






随着3D渲染场景规模越来越复杂,单线程渲染架构在满足业务性能要求时已经捉襟见肘,因此,多线程渲染显得愈发重要。本文首先介绍了新一代图形渲染接口Metal、Vulkan,以及它们的多线程渲染特性,然后描述了一种优雅的渲染架构,可以解决渲染管线开发中的诸多困扰,并且基于此实现了多线程渲染,极大的提升了3D渲染效率。
一、背景
Metal[1]、Vulkan[2]是分别由苹果(Apple)和科纳斯组织(Khronos Group)面向新一代图形处理器(GPU)设计的图形API。在移动平台上,Metal应用于iOS系列产品,Vulkan主要由Android系统提供。Metal、Vulkan作为新一台的图形API,相较于OpenGL(ES),设计了更底层、更细粒度的接口,提供了全新的状态管理,改善了错误处理机制,增加了新的特性支持。
使用新一代的图形渲染接口,可以全方位的增强3D引擎的渲染能力。比如使用状态缓存机制,可以降低CPU负载;利用ray tracing的三角面求交能力,可以带来全新的全局光照方案(Global Illumination);自定义显存管理器,可以提高显存利用率……本文受限于篇幅,无法从各个角度逐一而述,这里主要讨论新一代图形渲染接口带来的多线程渲染能力,以及如何围绕它设计一种渲染架构。
二、多线程渲染
通常一个单线程渲染引擎会面临着硬件资源浪费的问题。如下图1所示,一个CPU线程需要先负责逻辑更新,然后反复更新渲染状态,提交渲染指令。这种架构同时造成了CPU和GPU闲置。对CPU而言,完全可以将这些任务分配给多个CPU线程并行执行;就GPU而言,CPU线程在进行逻辑更新和提交渲染指令时,GPU处于闲置状态,浪费了算力。

图1 单线程渲染面临的问题
作为开发者,在不考虑功耗、散热、资源分配等现实限制条件下,通常希望CPU、GPU永远处于满负荷状态。为了达到满负荷的状态,每个线程通常需要具备三个基本能力:
