







无论以任何形式本篇文章内容,请注明来自leonnwei的csdn blog
在第一章节中我们讨论了图形API的基本数据结构和图形指令的提交机制,在指令的生成,提交,执行过程中,在复杂而又高度并行的GPU管线中,必然存在着指令和数据的同步机制,以保证逻辑上的正确执行和访问顺序,这是现代API编程的基石和难点,本章节我们先仔细讨论同步这个问题。
此外GPU上的一切数据和对象都存在于显存之中,而GPU上内存的分配,访问,释放,在高级API出现后已经不再是一个黑盒,如同CPU内存一样可以被开发者显示去使用,在进一步认识API中的对象之前,我们要先了解下显存如何使用。
三、同步
3.1 图形指令和顺序
我们透过API,将数据从CPU一侧发送到Device(GPU)上,从CPU一侧来说,数据的执行和访问在顺序上相对是可控的,但是GPU上则是一个高度并发的环境,很多时候我们并不能保证这个“顺序”。我们需要明确事情要按照顺序发生,就是“同步”,由于完全CPU一侧的同步都是C++编程规范中解决的问题,所以图形API这里特别关注的就是涉及到Device(GPU)一侧的同步。
我们先谈论这里面涉及到的几种顺序。
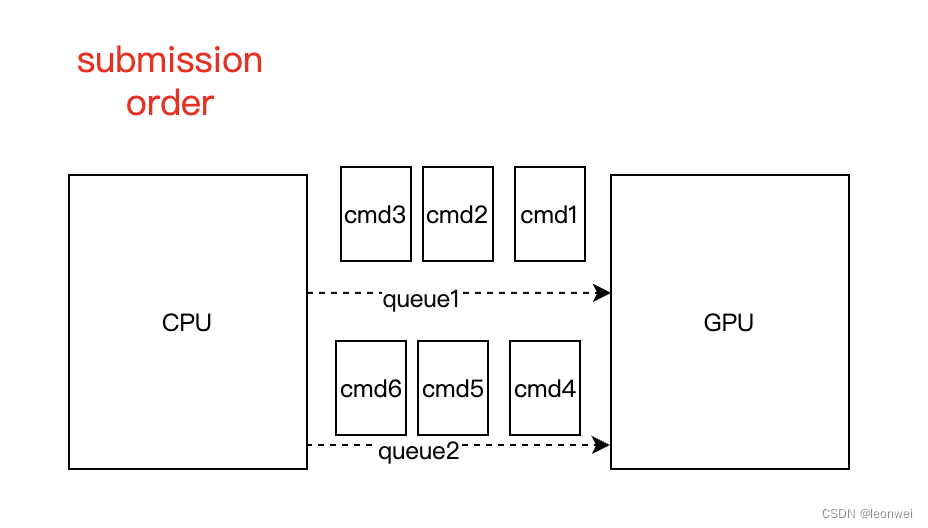
3.1.1 提交顺序 submission order
这是你在代码中最开始调用API进行指令录制和提交的顺序,来源来自于CPU一侧,如下图,我们可以说对于queue1来说,1,2,3指令存在提交顺序,对于queue2来说,4,5,6指令存在提交顺序(当然1和4可能是并行提交,需要依靠CPU一侧的同步机制保证提交顺序)
提交顺序仅仅在cpu一侧保证,取决于哪个指令先被submit,处于同一批submit数据中的指令取决于哪个指令先被record。
一旦图形指令被GPU接受就会对进入GPU的处理范围,这个时候提交顺序已经不能起太多作用了,GPU可能会按照自己的策略最优化的处理它接收到的指令。
cmd和cmd之间不一定保证提交顺序,同一个cmd 产生的不同primitive不一定保证顺序,同一个 产生的PS也不一定保证顺序。
但是这里对于屏幕上的的同一个ps的同一个sample来说,确存在一个和提交顺序相关的顺序,它叫光栅化顺序,这是个很重要的顺序
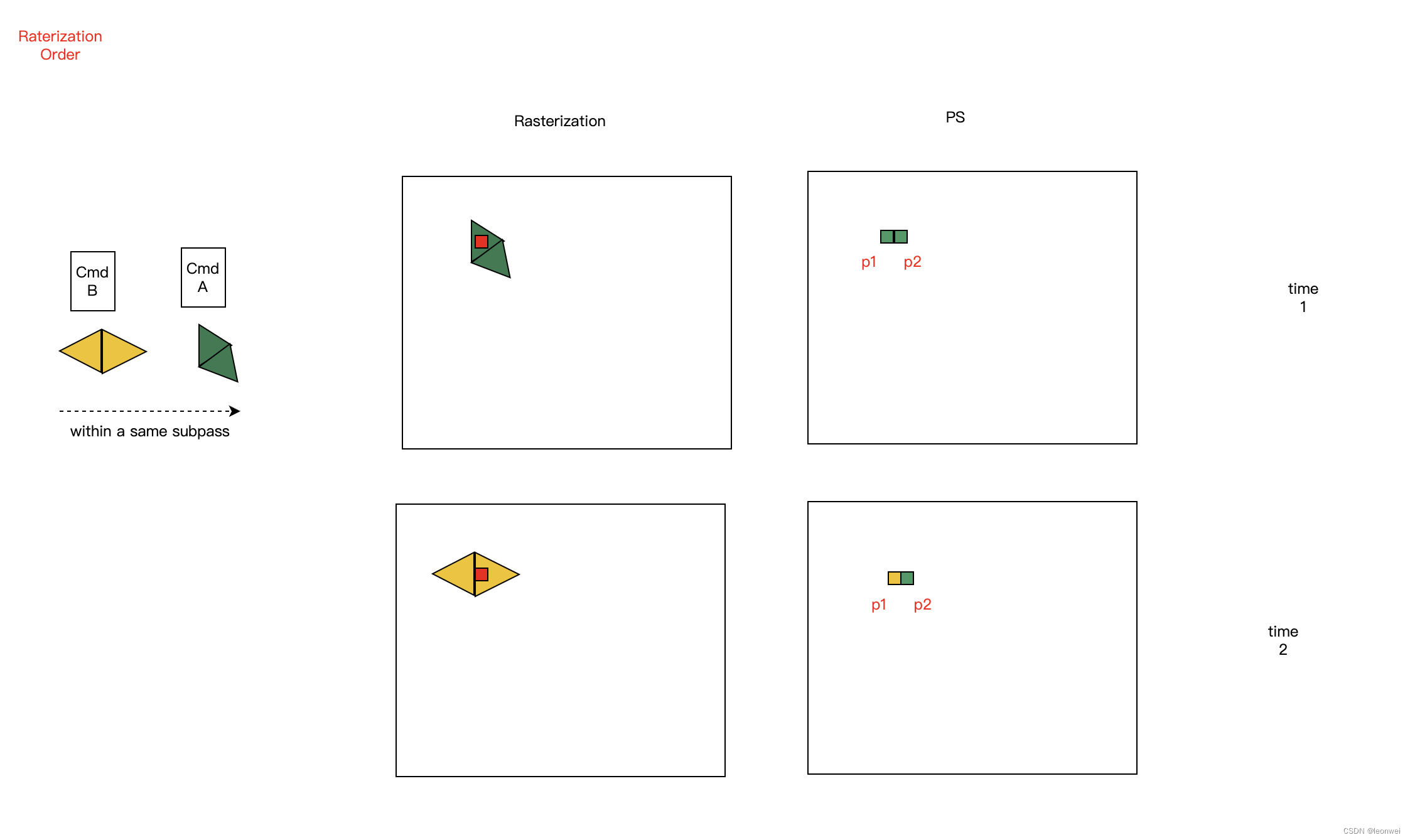
3.1.2 光栅化顺序 rasterization order
它是指对于同一个sample来说,在同样一个subpass之内,对于以下操作:
- Fragment operations。(PS)
- Blending,logic operations, color writes(注意不包括depth write).
保证按照如下顺序执行:
- 首先按照cmd的提交顺序
- 同一个cmd之内,按照instance索引从小到达的顺序,同一个instance之内,按照IB访问从小到大的顺序。
如下图,p1这个sample点会经历从time1时刻点的绿色到time2点的黄色,但是不代表time2点,它隔壁的p2点也会是黄色,这个顺序只对于同一个sample点(不是同一个pixel),同一个subpass内来说,并且这个顺序不保证PS过程中产生的对其他内存的读写顺序。
光栅化顺序是一个重要的顺序,它内在保证了ps着色的顺序,并且使得cpu的提交顺序对单个sample点的着色顺序产生影响。
光栅化顺序也几乎是GPU唯一能够内在帮我们保证的顺序了!
光栅化顺序可以抽象看作成:
只是在PS和之后的渲染管线阶段,基于单个sample指令执行和color attachment的写入顺序
但是,GPU上的管线状态不只有PS,比如我们有时候要保证VS的顺序,且有时要保证基于整个pixel甚至基于整个Framebuffer的写入顺序,他们不是局限在单个sample内,并且GPU上还有出color写入外的很多其他的内存读写操作,所有其余这些顺序都需要我们自己去保证,其余的这些顺序主要分成两类,在某种管线阶段区间指令的执行顺序,以及内存的访问顺序。
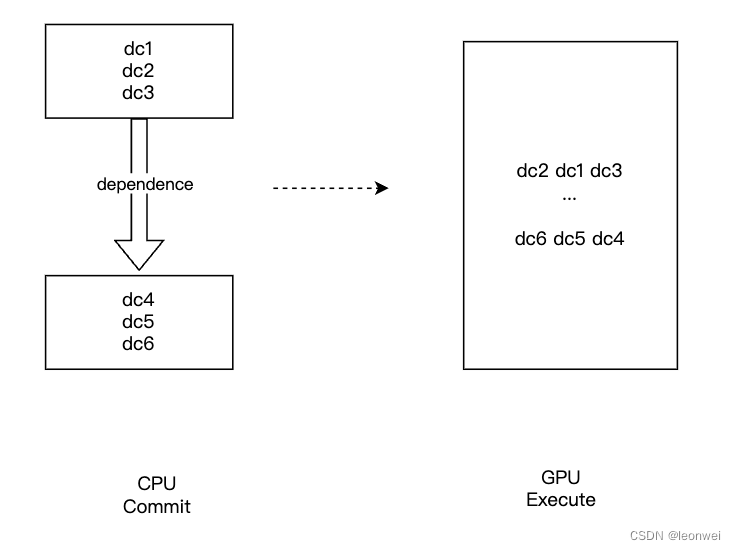
3.1.3 指令执行顺序 execution order
执行顺序的严格定义是:对于两个操作集合A和B,在特定的gpu管线阶段,保证A中的所有操作早于B中的任何操作完成。
例如定义了两组drawcall的执行顺序依赖,则后面一组drawcall的任何一个都要晚与前面一组drawcall的任何一个,但是这两组drawcall内部,哪个drawcall先被执行则不保证顺序。
如果不牵扯到内存的访问,只考虑简单的ps着色,那么其实不需要自己保证这种指令执行顺序,因为内在的光栅化顺序已经可以保证对特性pixel,color的着色按照提交顺序来。但是一旦牵扯到内存访问,牵扯到非color的写入,牵扯到非单个pixel的作用域,就不一样了,例如前面的drawcall写入一个buffer,后面的drawcall读取一个buffer,就不得不加入执行顺序的同步,因为这个buffer的读写和color rt的写入可能没有什么关系。
此外指令的执行会触发内存的访问,而执行顺序也不能等同于内存访问顺序。
例如相继利用两个API在一个RT上绘制两个个三角形,第一个绘制API发生后,不意味着RT的内存上就被马上写入完数据。甚至很有可能两个drawcall是依次发生的,但是后一个drawcall的数据在pixel A上反而先与第一个drawcall在pixel B上的写入。
所以还要考虑内存的访问顺序
3.1.4 内存访问顺序 memory access order
GPU上内存访问主要为读和写两种,只有写入的发生才引入依赖问题。
在给内存访问顺序下定义之前,先明确下内存写入主要有以下几种状态:
- availbility: 写入完成,可以被继续写入
- visibility:可以被其他人读
- domain:例如在Host上的写入操作对于Device来说是availbility的
avaibility和visibility是两种不同的状态,availbility之后你可以继续写入,visibility之后才可以继续被读。
所以内存访问顺序的严格定义是:对于两个操作集合A和B,在GPU的某个管线区间下,对某个内存M,B对A的内存访问依赖的严格定义包括两条:
- 对M的任何内存写入在A中是availble的(写入完成)
- M对于B是visible的(可以被读)
对于两个操作,如果是只读和先读后写只需要保证执行顺序即可,对于先写后读和同时写的情况一般除了执行顺序之外,都还要保证内存访问顺序。
3.1.5 图像的可操作状态
GPU上很重要的一类内存就是图像,对于图像的内存访问来说,除了需要关心它的顺序和同步关系之外,还需要额外关注它当前的可访问状态。
这是因为贴图在显存上的状态比较复杂,它的数据可能同时存在与tile mem上主mem上,它可能正在被读,也可能正在被写,(详细见本文第一章中的“RT读写操作”)。
所以在访问贴图内存前,还需要告诉API我们想要对贴图做的操作具体是什么,以便硬件可以做到:
- 为这些贴图资源做好一些准备,例如去采样一张RT,首先要保证它的内容全部从tile resolve到了主存
- 贴图的存储格式,位置等有多种选择,在不同的内存访问下,最佳的选择可能是不同的,如果硬件知道我们要对这个贴图做什么,他可以选择更好的存放策略。
因此,对贴图内存发生同步的时候,一般还要额外设置它的这种“当前可操作状态"。
不同平台上对这种“当前可操作状态"的定义和设置是不同的,这也是vulkan上几个复杂的概念之一。
Vulkan
在Vulkan上Image的这种“当前可操作状态"有明确的数据结构定义,叫image layout。
Vulkan定义了以下几种主要的layout:
VK_IMAGE_LAYOUT_UNDEFINED = 0,
VK_IMAGE_LAYOUT_GENERAL = 1,
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL = 2,
VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL = 3,
VK_IMAGE_LAYOUT_DEPTH_STENCIL_READ_ONLY_OPTIMAL = 4,
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL = 5,
VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL = 6,
VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL = 7,
VK_IMAGE_LAYOUT_PREINITIALIZED = 8,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_STENCIL_ATTACHMENT_OPTIMAL = 1000117000,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_STENCIL_READ_ONLY_OPTIMAL = 1000117001,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL = 1000241000,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_OPTIMAL = 1000241001,
VK_IMAGE_LAYOUT_STENCIL_ATTACHMENT_OPTIMAL = 1000241002,
VK_IMAGE_LAYOUT_STENCIL_READ_ONLY_OPTIMAL = 1000241003,
VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL = 1000314000,
VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL = 1000314001,
一个Image在某一时刻一定是处于其中的某个Layout状态,并且可以通过API进行Layout的设置(也叫layout的transition)。
上面的layout可以大致分为以下几种,其不同的功用是:
初始化的layout
一张Image创建的时候只能通过创建参数设置指定它为PREINITIALIZED或者UNDEFINED,并且没有任何其他layout可以转变成这两种状态。PREINITIALIZED可以被Host访问,UNDEFINED不可以。
General layout
General是支持任何情况的访问,理论上你可以把Image的layout设置成General后不用在管它,但是这显然是性能不优化的,但是对于Host访问,Compute Shader访问的情形一般都只能用General。
Transfer Layout
Transfer_Source和Transfer_Dst用于贴图的数据拷贝
用作RT和被图形管线读取,
这里面设计三种layout :Attachment,Read,Shader_read,容易弄混,所以放一起看
首先Attachment和Read(VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL)两种layout都可以做RT,但是区别在于
Attachment:可以作为attachment写,可以作为attachment读(depth test, blend)
Read:不可以作为attachment 写,可以做除了attachement读(depth test, blend)之外的其他内存读操作(采样和Input Attachment的Read)
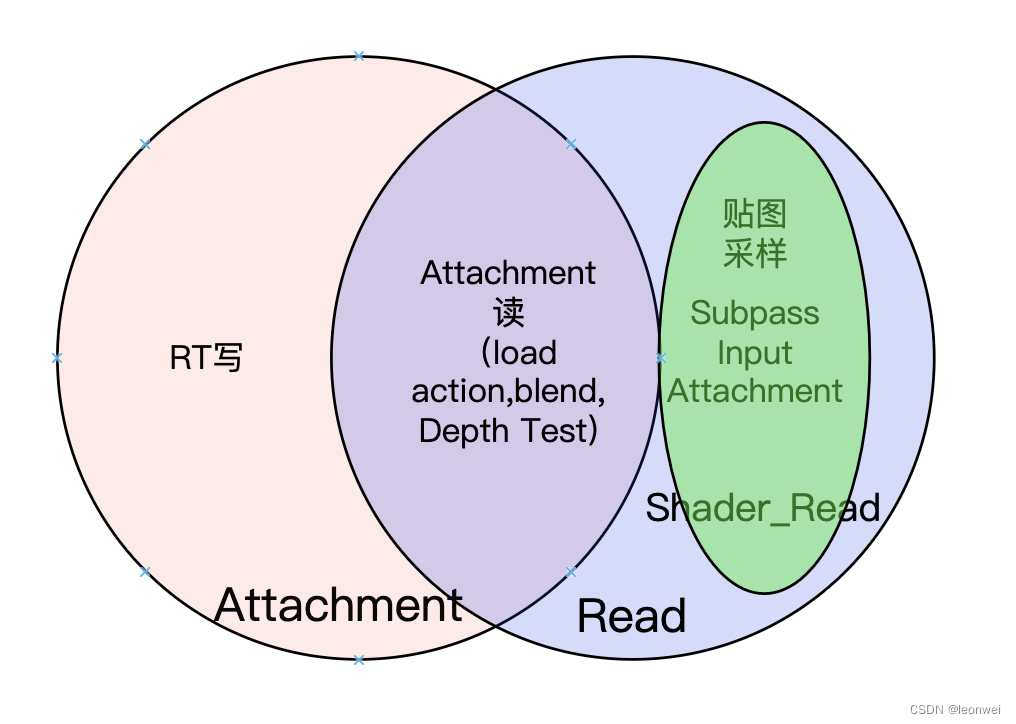
如果贴图只需要作为Attachement读,如一张深度图在当前pass不会写深度,只作为深度测试,那么优先选择使用Read而不是Attachment,同等情况Read更优化。
如果只是用作图形管线采样或者InputAttachemnt,不作为Attachment读,那么更优化的是 VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL ,这是大多数普通非RT贴图该选择的layout。
同样从这张图可以看到,贴图永远不能:
1同时作为写入RT被写入和作为贴图被采样
2 同时作为写入RT被写入和作为shader input attachment
Metal
Vk的layout定义的过于复杂,而在metal上没有这个显示的概念,metal会根据你的API调用自动的对image的“layout”进行设置,只是在encoder上留了两个相当简单的API:
optimizeContentsForGPUAccessoptimizeContentsForCPUAccess
用来告诉硬件这个贴图的存储是优化成更易被GPU访问还是CPU访问。
Gles
在GLES上则完全没有这个概念,全部交给驱动根据API的调用做一些自动化的“layout”设置。
3.1.6 同步粒度
对于A和B两个指令集合,当谈到同步的时候,还要限定一个同步的粒度
空间上的粒度
即这个同步是指对一个sample来说有效,还是对一个pixel,一个tile,一整个frame buffer。对整个Framebuffer有效就意味着,A的操作要对整个Framebuffer都完成,才能发生B的操作。
光栅化顺序就是对于单个sample来说的,其他大多需要API保证的顺序一般都是按照tile或者framebuffer粒度的。
在vulkan上有一个枚举类型VkDependencyFlagBits里面定义了这种空间上的粒度,大多数同步API都需要这个类型的一个参数。
时间上的粒度
即这个同步的集合里面只包含一个command,还是一批command,还是一个subpass,一批subpass。如果是一批command,那么意味着A集合中的所有command都执行结束后,B集合中才能有command开始执行。
对于时间上的粒度,不同的API里面都会设计不同的数据结构,后面会具体讲解。
3.2 不同平台的同步机制实现
前面提到的执行顺序,内存访问顺序的同步,图像可操作状态的转换等在不同的平台下需要靠不同的数据结构和API来实现,不过我们可能在gles编程中几乎感受不到同步这个概念和他带来的困扰,那是因为Gles API为我默默保证了很多同步顺序,但是也可以说我们在gles上做不到细粒度的同步,GPU也不能更好的提升并行效率。在vulkan和metal上同步API的使用都是经常性的操作,metal设计上很轻量,但确实vulkan的重难点之一。
这一节将先分析vulkan和metal的同步机制的实现,最后讲下gles的机制。不过在具体看他们的区别并进行对比前,我们先抽象一下同步这个概念,即在任何API中,都需要有这个抽象来实现同步,同步在API实现上就是关注“两个集合,一个barrier”的事情。
3.2.1 两个集合,一个Barrier
首先图形API都是以指令的形式发送到GPU的。
当考虑对顺序做保证等时候,一定是保证某些指令集合A和某些指令集合B之间的顺序,做到这一点,最可行的方案就是往指令流种插入一个特殊指令C,让这个特殊指令将指令流做切割,C之前的某些指令就会看做成A,C之后的某些指令就会看作成B。
这种特殊指令C就被称为同步指令,C插入,切割的逻辑可以多种多样,同步的时间粒度也不一致,这就造成了后面会看到的不同的实现不同的同步指令,但是不管怎样,都可以看作往指令流里面设置了一个“路障”,因此本文后面都把这种同步API称做“Barrier”。
如下图,对每个Barrier来说,都可以找到他的一个前置的集合A,和一个后置的集合B,Barrier,A,B三者之间保证了一个特定的顺序。
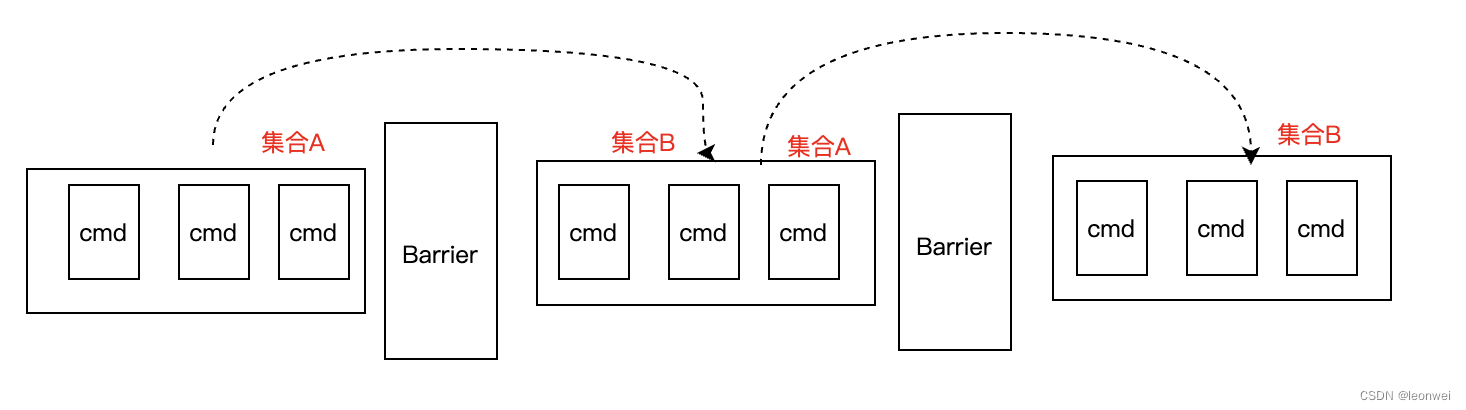
Barrier从设计和实现上看要考虑以下因素:
- 同步的有效作用域:GPU上的指令从大到小可能存在于不同的范围内:如queue,comand buffer,renderpass。如果能够对不同的指令作用域使用不同的同步类型,性能一定会更好。如支持queue内部的同步机制一定比可以支持跨queue(线程)的高效。
- 同步的时间粒度:是支持单个command之间的同步,还是只支持rendperass整体的同步,或者是支持command buffer整体的同步,性能也不一样。
- 同步的空间粒度:是同步只保证单个pixel的尺度,还是要针对整个Framebuffer?
