding boxes.
现在,该帖子将深入探讨如何训练模型以及如何预测边界框的细节。
计算区域提案 (Calculating region Proposals)
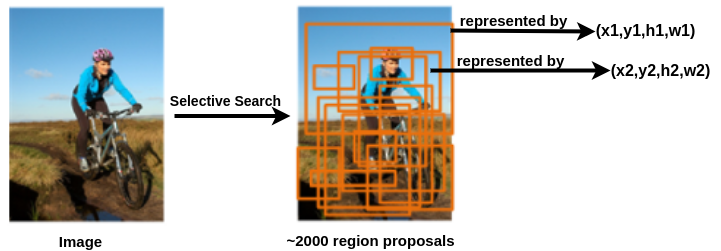
Region proposals are the bounding boxes that may contain an object. These are represented by a tuple of 4 numbers(x,y,h,w). The (x,y) are the coordinates of the centre of the bounding box and (h,w) are the height and width of the bounding box respectively. These region proposals are calculated by an algorithm called selective search[2]. For an image, approximately 2000 region proposals are extracted.
区域投标是可能包含对象的边界框。 这些由4个数字(x,y,h,w)的元组表示。 (x,y)是边界框中心的坐标,(h,w)分别是边界框的高度和宽度。 这些区域提议是通过称为选择性搜索的算法计算的[2]。 对于图像,提取了大约2000个区域建议。
训练CNN功能提取器: (Training CNN feature extractor:)
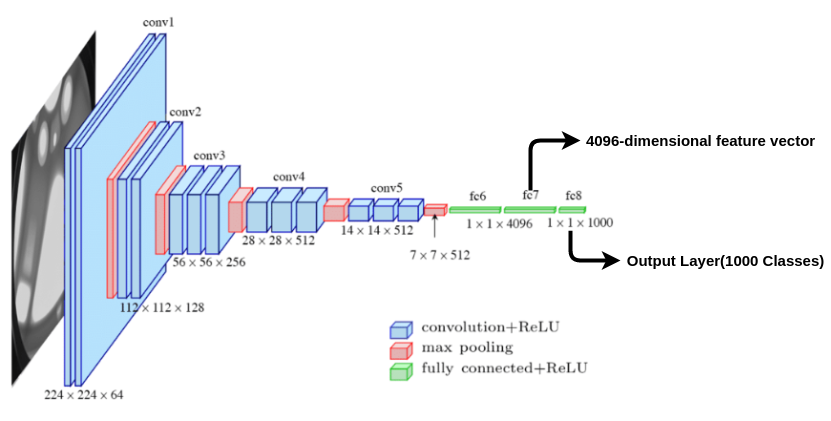
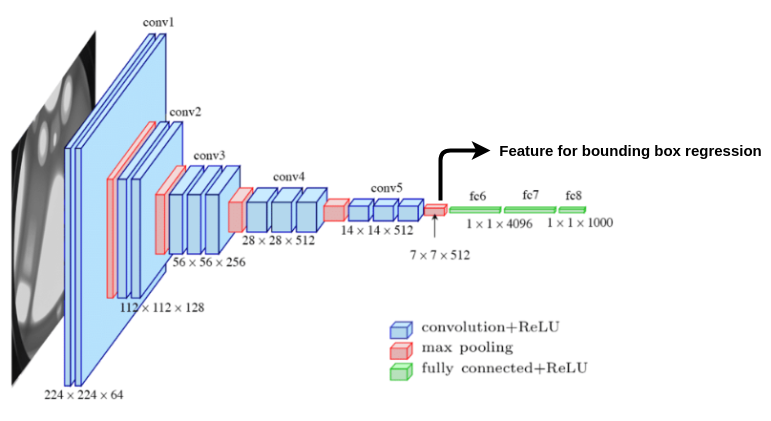
Pretrained network: To train the CNN for feature extraction, an architecture like VGG-16 is initialized with the pre-trained weights from imagenet data. The output layer having 1000 classes is chopped off. So when a region proposal image(warped to size 224x224) is passed to the network we get a 4096-dimensional feature vector as shown in the above image. In this way, each region proposal is represented by a 4096-dimensional feature vector.