· 资源创建管理
· Pipeline创建管理
· Command Buffer创建管理(提交Draw Calls)
如果使用OpenGL(ES),引擎开发者将面临的最大问题是,OpenGL(ES)API不能跨线程调用,它们的调用只能局限在GL Context创建线程内,这也就意味着OpenGL(ES)无法原生支持多线程渲染。为了达到OpenGL(ES)多线程渲染的目的,开发者需要手动实现Command Buffer,记录图形调用指令,考虑数据线程安全问题,解决资源同步可能带来的性能损耗,不胜其烦。而这些问题,已经在metal、vulkan设计者考虑之内,新一代的图形API天然支持跨线程调用,让多线程渲染变得更具有实践可行性。如下图2所示,使用Vulkan时,Thread 1、2、3独自组织更新工作,写入Command Buffer,最后提交到Thread 4中的Command Queue中。
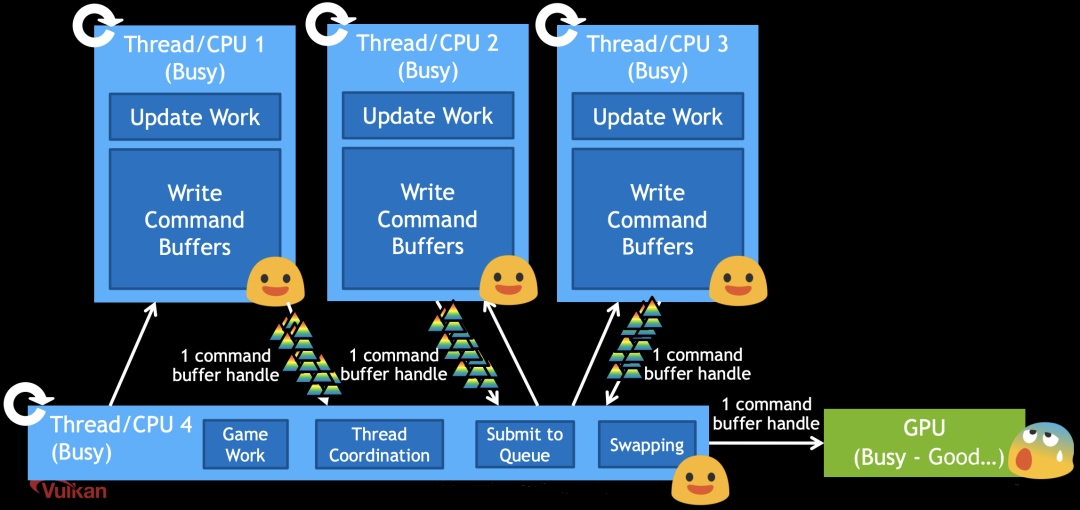
图2 Vulkan多线程渲染架构
三、小结与转进
从上面的描述可以看到,新一代的图形API为了提高硬件资源利用率,进行了全新的设计,似乎多线程渲染唾手可得,渲染效率即将走向巅峰。然而,如果到此为止,急冲冲拿着多线程渲染API试图提升渲染效率,进行实践时,才会发现脑子里一团乱,无从下手。毕竟上面只是简单描述了图形API的基本能力,并没有提供任何实际可行的方案。就好比做菜,有一样的原料,做出来的菜品可能千差万别。不过下面不准备直接描述一种多线程渲染方案,先转进到一个相关问题—Render Graph。
四、Render Graph