- 同步所在的gpu管线阶段:因为一个渲染资源可能在渲染管线的不同阶段被进行访问,而现代GPU流水线上的不同渲染阶段也能被并行,因此如果对被依赖的指令执行和内存的等待只局限在特定的渲染管线阶段,就可以大大提高渲染的并行程度。
举个例子,某个image 在指令CmdA中被在PS中写入,而在指令CmdB中在PS中被读取。如果不考虑渲染阶段,那么这个依赖关系就是:
CmdB要晚与CmdA被GPU处理,image需要先被CmdA的流水线处理完,再被CmdB处理。
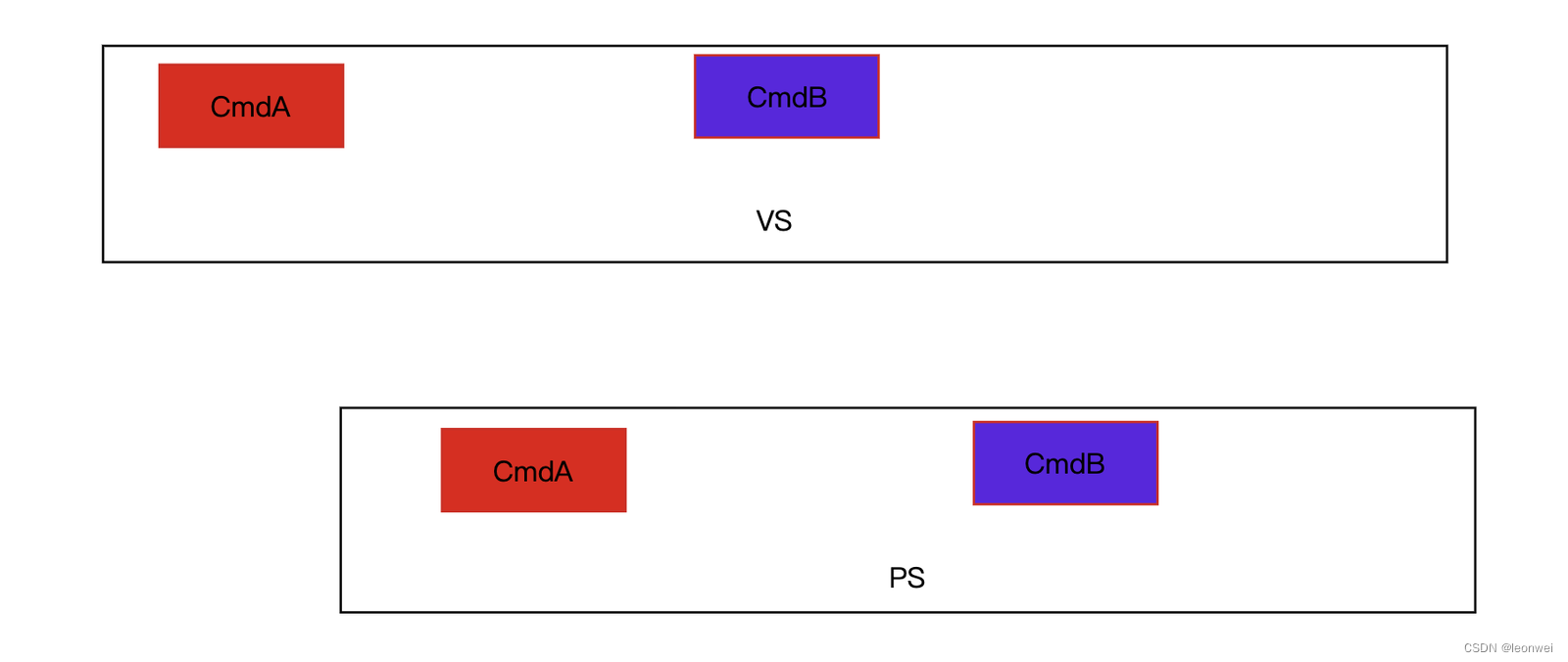
如上图一样,CmdB的执行一定要推迟到CmdA完全执行完。但事实上这里有并行度的浪费,因为明明可以这样
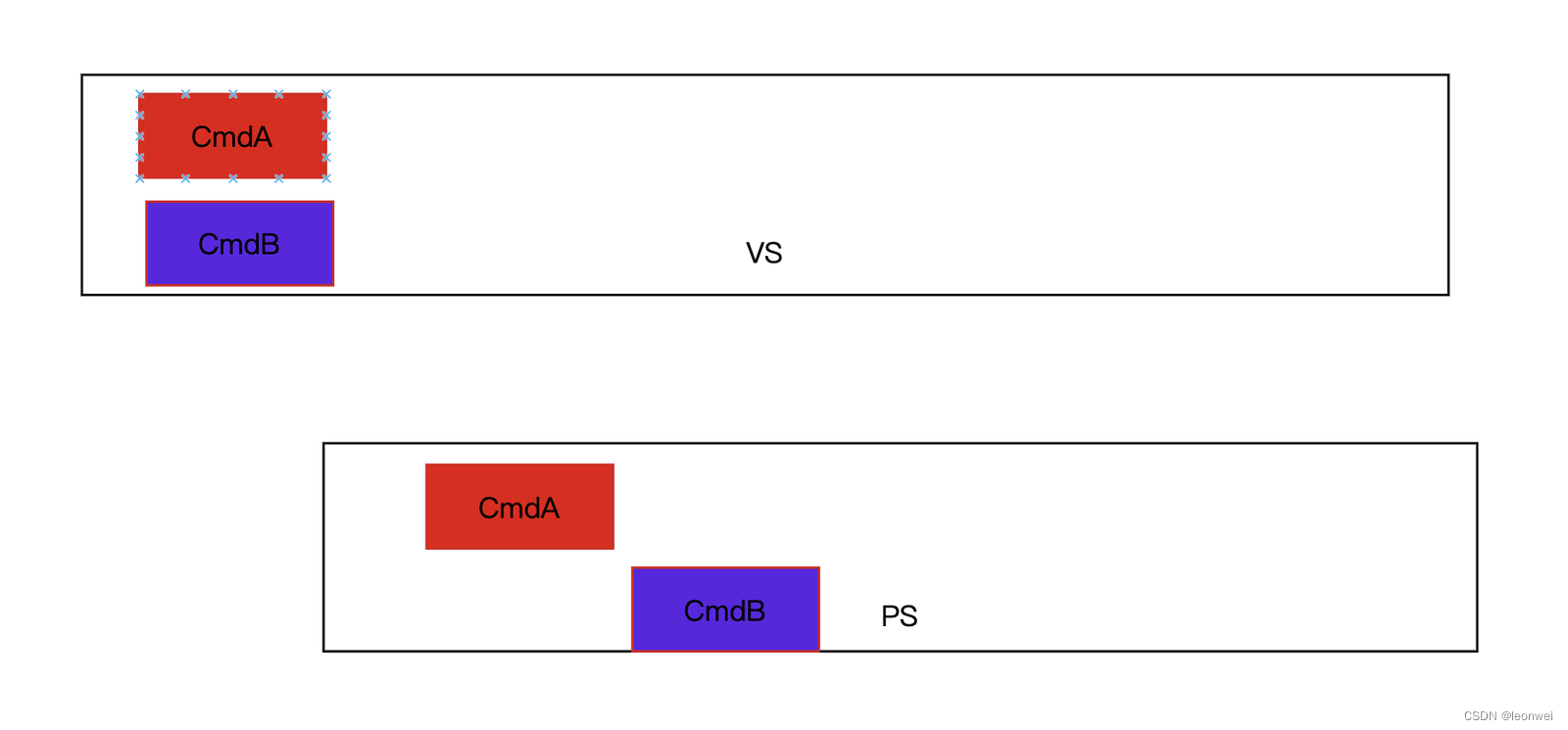
因为他们的VS是不存在依赖关系的,只有PS才存在,所以要考虑同步发生的管线阶段。
- 是否在图像的同步结束后发生图像的可读写状态改变。
我们在分析后面的各种同步指令中,都要考虑上面的5点来选择合适的API,以达到最好的性能。
3.2.3 Vulkan上GPU的同步机制
对于GPU上的同步,Vulkan上设计了5种同步机制,他们的不同是为了方便上面讨论的关于不同同步需求的需要。先用一个表格简要列出这5种机制的区别,他们全都是同时支持指令顺序和内存访问顺序的同步。
| 作用域 | 时间粒度 | 对管线阶段的定义 | 使用场景 | |
| Fence | -- | SubmitInf | 粗粒度 | 只存在Barrier之前的操作集合 |
| Semaphore | Device | SubmitInf | 粗粒度 | 最简单的Barrier |
| Event | Queue | Command | 细粒度 | Barrier的标准实现 |
| PipelineBarrier | Queue | Command/RenderPass | 细粒度 | 最易用版本的Barrier |
| Renderpass Dependency | Pass | SubPass | 细粒度 | subpass之间的barrier |
3.2.3.1 Vulkan上如何表达两个集合的依赖关系
Vulkan API中首先要对这种“两个集合的依赖关系"定义成一些数据结构。
管线阶段的表达
前面提到同步需要考虑到所处的管线阶段。
指令执行所在的管线阶段
vulkan中叫做 execution scope
定义在vk的枚举类型
VkPipelineStageFlags2 里面
它定义了如下主要阶段(列举了部分)
图形管线相关:
VK_PIPELINE_STAGE_2_DRAW_INDIRECT_BIT
VK_PIPELINE_STAGE_2_VERTEX_INPUT_BIT
VK_PIPELINE_STAGE_2_VERTEX_SHADER_BIT
VK_PIPELINE_STAGE_2_TESSELLATION_CONTROL_SHADER_BIT
VK_PIPELINE_STAGE_2_GEOMETRY_SHADER_BIT
VK_PIPELINE_STAGE_2_FRAGMENT_SHADER_BIT
VK_PIPELINE_STAGE_2_EARLY_FRAGMENT_TESTS_BIT
VK_PIPELINE_STAGE_2_LATE_FRAGMENT_TESTS_BIT
VK_PIPELINE_STAGE_2_COLOR_ATTACHMENT_OUTPUT_BIT
这里有两个比较特殊的状态,但是比较常用,描述整个管线的最开始和最后面,例如一个很保守的执行顺序的同步是,后一个指令的top依赖于前一个指令的bottom,意味着两个指令的管线阶段完全被错开,没有交叠。
VK_PIPELINE_STAGE_2_TOP_OF_PIPE_BIT
VK_PIPELINE_STAGE_2_BOTTOM_OF_PIPE_BIT
CS管线:
VK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT
Transfer状态(copy贴图等):
VK_PIPELINE_STAGE_2_ALL_TRANSFER_BIT
这里的Host状态是指在CPU一侧进行处理的状态
VK_PIPELINE_STAGE_2_HOST_BIT
内存访问的管线阶段
vulkan中叫做Memory access scope
定义在VkAccessFlags2 中
里面常见的类型有:
可以看到在管线中各种对内存的访问情形
VK_ACCESS_2_VERTEX_ATTRIBUTE_READ_BIT
VK_ACCESS_2_UNIFORM_READ_BIT
VK_ACCESS_2_INPUT_ATTACHMENT_READ_BIT
VK_ACCESS_2_SHADER_READ_BIT
VK_ACCESS_2_SHADER_WRITE_BIT
VK_ACCESS_2_COLOR_ATTACHMENT_READ_BIT
VK_ACCESS_2_COLOR_ATTACHMENT_WRITE_BIT
VK_ACCESS_2_TRANSFER_READ_BIT
VK_ACCESS_2_TRANSFER_WRITE_BIT
VK_ACCESS_2_HOST_READ_BIT
VK_ACCESS_2_HOST_WRITE_BIT
此外None是个特殊的情形,意味着不关心内存的操作。
VK_ACCESS_2_NONE
同步的空间粒度
对于前面提到的同步所使用的空间粒度,Vulkan中使用VkDependencyFlagBits来定义
例如里面的一些值:
VK_DEPENDENCY_BY_REGION_BIT :同步是整个Framebuffer的,还是local的。
VK_DEPENDENCY_VIEW_LOCAL_BIT:同步是所有view下的,还是单个view下的。
VK_DEPENDENCY_DEVICE_GROUP_BIT :同步是基于一个device group下的所有device的,还是单个device的。
两个集合的依赖关系
基于上面的Execution Scope和Memory Access Scope 可以定义出VK上用来表达这种同步依赖关系的数据结构
VK***MemoryBarrier
虽然它被叫做memory barrier,但实际上里面也包含了指令执行的依赖关系,这种数据结构有很多种,包括VkMemoryBarrier2/VkBufferMemoryBarrier2/VkImageMemoryBarrier2
VkMemoryBarrier2
typedef struct VkMemoryBarrier2 {
VkPipelineStageFlags2 srcStageMask;
VkAccessFlags2 srcAccessMask;
VkPipelineStageFlags2 dstStageMask;
VkAccessFlags2 dstAccessMask;
} VkMemoryBarrier2;
它是指对于当前Device上的任意资源内存为同步对象,是global的
里面定义了对于指令执行的管线阶段的依赖关系srcStageMask和dstStageMask,内存访问的管线阶段依赖关系srcAccessMask和dstAccessMask。即对于当前的全部内存对象,在同步API提交前提交的指令集合A和同步API提交后提交的指令集合B,任何B中的指令的dstStageMask的阶段的执行要晚与所有A中指令的srcStageMask阶段执行完,且B中指令在dstStageMask中产生的任何相关的对内存的的dstAccessMask访问要晚与A中指令在srcStageMask阶段产生的对内存的srcAccessMask操作。
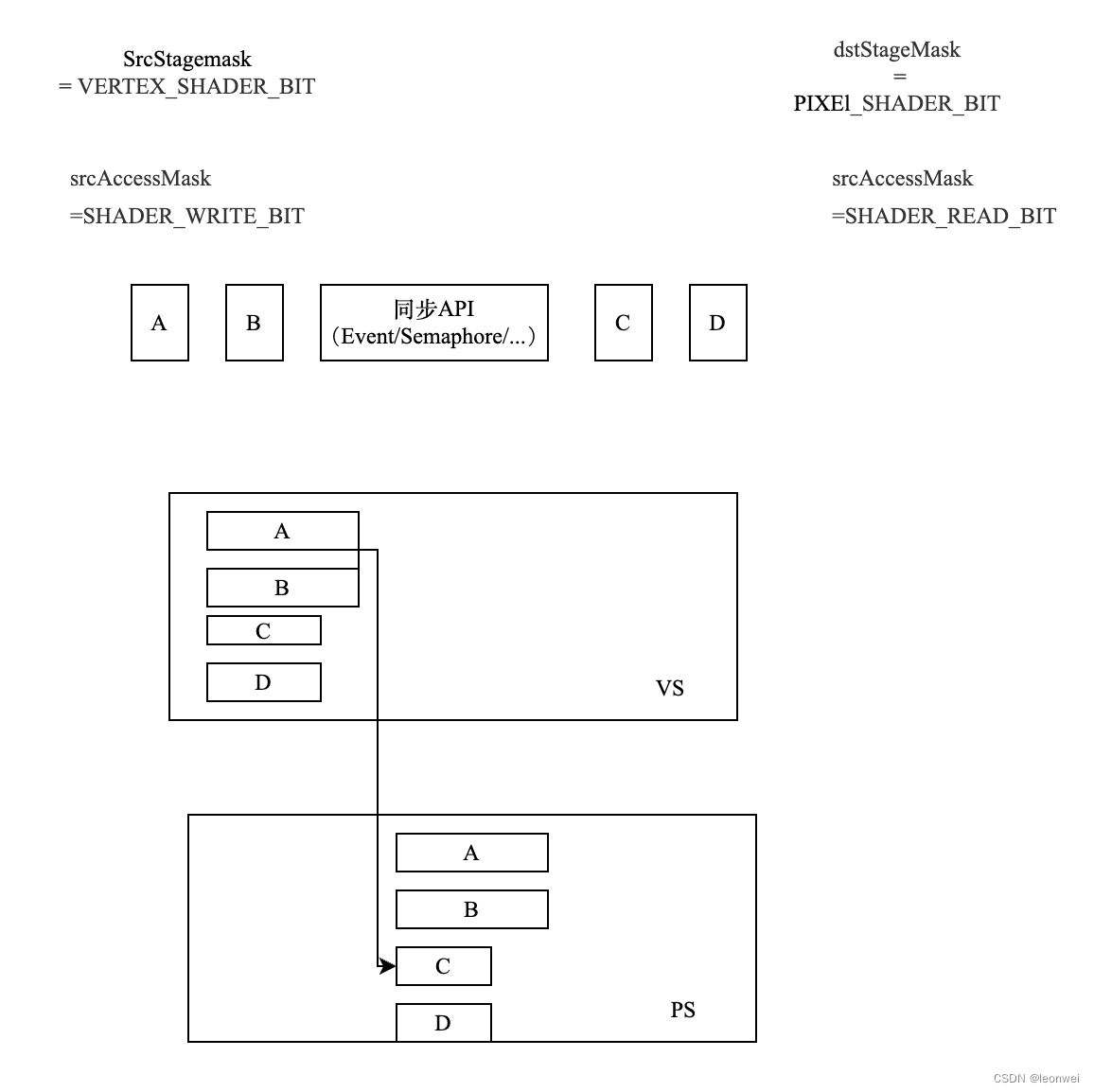
如上面的例子,当某个同步API使用这个VkMemoryBarrier2作为参数插入command buffer之后,c和d的ps依赖ab的vs,所有ABCD的vs理论上可以并行,但是cd一定要等完ABCD的vs结束后才能进入ps,而不是CD自己的vs结束,同时CD对所有内存在shader中的读取采样操作,都要等待AB在shader中将他们写入完成。
另外需要注意的是这里的srcStageMask同srcAccessMask,以及dstStageMask同dstAccessMask必须匹配,例如srcAccessMask如果为SHADER_READ_BIT, 那么它能搭配使用的srcStageMask只能是STAGE_*_SHADER_BIT,这个需要查阅vk的规范。
VkBufferMemoryBarrier2
同VkMemoryBarrier2唯一不同的是他里面定义的保持同步的内存不是device上的全部资源内存,而是一个指定的Buffer对象。
typedef struct VkBufferMemoryBarrier2 {
VkStructureType sType;
const void* pNext;
VkPipelineStageFlags2 srcStageMask;
VkAccessFlags2 srcAccessMask;
VkPipelineStageFlags2 dstStageMask;
VkAccessFlags2 dstAccessMask;
uint32_t srcQueueFamilyIndex;
uint32_t dstQueueFamilyIndex;
VkBuffer buffer;
VkDeviceSize offset;
VkDeviceSize size;
} VkBufferMemoryBarrier2;
VkImageMemoryBarrier2
同VkMemoryBarrier2唯一不同的是他里面定义的保持同步的内存不是device上的全部资源内存,而是一个指定的Image对象。
typedef struct VkImageMemoryBarrier2 {
VkStructureType sType;
const void* pNext;
VkPipelineStageFlags2 srcStageMask;
VkAccessFlags2 srcAccessMask;
VkPipelineStageFlags2 dstStageMask;
VkAccessFlags2 dstAccessMask;
VkImageLayout oldLayout;
VkImageLayout newLayout;
uint32_t srcQueueFamilyIndex;
uint32_t dstQueueFamilyIndex;
VkImage image;
VkImageSubresourceRange subresourceRange;
} VkImageMemoryBarrier2;
此外它还定义了图像可访问状态的改变,意思是经过这个API,这个image的layout会从oldlayout变成newlayout
VkDependencyInfo
上面的这些MemoryBarrier最终会进一步被包装到VkDependencyInfo这个数据结构种,它包含了上面的这些对于全局资源,特定image,特定buffer的memorybarrier和VkDependencyFlags,其中VkDependencyFlags用来定义Framebuffer-local Region。
typedef struct VkDependencyInfo {
VkStructureType sType;
const void* pNext;
VkDependencyFlags dependencyFlags;
uint32_t memoryBarrierCount;
const VkMemoryBarrier2* pMemoryBarriers;
uint32_t bufferMemoryBarrierCount;
const VkBufferMemoryBarrier2* pBufferMemoryBarriers;
uint32_t imageMemoryBarrierCount;
const VkImageMemoryBarrier2* pImageMemoryBarriers;
