





切尔诺贝利
‘Resilience’ seems more like a buzzword today. But as the trend graph shows above, we have started to lean into resilience over determinism in an increasingly complex, chaotic and connected world. I will share some historical narratives, practices and examples of building resilience into software systems through a proposed conceptual framework called “MARLA”.
今天,“弹性”似乎更像是一个流行语。 但是,正如上面的趋势图所示,在一个日益复杂,混乱和相互联系的世界中,我们已经开始倾向于确定性的弹性。 我将分享一些历史性的叙述,实践和通过建议的概念框架“ MARLA ”将抵御能力构建到软件系统中的示例。
什么是弹性 (What is Resilience)
Traditionally speaking, resilience is the property of “bouncing back” from unexpected circumstances. Such “unexpected circumstances” are highly expected in modern systems. Long-lived code, infrastructure, human-computer interactions, vast scale and domains — each contributes to the ever growing complexity of the system. e.g., at Google’s scale failures with one in a million odds are occurring several times a second. “As the complexity of a system increases, the accuracy of any single agent’s own model of that system decreases rapidly.” In this world-view, resilience is not about reducing negatives or errors. It is rather a branch of engineering — how to identify and enhance the “positive capabilities of people in organizations that allow them to adapt effectively and safely under varying circumstances.”
从传统上讲,弹性是意外情况“ 反弹 ”的特性。 在现代系统中,这种“意外情况”是高度期望的。 长期存在的代码,基础结构,人机交互,大规模和领域化-均导致系统的复杂性不断提高。 例如,在Google的规模下,每秒发生几百万次故障的可能性为数百万次。 “随着系统复杂性的增加,该系统的任何单个代理自身模型的准确性都会Swift下降。” 在这种世界观中,弹性并不是要减少负面影响或错误。 这是工程学的一个分支,即如何识别和增强“组织中人员的积极能力,使他们能够在不同情况下有效,安全地适应。”
In a slightly different ‘future proofing’ world-view, since outlier events are the ‘new normal’ we must abandon the statistical realm of risk management and embrace our beliefs about an uncertain future. In this approach, rather than bounce-back, we ‘bounce forward’ to a ‘new normal’ and plan for risks that cannot be predicted in advance.
在稍微不同的“未来证明”世界观中,由于异常事件是“新常态”,因此我们必须放弃风险管理的统计领域,并接受我们对不确定的未来的看法。 在这种方法中,我们不是“ 反弹 ”,而是“ 反弹 ” 到“新常态”,并计划无法预先预测的风险。
The first-model of ‘bouncing back’ is perhaps more applicable to the majority of the software systems. We therefore will focus on that. However, since it is possible to simulate uncertainty in such systems using modern tools (e.g., Chaos Testing), we will integrate the ‘future proofing’ model in our conceptual framework as well.
“反弹”的第一个模型也许更适用于大多数软件系统。 因此,我们将专注于此。 但是,由于可以使用现代工具(例如,混沌测试)在此类系统中模拟不确定性,因此我们也将“未来证明”模型集成到我们的概念框架中。
为什么软件需要弹性 (Why Software Needs Resilience)
More than two out of three lines of code running in our system is not written by anyone who works with us, or even anyone who ever directly worked with us. Number of lines of code in all libraries and external frameworks easily dwarf the code written by us. Then such unknown code will run at some unknown computer at some unknown location and interact with gazillion external services each with its own non-determinism. Failure is therefore a statistical certainty, and — without considerable thoughtful planning and processes — continuous success will remain a miracle. Resilience offers models and tools to conquer this non-determinism and avoid cosmic scale failures.
在我们系统中运行的三行代码中,有超过两行不是由与我们合作的人,甚至没有直接与我们合作的人编写的。 所有库和外部框架中的代码行数很容易使我们编写的代码相形见war。 然后,这样的未知代码将在某个未知位置的某个未知计算机上运行,并与庞大的外部服务交互,每个外部服务都具有自己的不确定性。 因此,失败是统计上的确定性,并且-在没有大量周密的计划和流程的情况下-持续成功将仍然是奇迹。 弹性提供了模型和工具来克服这种不确定性并避免宇宙尺度的破坏。
In medicine, doctors were once trained on Zebra principle — ”when you hear hoofbeats, think of horses not zebras”. This is a derivative of Occam’s razor where the simplest explanation is the most likely one. While the heuristics may still work on isolated humans, in inter-connected technology land it is Zebras all the way down! ‘Unexpected is regularly expected’ and ‘prepare to be unprepared’ are thus the best safety policies for organizations.
在医学上,医生曾经接受过斑马原理的培训-“当您听到蹄声时,请想一想马而不是斑马”。 这是Occam剃刀的派生词,其中最简单的解释是最可能的解释。 尽管启发式方法可能仍然适用于孤立的人,但在相互连接的技术领域,斑马线一直都在下降! 因此,“经常发生意料之外的事”和“做好准备的事”是组织的最佳安全策略。
To extend the metaphor, regular “quality tests” check for known horses while — by induction — unknown zebras zip line into nasty production incidents. Since we can only test for horses (known/risk), we get zebras (unknown/uncertainty).