预训练网络:为了训练CNN以进行特征提取,使用来自Imagenet数据的预训练权重初始化VGG-16之类的体系结构。 具有1000个类别的输出层被切掉。 因此,当区域投标图像(变形为224x224大小)传递到网络时,我们将获得4096维特征向量,如上图所示。 这样,每个区域提议都由4096维特征向量表示。
The next step is to fine-tune the weights of the network with the region proposal images. To understand this a new metric called intersection-over-union or IoU score will be introduced.
下一步是使用区域建议图像微调网络的权重。 为了理解这一点,将引入一个称为“交集超过工会”或“ IoU得分”的新指标。
联合路口(IoU) (Intersection-Over-Union(IoU))
To measure the performance of a classification model, we generally use metrics like accuracy, recall, precision etc. But how to measure the performance of object detection. In object detection we have to evaluate two things:
为了衡量分类模型的性能,我们通常使用诸如准确性,召回率,准确性等指标。但是如何衡量对象检测的性能。 在对象检测中,我们必须评估两件事:
- How well the bounding box can locate the object in the image. In other words, how close the predicted bounding box is to the ground truth. 边界框在图像中定位对象的程度。 换句话说,预测的边界框离地面真值有多近。
- Whether the bounding box is classifying the enclosed object correctly 边界框是否正确分类了封闭对象
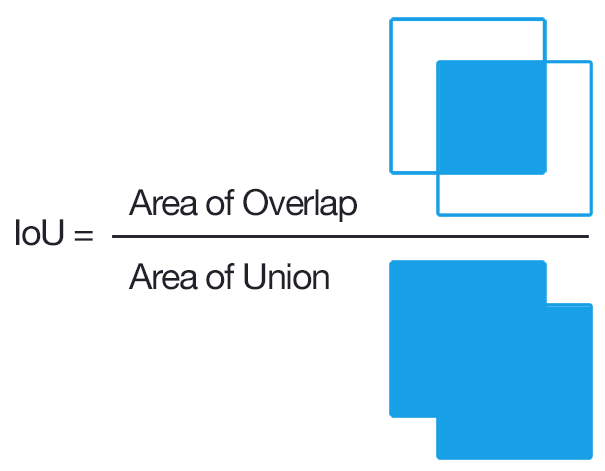
The IoU score measures how close the predicted box is to the ground truth. It is the ratio of the area common to ground truth and predicted box to the total area enclosed by both the boxes.
IoU分数用于衡量预测框与地面实况的接近程度。 它是基本事实和预测框的公共面积与两个框所包围的总面积之比。

In the left-most image, it can be seen that the predicted box is not close to the ground truth so the IoU score is only 35% while in the right-most image the predicted box completely overlaps the ground truth box, hence a very high value of 95% is obtained. The IoU value varies from 0 to 1.
在最左侧的图像中,可以看到预测框与地面实况不接近,因此IoU分数仅为35%,而在最右侧的图像中,预测框与地面真实框完全重叠,因此非常获得了95%的高值。 IoU值从0到1。
Fine-tuning the network: To fine-tune the model the output layer having 1000 classes is replaced with N+1 classes(softmax layers) and the rest of the model is kept unchanged. N is the number of the distinct classes the objects be classified and plus 1 for the background class.
网络的微调:为了微调模型,将具有1000个类的输出层替换为N + 1个类(softmax层),其余模型保持不变。 N是对象分类的不同类别的数量,背景类别则加1。
Next, data is required for fine-tuning. The region proposals whose IoU > 50% are considered a positive class for that object and rest are considered as background. In the above image of balls, the region proposal with 35% IoU score will be labelled as background while the rest of the boxes will be labelled as ball. These images(region proposals) are warped(resized) to the size compatible with CNN, in case of VGG 16 it is 224x224. Using these images the weights of the network are fine-tuned.
接下来,需要数据以进行微调。 IoU> 50%的区域提案被认为是该对象的良好类别,其余部分被视为背景。 在上面的球图像中,IoU分数为35%的区域提议将被标记为背景,而其余的框将被标记为球。 将这些图像(区域建议)扭曲(调整大小)到与CNN兼容的大小,在VGG 16的情况下为224x224。 使用这些图像可以对网络的权重进行微调。
培训特定于课程的SVM (Training class-specific SVM)
Once the 4096-dimensional feature is obtained for each region proposal, the next task is to train a binary SVM for each class. For example, if the detection model is to detect three distinct objects — cat, dog and people, then three SVMs need to be trained for each of the class.