} VkDependencyInfo;
VkDependencyInfo常作为参数用来表达细粒度的依赖关系出现在大部份的同步api中。
下面就可以介绍vk的5大同步机制了。
3.2.3.2 Fence
VkFence是最简单的同步机制,正如其名,它很像一个围栏,它的特点是只保证barrier之前的API要在barrier前被处理,值得注意的是,这里只定义了barrier和barrier的前置集合这一种依赖关系,没有定义后置集合,少了一个集合,也就是说不同barrier之间的API们并没有必然的依赖关系,他们依然可能存在某种并行。
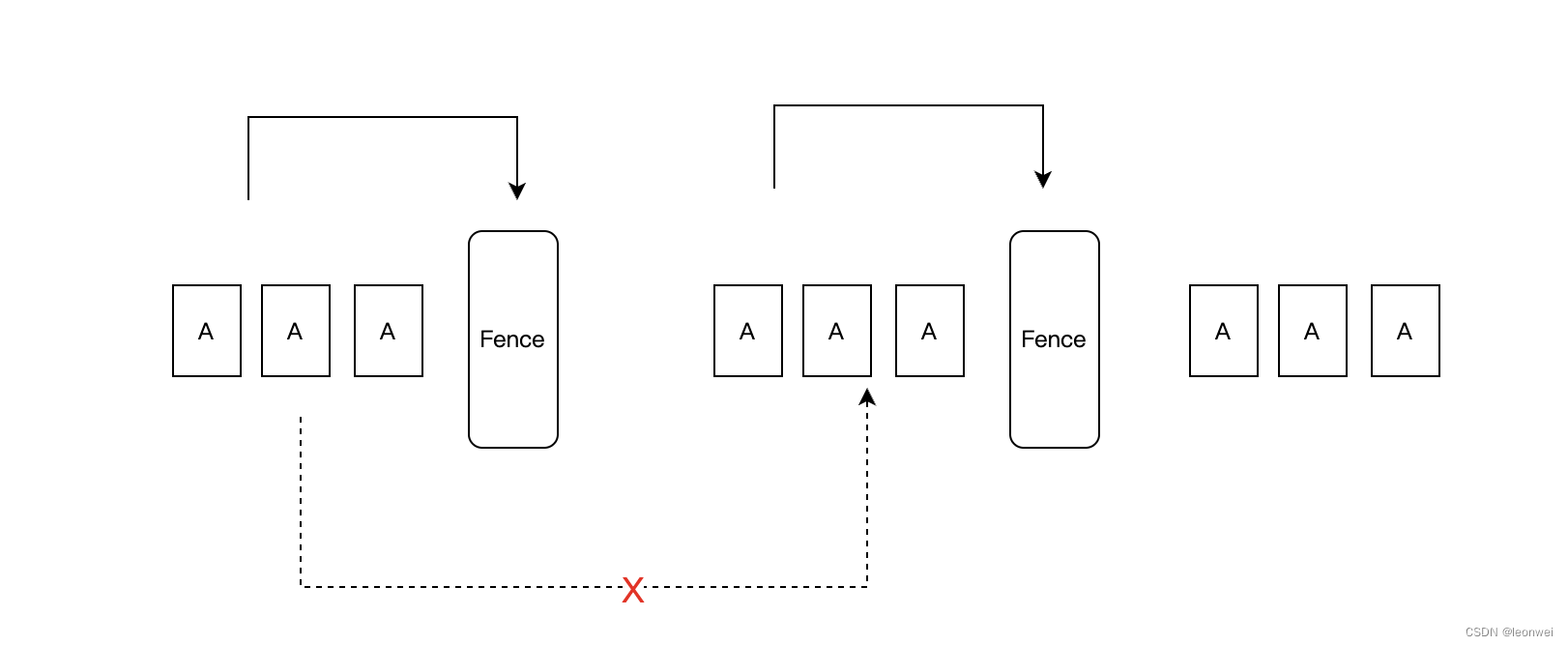
时间粒度
它只能对单个的submitinf(即一批command buffer)做同步
使用
在使用vkQueueSubmit 提交一个submitinf时,可以插入这个fence,当这个submitinf执行完触发fence的signal
因为没有后置集合,在GPU上不能wait一个Fence,只能在提交完毕时signal
(但是在CPU上可以wait)
指令执行和内存访问的依赖
Fence被插入command buffer后,会定义一对依赖关系如下:
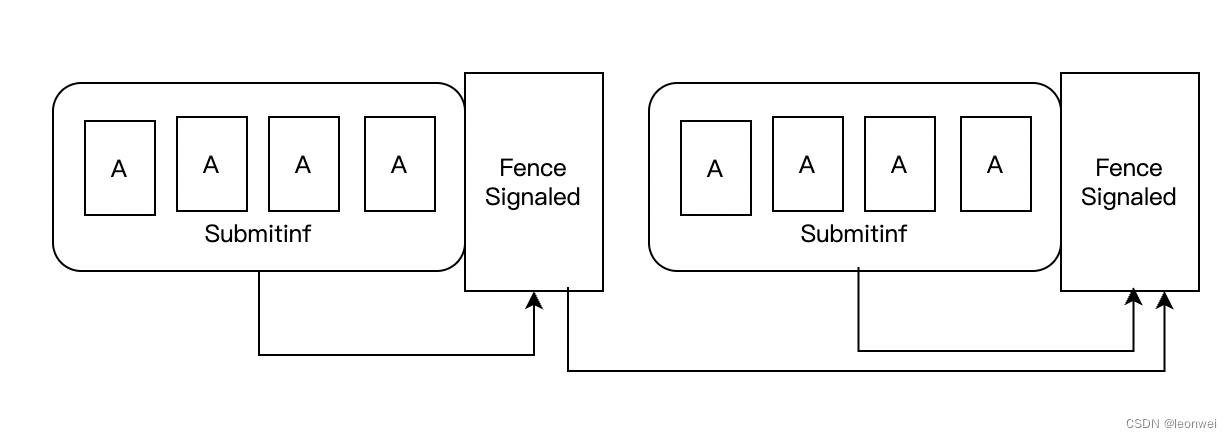
即这个fence的signal依赖它所在的submitinf中的所有cmd完成,以及之前所有signaled过的fence和semaphore。
管线阶段限定:
Fence不能携带类似VkMemoryBarrier2的参数来制定精细的指令执行和内存访问依赖。它的被依赖的指令执行阶段是submitinf中的所有指令的所有execution scope,内存依赖是device上的所有内存访问类型。
这是一种相当粗粒度的同步。
3.2.3.3 Semaphore
VkSemaphore是增强版本的Fence,它包含全部的两个同步集合,即比fence多了后置集合,如下
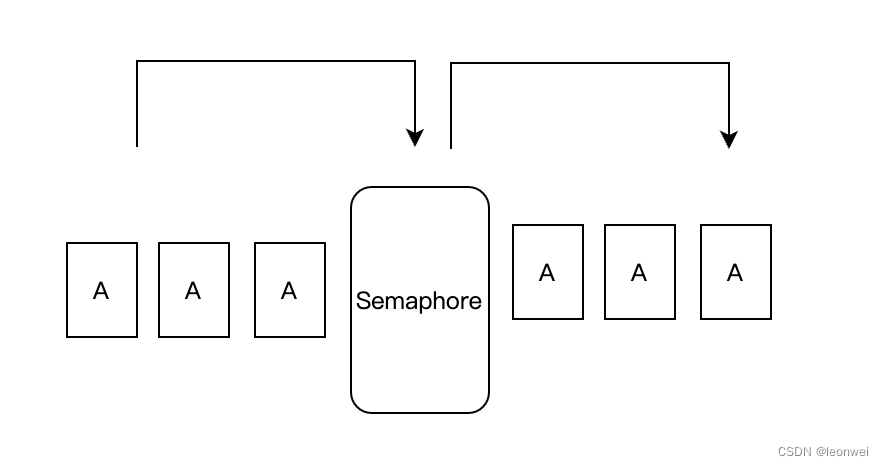
这是一种标准的barrier,对于Semaphore来说,这个barrier前的API结束后会导致这个barrier被设置成某种信号,barrier后的API的执行等待这个阻挡信号,因此这种barrier被称为信号量(semaphore)
时间粒度和作用域
对不同的submitinf(一批command buffer)之间的同步。这些submitinf可以是跨越queue的。
使用
同Fence类似,在提交API vkqueusubmit中,其提交参数VkSubmitInfo中指定了这个submitinf依赖的semaphore和它被gpu执行完之后会signaled的semaphore。
指令执行和内存访问的依赖
semaphore的signal和wait各自会定义一组依赖关系
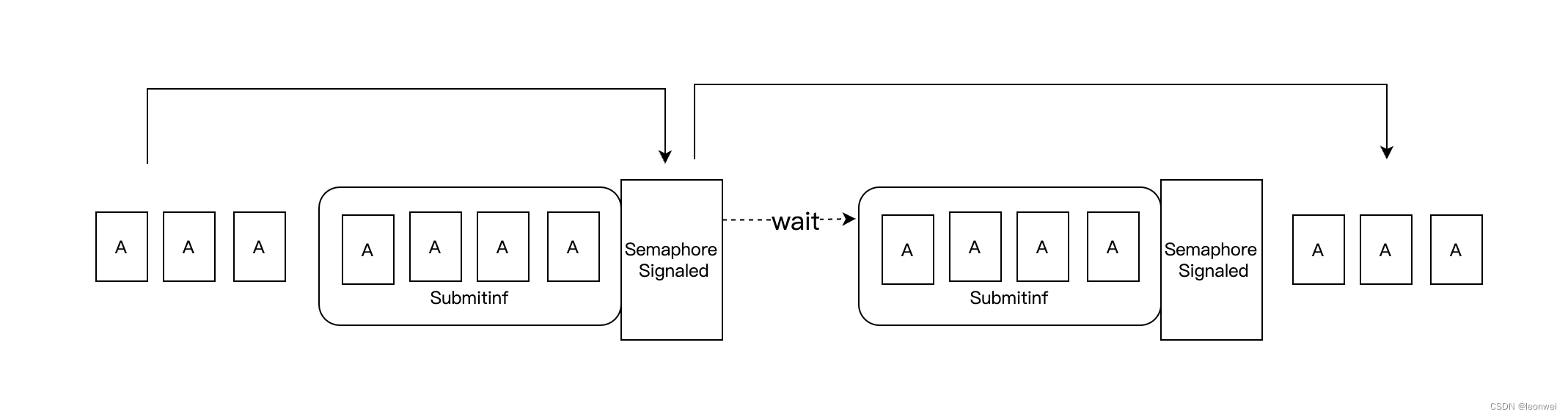
- signal定义了barrier的信号触发依赖于这个barrier之前提交的所有API完成(或者其他semaphore被定义),被依赖的指令执行阶段是所在submitinf中的所有指令的所有execution scope,内存依赖是所有device上的所有内存访问类型。
- wait定义了barrier之后的API的执行依赖于barrier被signal。依赖的指令执行阶段是所在submitinf中定义的pwaitdststagemask,内存依赖是所有device上的所有内存访问类型。
由于不能指定详细的管线阶段限定,sempahore同样是粗粒度的barrier。
3.2.3.3 Event
如果说fence和Semaphore是粗粒度的,那么Event就是细粒度版本的Barrier(当然粒度越细,性能可能就会更差),因为Event可以指定所在的管线阶段。
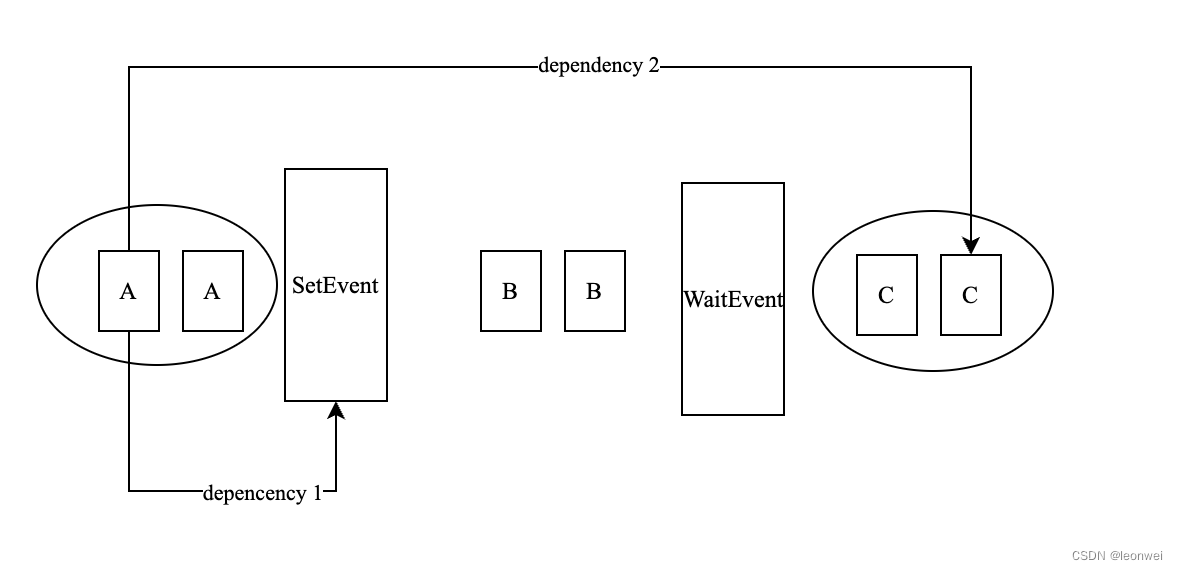
时间粒度和作用域
它可以指定单个Command之间的同步,但是需要限定在同个queue内部。
使用
使用vkCmdSetEvent2 插入一个cmd,当这个cmd执行时设置为signaled
使用vkCmdWaitEvent2使其在同个queue上提交顺序更后的所有cmd(可以跨越cmd buffer)产生对signaled之前的cmd的执行顺序和内存访问的依赖。
指令执行和内存访问的依赖
同样这里会存在两对依赖
1.setevent这个API本身会依赖在它之前提交的API(part A),
- waitevent之后的API(Part C)会依赖setevent之前的API(part A),这两种依赖可以指定不同的依赖参数。
管线阶段指定
上述API中都携带VkDependencyInfo参数,可以指定最细致的指令执行和内存访问的管线阶段依赖。
Event是标准版本的Barrier实现。
3.2.3.4 PipelineBarrier
在目前1.3的vk版本中,我们几乎可以认为pipeline barrier是一个语法上简化版本的event,它同样做细粒度的command之间的同步,同样支持指定细节的指令执行和内存访问的管线阶段依赖,layout的转换关系。只是这里不需要创建一个vkevent对象对他做set和wait,而只要插入一个pipleine barrier即可。(其实早期版本的vk中event只支持粗粒度的依赖,不具备vkdependencyinfo参数)。
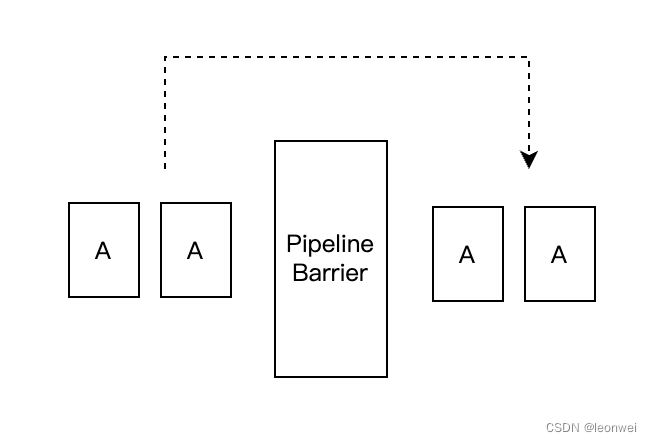
如图这里同event不同的是,把两种依赖关系简化成了只有一种依赖关系,Barrier后的API对之前的依赖。此外还有个不同点是,当pipeline barrier放在renderpass内部的时候,其作用范围只针对它所在的subpass内部有效。
因为简洁好用,另外vk编程中很多时候我们有紧紧需要改变Image的layout的需求,所以pipeline barrier可能是vk编程中最常被使用的同步API。
使用
直接使用
void vkCmdPipelineBarrier2( VkCommandBuffer commandBuffer,
const VkDependencyInfo* pDependencyInfo);
来插入一个barrier。
3.2.3.5 RenderPass Dependency
通常在subpass切换期间会大量的存在指令执行和内存访问的同步,因此VK为subpass间定义了一种特殊的barrier。
我们在前面一个章节讲vksubpass的时候,讲到过定义一个vk的renderpass时需要一个参数定义subpass之间的依赖关系。
// Provided by VK_VERSION_1_0
typedef struct VkSubpassDependency {
uint32_t srcSubpass;
uint32_t dstSubpass;
VkPipelineStageFlags srcStageMask;
VkPipelineStageFlags dstStageMask;
VkAccessFlags srcAccessMask;
VkAccessFlags dstAccessMask;
VkDependencyFlags dependencyFlags;
} VkSubpassDependency;
这里定义了dstsubpass要对srcsubpass产生依赖,后面的各种vkpipelinestageflags和accessfags,dependencyflags则用来指定细粒度的管线阶段和空间粒度。
它是专门为时间粒度为整个subpass而做的 barrier。
3.2.3.6 RenderPass 结束时的layout转换
事实上vulkan种还隐藏了一种形式的内存同步,即在一个renderpass结束的时候,会发生一次当前pass所用的attachment RT的layout的转换(即对图像内存发生了一次同步,然后改变它的可访问状态)。
这个转换在定义一个renderpass的时候定义在VkAttachmentDescription中
typedef struct VkAttachmentDescription {
VkAttachmentDescriptionFlags flags;
VkFormat format;
VkSampleCountFlagBits samples;
VkAttachmentLoadOp loadOp;
VkAttachmentStoreOp storeOp;
VkAttachmentLoadOp stencilLoadOp;
VkAttachmentStoreOp stencilStoreOp;
VkImageLayout initialLayout;
VkImageLayout finalLayout;
} VkAttachmentDescription;
参数finalLayout即是这个rt在renderpass结束时会被转换到的layout。
这个layout转换发生的同步是不能被忽略的。
3.2.4 Metal上GPU的同步机制
Metal大幅度的简化了vulkan的5种同步机制。相当于只保留了简化版本的Event和PipelineBarrier。
同Vk相关概念简单的对比如下
| Vk中的类似概念 | 对vk概念的简化 | |
| MtlEvent | VkEvent |
|
| MtlFence | VkEvent |
|
| Metal MemoryBarrier | Vulkan PipelineBarrier |
|
3.2.4.1 Event
MtlEvent同VkEvent的作用类似,都是提供通过对一个event的set和wait来同步,如下,eventwait之后的renderpass要等待event signale之前的renderpass的执行完毕。
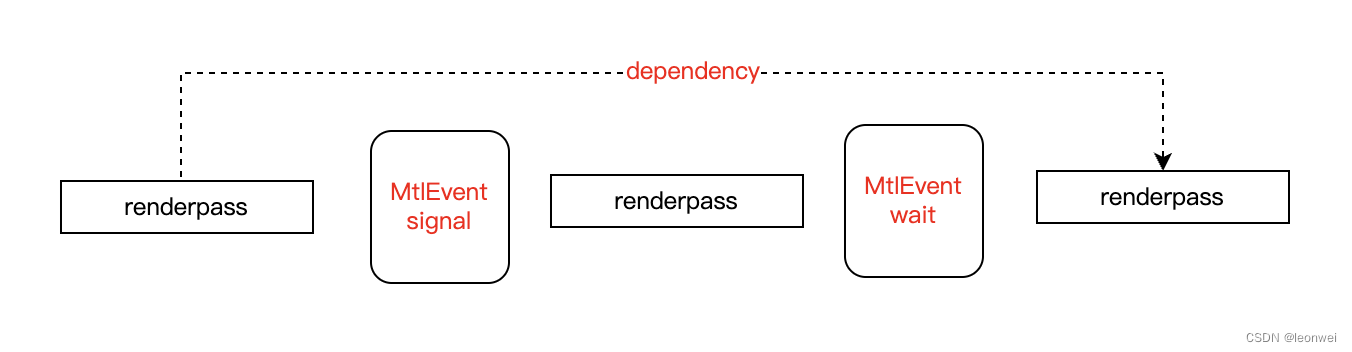
但是这里有很多不同之处:
作用域:
MtlEvent不是单个Command级别的,而是renderpass级别的,这要求event的signal和wait操作不能在一个renderpass内部调用。另外MtlEvent也可以是跨越Queue的。
内存访问顺序和管线阶段限定:
MtlEvent没有暴露出来内存访问顺序的同步,只有一个简单的执行顺序同步,但是在Metal中,RT的内存访问同步在很多情况是自动完成的,即API会自动根据Texture在Pass中的使用状况(何时被当作attachment写,何时被采样)而自动为我们做好RT的访问顺序同步,不需要开发者额外关心。
此外这里的Event同步也不能指定管线阶段,对于执行顺序来说,管线阶段就是全部阶段。
使用:
具体使用上 encodeSignalEvent:value 将一个mtlevent插入到cmdbuffer上,给他一个新的value, 等这个cmd之前的cmd都完成了,他会把旧的value更新成新的value
使用 encodeWaitForEvent:value:来等待这个event,直到这个event变成这个value, 这个cmd后面的指令才会执行。
3.2.4.2 Fence
Metal中的fence完全不同于vulkan中的Fence(最低配版本的半个barrier),它反而更像是Event的升级版本,相比Event,它增加了管线阶段限定的功能。
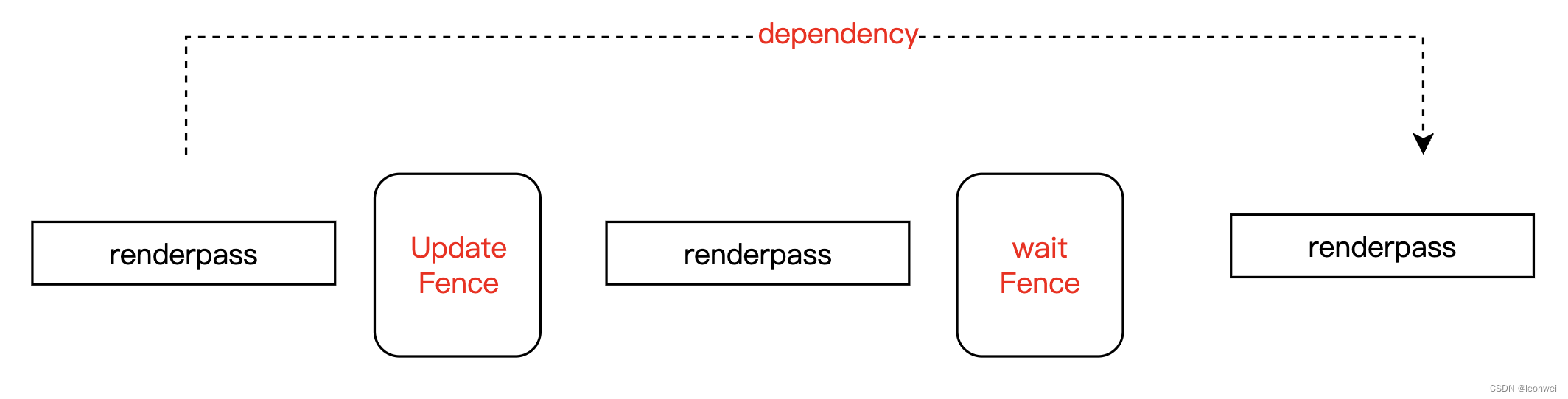
作用域:
同Event一样,它的时间粒度是整个renderpass,也是不能对单个command同步,同时它的作用域限定在单个queue内部,不能跨越queue。
使用:
它通过调用
-(void)waitForFence:fence
beforeStages:stages;
使得这个API之后的指令等待Fence被signal
通过调用
- (void)updateFence:(id<MTLFence>)fence
afterStages:(MTLRenderStages)stages;
使得之前的指令早于这个Fence被signal之前完成。