为了扩展这个比喻,定期的“质量测试”会检查已知的马匹,同时通过归纳法将未知的斑马拉索拉入恶劣的生产事故中。 由于我们只能测试马匹(已知/风险),因此我们得到斑马(未知/不确定性)。
An example — flying birds hitting a plane is a very common problem and could cause serious damage to flights. Jet engines are therefore tested by throwing about 8 small- and 16 medium- sized bird carcasses (with feathers!) while running at full power. Small bird weight guidance is about 4.5 lb. and medium 8 lb. Most passenger planes are also required to have N engines and certified ability to fly with (N-1) engines ‘broken’. On January 15. 2009 , however, a flock of Canadian geese hit US Airways flight 1549. Canadian Geese easily weigh more than 15 lb. and they travel in flocks of hundreds. Both the engines of the Airbus A320 were damaged. This was an inevitable Zebra event that no one would anticipate in any “sandbox” environment. The resulting safe landing of passengers — known as “Miracle on the Hudson” — is a great example of a complex system showing resilience to Zebra events.
一个例子-飞鸟撞击飞机是一个非常普遍的问题,可能会严重损害飞行。 因此,在全功率运行时, 通过扔掉约8个小型和16个中型鸟体 (有羽毛!)来测试喷气发动机。 小型鸟的重量指导约为4.5磅, 中型则为8磅。大多数客机还需要配备N台发动机,并且具有通过“破损”(N-1)台发动机飞行的认证能力。 但是,在2009年1月15日,一群加拿大鹅袭击了美国航空1549航班。加拿大鹅的体重很容易超过15磅,成群结队地飞行。 空客A320的两个引擎都损坏。 这是不可避免的Zebra事件,在任何“沙盒”环境中没人会想到。 由此产生的乘客安全降落-被称为“ 哈德逊奇迹 ”-是显示对斑马事件有弹性的复杂系统的一个很好的例子 。

MARLA —弹性概念框架 (MARLA — Conceptual Framework for Resilience)
In distributed computing “safety” and “liveness” are two inherent attributes of every system. Safety ensures “no bad thing ever happens”. Liveness implies “good (or, expected) thing ultimately happens”.
在分布式计算中,“安全性”和“活动性”是每个系统的两个固有属性。 安全确保“绝不会发生坏事”。 活泼意味着“好事(或预期的事)最终会发生”。
After working through safety features that work, hundreds of incidents and failures (many of those caused by yours truly!), sifting through history, studying real-life failures-at-large I propose MARLA — a five-headed conceptual framework to build and increase software resilience (therefore, also safety properties) -
在研究了有效的安全功能之后,数百起事件和失败(很多是您真正造成的!), 回顾历史,研究整个现实中的失败,我提出了MARLA (五头概念框架,用于构建和提高软件弹性(因此也提高了安全性)-
Monitoring
监控方式
Application Design
应用设计
Responding
回应
Learning
学习
Adapting
适应
Let us walk through each, starting with a narrative and offer some concrete pointers to work with in real life.
让我们从叙述开始,逐一讲解,并提供一些在现实生活中可以使用的具体指示。
1.监控-如何不错过未来的冰山? (1. Monitoring — How not to miss the Icebergs ahead?)
“Observability is Monitoring that went to college”.
“可观察性是上大学的监控”。
Among many probable causes, a binocular was not available at “Crow’s Nest” to give early warning of an iceberg ahead. “There were binoculars aboard the Titanic, but unfortunately, no one knew it. The binoculars were stashed in a locker in the crow’s nest — where they were most needed — but the key to the locker wasn’t on board. That’s because a sailor named David Blair, who was reassigned to another ship at the last minute, forgot to leave the key behind when he left. The key was in Blair’s pocket. Lookout Fred Fleet, who survived the Titanic disaster, would later insist that if binoculars had been available, the iceberg would have been spotted in enough time for the ship to take evasive action. The use of binoculars would have given “enough time to get out of the way,” Fleet said.”
在许多可能的原因中,“乌鸦之巢”没有提供双筒望远镜来预警前方的冰山。 “泰坦尼克号上装有双筒望远镜,但不幸的是,没人知道。 双筒望远镜被藏在最需要它们的乌鸦巢中的储物柜中,但是储物柜的钥匙不在船上。 那是因为名叫David Blair的水手在最后一分钟被重新分配到另一艘船上时,忘记了离开时留下的钥匙。 钥匙在布莱尔的口袋里。 在泰坦尼克号灾难中幸存下来的监视弗雷德·弗利特(Fred Fleet)后来坚持认为,如果可以使用双筒望远镜,那么冰山应该在足够的时间内被发现,以便舰船能够采取规避行动。 舰队表示,使用双筒望远镜将“有足够的时间摆脱干扰”。
Monitoring has come a long way and has now branched into alerting, real-time log searches, and distributed tracing. Once we expected binary answers from our monitors — “Is the database up”, “Does the storage have enough capacity left” etc. Good, modern monitoring should raise questions — “Why do we have a spike in invoice creation on Monday noon”, “Why did the 4 PM batch job take 20% longer today” etc.
监视已经走了很长一段路,现在已经扩展到警报,实时日志搜索和分布式跟踪。 一旦我们预期监视器会给出二进制答案,例如“数据库是否已启动”,“存储设备是否还有足够的容量”等。好的,现代化的监视器应会提出一些问题—“为什么周一中午发票创建量会激增”, “为什么今天下午4点批处理作业要花费20%的时间更长”等
We can generally monitor three sets of things — Network (e.g., % of non-200 response variability), Machines (e.g., database server) and Application (e.g., read:write ratio).
