








欢迎转载,转载请注明出处——知乎专栏“机器学习与控制论”。
“稀疏奖赏”(sparse reward)是强化学习应用中的经典难题。尤其是强化学习控制任务中,为了处理处理它,我打赌不少人都深受“奖赏塑形”等奖赏工程的折磨。
今天分享的这篇文献“Hindsight Experience Replay”(HER)正是提出一种极其简单巧妙且易实现的方法试图摆脱奖赏工程。现在,HER和模仿学习已经几乎成了机器人学习控制的标配。(OpenAI的geek们也是挺有趣的,取名和寡姐的电影一样,电影也是讲人工智能。)
知乎上有过相关内容,这里从控制的角度梳理思路和使用心得,附以简单的代码实现。
先放使用心得,后续经验还会更新:
(1)状态(state)设计需要满足文中两点前提
(2)尤其适合多目标(multi goal)任务,单目标任务很可能收益有限
(3)有些情况可能奖赏塑形效果更好、更简单
(4)主要思想并非与奖赏塑形不兼容,HER+奖赏塑形可能也有效果
(5)每个episode不要太长(本质是采样产生新goal的区间不要太长)
1.背景
强化学习(RL)直接应用,尤其应用于机器人学,往往需要精心地“奖赏塑形”(reward shaping),从而引导策略进行优化。
奖赏塑形思想倒是不难,如下面这个任务"pushing",推动方块到红点(目标)的位置。若是只是最后达到红点才给奖赏(即二元奖赏,binary reward),那大多数时候都得不到奖励。所以,可能的奖赏塑形方式是以方块到红点的距离平方的负数为奖赏函数。
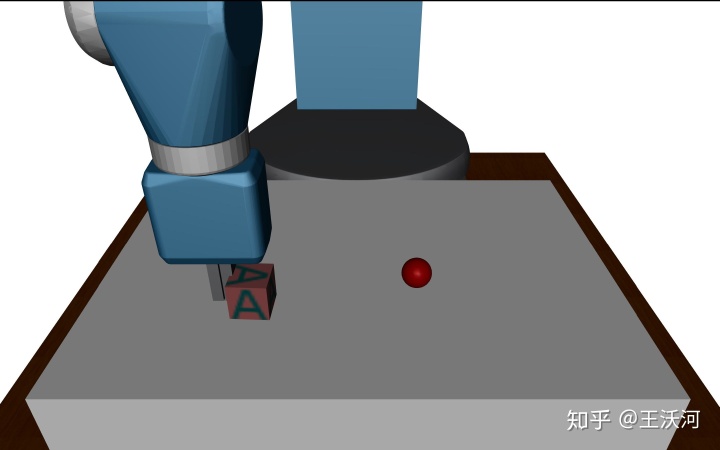
简单任务还好,但是遇到复杂任务,就既要求有RL知识又要有领域知识,设计起来非常不容易,甚至有论文在奖赏中设计了5个带权项[1]。此外,许多时候,我们更关心最后的结果,而不关心、也不太好判断中间可能的情况。
个人经验是,如果奖赏中有多个权,往往还要防止Agent进行cheating的情况,而且许多时候,我们更关心最后的结果,而不关心、也不太清楚中间可能的情况。因此,我们需要简单的奖赏设计,比如说,最好就是原来RL朴素的二元奖赏(达到目标则有,否则无)。
怎么做呢?从错误中学习。拿足球射门举例,如果你一次射门射偏到了球门右边,朴素的RL算法可能认为这就是没有奖赏,学到很少。而人的话却可以从这次失败中知道,这个射偏的落点,是我站在现在这个位置,用这样的脚法能射达的。夸张点说,如果门右挪一点就好了。
这种思想更有效的场景是控制、规划中常见的多目标任务,其中RL的建模方式叫做universal policy,最早来源于Universal Value Function Approximators[2](UVFA),此时输入给Agent的不仅仅有状态,还有当前任务指定的目标(二者进行concatenate操作)。比如下面的情况,Agent被要求射第3个门,但是若射偏到了第2个门,虽然没达到当前目标,但是达到了“射中第2个门”的目标!这就是所谓的hindsight(后见之明),所以这个经验完全可以复用起来,采样效率就增大了,而且可能可以用二元奖赏。
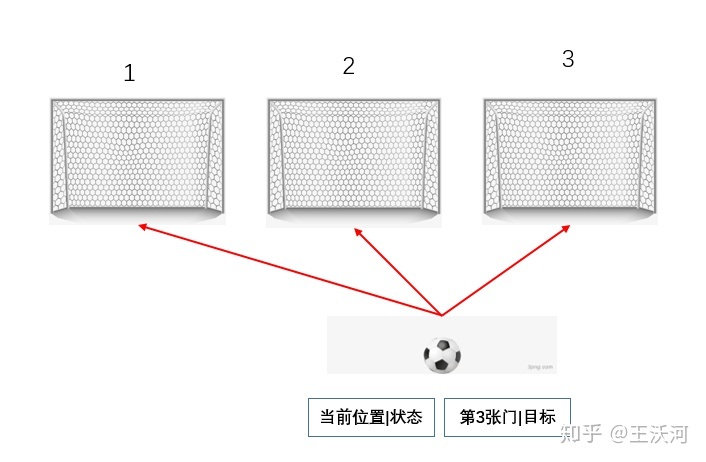
HER的思想就是如此,回放每个episode,用新的目标(如已经达到的状态)去替换掉经验中原本想要去达到的目标。HER的适用范围也就很明显了&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3740
3740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