注意这两个API调用必须在renderpass内部,当一个renderpass被提交时,metal会自动分析里面涉及到的wait和update的fence,如果一个renderpass同时wait和update同一个fence(例如你想让这个renderpass内部的所有ps完与所有vs),那么要先调用wait,再写update。
内存访问顺序和管线阶段限定:
同样不能指定内存访问的同步,但是可以指定指令执行的管线阶段,在参数MTLRenderStages中
不过metal上同样没有定义类似于Vulkan上VkPipelineStageFlags的复杂管线阶段定义。
只给了几个简单的枚举值定义,只有
MTLRenderStageObject/MTLRenderStageMesh/MTLRenderStageVertex/MTLRenderStageFragment/MTLRenderStageTile 五个,从命名就能推测其含义。
3.2.4.3 MemoryBarrier
Metal中Memory Barrier是一个最接近Vulkan的Pipeline Barrier的概念了。它同样是插在command中的一个barrier,保证barrier后面的指令对前面指令的依赖。作用域同样是单个Command级别。
使用上直接调用MTLRenderCommandEncoder的API
- (void)memoryBarrierWithScope:(MTLBarrierScope)scope
afterStages:(MTLRenderStages)after
beforeStages:(MTLRenderStages)before;
来往当前Command中插入一个Barrier。
但是它相比Vulkan还是做了极大的简化。
内存访问顺序和管线阶段限定:
metal同样没有定义类似于Vulkan上VkAccessFlags的结构定义内存访问所在的阶段,而只是给了一简单的枚举值
MTLBarrierScope类型,里面也只包含来三个数据
MTLBarrierScopeBuffers/MTLBarrierScopeRenderTargets/MTLBarrierScopeTextures
意味着对全局的所有buffer或者rt或者贴图做所有内存访问类型的同步。
它也通过MTLRenderStages来限制管线阶段,这是指令执行和内存访问共有的阶段。
3.2.5 CPU-GPU同步
上面介绍的都是GPU上到同步机制,有时我们需要在CPU-GPU之间进行同步,分为两种情况:
- CPU等待GPU的某个指令完成
- GPU等待某个CPU控制的信号被signal才能继续
上面多数的GPU上的Barrier同样可以做CPU-GPU间到同步。
Vulkan
VkFence:用vkResetFences在CPU一侧reset fence, 用vkWaitForFences在CPU一侧wait fence,但是不能在GPU等待
VKSemaphore:可以直接使用vkSignalSemaphore/vkWaitSemaphores一侧触发或等待一个semaphore
VkEvent:可以使用vkSetEvent直接在CPU一侧触发这个event,但是不能在CPU等待
Metal
metal则使用了MtlEvent的派生类型MtlSharedEvent来做CPU-GPU的同步。SharedEvent存储了一个value,
在创建一个SharedEvent之后,可以在CPU一侧block住直到value到达预期值,GPU一侧还是通过encodeWaitForEvent/encodeSignalEvent进行触发和等待。
3.2.6 Gles上的同步机制
前面谈到的都是metal和vulkan上到同步机制,而在gles上,一切都非常简单。
执行顺序
gles上的提交顺序即是gpu的执行顺序,gles也只有一个queue,所以保证指令record到queue的顺序就保证了最终gpu上的指令执行顺序。
正因为gles默认的保证gpu的指令执行顺序,所以把一个gles上的渲染逻辑移植到vulkan上可能会不注意同步而产生问题,一个最简单的例子是:在gles上顺序提交的两个renderpass,他们往同一个rt上绘制,由于他们在gpu上的处理顺序也是顺序完成绘制的,所以没什么问题。但是在vulkan上,这样的代码可能导致两个renderpass被并行或者倒序处理都是可能的,如果不加以barrier,很可能会发现后一个renderpass绘制的半透明经常被第一个renderpass的绘制遮盖住。
SyncObject
gles上因为也只支持多线程同时record指令的,这时候还是要考虑保证多个线程间record的顺序,当然可以用cpu一侧的同步机制,但是会导致cpu一侧发生block,因此gles还是提供了一个GPU侧的barrier机制保证执行顺序,即SyncObject。它的工作原理如下
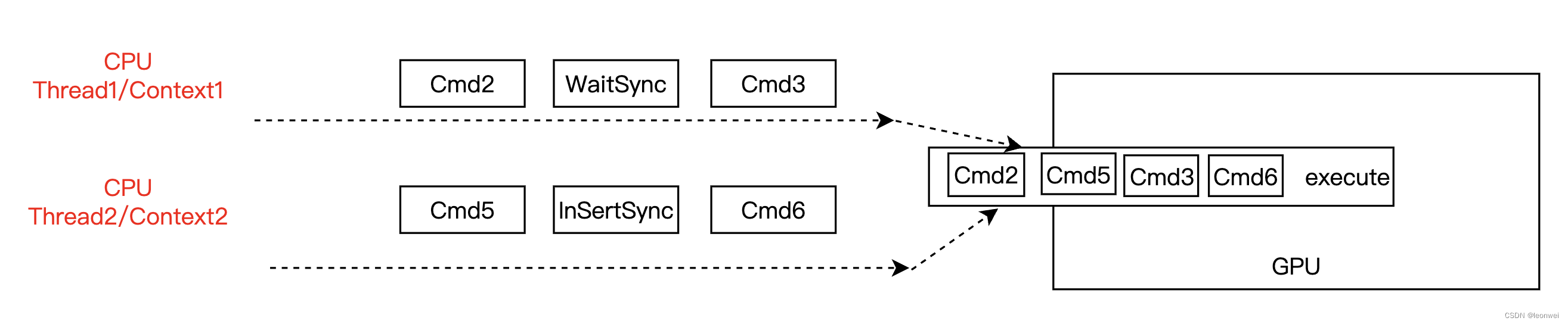
两个contex同时指令的record,context 2通过glFenceSync创建并插入一个SyncObject,context1中用glwaitsync等待这个SyncObject,这会导致GPU在执行cmd3的时候,保证Cmd5被执行完毕。
gles的SyncObject是Barrier的极简化版本,只包含粗力度的指令执行同步,多数用于gles上多个context并行record指令并涉及到有sharedobject的时候,例如一个线程负责shader编译,另一个线程负责draw,那么draw线程中就需要wait编译线程中某个shader编译好的syncobject。
此外SyncObject也是Gles用来做CPU-GPU同步的手段,使用glWaitClientSync可以在CPU一侧等待这个syncobject被signal。
内存访问顺序
gles上额外提供了一个相关简单的机制保证内存访问顺序的同步,就是
void glMemoryBarrier(GLbitfield barriers);
首先Gles上同Metal类似,对于简单的用于Attachment的贴图的读写同步是可以内部进行粗粒度保证的,如一个rt前面pass被写,后面被读,因为pass在执行上保证同提交的顺序,这个rt的先写后读也可以被保证,且是在Framebuffer域保证。
但是对于一些其他渲染管线中用到的内存,还是需要依靠API保证。
glMemoryBarrier的行为不是像高级API那样逐个定义前后两个集合的指内存访问类型和同步所在的管线阶段,而是定义了一堆枚举值来枚举了各种典型的可以支持的同步情况。且这个同步的时间粒度是这个API之后的所有指令依赖API之前的所有指令。
这些值典型的有:
GL_VERTEX_ATTRIB_ARRAY_BARRIER_BIT:对于vb的使用依赖与前面shader对vb的使用
GL_TEXTURE_FETCH_BARRIER_BIT:对于贴图的采样依赖前面shader对贴图的写入
GL_SHADER_IMAGE_ACCESS_BARRIER_BIT:对于Image的读取依赖前面(compute shader)对image的写入
3.2.7 关于默认的顺序
正是因为在利用API编程时,同步如此重要,所以我们需要再次总结下在不同API上哪些同步机制是API默认提供给我们的,而除此之外都是需要我们主动思考保证的。
Vulkan
Vulkan显然是最麻烦的情形,因为在Vulkan上,只有一种顺序是默认情况下可以确定的,就是光栅化顺序,即对于同一个subpass中的同一个sample,它在ps中的执行和对attachment的内存写入按照光栅化顺序(即GPU的提交顺序)。其他任何顺序(驱动对command的处理,GPU对drawcall的绘制,不同的ps执行之间...)都可能是同你的提交顺序无关的,且大概率会被硬件按照它最优化的方式并行无序执行,这是一个非常极端的API。
Metal
除了光栅化顺序之外,Metal能够自动分析出RenderPass之间的依赖关系,对有明显依赖关系的RenderPass,一般不需要主动保证他们的指令执行和rt的同步关系,只有对于pass中涉及到的其他内存资源,需要主动去保证同步关系,此外没有依赖之间的renderpass也是会被metal并行执行。
Gles
Gles上GPU执行顺序等同于指令的提交顺序,加上gles上基本都会单线程提交drawcall,所以gles上的指令执行顺序是默认明确的。对于RT,同metal一样也可以自动保证其读写同步,只有对于渲染中涉及到的其他内存资源,才需要通过glmemorybarrier去进行同步。
- 内存
图形API会在多大程度上触碰到内存?CPU一侧我们通过new/malloc等语法分配CPU上的内存,而图形API则通过特定的API接口间接的分配释放内存和显存。
我们首先可以把图形API能触碰到的内存分为Host和Device两种,Device一般就是我们为实际的渲染资源(如texture,buffer)在GPU一侧分配的内存(或叫做显存),而Host一般是API为了管理渲染结构在CPU一侧分配的内存,虽然在移动端HOST和Device在物理上可能是放在一起的。
4.1 Host内存
为了维护渲染上下文,管理GPU上的渲染结构,准备渲染数据,API都会在CPU一侧在驱动内部分配大量的内存,这部分内存对开发者来说基本是不可控的,即你不能显示的决定这些内存在何时分配和销毁,它只是你调用API时的副产物。有时这部分内存占用可观,甚至超过图形资源实际占用的显存,在平台的内存分析工具中,它会统计到在你的app的native内存中,有时候我们自己的引擎在C++一侧分配的内存并没有那么多,这个差值的很大一部份就来源于API的Host内存分配,它由驱动所在的C++库分配。
Gles
gles上不能控制这部分内存的分配,它随API产生,如果要统计他们的大小也不容易,你可能需要hook 类似adreno.so这种显卡驱动的native内存分配,或者统计pmap指令中来自类似kgsl这种文件的mmap。Gles上的Host内存浪费是比较严重的。
Vulkan
Vulkan中默认Host内存也是驱动管理的,但是在相当大的程度上给了一个callback通知我们host内存的分配时机并允许我们使用自己的内存分配策略,这个相当友好,因为大多数引擎都有自己封装的更高级的内存分配器,这样也可以把他们给API的Host内存分配使用,有利于内存profile和内存的使用效率。
在大部分涉及到资源分配的的Vulkan API中,都允许传入一个类型为VkAllocationCallbacks的回掉。
typedef struct VkAllocationCallbacks {
void* pUserData;
PFN_vkAllocationFunction pfnAllocation;
PFN_vkReallocationFunction pfnReallocation;
PFN_vkFreeFunction pfnFree;
PFN_vkInternalAllocationNotification pfnInternalAllocation;
PFN_vkInternalFreeNotification pfnInternalFree;
} VkAllocationCallbacks;
这里面定义了Alloc,realloc,Free时自定义的回掉函数,puserdata是允许往这些自定义回掉函数里传递的自定义数据,注意实践中自定义的alloc free要配对。
另外有一些内存分配释放行为不允许我们自己实现,但是我们能够得到通知,这些通知的回调就是其中的InternalAllocation和InternalFree。
Metal
metal上虽然也不能显示控制这部分内存的分配,但是可以通过xcode中的alloccation等工具方便的看到metal API对内存的分配状况。
4.2 Device内存的分配释放
Device内存是API在GPU上分配的空间用于创建渲染资源。Device内存主要有种:
- Image
- Buffer
- Shader
- sampler,framebuffer等其他需要占用内存的对象
由于Image和Buffer是我们可以用多种方式操纵内存的大块内存对象,因此我们主要讨论他们用的内存(而其他对象的内存使用上相对固定,且被管线自动维护)。