Render Graph在有些文献也称之为Frame Graph,这里使用Render Graph一词,主要是考虑到与Shader Graph[3]一词呼应。附录对Shader Graph有一个简单描述。
Render Graph是基于数据驱动的理念,将行为与数据解耦。只不过是Shader Graph处理shading相关问题,Render Graph处理rendering相关问题。下面先了解下,渲染器开发时遇到的一些痛点问题,然后了解下Render Graph如何解决这些痛点。
4.1 网状结构的渲染流程
从图3可以看到,一个常见的渲染系统,包含了地形、粒子、全局光照、反射、PBR、后处理、天空……各种模块,而这些模块还具有相互依赖关系,形成网状结构,实际开发中会导致一系列令人沮丧的问题,简单举例:
· 记忆难度大。即使渲染系统由一个专人负责,过了一段时间之后,也很难对整个渲染流程记得分毫不差。
· 不易了解渲染流程全貌。阅读线性结构的代码,来理解图状结构的流程,非常困难。
· 日常维护难。为了支持新的渲染特性,经常需要向已有的流程中添加新的模块,新的模块意味着需要打断与重建各模块之间的联系,稍有不慎,就会出错。
· 资源管理困难。比如motion blur和Temporal Anti-Alias都需要使用velocity buffer,一旦渲染流程中各种开关过多,那么确定velocity buffer创建、销毁时机就变得异常困难。如果采用粗暴的设计方式,就会变成渲染开始阶段创建velocity buffer,直到渲染生命周期结束才销毁velocity buffer,占用了紧缺的GPU资源。更加糟糕的是,即使精妙的设计了velocity buffer创建和销毁时间,后续渲染流程稍有改动,这个所谓的精妙设计反而变成了错误设计,作茧自缚,心智负担极重。