为每个区域提案获得4096维特征后,下一个任务是为每个类别训练一个二进制SVM。 例如,如果检测模型要检测三个不同的对象(猫,狗和人),则需要针对每个班级训练三个SVM。
Data preparation: All the object proposals belonging to a particular class is segregated. The manually labelled ground truth image for the class is considered as a positive class while object proposals having IoU < 30% for that class is considered as negative class. The same thing is done for each class and N SVM models are trained for classifying each region proposal into N classes.
数据准备:隔离属于特定类别的所有对象建议。 手动标记的类别的地面真实图像被视为肯定类别,而该类别的IoU <30%的对象建议被视为否定类别。 对于每个类别都执行相同的操作,并且训练了N个SVM模型以将每个区域建议分类为N个类别。
边界框回归 (Bounding box regression)
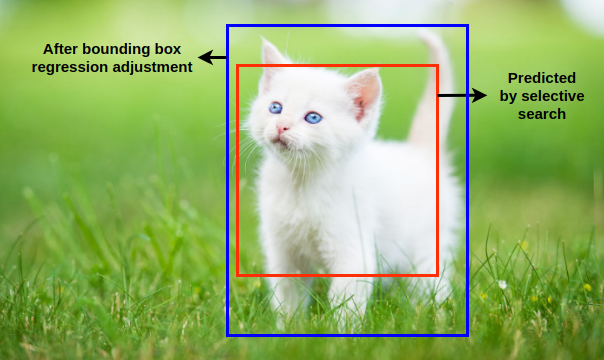
The region proposal bounding box predicted by selective search[2] algorithm might not be able to capture the entire object. To fine-tune the predicted bounding box, bounding box regression is used.
由选择性搜索[2]算法预测的区域提议边界框可能无法捕获整个对象。 要微调预测的边界框,请使用边界框回归。
Consider the ground truth region proposal G and the predicted region proposal P by the selective search[2] algorithm.
通过选择性搜索[2]算法考虑地面真实区域建议G和预测区域建议P。
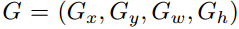
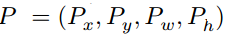
To make the prediction of G scale-invariant, the following transformations are done such that the target for the regression is t.
为了预测G尺度不变,进行以下转换,以使回归的目标为t。
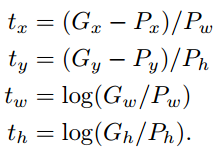
The input to the regression model is the feature from the last pooling layer of the CNN. We train 4 regression models per class with the target as t and input features as last pooling layer feature from CNN to learn regression parameter w.
回归模型的输入是来自CNN最后一个合并层的要素。 我们每类训练4个回归模型,其中目标作为t ,输入特征作为CNN的最后一个合并层特征,以学习回归参数w。
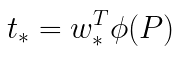
Here * is the placeholder for (x,y,w,h) and phi(P) is the last pooling layer feature corresponding to proposal P. So to predict ground truth G we can use the regression equation to calculate t from the region proposal P and then substitute the value of t and P in transformation equation to obtain G.
*是(x,y,w,h)的占位符,phi(P)是与提案P对应的最后一个合并层特征。因此,要预测地面实况G,我们可以使用回归方程从区域提案中计算t P,然后将t和P的值代入转换方程式以获得G。
预测 (Prediction)
Once different parts of R-CNN are trained, the next part is to do the object detection.
