






tiny-cnn是一个基于CNN的开源库,它的License是BSD 3-Clause。作者也一直在维护更新,对进一步掌握CNN非常有帮助,因此以下介绍下tiny-cnn在windows7 64bit vs2013的编译及使用。
2. 源文件里已经包括了vs2013project,vc/tiny-cnn.sln,默认是win32的,examples/main.cpp须要OpenCV的支持。这里新建一个x64的控制台projecttiny-cnn。
3. 仿照源project,将对应.h文件加入到新控制台project中。新加一个test_tiny-cnn.cpp文件;
4. 将examples/mnist中test.cpp和train.cpp文件里的代码拷贝到test_tiny-cnn.cpp文件里;
#include
#include
#include
#include
#include
#include
using namespace tiny_cnn;
using namespace tiny_cnn::activation;
// rescale output to 0-100
template
double rescale(double x)
{
Activation a;
return 100.0 * (x - a.scale().first) / (a.scale().second - a.scale().first);
}
void construct_net(network& nn);
void train_lenet(std::string data_dir_path);
// convert tiny_cnn::image to cv::Mat and resize
cv::Mat image2mat(image<>& img);
void convert_image(const std::string& imagefilename, double minv, double maxv, int w, int h, vec_t& data);
void recognize(const std::string& dictionary, const std::string& filename, int target);
int main()
{
//train
std::string data_path = "D:/Download/MNIST";
train_lenet(data_path);
//test
std::string model_path = "D:/Download/MNIST/LeNet-weights";
std::string image_path = "D:/Download/MNIST/";
int target[10] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
for (int i = 0; i < 10; i++) {
char ch[15];
sprintf(ch, "%d", i);
std::string str;
str = std::string(ch);
str += ".png";
str = image_path + str;
recognize(model_path, str, target[i]);
}
std::cout << "ok!" << std::endl;
return 0;
}
void train_lenet(std::string data_dir_path) {
// specify loss-function and learning strategy
network nn;
construct_net(nn);
std::cout << "load models..." << std::endl;
// load MNIST dataset
std::vector train_labels, test_labels;
std::vector train_images, test_images;
parse_mnist_labels(data_dir_path + "/train-labels.idx1-ubyte",
&train_labels);
parse_mnist_images(data_dir_path + "/train-images.idx3-ubyte",
&train_images, -1.0, 1.0, 2, 2);
parse_mnist_labels(data_dir_path + "/t10k-labels.idx1-ubyte",
&test_labels);
parse_mnist_images(data_dir_path + "/t10k-images.idx3-ubyte",
&test_images, -1.0, 1.0, 2, 2);
std::cout << "start training" << std::endl;
progress_display disp(train_images.size());
timer t;
int minibatch_size = 10;
int num_epochs = 30;
nn.optimizer().alpha *= std::sqrt(minibatch_size);
// create callback
auto on_enumerate_epoch = [&](){
std::cout << t.elapsed() << "s elapsed." << std::endl;
tiny_cnn::result res = nn.test(test_images, test_labels);
std::cout << res.num_success << "/" << res.num_total << std::endl;
disp.restart(train_images.size());
t.restart();
};
auto on_enumerate_minibatch = [&](){
disp += minibatch_size;
};
// training
nn.train(train_images, train_labels, minibatch_size, num_epochs,
on_enumerate_minibatch, on_enumerate_epoch);
std::cout << "end training." << std::endl;
// test and show results
nn.test(test_images, test_labels).print_detail(std::cout);
// save networks
std::ofstream ofs("D:/Download/MNIST/LeNet-weights");
ofs << nn;
}
void construct_net(network& nn) {
// connection table [Y.Lecun, 1998 Table.1]
