







从图中可以看出,R-CNN主要包括以下几个方面的内容:
- Extract region proposal,使用selective search的方法提取2000个候选区域
- Compute CNN features,使用CNN网络计算每个proposal region的feature map
- Classify regions,将提取到的feature输入到SVM中进行分类
- Non-maximum suppression,用于去除掉重复的box
- Bounding box regression,位置精修,使用回归器精细修正候选框的位置
所以,本文将主要针对这几方面的内容进行讲解
1. Extract region proposal
本文中使用了selective search这个方法来选择候选区域,输入一张图片,selective search根据以下的步骤生成region proposals:
- 使用一种过分割方法,将图片分割成比较小的区域
- 计算所有邻近区域之间的相似性,包括颜色、纹理、尺度等
- 将相似度比较高的区域合并到一起
- 计算合并区域和临近区域的相似度
- 重复3、4过程,直到整个图片变成一个区域
在每次迭代中,形成更大的区域并将其添加到区域提议列表中。这种自下而上的方式可以创建从小到大的不同scale的region proposal,如下图所示:

本文就是使用这种方法来提取2000个region proposal的。
2. Compute CNN features
2.1 Warped region
由于文中使用的CNN中包含有全连接层,这就需要输入神经网络的图片有相同的size,但是region proposal都是不同size的,所以需要对每个region都缩放到固定的大小(227*227),文中讨论和比较了多种方法:
(1)各向异性缩放:这种方法比较简单,就是不管图片的尺寸,直接resize到固定的大小,如下图的第3列,这种方法会导致图片发生形变。
(2)各向同性缩放:主要包括两种方法:
- 先扩充后裁剪:在原始图片中把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪,如上图第1列所示。
- 先裁剪后扩充:先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片,如上图第2列所示。
经过实验,作者发现采用各向异性缩放的精度最高。

2.2 Training
本文中使用CNN网络来对每个region proposal提取特征,我们首先来看一下本文是如何训练CNN网络的,主要包括以下两步:
(1) Pre-training,由于目标检测的数据量相对较少,不足以训练一个好的CNN网络,因此文中首先使用一个大的数据集(ILSVRC2012数据集)来训练AlexNet,得到一个预训练的分类网络模型。

(2) Fine-tuning,然后再使用warped region proposals来微调AlexNet的参数,即微调AlexNet来对region proposal进行分类。因此需要将原来1000-way的分类层替换成了21-way的分类层(20类物体+背景)。

此外,对于IoU>0.5的region proposal被视为正样本,否则为负样本(即背景)。在每次迭代的过程中,选取32个正样本和96个负样本组成一个mini-batch。我们使用0.001的学习率和SGD来进行训练。
2.3 Testing
虽然文中训练了CNN网络对region proposal进行分类,但是实际中这个CNN的作用只是提取每个region proposal的feature,因此,在testing的过程中,我们输入region proposal,然后AlexNet的FC7层会输出4096维的特征,然后我们将这些特征保存起来,以供后续的分类使用。
3. Classify regions
本文使用了SVM来进行分类,对于每一类都会训练一个SVM分类器,所以共有N(21)个分类器,该分类器的主要作用是判断我们同样来看一下是如何训练和使用SVM分类器的。
3.1 Training
如下图所示,在训练过程中,SVM的输入包括两部分:

(1) CNN feature:这个便是CNN网络为每个region proposal提取的feature,共2000*4096。
(2) Ground truth labels: 在训练时,会为每个region proposal附上一个label,在SVM分类过程中,当IoU<0.3时,为负样本,然后正样本便是ground-turth box(个人理解应该是和ground truth box重合度最高的region proposal)。但是,对于label的形式没有详细说明,但是根据我个人理解,正负样本的label应该是以下的形式:
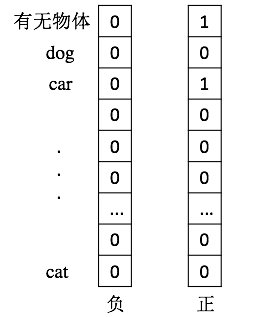
然后SVM分类器也会输出一个预测的labels,然后用labels和ground truth labels计算loss,然后训练SVM。
3.2 Testing
Testing的过程就是输入经过之前的步骤得到test image的region proposal的feature,然后输出对2000个proposal的类别预测值。
4. Non-maximum suppression
经过SVM之后,我们会得到2000个region proposal的class probability,然后我们可以根据‘有无物体’这一类过滤掉一大批region proposal,然后如果某个候选框的最大class probability<阀值,那也可以过滤掉这些region proposal,那剩下的可能如下左图所示,就是有多个box相互重叠,但是我们目标检测的目标是一个物体有一个box即可,那这个时候就需要用到非极大值抑制(NMS)了,经过NMS之后,我们最终的检测结果如下右图所示:

限于篇幅,在这里就不详细介绍NMS啦,如果有不懂的同学,请参考()
5. Bounding box regression
有很多同学可能会感到疑惑,上边那步不是已经给出一个比较好的结果了吗,为什么还需要bounding box regression呢,为了解释这个问题,我们看下边这个例子:

图中,绿色的框表示Ground Truth Box, 红色的框为我们预测得到的region proposal 。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。所以我们需要对红色的框进行微调,使得经过微调后的窗口跟Ground Truth Box更接近,这样就可以更准确的定位了。限于篇幅,这里就不展开讲解bounding box regression了,如果有不懂的同学,可以参考()。
至此,我们已经讲解完了整个R-CNN的训练和测试过程,作为R-CNN家族的鼻祖,这篇文章的许多思想和做法都在后续的paper中有用到,但是我们也能意识到这篇文章确实存在着不足之处:
- 训练时间长:主要原因是分阶段多次训练,而且对于每个region proposal都要单独计算一次feature map,导致整体的时间变长。
- 占用空间大:主要原因是每个region proposal的feature map都要写入硬盘中保存,以供后续的步骤使用。
- multi-stage:文章中提出的模型包括多个模块,每个模块都是相互独立的,训练也是分开的。
这些不足也会在后续的paper中逐渐改进,我也会持续更新R-CNN系列的模型,欢迎大家持续订阅哦~















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