Buffer是一段格式相对简单的一维内存数据,而Image则是有特定格式,多个维度的内存格式,一般当Image作为GPU读取的图像内存时多被称为texture,而图像内存也可以被GPU写入,这时候一般才叫做Image,本章节中,将统一用Image来称呼。
Device内存的分配主要是是为了Buffer和Image的对象实例的创建,API上内存分配方法有两种派别。
一种是Vulkan的内存分配+对象绑定方式,一种是gles和metal的简单的对象创建方式。
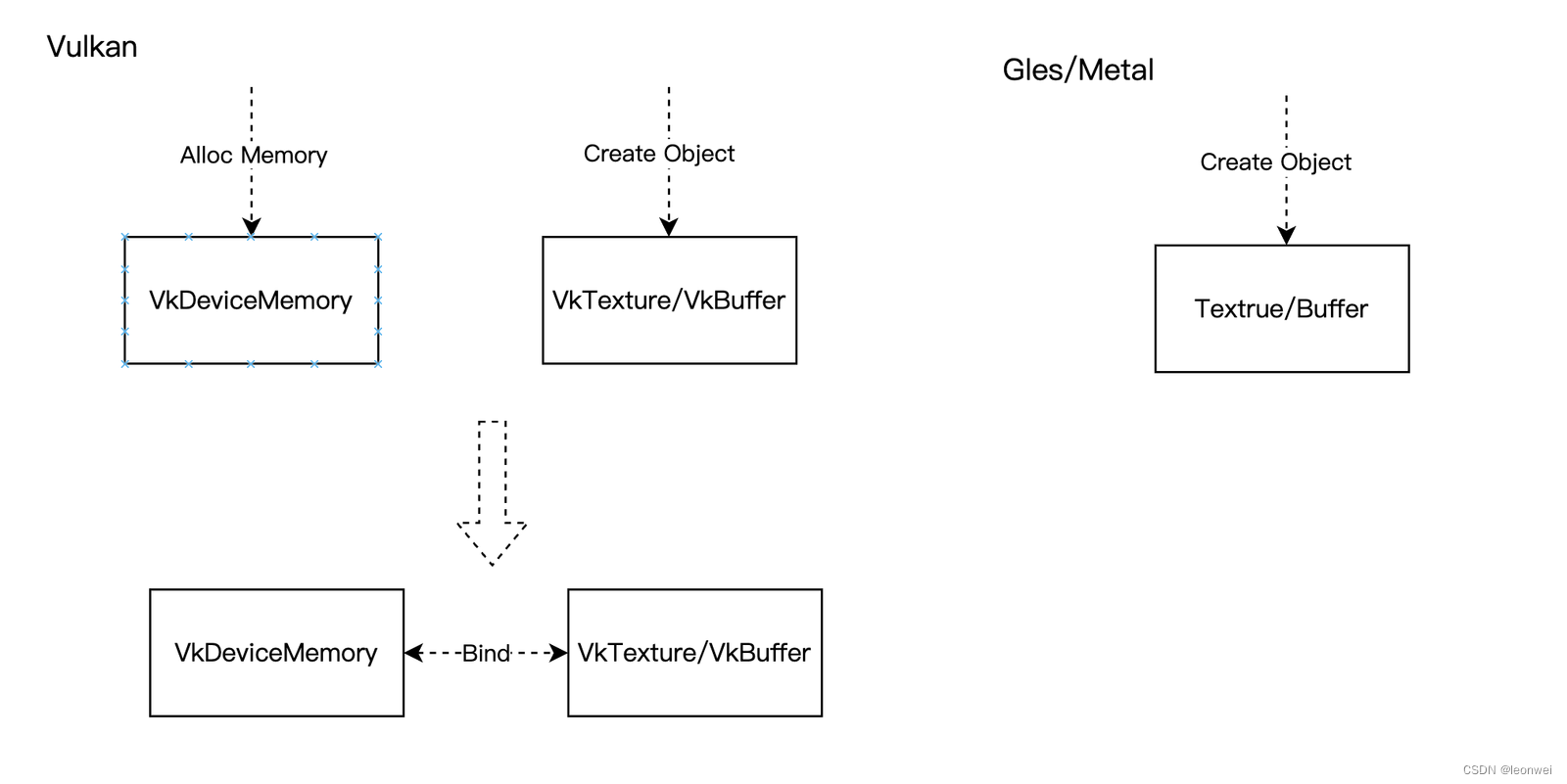
4.2.1 Vulkan
Vulkan上有单独的device内存对象VkDeviceMemory,vulkan上对于Texture和Buffer的内存,必须要先创建独立的内存对象(可以认为物理内存)和资源实例(只是资源描述),然后再将二者绑定。
内存对象分配
通过API vkAllocateMemory 在某个MemType的Heap上分配一个内存对象
VkResult vkAllocateMemory(
VkDevice device,
const VkMemoryAllocateInfo* pAllocateInfo,
const VkAllocationCallbacks* pAllocator,
VkDeviceMemory* pMemory);
typedef struct VkMemoryAllocateInfo {
VkStructureType sType;
const void* pNext;
VkDeviceSize allocationSize;
uint32_t memoryTypeIndex;
} VkMemoryAllocateInfo;
其中会指明需要的内存大小,以及这个memorytypeindex就是在前面vkGetPhysicalDeviceMemoryProperties查询到的memoryTypes中的索引,即某种类型的一个heap,即我们创建内存对象的时候就指明了这块内存的访问方式。
资源对象创建和内存绑定
有了内存对象后,对于image和buffer对象,通过对象创建的API vkCreateBuffer或vkCreateImage等创建出资源对象,最后通过API
VkResult vkBindBufferMemory(
VkDevice device,
VkBuffer buffer,
VkDeviceMemory memory,
VkDeviceSize memoryOffset);
VkResult vkBindImageMemory(
VkDevice device,
VkImage image,
VkDeviceMemory memory,
VkDeviceSize memoryOffset);
对资源和内存绑定。
资源只有绑定内存后才能使用,这里在创建内存对象时需要知道资源所需的内存大小,可以通过API vkGetBufferMemoryRequirements / vkGetImageMemoryRequirements 来计算。
资源对象一旦绑定内存后不能重新绑定,也不能解绑
我们也可以在创建VkMemory时自动为他绑定给一个buffer或Image,在VkMemoryAllocateInfo中有个pnext扩展参数,将它指向一个VkMemoryDedicatedAllocateInfo类型。
因为vulkan的资源和对象是分离的,你甚至可以将多个资源对象绑定在同一个vkmemory上,只要他们的内存确定是可以共享的,并能维护好使用的冲突。
4.2.2 Metal 和Gles
Metal上直接使用
- (id<MTLBuffer>)newBufferWithLength:(NSUInteger)length
options:(MTLResourceOptions)options;
和
- (id<MTLTexture>)newTextureWithDescriptor:(MTLTextureDescriptor *)descriptor;
这样的API创建buffer和贴图对象,同时为他们分配内存,在创建的参数中都需要传入MTLResourceOptions来指定内存的访问方式。
Gles上则一般是先创建对象,再为对像分配内存。
如对于buffer,先通过glBindBuffer()创建一个buffer对象,再通过glBufferData()创建和填充它的内容。对于Texture,先通过glBindTexture()创建一个贴图对象,再通过glTexImage2d()来创建和填充他的device内存。
4.2.3 Gles上额外的内存对象
Image和 Buffer抽象了Vulkan和Metal上我们可以自由操纵所有内存对象,Gles上则除此之外,还有一些额外的可以操纵内存的对象,这看上去是在此之上为了解决一些需求而打了很多补丁一样。它多了以下三种特殊的内存对象需要额外考虑。
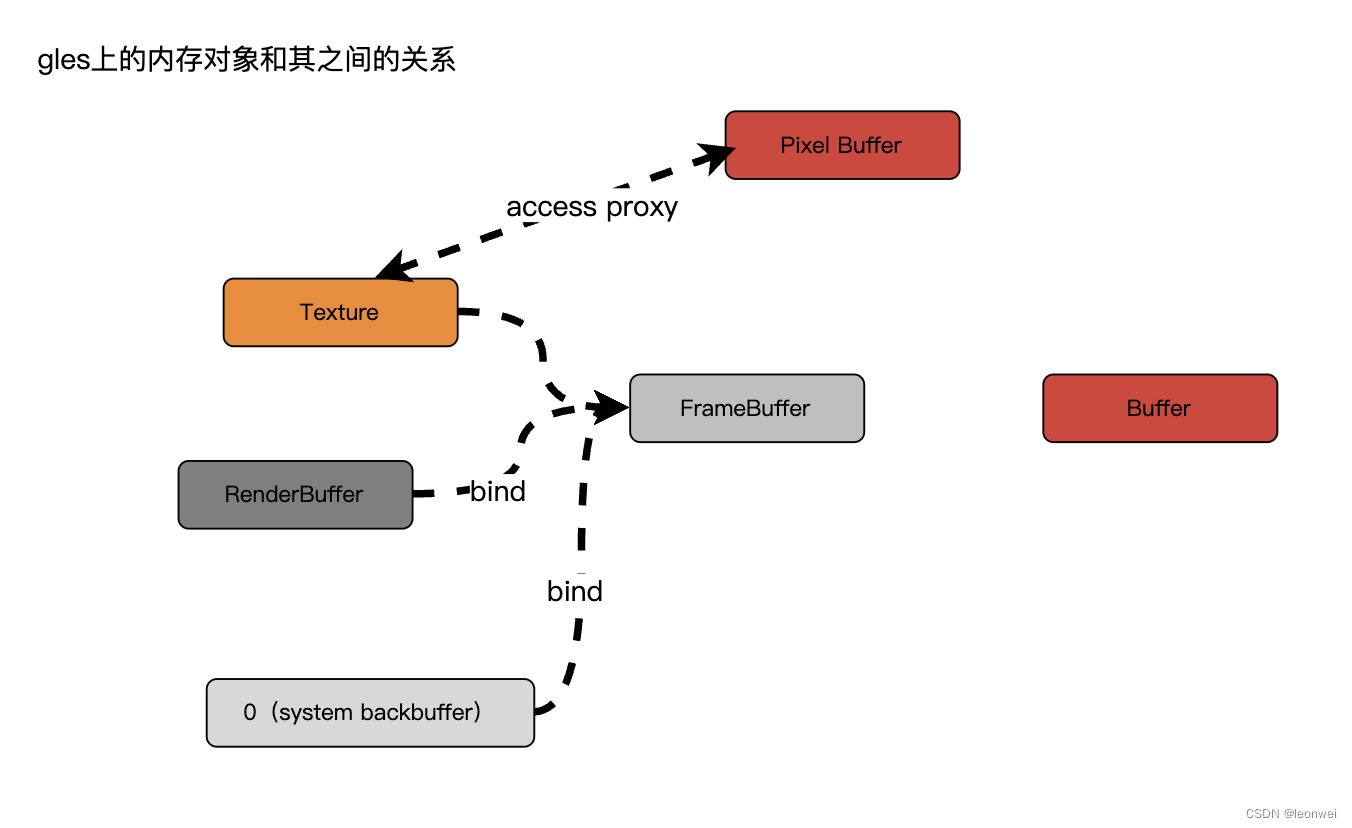
RenderBuffer
我们知道正常情况下,Framebuffer都是同一张Texture关联,但是在gles下抽象出来了一种可以不是texture的纯内存形式的buffer同Framebuffer关联作为其attachment,它被认为比texture更加的纯粹,它不是为了采样,专门为了做渲染目的地,主要基于两个需求:
- msaa渲染的硬伤,core API中不能将framebuffer渲染到一张multisample的texture上,可以渲染到一个multisample的renderbuffer上。
- 性能的提升,如果不考虑image的继续采样等,单纯做一个rt,那么性能比texture要好。
BackBuffer
此外在gles上不能直接拿到backbuffer的image对象,这就造成了无法读取backbuffer的困境,因为gles在渲染时将Framebuffer的texture bind到0就意味着使用系统的backbuffer。
所以在gles的API中允许直接从Framebuffer层面读写该Framebuffer的内存内容,以达到对系统的屏幕缓存(所谓的backbuffer)的访问,这种设计在vulkan和metal上不存在,因为vulkan 和metal上的backbuffer也是能够获取到的Image对象。
PixelBuffer
gles上的Image(texture)在设计之处不能自由的同Buffer交换内存,这也是个硬伤,因为我们知道CPU对RT的写入读取在多数情况最好不要直接进行,这样会导致CPU和GPU的强同步,一般的选择是现在GPU上device内存内部将RT 暂存到一个临时buffer上,等待合适的时机再从Buffer上读取内存回CPU,这需要texture和buffer传递内存的能力。
另外CPU对texture的写入,也可以先利用PBO将CPU内存写入到PBO,再从PBO拷贝到texure,在很多机型上要比直将CPU内存写入texture性能要好。
为了解决这个问题,gles 3.0版本又打了一个大大的补丁,引入了一种特殊的Buffer,注意它其实也是一个普通的buffer,应该算在buffer对象里面,只是有个特殊的类型flag叫做PIXEL_PACK_BUFFER和PIXEL_UNPACK_BUFFER,我们一般叫做Pixel Buffer Object。但是它在数据传输过程中作用特殊。
PBO基本用来做对Texture内存访问的一个代理人的角色,texture和frambuffer不能直接将数据拷贝或从buffer读取,但是可以先拷贝会从Pixel Buffer读取,再使用PBO同其他buffer打交道。PBO在API中通过一些标记触发到对他的使用。
4.3 Device内存的访问
Host内存的存储,访问都完全在Host一侧范围,所以管理上很简单,但是Device内存可能同时被Host和Device访问,尤其涉及到Device内存被Host访问,就要牵扯到复杂的机制。
对Deivce的内存数据访问一般有以下情况:
- Device(GPU)侧的read
- Device(GPU)侧 的write
- Device侧的copy
- Host(CPU)侧的read
- Host(CPU)侧的write
4.3.1 GPU Read Write
4.3.1.1 Access after Bind
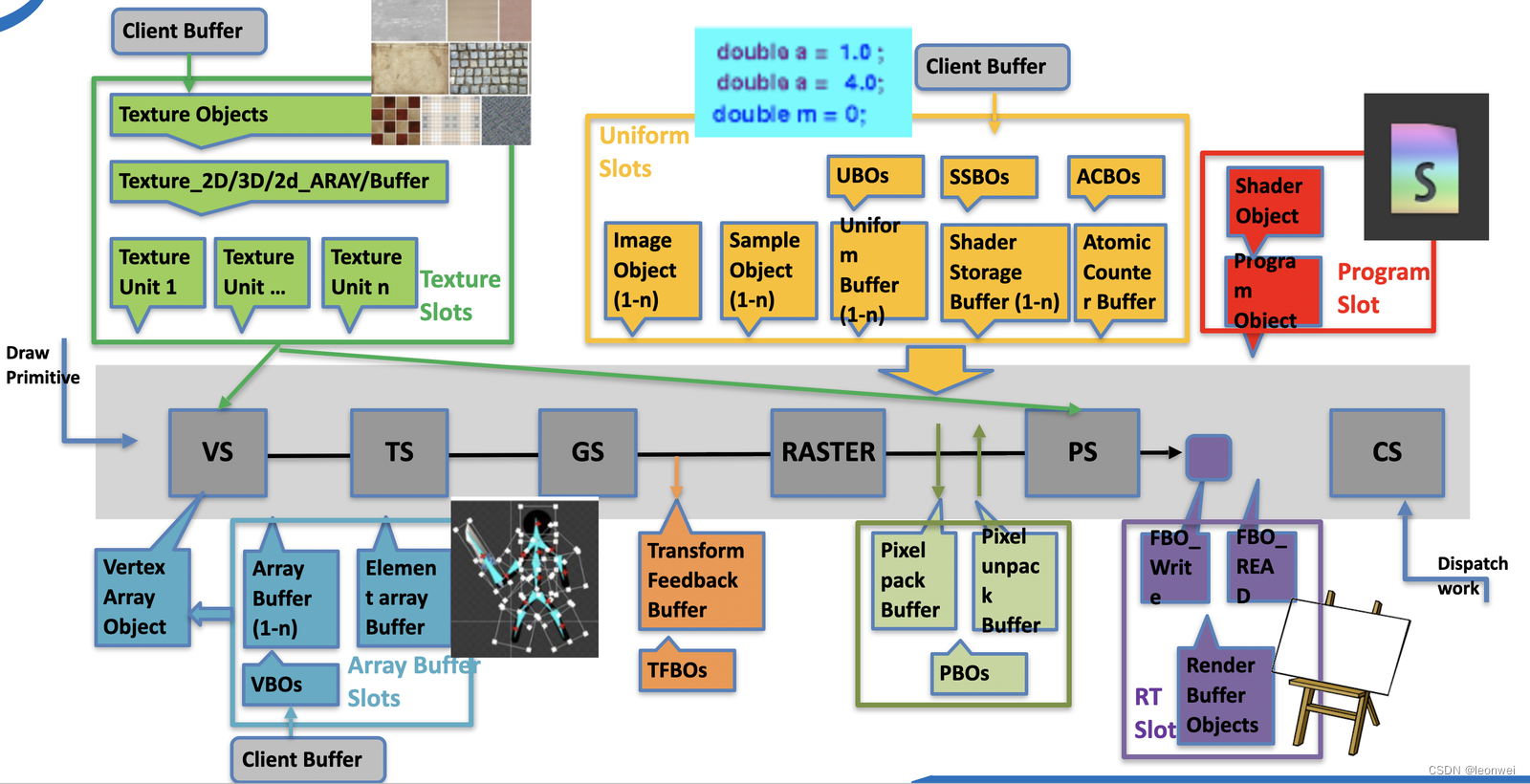
Device上的资源不同于Cpu上的,它存在一个设计好的硬件化的数据处理管线,管线上预留了一些资源绑定槽位,管线一般不能主动通过寻址的方式访问资源,一般都需要事先将对象绑定到相关位置上喂给管线才能被GPU访问。
如下图描述了基本的GPU管线上需要被绑定的槽位,上面的各种texture unit, uniform slots,arraybuffer ,都是需要我们主动绑定给管线的资源。
Read
GPU read是对device内存最原始最常用的访问情况,贴图创建后被采样,buffer创建后被索引,都是最常用的GPU使用方式,
例如对贴图的访问都需要先经过类似glBindTexture/vkCmdBindDescriptorSets/[MtlRenderCommandEncoder setFragmentTexture] 这样的API将image资源 Bind到管线某个Index的贴图位置上,shader中就可以对它采样。
而buffer也是利用类似的
glBindBuffer/vkCmdBindDescriptorSets/[MtlRenderCommandEncoder setFragmentBuffer] 的函数绑定后被读取
Write
资源通过一些API还可以绑定到gpu管线上被GPU写入,典型的情况包括:
- 作为renderpass的attachement被图形管线写入
- 在computer shader中直接在image或buffer的内存上写入
vs和ps里面一般只能发生资源的读,而不能写入。
4.3.1.2 Clear
对于Device资源,GPU还会发生一种特殊的写入操作,叫做Clear。将一个buffer 或Image的所有元素设置为某个值。
我们知道对于RT来说,通过把它绑定到renderpass上,然后设置renderpass的loadaction为clear,storeaction设置成store,设置好当前的clearcolor,然后启动这个renderpass,就可以做到对RT的clear,这种是基于图形管线的image clear。在一些API上提供了更简单的API。
Vulkan
对于Buffer,使用API
void vkCmdFillBuffer(
VkCommandBuffer commandBuffer,
VkBuffer dstBuffer,
VkDeviceSize dstOffset,
VkDeviceSize size,
uint32_t data);
注意可被clear的buffer需要带有VK_BUFFER_USAGE_TRANSFER_DST_BIT的创建参数
对于Image,如果想要在renderpass之外clear,使用API
vkCmdClearColorImage 和 vkCmdClearDepthStencilImage
注意此时的Image必须处于General或者Transfer_Dst layout
这里不能支持压缩格式的Image
如果想要在renderpass之内clear,使用API
vkCmdClearAttachments
这个API事实上是相当于发生了一个全屏的drawcall。
注意上述只有FillBuffer允许在单独的Transfer queue上执行。对于Image的clear仍然依赖于图形或计算管线。
Metal
metal上的Image只能通过设置renderpass进行clear,对buffer的clear可以使用
MtlBlitCommandEncoder中的API
- (void)fillBuffer:(id<MTLBuffer>)buffer
range:(NSRange)range