我们通常可以监视三组事物-网络(例如,非200响应可变性的百分比),机器(例如,数据库服务器)和应用程序(例如,读/写比率)。
A good framework to create useful monitors across the sets is RED -
在整个集合中创建有用的监视器的一个很好的框架是RED-
Rate (e.g., number of transactions/second; CPU utilization), Error (e.g., HTTP 500s; Query Timeouts; Deadlocks etc), and Duration (e.g., 99-percentile latency for login etc).
速率(例如,每秒事务数; CPU利用率),错误(例如,HTTP 500,查询超时,死锁等)和持续时间(例如,登录的99%延迟)等。
While alerting on a large upswing variability across all three buckets is a good practice — rate metrics are usually “alerted” on system-specific thresholds (ALWAYS alert on CPU > 65%), error metrics often on a binary OR up/down trend, and application metrics are often paired with domain-specific adjacencies (e.g., if the login rate is high, standalone (attack?) OR in conjunction with a new session stickiness parameter recently launched).
虽然警告所有三个存储桶都有较大的上升变化是一个好习惯-速率指标通常会根据系统特定的阈值“更改”(CPU始终> 65%时始终为警报),错误指标通常会采用二进制或上下变化趋势,和应用程序指标通常与特定于域的邻接关系配对(例如,如果登录率很高,独立(攻击?),或者与最近启动的新会话粘性参数结合使用)。
Remember, monitoring in a vacuum — i.e., non-actionable metrics — is a drain to the system. If a tree is counted as “fallen” and no one looks into it, the forest still has the same number of trees as far as we are concerned.
请记住,在真空中进行监视(即不可操作的指标)会浪费系统。 如果一棵树被认为是“倒下”而没有人看着它,那么就我们而言,森林仍然有相同数量的树。
Important metrics do not need immediate attention. Growth (e.g., TPV), Cost (e.g., Customer Call Rate), Rate (e.g., % of HTTP-500 errors) metrics are important. Urgent metrics require immediate action or escalation, and any exception should be automatically radiated to the entire team. Uptime, Availability, Critical Errors, Serious threshold breach (e.g., >80% CPU in Database server) are generally urgent metrics. Exception processing in Urgent metrics should also be properly documented (e.g., what to do if the midnight process stalls and does not finish within an hour). A good guidance for leaders is to choose 3 to 5 important metrics and look at it every day (urgent) or every week (important) to track variability. Proactive alerting should, of course, be set for operational teams or on-call engineers to respond to emergencies. But As Yogi Berra reportedly said, “You can observe a lot just by watching”. I have found the practice of starting- or ending the day by looking at the urgent metrics and weekly broadcast to the respective teams on important metrics very useful practice. Teams then pay attention to important metrics and start asking the right questions themselves. Choosing right metrics and medium for cascading itself becomes a big safety feature of the system.
重要指标不需要立即关注。 增长(例如TPV),成本(例如客户呼叫费率),费率(例如HTTP-500错误的百分比)指标很重要。 紧急指标需要立即采取行动或升级,任何异常都应自动辐射给整个团队。 正常运行时间,可用性,严重错误,严重的阈值违反(例如,数据库服务器中的CPU> 80%)通常是紧急指标。 还应正确记录紧急指标中的异常处理(例如,如果午夜进程停顿并且在一小时内未完成,该怎么办)。 对领导者的一个很好的指导是选择3到5个重要指标,并每天(紧急)或每周(重要)对其进行检查以跟踪变化。 当然,应该为运营团队或值班工程师设置主动警报,以应对紧急情况。 但正如Yogi Berra所说的那样,“只要观察就可以观察到很多东西”。 我发现通过查看紧急指标来开始或结束一天的做法,并且每周在重要指标上向各个团队进行广播是非常有用的做法。 然后,团队会注意重要的指标,并开始自己提出正确的问题。 选择正确的度量标准和介质进行级联本身已成为系统的一项重要安全功能。
While the general trend is to create an alert on exceptions, I strongly endorse the notion of “Positive Alerts”. High-performing teams I worked with recommend to radiate business-critical and regular processes’ positive outcomes to team Slack channels as well. An example of a positive alert could be “Successful Completion of Most Important Batch Job” that is expected around 6PM every weekday. In such cases, we have observed the absence of the positive alerts is immediately noticed and often a large failure can be avoided. i.e., if we tell people every day that “No tree fell today” and miss saying that one day, people usually walk to the forest to check out if things are alright.
尽管总的趋势是针对异常创建警报,但我强烈支持“正面警报”的概念。 与我一起工作的高效团队建议将关键业务和常规流程的积极成果也传递给团队Slack渠道。 积极警报的示例可能是“成功完成最重要的批处理作业”,预计每个工作日下午6点左右。 在这种情况下,我们观察到没有积极警报的情况会立即被注意到,并且通常可以避免大的故障。 即,如果我们每天告诉人们“今天没有树倒下”而错过了说一天的回忆,人们通常会走到森林里检查一切是否正常。
2.应用程序设计-如何让事情优雅地失败? (2. Application Design — How to let things fail gracefully?)