#define O true
#define X false
static const bool tbl[] = {
O, X, X, X, O, O, O, X, X, O, O, O, O, X, O, O,
O, O, X, X, X, O, O, O, X, X, O, O, O, O, X, O,
O, O, O, X, X, X, O, O, O, X, X, O, X, O, O, O,
X, O, O, O, X, X, O, O, O, O, X, X, O, X, O, O,
X, X, O, O, O, X, X, O, O, O, O, X, O, O, X, O,
X, X, X, O, O, O, X, X, O, O, O, O, X, O, O, O
};
#undef O
#undef X
// construct nets
nn << convolutional_layer(32, 32, 5, 1, 6) // C1, 1@32x32-in, 6@28x28-out
<< average_pooling_layer(28, 28, 6, 2) // S2, 6@28x28-in, 6@14x14-out
<< convolutional_layer(14, 14, 5, 6, 16,
connection_table(tbl, 6, 16)) // C3, 6@14x14-in, 16@10x10-in
<< average_pooling_layer(10, 10, 16, 2) // S4, 16@10x10-in, 16@5x5-out
<< convolutional_layer(5, 5, 5, 16, 120) // C5, 16@5x5-in, 120@1x1-out
<< fully_connected_layer(120, 10); // F6, 120-in, 10-out
}
void recognize(const std::string& dictionary, const std::string& filename, int target) {
network nn;
construct_net(nn);
// load nets
std::ifstream ifs(dictionary.c_str());
ifs >> nn;
// convert imagefile to vec_t
vec_t data;
convert_image(filename, -1.0, 1.0, 32, 32, data);
// recognize
auto res = nn.predict(data);
std::vector<:pair int> > scores;
// sort & print top-3
for (int i = 0; i < 10; i++)
scores.emplace_back(rescale(res[i]), i);
std::sort(scores.begin(), scores.end(), std::greater<:pair int>>());
for (int i = 0; i < 3; i++)
std::cout << scores[i].second << "," << scores[i].first << std::endl;
std::cout << "the actual digit is: " << scores[0].second << ", correct digit is: "<
// visualize outputs of each layer
//for (size_t i = 0; i < nn.depth(); i++) {
//auto out_img = nn[i]->output_to_image();
//cv::imshow("layer:" + std::to_string(i), image2mat(out_img));
//}
visualize filter shape of first convolutional layer
//auto weight = nn.at>(0).weight_to_image();
//cv::imshow("weights:", image2mat(weight));
//cv::waitKey(0);
}
// convert tiny_cnn::image to cv::Mat and resize
cv::Mat image2mat(image<>& img) {
cv::Mat ori(img.height(), img.width(), CV_8U, &img.at(0, 0));
cv::Mat resized;
cv::resize(ori, resized, cv::Size(), 3, 3, cv::INTER_AREA);
return resized;
}
void convert_image(const std::string& imagefilename,
double minv,
double maxv,
int w,
int h,
vec_t& data) {
auto img = cv::imread(imagefilename, cv::IMREAD_GRAYSCALE);
if (img.data == nullptr) return; // cannot open, or it's not an image
cv::Mat_ resized;
cv::resize(img, resized, cv::Size(w, h));
// mnist dataset is "white on black", so negate required
std::transform(resized.begin(), resized.end(), std::back_inserter(data),
[=](uint8_t c) { return (255 - c) * (maxv - minv) / 255.0 + minv; });
}
5. 编译时会提示几个错误,解决方法是:
(1)、error C4996。解决方法:将宏_SCL_SECURE_NO_WARNINGS加入到属性的预处理器定义中;
(2)、调用for_函数时,error C2668,对重载函数的调用不明教,解决方法:将for_中的第三个參数强制转化为size_t类型;
6. 执行程序,train时,执行结果例如以下图所看到的:
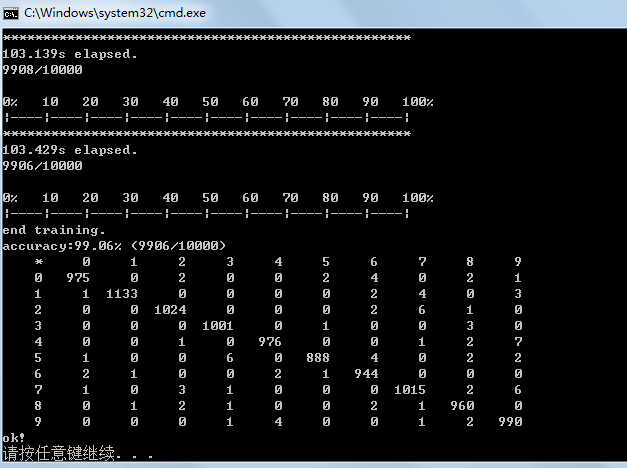
7. 对生成的model进行測试,通过绘图工具,每一个数字生成一张图像,共10幅,例如以下图:

通过导入train时生成的model。对这10张图像进行识别,识别结果例如以下图,当中6和9被误识为5和1:
















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