一旦训练了R-CNN的不同部分,下一部分就是进行对象检测。
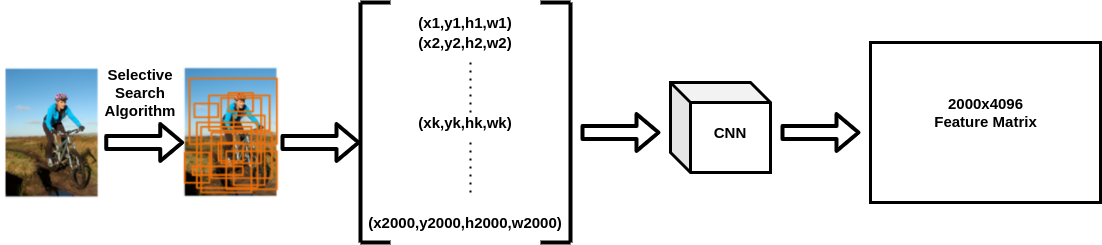
- An input image is taken and using selective search[2] algorithm, around 2000 region proposals are obtained for an image. 拍摄输入图像,并使用选择性搜索[2]算法,为图像获得大约2000个区域建议。
- Each region proposal image is warped to a fixed size of 224x224. 每个区域建议图像都将变形为224x224的固定大小。
- These region proposal images are then passed to the trained CNN to obtain 4096-dimensional feature vector for all the 2000 region proposals which result in 2000x4096 dimensional matrix. 然后将这些区域建议图像传递给训练后的CNN,以获取所有2000个区域建议的4096维特征向量,从而得出2000x4096维矩阵。
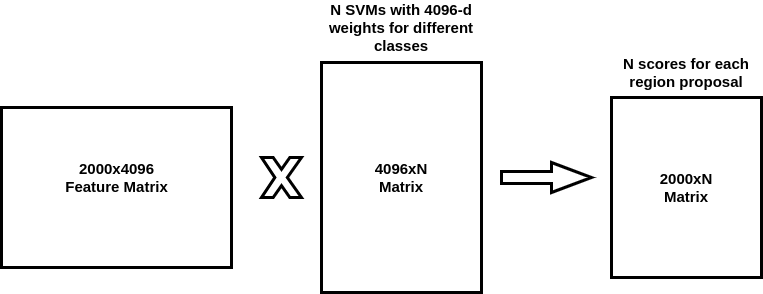
3. Each region proposal is classified using SVM for each class. generally for N classes, the SVM weights(4096-dimensional) are stacked in the form of a matrix and multiplied with the feature matrix. This results in a matrix which assigns a score to each class to which a region proposal can belong to.
3.针对每个类别,使用SVM对每个区域提案进行分类。 通常对于N类,SVM权重(4096维)以矩阵的形式堆叠并与特征矩阵相乘。 这产生一个矩阵,该矩阵为区域提案可以属于的每个类别分配分数。
4. The proposal is assigned the class which receives the maximum score. So all the 2000 region proposals or bounding boxes in the image are labelled with a class label.
4.为提案分配获得最高分的班级。 因此,图像中的所有2000个区域提议或边界框都标记有类标签。
5. Out of those many bounding boxes, a lot of them would be redundant and overlapping bounding boxes which need to be removed. To accomplish that Non-maximum suppression algorithm is used.
5.在许多边界框中,其中许多将是多余的并且需要删除重叠的边界框。 为此,使用了非最大抑制算法。
Non-maximum suppression algorithm:
非最大抑制算法:
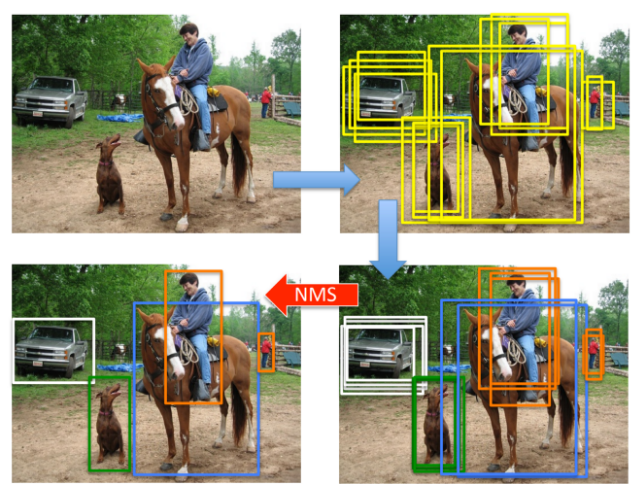
Non-maximum suppression is a greedy algorithm. It works on one class at a time. For a particular class, it picks the box with the maximum score obtained using SVM. Then it calculates IoU score with all other bounding boxes belonging to that class. The boxes having IoU score greater than 70% are removed. In other words, the bounding boxes which have very high overlap are removed. Then the next highest score box is chosen and so on until all the overlapping bounding boxes are removed for that class. This is done for all classes to obtain the result as shown above.
