








【Scene Graph and Visual Relationship论文总结】
-------------------------- 2019.4.4 更新 -----------------------------
2019_CVPR. Learning to Compose Dynamic Tree Structures for Visual Contexts
无耻的推荐下自己今年CVPR的文章把,其实performance不算高。主要是用了个动态的树结构+TreeLSTM 来给每个bounding box encode一下context信息。另外因为现在scene graph完全都是被大样本的类别主导(e.g. on, has, wearing,....),基本上只要预测对最高频的几个relationship类performance就很高,而完全不考虑低频类,所以我提出了个Mean Recall@K的metric,其实就是对50个relationship的类分别算Recall@K 然后求平均, 这样就可以看出模型学习小样本的能力,而我提出的VCTree可以大大提高学习小样本的能力(可见下图和Motif的对比)。我个人认为原因有二 (1)VCTree给每个bounding box encode了更相关的环境信息(而不是Motif的无脑BiLSTM),所以可以预测更复杂的relation,比如'covered in’(2) 我们的树结构,在training过程中一直在微调,这可以看成是网络结构(Tree LSTM结构)一直在微调,所以不容易轻易的过拟合。
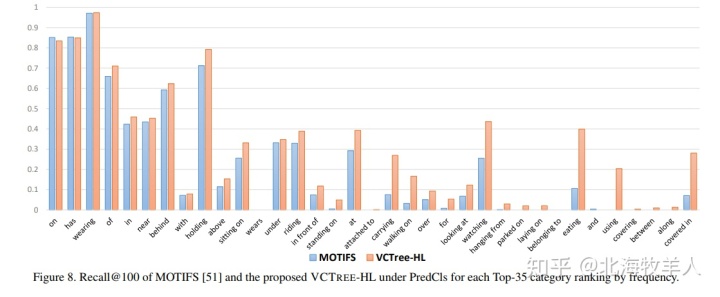
关于详细的Mean Recall@K 分析可以参考我的Supplementary Material

具体的code可以参考我放出的代码,RL部分我做的不是太好,有兴趣的人可以优化下:
KaihuaTang/VCTree- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5247
5247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