· 模块管理困难。比如 shadow map模块,如果某个场景中不需要使用阴影,那么shadow map模块就不应该执行。为了达到这种开关效果,往往实际中建立一系列的if分支判断,决定流程是否执行。但这种带有“土味”的方法,会使渲染流程更难理解,代码bug极容易发生。
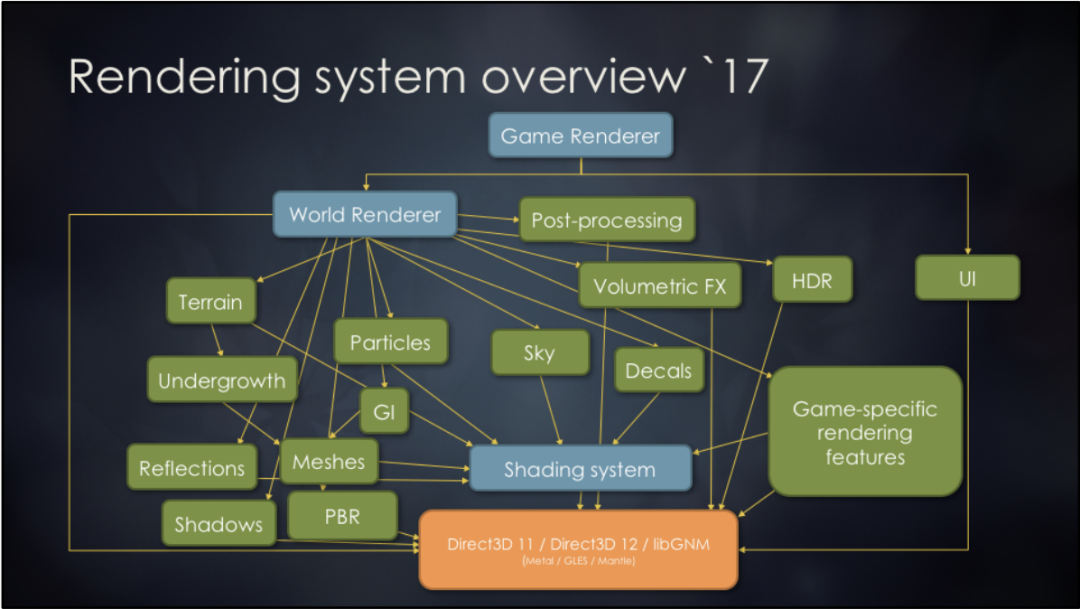
图3 Frostbite渲染系统
上面一系列令人头疼的问题,实践过的人会明白,痛不欲生,Render Graph应运而生。
4.2 Render Graph应用在延迟渲染上
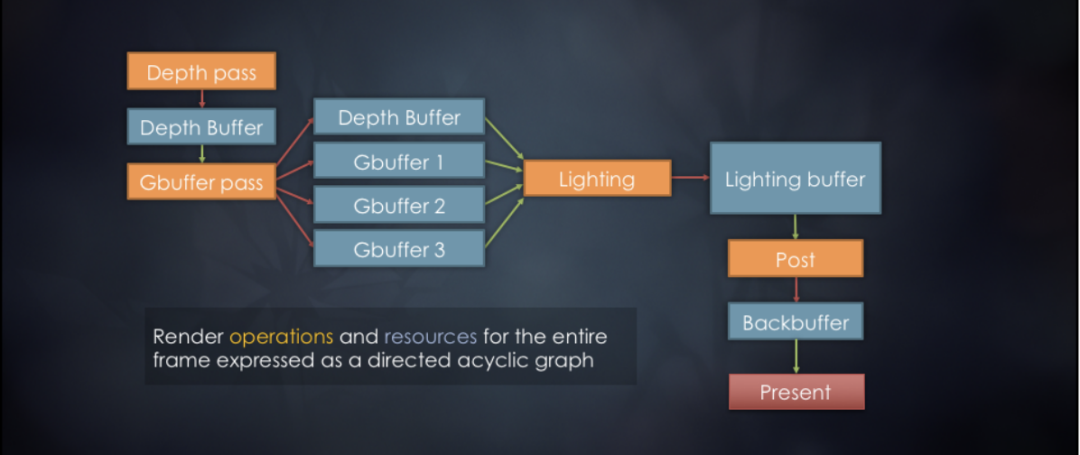
图4 延迟渲染流程使用Render Graph描述
要讲清楚什么是Render Graph,最好的方式是直接看一个Render Graph例子。如上图4所示,它描述的就是一个延迟渲染流程的Render Graph,从中可以看到橙色的方框代表的是行为(operation),蓝色的方框代表的是资源(resource)。在实践中,引擎中使用一个基类RenderGraphRenderPass来定义行为,使用一个基类RenderGraphResource来定义资源。这样在实现RenderGraph时,需要经历三个阶段:
· 构建阶段。在此阶段中需定义所有RenderGraphRenderPass、并为其定义输入输出RenderGraphResource。资源类型分为两种,permanent和transient。Permanent一般是Render Graph的外界资源,比如back color buffer之类。Transient资源可根据读写属性分为三种,只读资源,可写资源、内部创建资源。
· 编译阶段。在这个阶段,Render Graph可以自动的根据配置剔除无效行为和数据,并且自动的计算资源生命周期。
· 运行阶段。执行代码,完成整个渲染流程。