非最大抑制是一种贪婪算法。 一次只上一堂课。 对于特定的班级,它会选择使用SVM获得最高分的盒子。 然后,它使用属于该类的所有其他边界框计算IoU分数。 IoU分数大于70%的框将被删除。 换句话说,将重叠度很高的边界框删除。 然后选择下一个得分最高的框,依此类推,直到删除该类的所有重叠边界框。 如上所示,对所有类都执行此操作以获得结果。
6. Once the labelled bounding boxes are obtained the next task is to fine-tune the location of the boxes using regression.
6.一旦获得标记的边界框,下一个任务是使用回归微调框的位置。
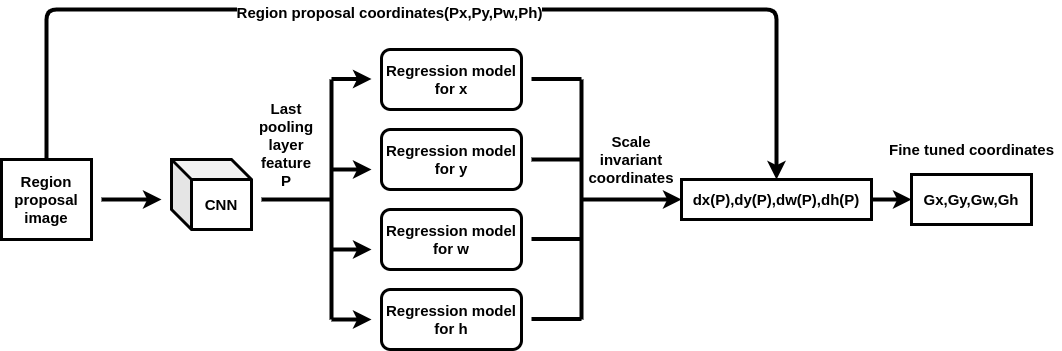
During training,4 regression models were trained for each class. So for a particular bounding box, region proposal image is passed through CNN to obtain features P to be passed to the regression model. The regression model outputs the scale-invariant coordinates ( dx(P), dy(P), dw(P), dh(P) ). These coordinates are combined with the region proposal coordinates ( Px, Py, Pw, Ph ) to obtain the adjusted final coordinates ( Gx, Gy, Gw, Gh) using the formula below.
在训练期间,为每个班级训练了4个回归模型。 因此,对于特定的边界框,区域建议图像通过CNN传递,以获得要传递给回归模型的特征P。 回归模型输出尺度不变坐标(dx(P),dy(P),dw(P),dh(P))。 这些坐标与区域建议坐标(Px,Py,Pw,Ph)组合,使用以下公式获得调整后的最终坐标(Gx,Gy,Gw,Gh)。
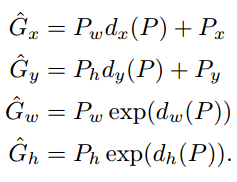
原始纸的结果 (The result from the original paper)

结论 (Conclusion)
Although R-CNN is good at detecting objects, it has its shortcomings.
尽管R-CNN擅长检测物体,但它也有缺点。
- This algorithm is slow and it takes about 47 secs to perform object detection on an image. 该算法速度很慢,大约需要47秒才能对图像执行目标检测。
- Training is not done in a single step. There are different models for doing different parts which make the training process time-consuming. 培训不是一步一步完成的。 执行不同部分的模型不同,这会使培训过程变得很耗时。
These shortcomings are addressed in the later improvements of R-CNN which are Fast-RCNN, Faster-RCNN and Mask-RCNN. Having a good understanding of R-CNN helps to understand other variants of R-CNN easily and intuitively.
R-CNN的后续改进(即Fast-RCNN,Faster-RCNN和Mask-RCNN)解决了这些缺点。 充分了解R-CNN有助于轻松直观地了解R-CNN的其他变体。
深度学习cnn人脸检测















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









