







 文章探讨了分层强化学习(HRL),一种结合深度学习和分层控制的算法,通过分解问题解决复杂性,提高样本效率,应对大规模状态或动作空间,以及增强泛化能力。层次结构、高层策略和低层策略是其关键组成部分。
文章探讨了分层强化学习(HRL),一种结合深度学习和分层控制的算法,通过分解问题解决复杂性,提高样本效率,应对大规模状态或动作空间,以及增强泛化能力。层次结构、高层策略和低层策略是其关键组成部分。
hierarchical deep reinforcement learning(HRL, 分层强化学习):是一种结合了深度强化学习和分层控制思想的算法。在传统的强化学习中,智能体通常需要学习如何相似复杂的、高维的状态空间中直接映射出最佳的动作,然而,许多显示世界的问题,这种复杂性可能会导致学习过程非常缓慢,甚至是不可能的,HRL通常是将问题分解成更小、更易于管理的子任务来解决这个问题。
在 HRL 中,智能体的行为被组织成一系列的层次结构,其中每个层次都负责学习解决特定类型的子问题。这些层次可以是预定义的,也可以是自动学习的。高层策略负责选择哪个子任务应该被执行,而低层策略则负责执行这些子任务的具体动作。
HRL旨在通过分解学习的特定部分来减轻学习的复杂性,与分层强化学习的优势相比,强化学习的主要弱点可以被分解如下:
1、样本效率低:数据生成常常是瓶颈,数据效率较低。
2、扩展:将传统的RL方法应用于具有大的动作或者状态空间的问题是不可行的(维数灾难)。
3、泛化:不一定能够成功迁移到新的(甚至相似的)环境中
4、抽象
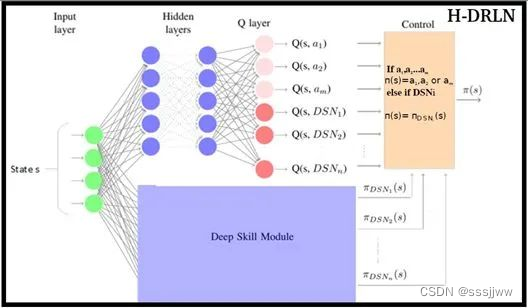
分层强化学习
关键组成部分:
1、层次结构:由多个层级组成,每个层级都有自己的策略和奖励函数,高层策略负责设置目标或任务,而低层策略则关注如何实现这些目标。
2、高层策略:负责在抽象层面上做出决策,这些决策通常指导低层策略的行为,高层策略关注的是长期目标和任务规划。
3、低层策略:执行高层策略制定的指令,它们关注的是具体行动和短期目标
4、奖励信号:通常每个层级都有自己的奖励型号,这些信号反映了该层级策略成功实现其目标的程度。

















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