有了Render Graph,数据和行为得到解耦,加上清晰的数据流,很好的解决了4.1节提到的诸多混乱。比如,如果需要在上面的延迟渲染流程中添加Screen Space Ambient Occlusion(SSAO),只需要将全部的精力集中在SSAO的算法实现上,实现一个RenderGraphSSAORenderPass,然后定义好输入输出,不用关心现有的渲染流程如何复杂。然后在Render Graph中设置好AO相关节点,连接好相应的数据流,整个过程就完成了。
4.3 复用延迟渲染渲染流程
在4.2小节中定义了一个延迟渲染的Render Graph,在本节可以看看如何复用这个Render Graph来实现新的功能。从图5可以看到,对于延迟渲染的绝大部分流程,不必做改变,只需要把Lighting Buffer拷贝到cube map之中,然后进行卷积,就可以得到反射球。
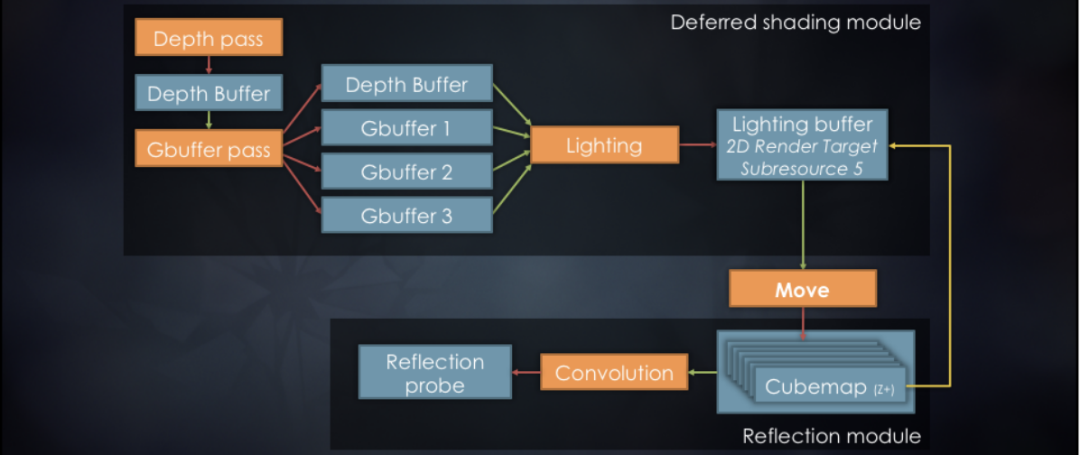
图5 复用延迟渲染生成反射球
4.4 剔除无效数据和行为
在4.2小节中提到了, RenderGraph第二阶段是编译阶段,会进行无效行为和数据剔除。如下图6所示,这里本来Gbuffer是作为Lighting render pass的输入,现在改为Debug View render pass的输入,然后拷贝到Final target上,就可以显示渲染中间变量,用来进行调试。此时Lighting render pass及其相关资源和render pass就变成了无效资源,可以直接在编译阶段剔除。
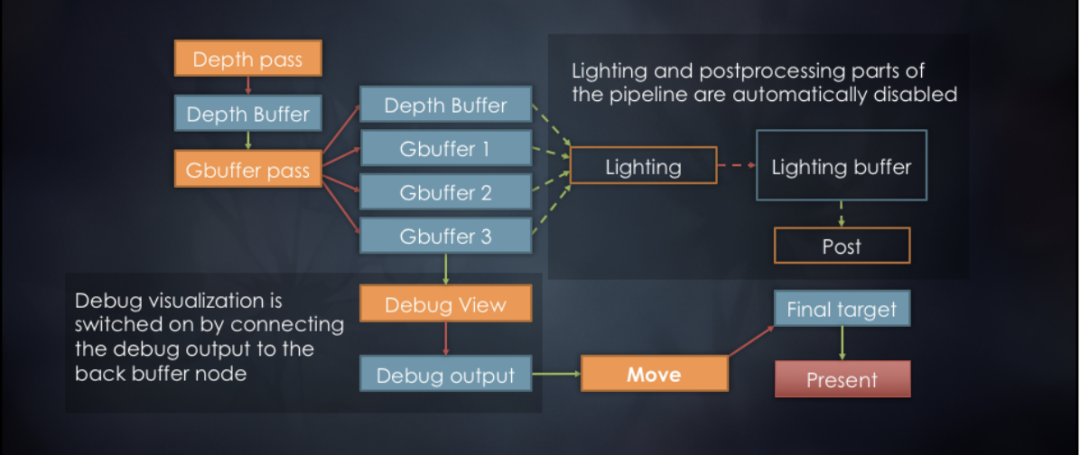
图6 剔除Lighting及其相关资源
4.5 异步执行的Compute Shader