“In theory, theory and practice are the same. In practice, they are not.”
“在理论上,理论和实践是相同的。 实际上,它们不是。”
“Programming is a race between software engineers striving to build better and bigger idiot-proof programs, and the Universe trying to produce bigger and better idiots. So far, the Universe is winning.”
“编程是软件工程师之间的竞赛,他们努力构建更好,更大的防白痴程序,而Universe则试图产生更大,更好的白痴。 到目前为止,宇宙正在胜利。”
“You’ve baked a really lovely cake, but then you’ve used dog shit for frosting.” — Steve Jobs
“您已经烤了一个非常可爱的蛋糕,但是随后您用狗屎来结霜。” —史蒂夫·乔布斯
Titanic also had only 20 lifeboats — just enough to carry only about half the passengers. Designing domain-agnostic safety measures in application is similar to having enough lifeboats. In principle, this often boils down to the stacked-rank choice of what to let fail so more important stuff can survive. The survivability options of features or services must be a key design choice objectively made. i.e., upon what context should this service retry/shed load/fail-over/shutdown/respond with stale data etc? And how does that local choice impact global system (e.g., cascading failures, gap propagation, compensating transactions, manual clean-up etc.)?
泰坦尼克号还只有20艘救生艇-仅够运送大约一半的乘客。 在应用程序中设计与领域无关的安全措施类似于拥有足够的救生艇。 原则上,这通常归结为失败的堆叠选择 ,以便更重要的东西可以生存。 功能或服务的可生存性选项必须是客观地做出的关键设计选择。 即,该服务应在什么情况下重试/放弃加载/故障转移/关闭/以过时的数据等响应? 本地选择如何影响全球系统(例如,级联故障,差距传播,补偿交易,手动清理等)?
Key Principles -
关键原则 -
- Failures are inevitable, in both hardware and software. 硬件和软件都不可避免地会发生故障。
A priori prediction of all, or even any, failure modes is not possible. Since many failures are completely unexpected, it is not possible to address each type of failure in a cost-efficient manner. We therefore should embrace a set of safety patterns and implement them in a low-cost, high-fidelity way.
无法对所有甚至任何故障模式进行先验预测 。 由于许多故障是完全无法预料的,因此无法以经济高效的方式解决每种类型的故障。 因此,我们应该采用一套安全模式,并以低成本,高保真度的方式实施它们。
Modeling and analysis can never be sufficiently complete. Monitoring, especially important metrics, should iterate into the model.
建模和分析永远不可能足够完整。 监视(尤其是重要的指标)应迭代到模型中。
Human action is a major source of system failures. Application design should over-index human action variability. This is what Google calls Hyrum’s Law: With a sufficient number of users of an API, all observable behavior of your system will depend on a random person doing a random thing. Someone could enter “999999” as the year in the only obscure page our engineers did not bother to validate field input and that could trigger a static date-driven logic to run forever leading to a system crash (note: exact same thing happened with me!)
人为操作是系统故障的主要根源。 应用程序设计应过度索引人类行为的可变性。 这就是Google所谓的Hyrum定律 :有了足够的API用户,您系统中所有可观察到的行为将取决于随机的人在做随机的事情。 在我们的工程师没有费心去验证字段输入的唯一晦涩页面中,有人可以输入“ 999999”作为年份,这可能会触发静态日期驱动逻辑永久运行,从而导致系统崩溃(注意:我发生的完全相同) !)
Real life Lessons -
现实生活中的教训 -
Every failing system starts with a queue backing up somewhere.
每个发生故障的系统都始于某个地方备份的队列 。
That somewhere is almost always the database! The more ‘down’ the stack, the more risk it poses to the system.
这地方几乎总是数据库! 堆栈越“ 向下 ”,对系统造成的风险就越大。
RTT — Retry-Timeout-Throttle — are the three most useful and simple to implement safety attributes in remote or distributed calls. Still, at least half the remote calls I have seen implemented do not have automatic retry built-in!
RTT — Retry-Timeout-Throttle —是在远程或分布式呼叫中实现安全属性的三个最有用和最简单的方法。 尽管如此,我看到的至少有一半的远程调用没有内置自动重试功能!
- Generally speaking - 一般来说 -
Retry — ensures safety of the Process
řetry -确保过程的安全
Timeout — ensures safety of the Instance
牛逼 imeout -实例,保证安全
Throttle — ensures safety of Overall System
牛逼 hrottle -确保整个系统的安全性
Software design today resembles automobile design in the early ’90s — disconnected from the real world. Then we rapidly built traffic-aware cruise control, ABS, backup camera, collision warning system and self parking in the last decade. Like a car today is expected to have these safety features even in ‘basic’ models, software applications can use standard, open-source libraries (e.g., Hystrix) to implement patterns like RTT with minimal or zero code.