value:(uint8_t)value;
Gles
gles上的Image只能通过设置成rt进行clear,对于buffer也没有很有效的API进行clear,只能通过glBufferData重新设置某个buffer的数据内容,注意如果glBufferData的中的地址设置为null,不代表clear,而是代表这段buffer没有初始化。
4.3.1.3 BindLess
更现代的API允许对texture 和buffer不事先绑定在管线上,而直接通过device内存上的地址对它进行读写,这种资源访问形式叫做bindless
vulkan在1.2版本之后正式支持buffer_device_address特性,通过APIvkGetBufferDeviceAddress可以获取到一个VkBuffer的device上的内存的64bit指针(不是handle,是直接的显存指针),在shader中,可以直接用这个指针访问buffer内存。
metal上则在1.3之后允许我们直接讲对texture和buffer的访问提前录制到Indirect Command Buffer中,以达到使用时不用预先bind。
4.3.2 GPU Copy
device上有一种特殊的经常发生的对device内存的读写操作,叫做copy,我们单独分析。
Copy的过程还可能从一种形式的对象到另一种形式,如从Image copy到Buffer。
Vulkan和metal上的device一侧数据传递接口简洁优雅,非常简单,不过gles上反而是非常繁杂的一块内容。
4.3.2.1 Vukan
vulkan下面的API非常明确,提供了4大类直观的API完成内存在Image和Buffer之间的两两组合形式的拷贝。
Buffer 到Buffer:
- vkCmdCopyBuffer2 将A buffer的某个region拷贝到B buffer的某个region
- vkCmdUpdateBuffer 这也叫做Inline copy,它将待源数据直接写入到Command Buffer中,然后copy 给vkbuffer对象,更加快速,但是数据必须足够小,一般小于64k。
Image 到 Image:
- vkCmdCopyImage2 将A Image的某个mip的某个区域拷贝给B Image,单纯内存数据传输
- vkCmdBlitImage 允许再不同的格式,缩放,贴图filter(点采样,和线性采样)之间拷贝,这不是单纯到数据搬运,还会对image数据做重解析,不支持multi sampled
- vkCmdResolveImage 用于Multisample image的resolve,即将一个多重采样的Image按解析成单采样的
Buffer 到Image:
- vkCmdCopyBufferToImage
Image 到Buffer:
- vkCmdCopyImageToBuffer
上面这两个也常用与CPU读写Image的操作,这时一般都需要先讲Image同Buffer之间转换。
此外要注意,在上面Image的拷贝过程中,Image的layout都需要提前根据作为copy到源和目的设置为VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL或者VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL。
另外所有的这些Device侧的copy指令的record一定要发生在renderpass之外,即他们的renderpass scope是OutSide的。
上述所有API都支持在Graphic/Compute/Transfer中任何一种queue中提交,也就是说这些GPU上的数据Copy可以放在一个单独的Transfer queue中执行。
4.3.2.2 Metal
metal下进行Device侧的数据copy要将其放在BlitCommandEncoder里面,即它也是同常规的渲染的RenderCommandEncoder分离开的。(Encoder的部分见我们前一个章节内容)。
BlitCommandEncoder里面封装了两个函数实现所有功能:
- copyFromBuffer 将一个buffer内存copy 到另外一个buffer或texture
- copyFromTexture 讲一个Texture内存copy 到另外一个buffer或texture
4.3.2.3 Gles
基于前面提到的gles上多了几种需要考虑的内存对象的,所以实际上要关心Buffer,Image,RenderBuffer,Framebuffer,(pixel)buffer 这5种类型资源之间的数据传递,涉及的API繁杂,API命名形式也互相没有什么关系,很考察记忆力,我们下面来捋一下.
buffer之间的拷贝
- glCopyBufferSubData(GLenum readtarget, GLenum writetarget)
gles上的buffer若想发生数据copy,和渲染一样,必须也bind到管线上,因此这里需要指定的src和dst并不是某个具体的Buffer对象,而是管线的默认绑定点,例如 GL_UNIFORM_BUFFER, GL_ARRAY_BUFFER,但是为了copy把两个buffer绑定到关系上,事必占用了本该用作渲染点槽位影响现有管线状态,因此gles定义了两个专门用于copy的管线绑定点GL_COPY_READ_BUFFER和GL_COPY_WRITE_BUFFER,我们通常在copy之前需要把copy的src和dst绑定在这两个位置,但是记住他们绑在其他有意义的绑定点也可以。
Image 之间的拷贝,RenderBuffer之间的拷贝,Image和RenderBuffer之间的拷贝
- glCopyImageSubData
用于在两个Texture和Renderbuffer之间做拷贝,它是一个单纯的内存拷贝,所以甚至两边尺寸不一样,但是总大小一致也可以完成,但是需要internal format是compatible的(这个具体要查阅文档)。
但是注意到renderbuffer使用的internalformat只能是可以渲染的,因此这里只能够支持那些可以作为rt的格式的textrure和renderbuffer之间的拷贝,压缩格式等都是不行的。
FrameBuffer 之间的拷贝
- glBlitFramebuffer
需要将src framebuffer绑定到 read framebuffer上,将dst framebuffer绑定到 draw framebuffer上。
FrameBuffer到Image的拷贝
- glCopyTexImage2D
剩下两种涉及到Texture的copy都需要Pixel Buffer的参与了
buffer到Image的拷贝
只能从PIXEL_UNPACK_BUFFER 的buffer拷贝到texture
所以需要先
- 将一个buffer绑定到_BUFFER,调用 glCopyBufferSubData 将待拷贝buffer拷贝到PIXEL_UNPACK_BUFFER
再用
- glTexImage2D
这个接口,这个API本身是用来从CPU地址写入texture的,如果将其中的CPU地址设置为0,则意味着从当前的绑定的PIXEL_UNPACK_BUFFER 写入数据到texture。
Image 到 buffer的拷贝
gles只能从当前的framebuffer拷贝数据到PIXEL_PACK_BUFFER 。所以这里的步骤就会很多,需要三步,且如果texture不是一个支持做RT的format,那不能进行
- 将Image绑定到Framebuffer,并将Framebuffer绑定到当前的read framebuffer
- 将一个buffer绑定到PIXEL_PACK_BUFFER,调用glReadPixels API
这个API本来是用来从当前的read framebuffer读取数据到CPU 内存的,但是如果其中的CPU地址填写为0,他将拷贝到当前绑定的PIXEL_PACK_BUFFER
- 用glCopyBufferSubData从PIXEL_PACK_BUFFER拷贝到目标buffer
Framebuffer到buffer的拷贝
其实就上面Image 到 buffer的拷贝的后两步。
RenderBuffer到Buffer的拷贝
同Texture 到 buffer的拷贝。
4.3.3 CPU Read Write
4.3.3.1 Device内存的访问类型
因为Device内存本来是在Device上的,如果被CPU读写,那么就会痛GPU读写产生冲突,
还涉及到数据同步的效率问题,为了解决这个问题,不同的API设计了不同的Device—Host共同访问的策略,但是从根本上,从跨越API的角度上,我们把device内存的访问类型,大致可以抽象为以下5大类。
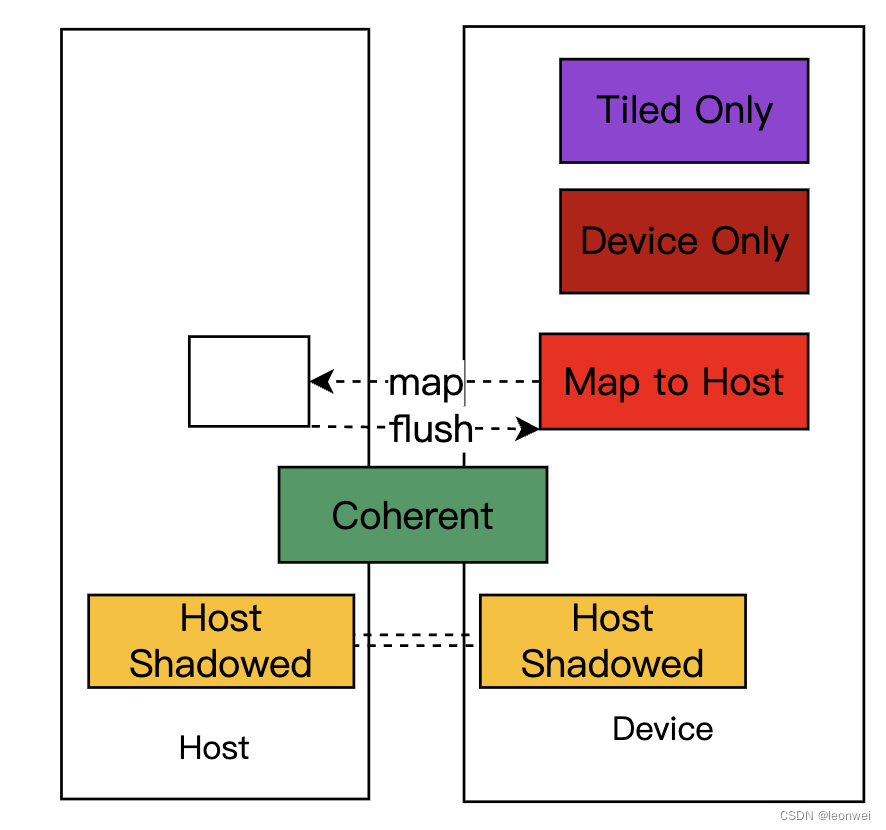
- Tiled Only:最简单高效,只能在tile上被访问,这部分内存只存在于gpu cache上,生命周期只局限在tile上,这部分内存可以认为不占用我们的系统内存,这是移动端TBDR架构下的特有内存。
- Device Only:这部分内存只能被Device访问,完全在GPU一侧,也很快。
以下三种策略都是host 可访问的:
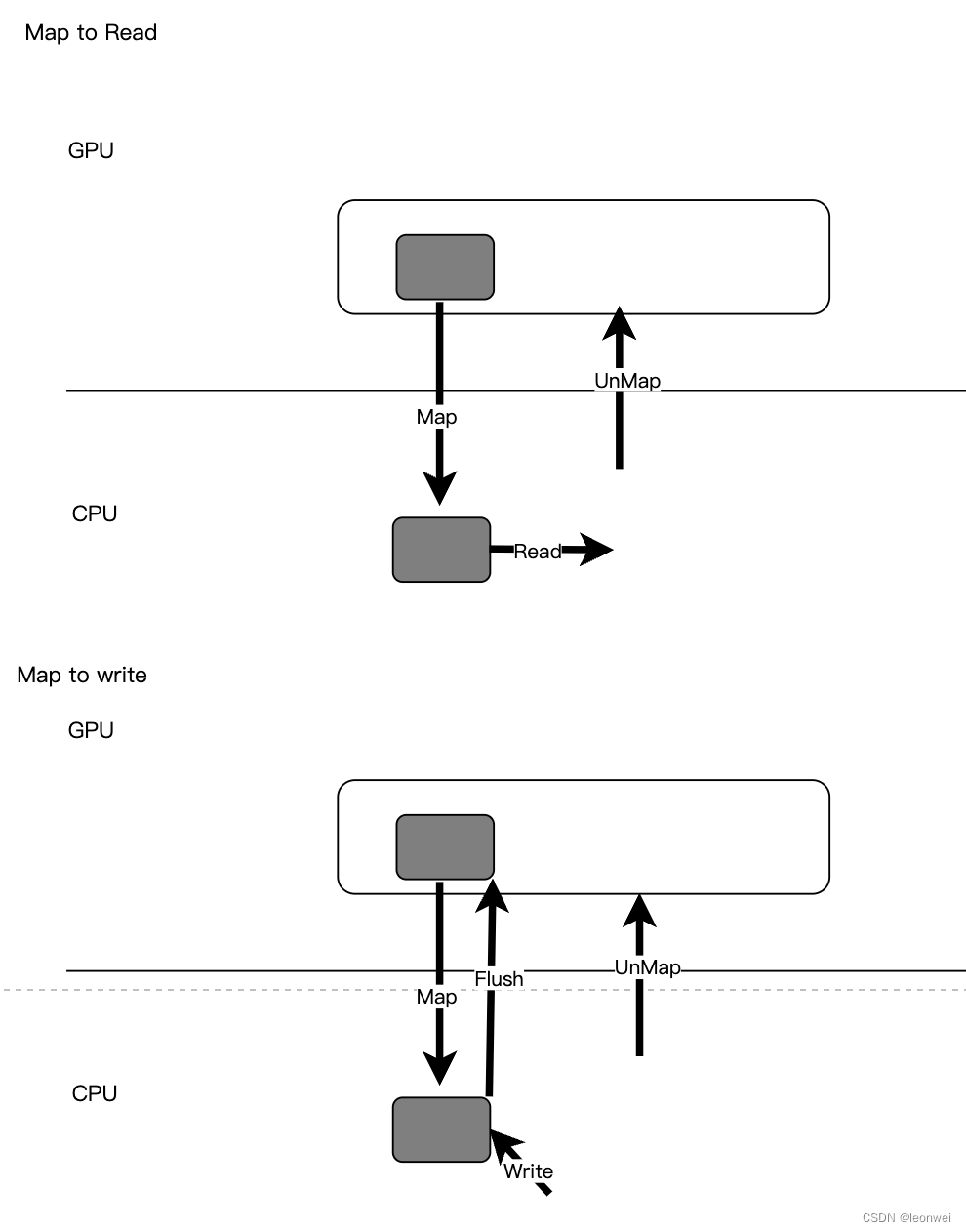
- Map to Host:Device内存通过显示的接口Map/unmap暴露给Host,Host写入之后通过 接口Flush更新Device内存, 这是最经典的方式,它兼顾了两侧的访问效率,也是gles上唯一的方式。
在实现上,一般会有一个显示的Map和Unmap接口,用来把一段device内存暴露出来, 这个map和unmap可以完全block住GPU对这段内存的使用,也可以不block住,map之后,Host就可以读取这段内存,也可以直接在上面写入,当写入完成,通常还需要一个flush接口,将写好的内容同步给Device。以下是Map to read/write的工作原理
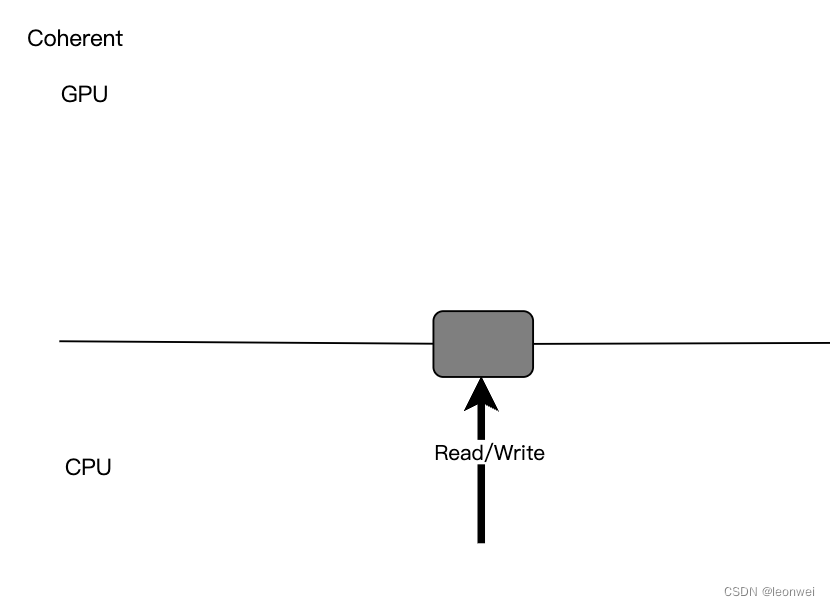
- Coherent:这个一般只存在于移动端硬件上,因为移动端的host和device的内存在物理上可以是在一起的,Host和Device共享这块内存,这个内存可以同时被host和device访问,任何一端对其修改都是即可对另一端产生了影响,这种对于两侧共同访问情况下使用方便,但是对device这一侧来说性能可能比Map to Host这种实现更差。
这种内存的访问一般没有显示的API,CPU一侧可以直接读写这块内存,但是要主动的做好CPU和GPU对这块内存的访问冲突,保证不会发生同时读写的情况
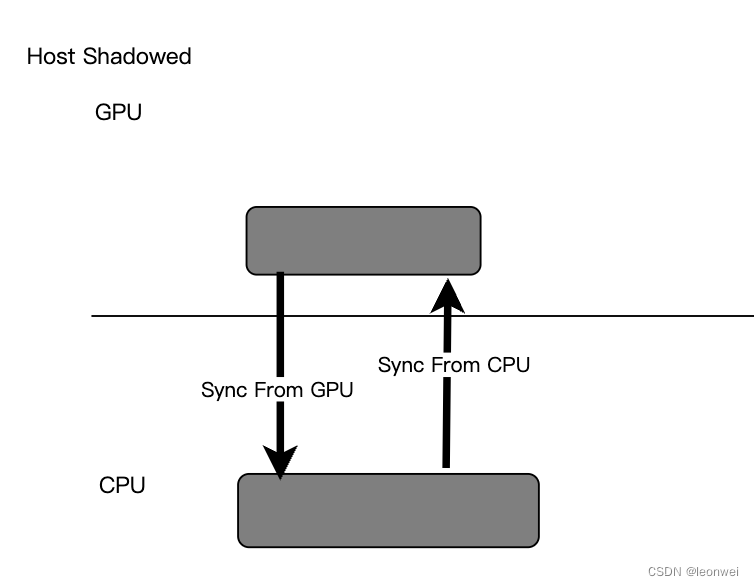
- Host Shadowed:这种类型常见在PC硬件上,更优化于Host的访问,一般驱动内在Host一侧提供一个同样大小的内存,同device一侧在某些时刻拷贝数据,使得host一侧的读取更快速,但是一般需要逻辑去显示的同步这两份内存,GPU的sync同步之后一般会给CPU一侧一个回掉或者event,两边的访问效率都很高,但是内存消耗较高。
对应于不同的API,都是基于上面5中策略实现了不同的API
Vulkan
vk上的device内存被分成多个MemoryHeap,每个Heap 又被按照所支持的访问类型的不同分成多个 memory type, 一个VkMemoryType就是vulkan上一个Heap上的支持一种特定访问类型的内存堆,因为在vulkan上分配的内存的API则必须指定其所在的VkMemoryType,我们需要首先查询出来当前设备含有的所有VkMemoryType,
通过API vkGetPhysicalDeviceMemoryProperties 查询
void vkGetPhysicalDeviceMemoryProperties(
VkPhysicalDevice physicalDevice,
VkPhysicalDeviceMemoryProperties* pMemoryProperties);
其中的包含了所有heap和type的信息。