除了常见的渲染单元,现代图形架构中还存在着不可忽视的计算单元(Compute Shader)。Compute shader相较于渲染单元,将精力集中在计算方面,类似于光栅化这种渲染单元中的标准步骤,在计算单元中不复存在。可以简单的认为,在执行通用计算时,compute shader的效率优于fragment shader。因此,一个完整的渲染架构不可回避通用计算模块,可以定义一个基类RenderGraphComputePass来描述这个功能。
既然同时有了RenderPass和ComputePass,就需要考虑RenderPass和ComputePass是否串行执行。考虑到RenderPass和ComputePass都涉及大量IO访问和图形API提交,GPU有可能处于闲置状态,因此将RenderPass和ComputePass进行并行设计。如图7所示,因为SSAO功能考虑使用compute shader实现,那么SSAO相关功能放到另外一个异步队列中。因为异步设计,同时会造成相应资源的生命周期延长,增加了整体显存消耗。
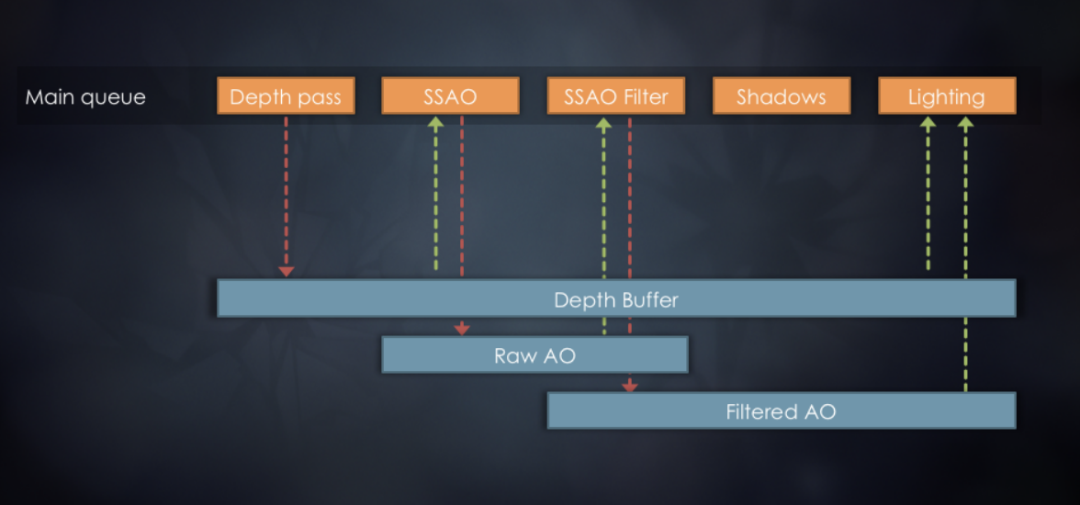
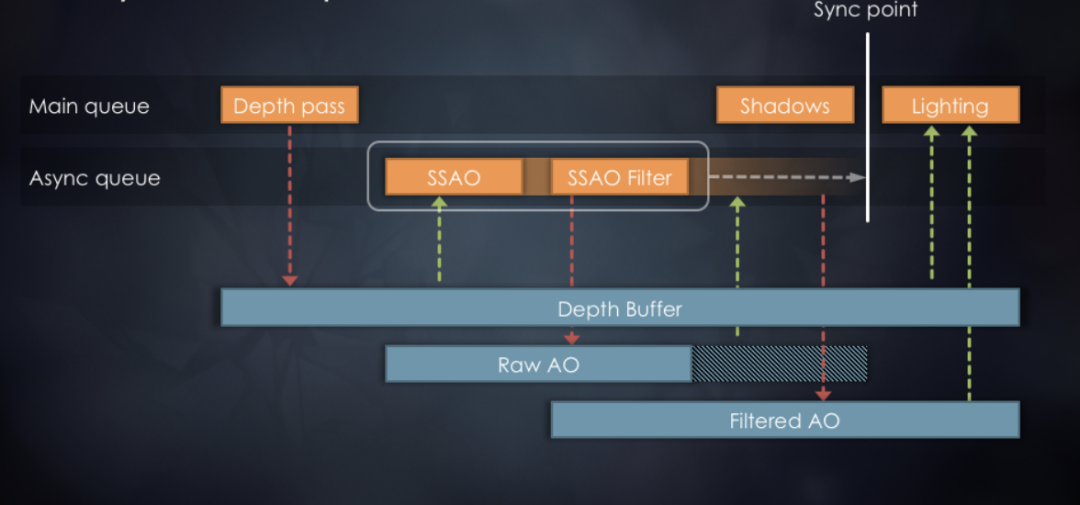
图7 上部和下部分别描述了SSAO的同步和异步设计
4.6 小结
基于Render Graph的渲染管线架构,数据流清晰,维护容易,高度可配置,甚至可以做到为每个渲染场景定义一套独特的渲染管线,最大化的利用硬件效率。
那么这一切和本文提到的多线程渲染有什么关联?
五、基于多线程渲染的Render Graph
站在更高角度抽象的去看Render Graph, Render Graph是一个有向无环图。如图8所示,执行C依赖F的完成,但D并不依赖F,也就是C、F必须串行执行,而D、F可以并行运算。因此只要对这个有向无环图进行拓扑排序,系统便可以自动判定任务并行性,这就是多线程渲染的切入点。如果具象的理解这个问题,可以认为任务D是Gbuffer pass,而任务F是shadow pass,那么D和F不存在相互依赖关系,可以并行计算。