今天的软件设计类似于90年代初的汽车设计-与现实世界脱节。 然后在过去的十年中,我们Swift构建了具有交通意识的巡航控制系统,ABS,倒车摄像头,碰撞预警系统和自助泊车系统。 就像今天的汽车一样,即使在“基本”模型中也有望具有这些安全功能,软件应用程序可以使用标准的开源库(例如Hystrix)以最少的代码或零的代码来实现RTT之类的模式。
Retry is our friend in simple use cases. Speculative retries, however, allow failures to jump the gap. A slowdown in the provider will cause the caller to fire more speculative retry requests, tying up even more threads in the caller at a time when the provider is already responding slowly. In advanced cases, use backoff (each retry spaced intelligently) and jitter (so multiple servers do not all retry together and create a “thundering herd” problem) to make retry safe. At a truly large scale, rejecting rather than retrying may add more global safety. Such a rejection pattern is also known as Load Shedding or Circuit-breaker.
在简单的用例中,重试是我们的朋友。 但是,投机性重试允许失败跳过差距。 提供程序的速度降低将导致调用方触发更多的推测性重试请求,而在提供程序已经响应缓慢的时候,调用方将占用更多线程。 在高级情况下,请使用退避 (每个间隔都以智能方式间隔开)和抖动 (因此多个服务器不会全部一起重试并产生“打雷群”问题)以确保重试安全。 从真正意义上讲, 拒绝而不是重试可能会增加全局安全性。 这种拒绝模式也称为减载或断路器。
Timeouts are more important at the core (e.g., in database) than at the edge. Retry and throttle are much easier to build on the edge than at the core.
超时在核心(例如,在数据库中)比在边缘更重要。 重试和限制比在核心上容易构建得多。
3.响应-在不可避免的情况下该怎么办? (3. Responding — What to do during the inevitable?)
Failures, especially large-scale failures, are inevitable. What to do when it happens? After a big crash, air traffic controllers take more time to get back to work than pilots or cabin crews. Psychological study says involvement in action builds psychological resilience (as opposed to system). First rule of responding therefore is — participate and own it! Then try to contain it with no other associated damage from the containment. Containment is not resolution. An incident is contained when regular life/behavior could resume even if the system may not be at an optimal level.
失败,尤其是大规模失败是不可避免的。 发生时该怎么办? 发生严重事故后,空中交通管制员要比飞行员或机组人员花费更多的时间才能恢复工作。 心理学研究表明,参与行动可以增强心理适应能力(相对于系统)。 因此,做出回应的首要原则是- 参与并拥有它! 然后尝试将其围住,而不会导致围护造成其他相关损坏。 遏制不是解决方案。 即使系统可能未达到最佳水平,也可以恢复正常的生活/行为,从而包含了事件。
Real life Lessons -
现实生活中的教训 -
5-WHYs is a simplistic and underused tool. Can quickly get to an actionable task. Could be misleading too.
1-WHO or 1-WHAT is what our mind tries to quickly arrive at. As someone once said, “For every complex problem there is an answer that is clear, simple, and wrong”. Be careful of quickly arriving at a fix, or worse, pinpointing failure at anyone.
1-WHO或1-WHAT是我们的思维试图快速达到的目标。 就像有人曾经说过的:“对于每个复杂的问题,答案都是明确,简单和错误的”。 要小心,要Swift找到解决办法,或更糟糕的是,要指出任何人的失败。
Listing human error as a root cause isn’t where we should end, it’s where we should start investigation. Getting behind what led to a ‘human error’ is where the good stuff happens, but unless you’ve got a safe political climate (i.e., no one is going to get punished or fired for making truly non-career limiting mistakes) you’ll never get at how and why the error was made. There is no pilot error, only cockpit errors.
将人为错误列为根本原因并不是我们应该结束的地方,而是应该开始调查的地方。 躲在导致“人为错误”的地方是好事发生的地方,但是除非您有一个安全的政治气氛(即,没有人会因犯真正的非职业限制错误而受到惩罚或开除),我永远不会知道错误的产生方式和原因。 没有飞行员错误,只有驾驶舱错误。
However, reality is often different. A very well known leader, and someone who I deeply admire, told me after a really bad failure — “Every such incident takes away SIX months of your good work.” Empirically, I found it to be quite accurate. Teams grapple with blowback, technical or political, after a large failure for months. Another such reality, specifically in executive leadership, is well illustrated by the parable of the three envelopes. A leader’s declining influence and effectiveness is significantly correlated with either repeating incidents of the same nature or duration of a large-scale incident. Irrespective of the currency — fiat or crypto — the proverbial buck does stop with the leader!
但是,现实往往是不同的。 一位非常著名的领导者,以及我深为钦佩的人,在经历了一次非常严重的失败之后告诉我:“ 每一次此类事件都占用了您六个月的良好工作 。” 根据经验,我发现它是非常准确的。 在几个月的重大失败之后,团队努力应对技术或政治上的反吹。 三个信封的寓言很好地说明了另一个这样的现实,尤其是在执行领导中。 领导者的影响力和有效性下降与重复发生的相同性质的事件或大规模事件的持续时间密切相关。 不管使用哪种货币(法定货币或加密货币),众所周知的降价都不会随着领导者而停止!
Latitude, Longitude and Altitude could precisely pinpoint one’s location. In, especially, engineering leadership the three analogs of where you stand are -
纬度,经度和海拔高度可以精确地确定一个人的位置。 特别是在工程领导中,您所处位置的三个类似物是 -
Are you delivering big things in time? (i.e., Slippage)
您是否及时交付大件东西? (即滑点)
Is your team’s productivity at par for the course? (i.e., Velocity)
您的团队的生产力在课程中是否达到同等水平? (即速度)
How many big accidents from your team recently impacted business? (i.e., Safety)
您的团队最近发生了几起重大事故 ,影响了业务? (即安全)
Therefore, anyone’s natural charter should include resilience for both business and career reasons. Remember, incidents cannot be avoided but we can prevent many, if not all, accidents. While innovations can elevate the career ceiling, big incidents most certainly lower the floor often with the bottom falling out.