typedef struct VkPhysicalDeviceMemoryProperties {
uint32_t memoryTypeCount;
VkMemoryType memoryTypes[VK_MAX_MEMORY_TYPES];
uint32_t memoryHeapCount;
VkMemoryHeap memoryHeaps[VK_MAX_MEMORY_HEAPS];
} VkPhysicalDeviceMemoryProperties;
typedef struct VkMemoryType {
VkMemoryPropertyFlags propertyFlags;
uint32_t heapIndex;
} VkMemoryType;
// Provided by VK_VERSION_1_0
typedef struct VkMemoryHeap {
VkDeviceSize size;
VkMemoryHeapFlags flags;
} VkMemoryHeap;
这个结构要先看memoryHeaps,包含了所有的device memory heap,而每个heap可能包含多种类型不同的memory type,在memorytypes中描述了它的type和归属于哪一个heap,heap和type是一对多的关系。
不同的memtype则对应了不同的访问类型,通过属性中的VkMemoryPropertyFlags枚举定义,值有如下:
VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT :它并不是单纯绝对的device only,而是更倾向为device访问做了优化,他可以同HOST_VISIBLE连用,同时给host访问。
VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT : Map to Host的。
VK_MEMORY_PROPERTY_HOST_COHERENT_BIT :Coherent的,需要同HOST_VISIBLE连用
VK_MEMORY_PROPERTY_HOST_CACHED_BIT :host shadowed,需要同HOST_VISIBLE连用,也可以同时叠加HOST_COHERENT使用。
VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT :tiled only的,需要同device local连用,只能bind给带有useflag VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT的image。
VK_MEMORY_PROPERTY_PROTECTED_BIT :需要同device local连用,允许 protected queue访问
Metal
Metal通过MTLResourceOptions 这个枚举来定义不同的内存访问类型,这个枚举值参数被用于metal上texture和buffer创建的API中。
MTLResourceStorageModeShared: coherent的,这也是metal在移动端texture和buffer默认的内存访问方式
MTLResourceStorageModePrivate:device only
MTLResourceStorageModeMemoryless: tiled only
MTLResourceCPUCacheModeDefaultCache:对于host 可访问的内存,默认的host 一侧的cache方式,可以保证读写顺序
MTLResourceCPUCacheModeWriteCombined:对于host 可访问的内存,专门优化为在host一侧CPU只写不读的cache方式
只有PC端的metal上有host-shadowed这种访问方式,叫做MTLResourceStorageModeManaged,移动端不做讨论
Gles
Gles上不能指定一个device 内存的访问方式,也可以理解成gles上device 内存全都是host 可见的,可被host访问,也没有太多专门的优化,只能通过一些扩展来支持堆tile 内存的使用。
用一张表格横向对比各个平台设置device 内存访问方式的情况
| 访问策略\平台 | Vulkan | Metal | Gles |
| Tiled Only | VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT | -- | |
| Device Only | VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT | -- | |
| Map to Host | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | -- | ALL |
| Coherent | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_COHERENT_BIT | ||
| Host Shadowed | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_CACHED_BIT or VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_CACHED_BIT|VK_MEMORY_PROPERTY_HOST_COHERENT_BIT | -- | -- |
可以看到如果想让一个device内存被host访问,在vk上即可以选择map策略,也可以选择coherent策略,还可以选择shadowed策略,并且在一些平台甚至可以选择同时是coherent和shadowed,在移动端上,如果是频繁的host访问,倾向使用coherent,如果是偶尔,那么倾向map策略,如果是metal,只能选择coherent策略,如果是gles,只能选择map策略。当然如果这个内存只是非常非常偶尔的被host访问一次,还可以尝试使用device only策略,只有当host访问时,将其在gpu上拷贝到另一个coherent的内存上。
4.3.3.2 平台API实现
Metal
Metal在移动端只有Coherent一种方式,即StorageModeShared,对于buffer可以直接访问MtlBuffer的Contents接口进行读写。对于Image,使用MtlTexture的GetBytes进行CPU读,使用MtlTexture的ReplaceRegion进行CPU写入。
Vulkan
Vk有全部都三种方式可以选择:
如果使用Map方式:在VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT的hep上创建内存,一般先用 VkMapMemory()将一段内存map出来,然后可以对于上面的内存读写,如果是写入的情况,写入完成后要 vkFlushMappedMemoryRanges 将它同步给GPU,如果map之后GPU上的内存发生变化,也需要vkInvalidateMappedMemoryRanges 将GPU上的修改重新同步给CPU,操作完成后使用VkUnmapMemory释放掉CPU的使用。
注意直接Unmap不代表会发生flush操作。
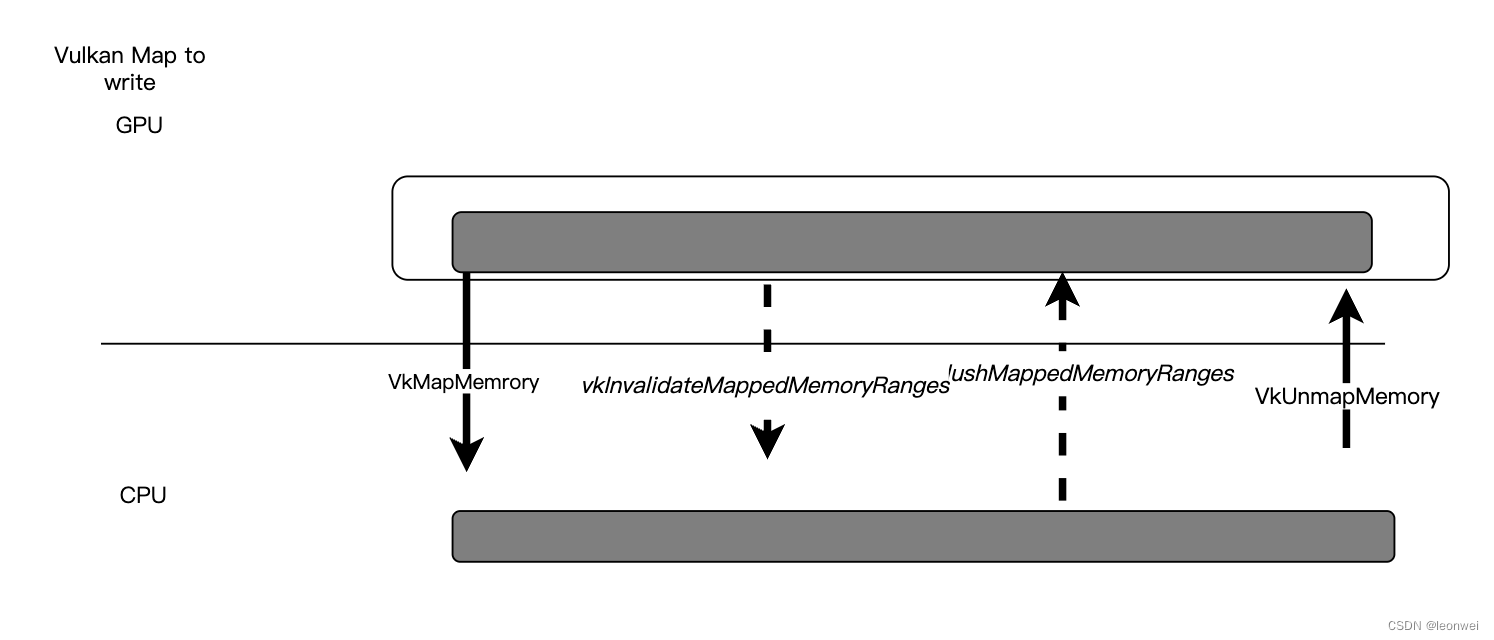
如果使用Coherent方式,在VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_COHERENT_BIT的heap上创建内存,则不需要上面的flush和invalidate操作,但是还是需要把内存map出来操作,但是Host的读写会直接影响到device的内存
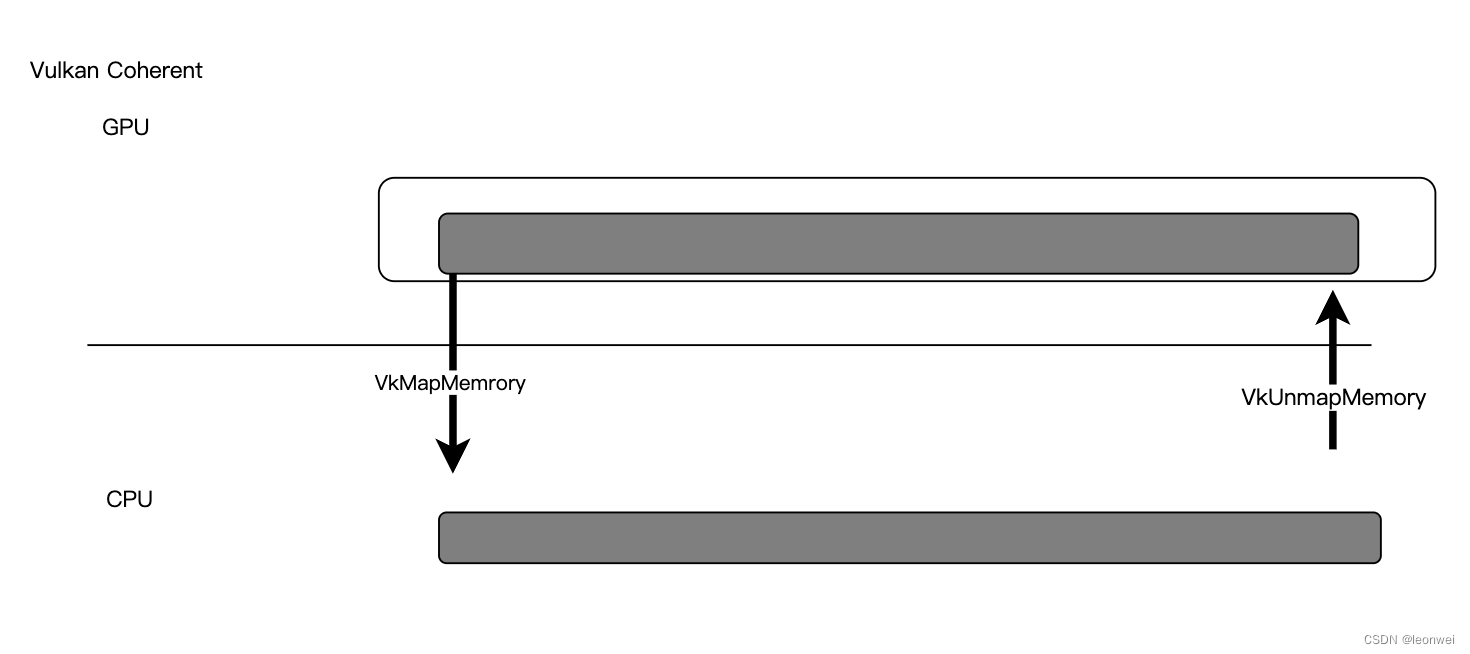
如果使用shadowed方式(多数移动端可能不支持,也不推荐),在VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_COHERENT_BIT的heap|VK_MEMORY_PROPERTY_HOST_CACHED_BIT 上 或者是VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT|VK_MEMORY_PROPERTY_HOST_CACHED_BIT的heap上创建内存,也就是说这个内存可以同时使Coherent和Shadowed的,如果同时是Coherent那么访问方式同上面的Coherent,否则访问方式同map,但是这里的CPU访问要更快,因为Host一侧会存在一个Cache,当然也存在一个内存开销。
虽然Vulkan下面对Buffer和Image都可以用相同的VkMapMemory来进行CPU的写入,但是对于Image数据来说,因为其存在特殊的格式和对其规则,直接的内存写入是比较困难的,一般还是通过先将CPU数据写入到Buffer,再用 vkCmdCopyBufferToImage这样的API 从Buffer拷贝到Image的方式,因为这种API中可以指定待写入的image范围,mip等信息。同理对Image做CPU读取,也是一般先用vkCmdCopyImageToBuffer,再从Buffer中读取。
Gles
Gles上对于CPU-GPU的同时读写从驱动上为我们做了很多封装,用一些枚举给了我们一些策略选择,我们面对一个高度封装的策略时,就反而需要弄清楚不同策略下的性能问题,同时正因为这些策略参数,反而让gles的cpu读写规则显得更加复杂。
首先是Buffer的CPU读,gles只有map方式,使用
void *glMapBufferRange( GLenum target,
GLintptr offset,
GLsizeiptr length,
GLbitfield access);
将buffer的一部份内存map出来,map出来的内存既可以进行读写,通过 FlushMappedBufferRange 将写入的内存通知给Device,不过同vk不同的是,map之后device上对内存的修改没有接口再反馈给Host,你需要重新unmap,map。
这里的access非常重要,它决定了这个内存是否可写,flush的机制,以及同步机制。
- 读和写
- MAP_READ_BIT :可以被CPU读
- MAP_WRITE_BIT: 可以被CPU写
- flush机制
- MAP_FLUSH_EXLICIT_BIT:同MAP_WRITE_BIT连用,标记这个内存CPU写入之后必须调用flush才能同步到device,如果没有这个标记,unmap会自动出发flush。
- 同步机制
默认情况下,gles在map之前会等待GPU上所有对当前buffer的读写操作完成,也就是自动为我们做了一个GPU-CPU同步,因此这个API很有可能在CPU上造成block影响性能(你需要考虑使用下一小节提到的new-and-copy或者double buffer策略来优化性能)。
但是我们可以设定如下标记来不使用这个同步,这种情况不会卡住CPU,但是我们要自己保证逻辑正确。
-
- MAP_UNSYNCHONIZED_BIT
- Invalidate优化
在map的时候,API可以暗示硬件这段内存已经被HOST标记且马上要被HOST改写,不需要继续维护这段内存的内容,提升性能。
-
- MAP_INVALIDATE_RANGE_BIT: 同MAP_WRITE_BIT连用,标记这段被map的内存的内容完全失效
- MAP_INVALIDATE_BUFFER_BIT: 同上面标志类似,只是标记整个buffer都失效了。
我们还要注意的是map返回的这段内存地址只能被直接读取,写入,不能作为地址传给其他API继续使用(如glbufferdata)。
对buffer的CPU写入除了上面提到的map方法之外,gles还提供两个API。