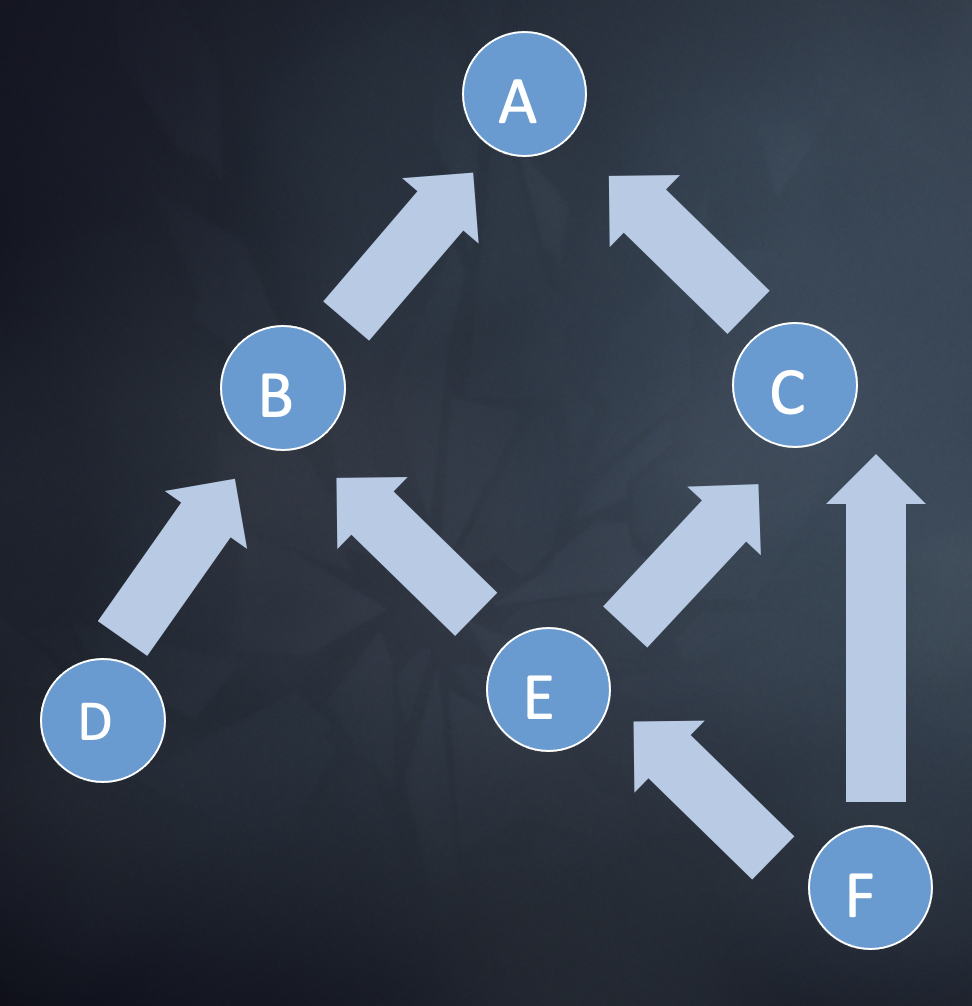
图8 Render Graph的抽象形式
这里设计了一种拓扑排序方法:
1. 统计各节点出度和入度。D、F入度为0,具备并行性,出度分别为1、2。E的入度为1。
2. 执行入度为0的节点。执行D、F,F任务结束后,将它指向的节点入度减去1,这样E的入度变为0。
3. 反复执行第二步,直到整个Graph执行完成。
经过上面的操作,整个Render Graph变成线性执行关系,最后提交给常规的并行系统执行,如图9所示。
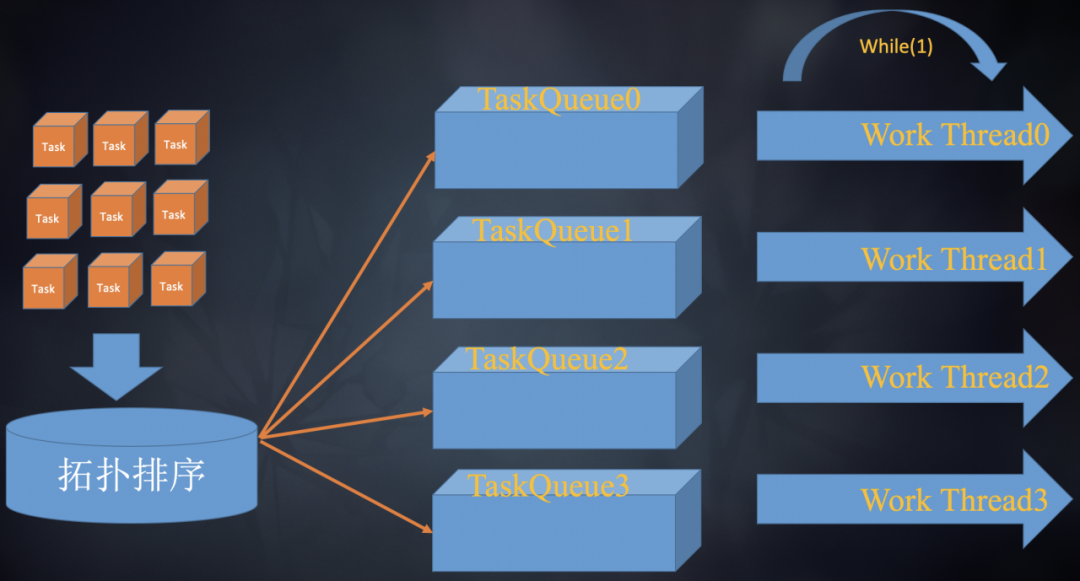
图9 拓扑排序Render Graph tasks并执行
六、总结
本文首先介绍了Metal、Vulkan的多线程能力,然后使用Render Graph作为渲染架构,最后利用了一种简单的拓扑排序方法,将有向无环图展开为线型执行结构,使Render Graph天然支持并发的特性得到发挥,能够充分利用新一代图形API的多线程渲染能力。
本文受限于篇幅,主要探讨新一代图形API的多线程渲染能力,其它方面来不及深究。此外,CPU逻辑的并行能力也没有来得及阐述,希望未来有机会进一步进行补充。
作者简介
饶超,2018年加入快手,图形引擎开发工程师,负责特效图形引擎设计与开发。
附录
Shader Graph主要是根据数据驱动的理念,将行为(shading)和数据解耦。下面图10展示了Unreal Engine 4 Shader Graph的UI界面。UI最右边面板含有Base color、Metallic、Roughness、Opacity等等slot,其余的部分为这些slot提供数据。