因此,出于业务和职业原因,任何人的自然宪章都应包括弹性。 请记住,事件是无法避免的,但是我们可以预防很多(如果不是全部)事故。 尽管创新可以提高职业生涯的最高水平,但重大事件最有可能降低底线,而底部却倒塌了。
In the incident management “War Room” three principles to follow are -
在事件管理“ 作战室 ”中要遵循的三个原则是:
Keep your calm. Ability to retain calm under production pressure is a magical superpower. Listen to a clip of Gene Kranz later in the essay and his tone after “Houston, we have a problem” Apollo 13 incident.
保持冷静 。 在生产压力下保持镇定的能力是一个神奇的超级大国。 在文章稍后的内容中聆听Gene Kranz的片段,以及在“休斯顿,我们有问题”阿波罗13号事件后的语气。
Gather data from multiple sources, aggregate and radiate it (e.g., using whiteboard). Allocate any concrete action item to one specific owner to look at. The fastest way to starve a horse is to assign two people to feed it. Core of successful Crisis Leadership lies in fast problem-to-single ownership mapping.
收集来自多个来源的数据 ,进行汇总和辐射(例如,使用白板)。 将任何具体的操作项目分配给一个特定的所有者以供查看。 饿马最快的方法是指派两个人喂它 。 成功的危机领导力的核心在于快速的问题到单个所有权映射 。
List recent change events and prepare progressive rollbacks, where applicable. There is no shame in retreats if it saves lives.
列出最近的更改事件,并在适用时准备逐步回滚。 如果能挽救生命,务虚会就不会丢脸。
Lastly, “do no more harm”. As Gene Kranz so eloquently blasted into space — “Let’s solve the problem, but let’s not make it any worse by guessing”. Software problem solving suffers a lot from what the medical field calls “Iatrogenic Deaths” — where the healer indirectly causes death.
最后,“ 不再伤害 ”。 正如吉恩·克兰兹(Gene Kranz)雄辩地冲入太空-“让我们解决问题,但让我们不要通过猜测使情况变得更糟”。 软件问题解决受到医学领域称为“医源性死亡”的困扰,医治人员间接导致死亡。
4.学习-没杀死我们的东西应该使我们变得更坚强 (4. Learning — Whatever didn’t kill us should make us stronger)
“Good judgments come from experience, experience comes from bad judgments”.
“好的判断来自经验,经验来自坏的判断”。
Lessons
经验教训
Learning from it is the success of each failure. Incidents are unavoidable but we must build immunity to the incident in the future.
从中学习是每一次失败的成功 。 事故是不可避免的,但我们将来必须对事故建立免疫力。
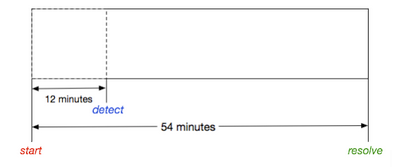
Always ask three big questions after each big incident -
在每次重大事件发生后,请务必提出三个大问题 -
When did we know it and who knew it first? MTTD (Mean Time To Detect).
我们什么时候知道的?谁先知道的? MTTD (平均检测时间)。
When did we contain it? MTTR (Mean Time To Resolve)
我们何时包含它? MTTR (平均解决时间)
Can it happen again tomorrow? MTBF (Mean Time Between Failures)
明天还能再发生吗? MTBF (平均无故障时间)
Broad action areas depending on the answer(s) —
广泛的行动领域取决于答案-
If MTBF is more than a minute OR caught by a human (not a machine), we have a Monitoring problem.
如果MTBF超过一分钟或被人(而不是机器)捕获,则存在监控问题。
If MTTR is more than an hour, we have an Application Design problem.
如果MTTR超过一个小时,则说明我们存在应用程序设计问题。
If MTBF is less than a month, we have a WTF problem (more specifically, we are not learning from past failures).
如果MTBF少于一个月,则说明我们存在WTF问题 (更具体地说,我们没有从过去的失败中学习)。
Hollywood Homicide Principle — if a murder is not solved within 72 hours, it is unlikely to be solved. Create a uniform format “Incident Report” within 72 hours. Share the report transparently via a shared document drive. That drive becomes institutionalized knowledge. Following is a one-page template I like to use, but any structured template should work equally well, or even better,
好莱坞凶杀案原则 -如果在72小时内不解决谋杀案,就不太可能解决。 在72小时内创建统一格式的“事件报告”。 通过共享文档驱动器透明地共享报告。 这种驱动成为制度化的知识。 以下是我喜欢使用的一页模板,但是任何结构化模板都应同样出色甚至更好地工作,
5.适应-永不踏步两次。 (5. Adapting — One Never Steps in the Same River Twice.)
