








可以在此处找到本文随附的代码。
https://github.com/NMZivkovic/ml_optimizers_pt3_hyperparameter_optimization
到目前为止,在学习机器学习的整个过程中,涵盖了几个大主题。研究了一些回归算法,分类算法和可用于两种类型问题的算法(SVM, 决策树和随机森林)。除此之外,将toes浸入无监督的学习中,了解了如何使用这种类型的学习进行聚类,并了解了几种聚类技术。在所有这些文章中,使用Python进行“从头开始”的实现和TensorFlow, Pytorch和SciKit Learn之类的库。
 担心AI会接手您的工作吗?确保是构建它的人。与崛起的AI行业保持相关!
担心AI会接手您的工作吗?确保是构建它的人。与崛起的AI行业保持相关!
超参数是每个机器学习和深度学习算法的组成部分。与算法本身学习的标准机器学习参数(例如线性回归中的w和b或神经网络中的连接权重)不同,工程师在训练过程之前会设置超参数。它们是控制工程师完全定义的学习算法行为的外部因素。需要一些例子吗?
该学习速率是最著名的超参数之一,C在SVM也是超参数,决策树的最大深度是一个超参数等,这些可以手动由工程师进行设置。但是如果要运行多个测试,可能会很麻烦。那就是使用超参数优化的地方。这些技术的主要目标是找到给定机器学习算法的超参数,该超参数可提供在验证集上测得的最佳性能。在本教程中,探索了可以提供最佳超参数的几种技术。
数据集和先决条件
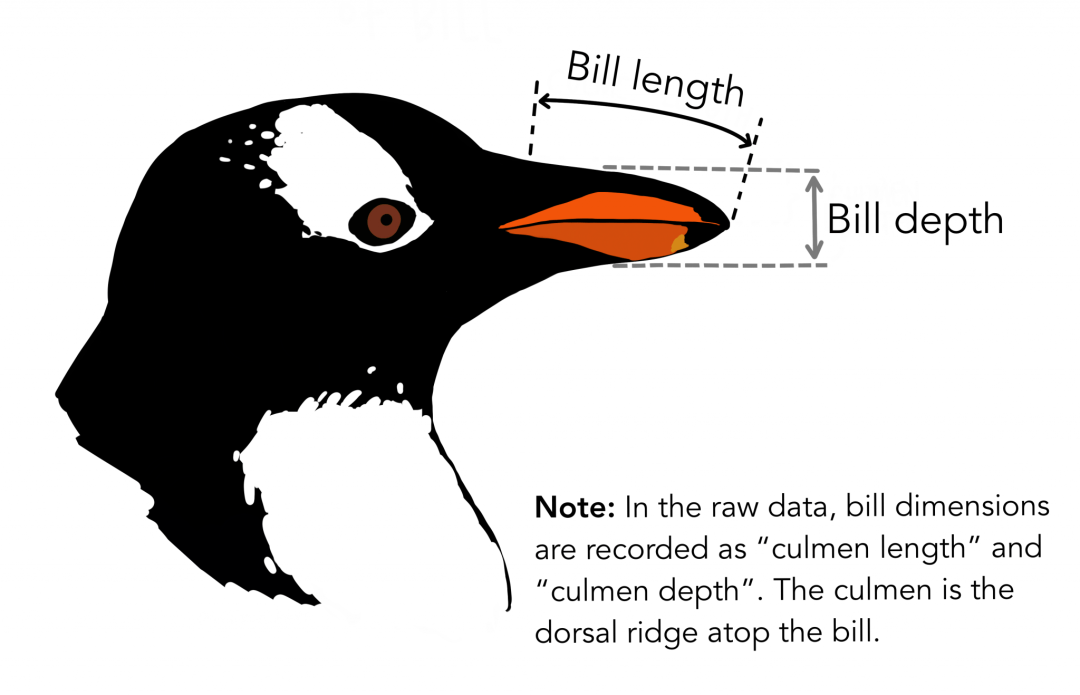
本文中使用的数据来自PalmerPenguins数据集。最近引入了此数据集,以替代著名的Iris数据集。它是由Kristen Gorman博士和南极洲帕尔默站创建的。可以在此处或通过Kaggle获取此数据集。该数据集实质上由两个数据集组成,每个数据集包含344个企鹅的数据。就像在鸢尾花数据集中一样,帕尔默群岛的3个岛屿中有3种不同的企鹅。同样,这些数据集包含每个物种的标本维度。高门是鸟嘴的上脊。在简化的企鹅数据中,顶点长度和深度被重命名为culmen_length_mm和culmen_depth_mm变量。
https://github.com/allisonhorst/palmerpenguins
由于该数据集已被标记,因此将能够验证实验结果。但是通常不是这种情况,并且对聚类算法结果的验证通常是一个困难而复杂的过程。
就本文而言,请确保已安装以下Python 库:
NumPy
SciKit学习
SciPy
Sci-Kit优化
安装完成后,请确保已导入本教程中使用的所有必要模块。
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import GridSearchCV, RandomizedSearchCVfrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestRegressorfrom scipy import statsfrom skopt import BayesSearchCVfrom skopt.space import Real, Categorical除此之外,至少要熟悉线性代数,微积分和概率的基础。
准备数据
加载并准备PalmerPenguins数据集。首先加载数据集,删除本文中未使用的功能:
data = pd.read_csv('./data/penguins_size.csv')data = data.dropna()data = data.drop(['sex', 'island', 'flipper_length_mm', 'body_mass_g'], axis=1)然后分离输入数据并对其进行缩放:
X = data.drop(['species'], axis=1)ss = StandardS 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1343
1343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