这种设计,引擎内部可以不用关心data provider(整个Shader Graph就是一个data provider)具体逻辑,直接拿到这些数据,进行进一步的shading。Shader Graph具体实现本文不做深入探讨,它与多线程渲染并没有太多的关联。
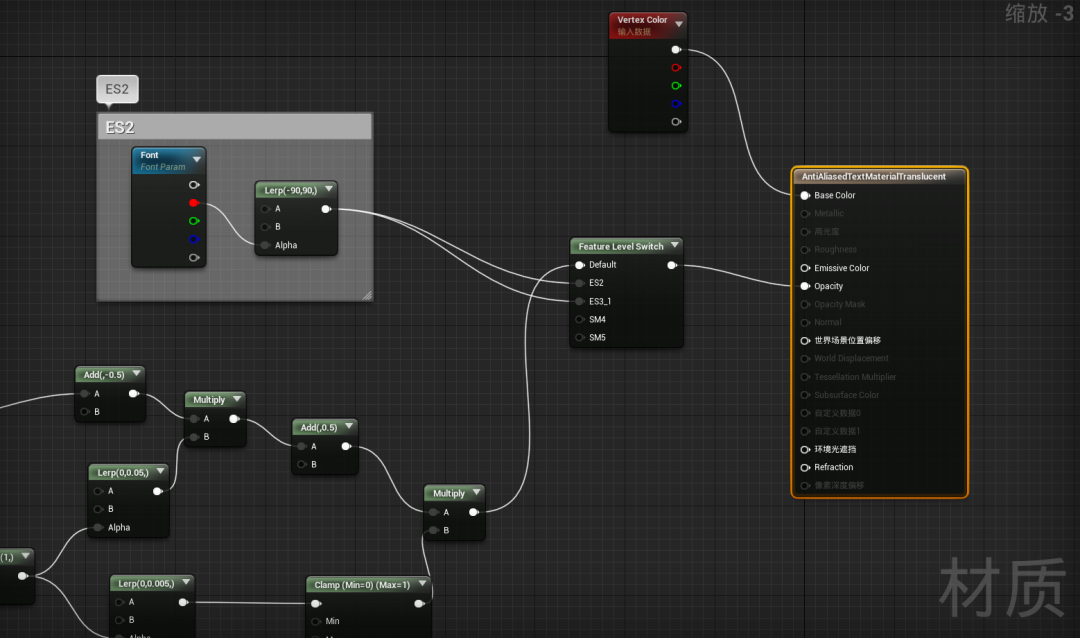
图10 Unreal Engine 4 Shader Graph
引用
[1] Metal Programming Guide:https://developer.apple.com/library/archive/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Introduction/Introduction.html
[2] Vulkan:https://www.khronos.org/vulkan/
[3] Unity3D shader graph:https://unity.com/shader-graph
快手Y-tech介绍Y-tech团队是快手公司在人工智能领域的探索者和先行者,致力于计算机视觉、计算机图形学、机器学习、AR/VR等领域的技术创新和业务落地,不断探索新技术与新用户体验的最佳结合点。目前Y-tech在北京、深圳、杭州、Seattle、Palo Alto有研发团队,大部分成员来自于国际知名公司和大学。如果你对我们做的事情很感兴趣,希望一起做酷炫的东西,创造更大的价值,请联系我们:ytechservice@kuaishou.com。














 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