Murphy’s Law: “Anything that can go wrong will go wrong”.Stigler’s Law: “No scientific discovery or law is named after its original discoverer”
墨菲定律 :“任何可能出错的地方都会出错”。 斯蒂格勒定律 :“没有科学发现或法律是以其原始发现者命名的”
Lessons:
经验教训 :
Anna Karenina Principle: Happy families are all alike; every unhappy family is unhappy in its own way. Each incident is a different zebra. By induction: if they were similar, they would be caught from testing/determinism. You don’t step in the same river twice. Either you will change or the river would. Likely both. System, user and their interactions are changing rapidly even in supposedly less-mutable workspaces like Payments.
安娜·卡列尼娜(Anna Karenina)原则 :幸福的家庭都是相似的。 每个不幸的家庭都会以自己的方式感到不幸。 每个事件都是不同的斑马 。 通过归纳法:如果它们相似,它们将被测试/确定性所吸引。 您不会两次踏入同一条河。 要么您会改变,要么河会改变。 可能两者都有。 即使在付款等所谓的可变性较小的工作区中,系统,用户及其交互也正在Swift变化。
More than 50% of what we apply at Technology jobs is learned, possibly even invented, in the last four years. We must adapt, and adapt fast.
在过去的四年中,我们了解了甚至超过50%的我们从事技术工作的知识。 我们必须适应并Swift适应 。
Prepare well to be completely unprepared. Be at a constant unease about the system. Everything running smoothly is an aberration and, honestly, a miracle.
做好充分准备,以防万一 。 对系统保持不安。 一切运转顺利都是一种畸变,老实说是一个奇迹 。
Opposable thumb evolved over billions of years. Then we went from Steam Engine to Auto-pilot under 200. How to speed adaptation in our system? This is where software systems offer significant advantage over organic systems. We can simulate “adaptation”, and therefore inject uncertainty and prepare the system, very cheaply with modern frameworks, elastic compute stacks and industrial strength monitoring tools. We can define a “Maturity Model” for such adaptation -
相反的拇指已经发展了数十亿年。 然后,我们从200以下的Steam Engine转到自动驾驶。 如何在我们的系统中加快适应速度 ? 这是软件系统相对于有机系统具有明显优势的地方。 我们可以模拟“适应”,从而注入不确定性并使用现代框架,弹性计算堆栈和工业强度监视工具非常便宜地准备系统。 我们可以为这种适应定义一个“成熟度模型”-
Level 1: Game Days are like vaccines to the known “diseases”. Game days, even “dry” game days where the team simulates a system failure and its reaction, tests the preparedness. These are the fire drills.
级别1 : 游戏日就像是针对已知“疾病”的疫苗。 游戏日,甚至是团队模拟系统故障及其React的“枯燥”游戏日,都会测试准备情况。 这些是消防演习。
Level 2: “Right shift” and start run Synthetic Transactions in production. These transactions can then be varied with both amplitude and frequency to understand the limits of present tolerance.
第2级 :“右移”并开始在生产中运行综合交易 。 然后,可以根据幅度和频率来改变这些事务,以了解当前容限的限制。
Level 3: Highest level resilience engineering with modern systems is often called Chaos Testing. In this level, random events and uncertainties are carefully injected into subsystems to both test and understand the outcomes. “If you don’t test it, the universe will, and the universe has an awful sense of humor.”
级别3 :具有现代系统的最高级别的弹性工程通常称为混沌测试 。 在这个级别上,将随机事件和不确定性仔细注入子系统中,以测试和了解结果。 “如果不进行测试,那么宇宙将会,并且宇宙会充满可怕的幽默感。”
能力模型-评估团队的弹性分数 (A Capability Model — Evaluate Your Team’s Resilience Score)
Add “1” for every “Yes” answer to the 10 questions — a score above 7 is good!
对10个问题的每一个“是”答案都添加“ 1”-得分高于7是很好的!
Do you have 3–5 key RED alerts for most important processes?
对于最重要的过程,您是否具有3–5个关键的RED警报?
Did machines rather than humans report the last 5 customer impacting incidents?
是机器而不是人员报告了最近5个客户影响事件吗?
Does every team member see these alerts in your team channel?
每个团队成员都会在您的团队频道中看到这些警报吗?
Does your team have “Positive Alerts” as well?
您的团队也有“ 正面警报 ”吗?
Do your distributed calls have Retry built in?
您的分布式呼叫是否内置了Retry ?
Do cross-stack calls Timeout?
跨堆栈调用是否超时 ?
Do API calls have Throttle set with the backend max capacity in mind?
API调用是否已考虑到Throttle的后端最大容量?
Do you create the incident report within 72-hours of a customer impacting incident?
您是否在客户影响事件发生后72小时内创建事件报告 ?
Is there a shared, up-to-date document drive for all your incident reports?
是否有用于所有事件报告的共享的最新文档驱动器 ?
Do you have Synthetic Transactions for your key workflows running in production?
您的生产中正在运行的关键工作流程是否具有合成交易 ?
TL; DR (TL;DRs)
Watch out for Zebras — exotic failures are inevitable in today’s complex systems. Disasters are not.
提防Zebras-在当今复杂的系统中,不可避免的失败是不可避免的。 灾难不是。

History is a vast early warning system and we can, we must, learn from our failures. That is the success of failures. Emperor Augustus was completely inexperienced in warcraft when he “succeeded” his adopted father — Julius Caesar. Worse, contemporary historians documented he regularly suffered from “mysterious physical illness” during early key battles. He was neither physically imposing, nor had an elite blood lineage one needed to succeed in Rome those days. Despite all that, he “re-platformed” Rome from a republic to an empire, defeated several extremely talented generals (including Mark Anthony) and paved the way to the Greatest Enterprise ever — Roman Empire — that lasted 1500 years surviving formidable enemies. Augustus said about his success, “Young men, hear an old man to whom old men hearkened when he was young.”
历史是一个巨大的预警系统 , 我们必须能够从失败中学习 。 那就是失败的成功。 奥古斯都皇帝“继承”他的养父朱利叶斯·凯撒(Julius Caesar)时,对魔兽完全没有经验。 更糟糕的是,当代历史学家证明他在早期的关键战斗中经常遭受“神秘的身体疾病”的折磨。 那时他既没有身体强壮,也没有精英血统才能在罗马取得成功。 尽管如此,他还是将罗马从一个共和国“重新改造”为帝国,击败了几位才华横溢的将军(包括马克·安东尼),并为有史以来最伟大的企业-罗马帝国铺平了道路,历时1500年在强大的敌人中幸存。 奥古斯都谈到自己的成功时说:“年轻人,听到一个老人,年轻人小时候就听他的话。”
In today’s increasingly complex systems, failures are inevitable. Disasters are not. Following time-tested strategies, principles and — most importantly — by looking through our monitoring “binoculars” we can spot the iceberg ahead in time to turn the ship around.
在当今日益复杂的系统中, 故障是不可避免的。 灾难不是 。 遵循久经考验的策略,原则,最重要的是,通过观察我们的监控“双筒望远镜”,我们可以及时发现冰山,从而使飞船转身 。
弹性参考资料库 (Resilience Reference Library)

Measurement A Very Short Introduction — excellent ‘deep introduction’ to the science of measurement. The last chapter “Measurement and Understanding” highlights several flaws of solely relying on measurement (Cobra Effect, Body Count, Kill ratio et al). Can be finished in an afternoon.
测量非常简短的介绍 -对测量科学的出色“深入介绍”。 最后一章“测量与理解”强调了仅依靠测量的几个缺陷(眼镜蛇效应,人体计数,杀灭率等)。 可以在一个下午完成。
Drift into Failure — Excellent introduction to Complex Systems and Systems Thinking — the cause and antidote to large scale uncertainties. Very enjoyable anecdotes including how Gorilla glass almost made Gorillas extinct (think of mining!)
陷入故障 -复杂系统和系统思想的出色入门-导致大量不确定性的原因和对策。 非常有趣的轶事,包括大猩猩玻璃如何使大猩猩灭绝(想想采矿!)
The Field Guide to Understanding Human Error — fallacy of “root cause” and how to go beyond superficial blaming (i.e., learning)
理解人为错误的现场指南 -“根本原因”的谬误以及如何超越表面的责备(即学习)
Leadership in War — immensely enjoyable book of essays into War Leadership — from Hitler to Stalin to Thatcher. Stalin’s WW2 strategy is summed up as “in the end enough quantity becomes quality”.
领导在战争 -非常愉快的书撰入战争的领导者-从希特勒到斯大林撒切尔。 斯大林的第二次世界大战战略被概括为“ 最终足够的数量变成质量 ”。
Leadership in Turbulent Times — slightly less useful than the above, a very America-centric analysis of Crisis Leadership of Lincoln, Teddy Roosevelt, FDR and LBJ. LBJ section is the most interesting as he fully knew he was going against his/party’s interest to do the right thing.
动荡时代的领导力 -比上述方法用处稍小,这是对林肯,泰迪·罗斯福,罗斯福和罗斯杰的危机领导力的非常以美国为中心的分析。 LBJ部分是最有趣的部分,因为他完全知道他违背他/他的政党的利益去做正确的事。
Futureproof — lays out the “bouncing forward” model of resilience. Very applicable to really wicked problem like Climate non-determinism, nuclear energy and so on. Surprisingly readable.
面向未来 -勾画出回弹的“弹跳前进”的模式。 非常适用于诸如气候不确定性,核能等真正邪恶的问题。 令人惊讶的可读性。
Chernobyl (show)- gripping drama that covers science, emotion and human frailty around the epochal event. Must watch!
切尔诺贝利 ( 切尔诺贝利) (表演)-令人惊叹的戏剧,涵盖了划时代事件周围的科学,情感和人类脆弱。 必须注意!
Release It! (2nd Ed) — everything one needs to design “safe” applications. Excellent treatment of the RTT and many other useful patterns with real life war stories. Cannot recommend high enough if you are interested in just the development side of things.
释放它! (第二版)—设计“安全”应用程序所需的一切。 借助真实的战争故事对RTT和许多其他有用的模式进行出色的处理。 如果您仅对事物的开发方面感兴趣,则不能推荐足够高的水平。
How Complex Systems Fail — canonical reading. Few short pages condense the overarching themes of failures. Also, watch many Youtube videos by Richard Cook (the author) for many more insights.
复杂系统如何失败 -规范阅读。 很少有简短的页面凝聚了失败的总体主题。 另外,请观看Richard Cook(作者)的许多YouTube视频,以获取更多见解。
切尔诺贝利















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}