- glBufferData,即buffer的初始化API,buffer初始化时可以指定一个cpu上的内存地址, 将其copy到gpu上 ,因为这个是初始化的时候调用,所以不用考虑CPU-GPU同步的问题。另外glBufferData也可以反复的对一个buffer调用,以重新写入这个buffer内容,这时候使用glBufferData而不是glMap可能会带来一个性能优化,如果你确定这个buffer内容已经立即无效了,glBufferData将不考虑任何同步,直接使当前buffer全体内容标记为失效,立即重新写入。
- glBufferSubData,可以将Buffer的特定区段内容更新。 有了glmapbuffer,为什么还定义这个函数?它相当于为更新buffer这件事情做了一个更加简便的函数,使用map我们需要完成map,copy,flush,unmap的一系列操作,这个就更加简便,且不用考虑同步问题,驱动会在何时的时候将cpu数据更新到device。不过从性能考虑出发,如果是对一个buffer做连续的更新,尤其是较大的buffer,那么将其map下来被认为是效率更高的。
gles 上buffer被CPU访问的其他优化
直观上gles只提供了map这一种CPU读写的方式,但是gles在调用对buffer做初始化的API
void glBufferData( enum target, sizeiptr size, const void *data, enum usage );
的时候,其中传入的usage这个枚举值其实暗藏了让硬件对buffer的CPU读写做更多优化的可能,但是无论这个值传入什么,都要清楚这个值只是一个给驱动实现的hint,不是必然会发生的。
这个值有如下定义:
- STREAM_DRAW :cpu只会初始化写入一次,然后被GPU使用一些次数但又不是很频繁,这可能暗示驱动用类似device only的方式去优化。
- STATIC_DRAW :cpu只会初始化写入一次,然后被GPU使用大量次数,多数用于渲染绘制的buffer,这可能暗示驱动用类似device only的方式去优化。
- STREAM_READ :这个内存会从gpu上copy数据初始化一次,然后被cpu读一些次数,用于cpu回读的buffer,这可能暗示驱动在host一侧cache这个数据。
- STATIC_READ::这个内存会从gpu上copy数据初始化一次,然后被cpu频繁读取,用于cpu回读的buffer,这可能暗示驱动在host一侧cache这个数据。
- STREAM_COPY :这个内存会从gpu上copy数据初始化一次,然后被gpu使用一些次数,用于来自copy数据的用与GPU绘制的buffer,这可能暗示驱动用类似device only的方式去优化。
- STATIC_COPY :这个内存会从gpu上copy数据初始化一次,然后被gpu频繁使用,用于来自copy数据的用与GPU绘制的buffer,这可能暗示驱动用类似device only的方式去优化。
- DYNAMIC_DRAW :这个内存可能反复的被CPU写入,又被GPU频繁读取,这是一个更新频繁的绘制用的buffer,这可能暗示驱动用类似map或者shadow的方式去优化。
- DYNAMIC_READ :这个内存可能反复的GPU上copy得到数据,又频繁的被CPU读取,这是一个频繁用于CPU查询的内存数据,这可能暗示驱动用类似map或者shadow的方式去优化。
- DYNAMIC_COPY :这个内存可能反复的GPU上copy得到数据,又频繁的被GPU使用,这是一个频繁的从另外一个buffer获得内容的用于绘制的buffer,这可能暗示驱动用类似device only的方式去优化。
对于buffer的CPU读写一定要注意选用合适的access和usage参数。
gles对Image的读写
Gles上使用glTexImage*D来从CPU写入Texture数据
Gles上没有一个简单直接的机制让CPU读取Image的数据,但是提供了接口glReadPixels读取Framebuffer上的数据回内存。glReadPixels又是一个会强行同步当前整个GPU指令完成的函数,性能消耗较大。
所以对于一般Image的cpu读取,如果是支持作为RT类型的Texture,可以先通过前面章节描述的将其copy到RBO,在通过glReadPixels读回,而非RT类型的Texture没有运行时方法,因此gles上做CPU读Image不是常规操作,应用应该在CPU一侧做好cache。
4.3.3.3 CPU-GPU的读写同步
前面提到的所有CPU读写Device内存的API都不会考虑当同GPU共同访问时的读写同步问题。这些API一般都不是指令缓存形的,都是立即被执行的。
所以你都需要完全自己保证资源不同时被CPU和GPU同时访问,如果你不保证,那么内存上的内容就是不被保证的。你需要保证:
- CPU 读时,之前提交的所有会产生的GPU对这块内存写入的操作都已经被执行完成。
- CPU写时,之前提交的所有会产生的GPU对这块内存写入和读取的操作都已经执行完成。
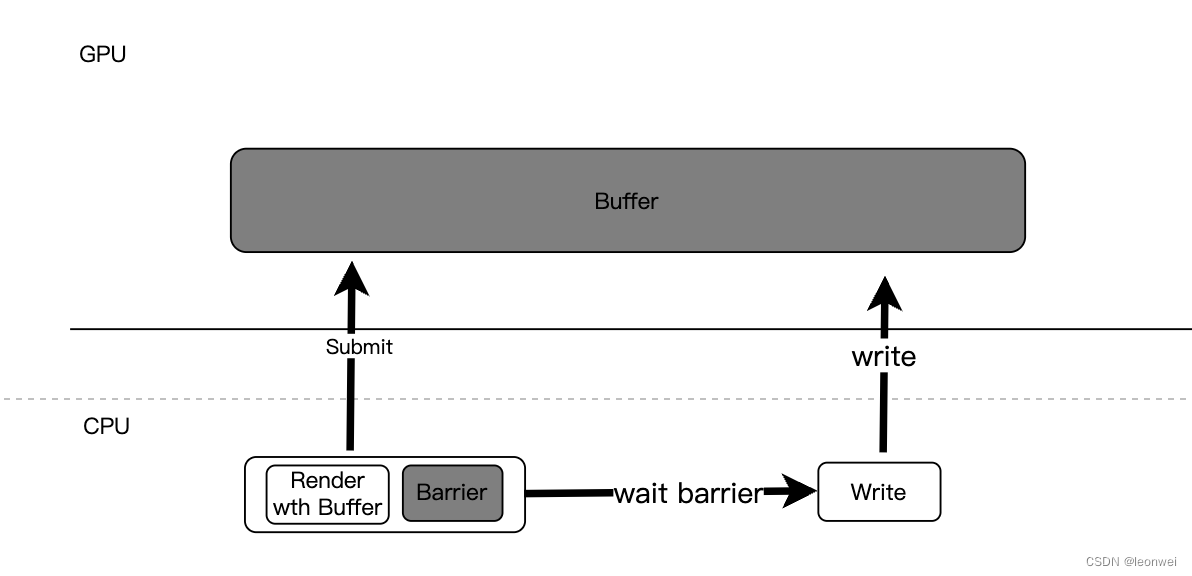
如下图,这种cpu侧的write在之前一个gpu的read之后发生,那么一般都需要在前面的操作之后加一个barrier(vk上的fence/semaphore,metal上的sharedevent,gles上的SyncObject),等cpu测等待到这个barrier之后才能去write。
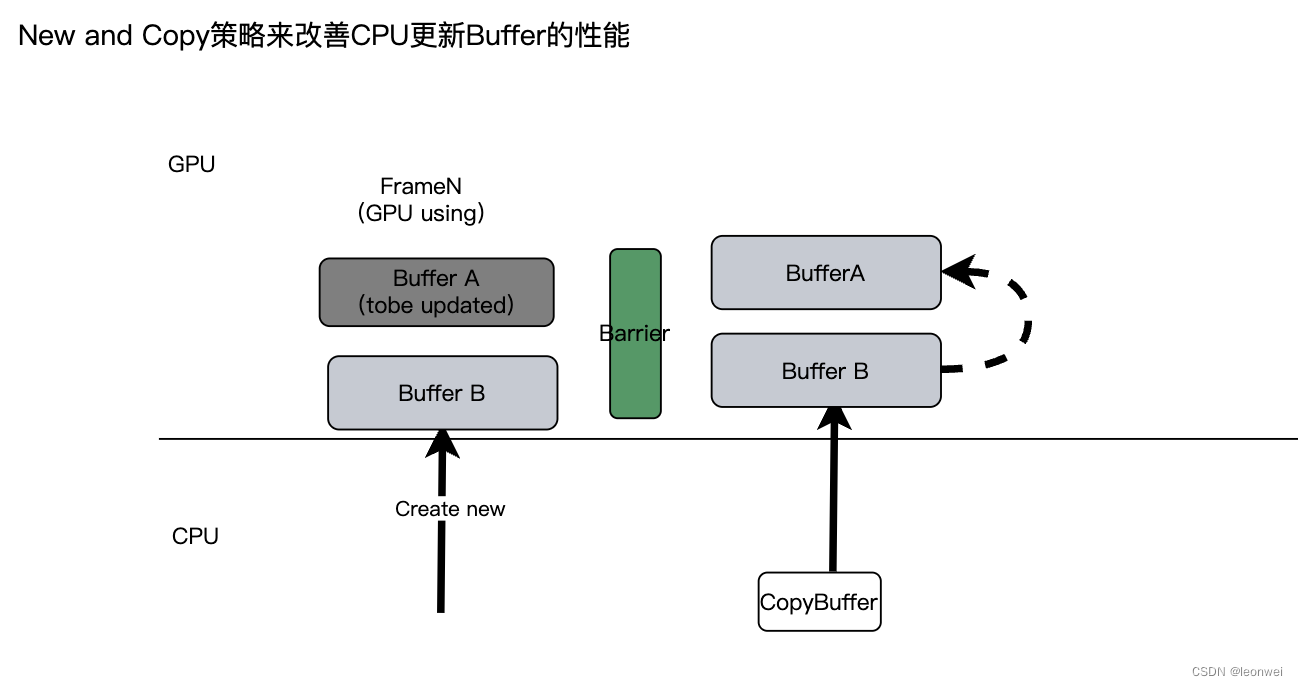
当然有时为了避免CPU产生这种等待,有也可以创建一个新的buffer共CPU写入,然后写入后,加一个GPU上的buffer copy指令推入指令缓存(当然中间要加一个barrier保证指令执行顺序),那当GPU用完老的buffer后,自然将其copy到老的buffer上,本文称为New-and-Copy策略,这种也是典型空间换时间的策略。
有时如果这种CPU的修改是每帧连续进行下去的,还可以选择使用双缓存策略,如奇数帧CPU往buffer A写入,GPU读buffer B,偶数帧CPU往buffer A写入, Gpu读buffer B,GPU的读总是延迟一帧。

4.4 Pixel Format
Buffer内存因为是一段简单的某种基本类型的数组,所以它的组织形式可以不多做讨论,但是Image内存都有其特定的数据组织格式,也就是我们通常所说的贴图格式,由于这个格式对于device上内存的组织和操作也很重要,比如前面在讨论image之间的GPU拷贝时,提到过需要遵循image 格式的相互适配性,我们需要专门讨论下各个平台上Image的格式问题。
4.4.1 Pixel Format
在API中,对于image的内存格式,一般会抽象出一个范围更大的概念,pixel format,因为它不仅仅用于表达Image的格式,还用与和image数据传输行为等涉及到的格式概念。
Pixel Format通常由data type和format 两个属性组成:
4.4.1.1 data type
它用来描述传输时这个单位数据被看待成什么类型,是一个int的数组?还是float的?data type 还可以进一步分成两种
基本类型
包括UNSIGNED_BYTE/ BYTE/HAL_FLOAT/FLOAT/UNSIGNED_SHOT/INT/...等这种基本的数据结构,byte是1字节,half和short是2字节,int和float是4字节。
packed 类型
这些type虽然逻辑上是多个通道数据,但是存储上被pack到了一个单位数据,如以下这些
- pack成一个ushort,如rgb565,rgb4444
- pack 成一个unit,如bgr10a2,depth24stencil8,rg11b10float,rgb9e5float等
在上述pack的数据中,每个单个通道数据都会被解释成一个无符号整数,除了一些特例会解析成float
- depth24stencil8中第一个24位解释成float
- rg11b10float中每个通道解释称10或11bit的float
- rgb9e5float的每个通道解释成一个浮点数,尾数有9bit,公用了一个5bit的指数
注意没有特殊说明的如bgr10a2解析出来的依然是无符号整数
4.4.1.2 format
这个是最终用来描述一个pixel的内存占用情况,要表达:
- 它由那些通道组成,即是几个元素的数据
- 每个通道元素占的内存大小
format同date type不是同一个概念,举个gles上的例子:
RGBA8是一个format,它的data type是unsigned byte,说明它的数据存储按照ubyte看待,每个pixel由4个通道组成,每个通道都是一个ubyte,读取一个像素等于跨越4个ubyte。
RGB10_A2UI是一个foramt,它的data type则是USIGINED_INT_10_10_10_2_REV。说明他的数据存储是一个packed成32bit的int,但是会被拆成10,10,10,2四个部分,而它的每个pixel是由4个通道rgba组成,其中RGB对应3个10bit的定点数,A对应2bit的定点数。
每个format都会有它对应的特定的data type。
format基本分成两大类:
- 非压缩 format
- 压缩格式的format
不同的GPU和驱动实现可以支持硬件上的压缩格式的pixel fomat,如ASTC.
压缩格式的pixel format和普通的pixel format稍有不同:
- 它的data type全都是ubyte,即数据统一被看作是单字节数据
- 额外带有block width/height属性,表示一个压缩单元的像素尺寸。
API规范中会定义一些基本需要支持的压缩类型 pixel format,但是不同的硬件实现一般会支持更多。
4.4.1.3 pixel数据的解释
一个数据可能被存储成byte,float,int等各种基本形式,但是对于GPU来说,最终会如何解释他们?基本有以下几种情况
- 解读成浮点数:对各种bit数的float来说,直接解读成浮点数
- 定点数转化到浮点数:对于大部分的byte类型数据,他们其实是定点数,最终回被gpu解读成归一化的一个浮点数,注意16bit和24bit的depth也是定点数,在命名上,一般会对于归一化到-1-1之间的称为snorm,对于归一化到0-1之间的定点数称为unorm或没有特殊后缀
- 解读成整数:int/uint类型
- 解读成Indice:索引,一些以byte存储的数据,例如STENCIL
- gles上还存在LUMINANCE类型的数据(也使用byte存储)
4.4.2 GPU对pixel 数据的读取流程
我们知道对于GPU来说,它只认识Image的RGBA四个通道,外加DEPTH STENCEIL两个特殊通道,那么当上面的某个pixel format的数据进入GPU之后,是如何正确的被解析到RGBADS这6种通道上的?大致经历如下4个过程:
- unpack:如果是pack类型的data type,要先unpack出每个单独的数据(unint 或float)
- convert to float:到这一步之前,所有数据可能是如上所说的浮点数/定点数/interger/Indice/LUMINANCE中的一种,如果是浮点数和定点数,被根据各种bit位的浮点数解释称gpu上的浮点数类型(一般只有float和half)
- convert to RGB:如果当前是LUMINANCE类型,要按照规则转成RGB通道,到这一步之后,所有的数据都是RGBADS通道上的float/half/int/indice/float+indice
- FInal to RGBA:对与DS通道的数据,保持当前数值不变,对于其他数据全部补成RGBA通道的数据,缺少RGB中的通道,用0补上,缺少A中的通道,用1不上,此步骤之后,所有数据都是要么RGBA的float/half/int,要么是 deppthstencil的float/indice,是GPU能够认识的数据。
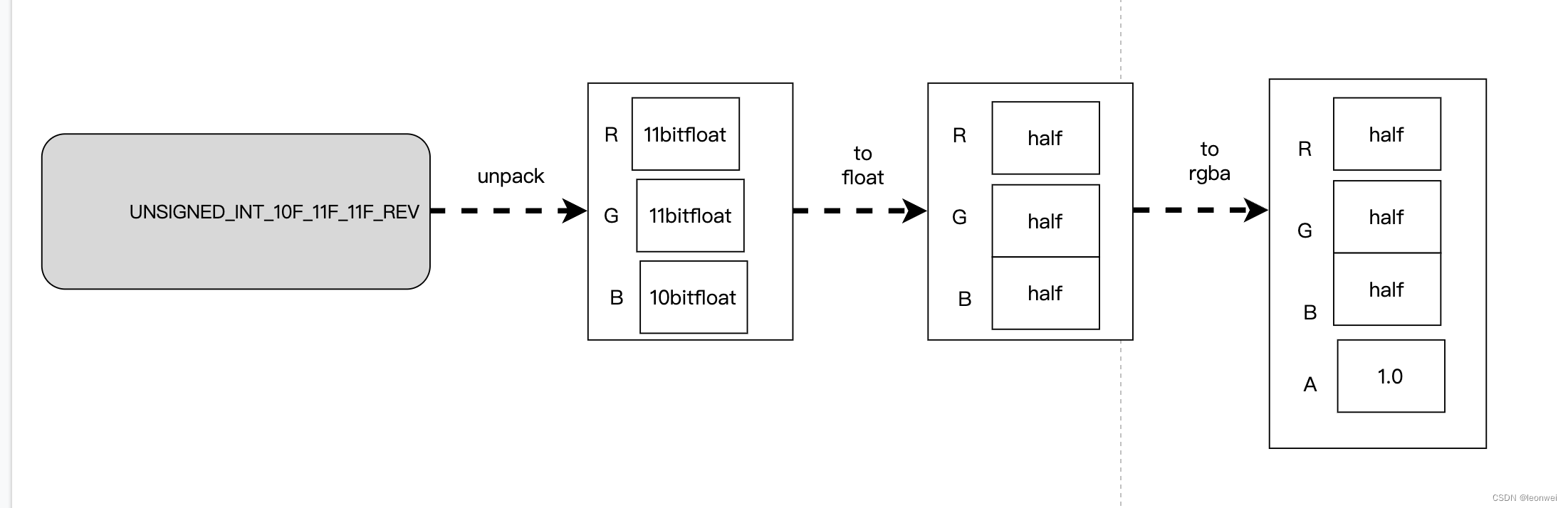
如下图展示了一个UNSIGNED_INT_10F_11F_11F_REV类型的数据读取到gpu的流程。
当然gpu对数据的写入存储按照类似的相反流程进行。
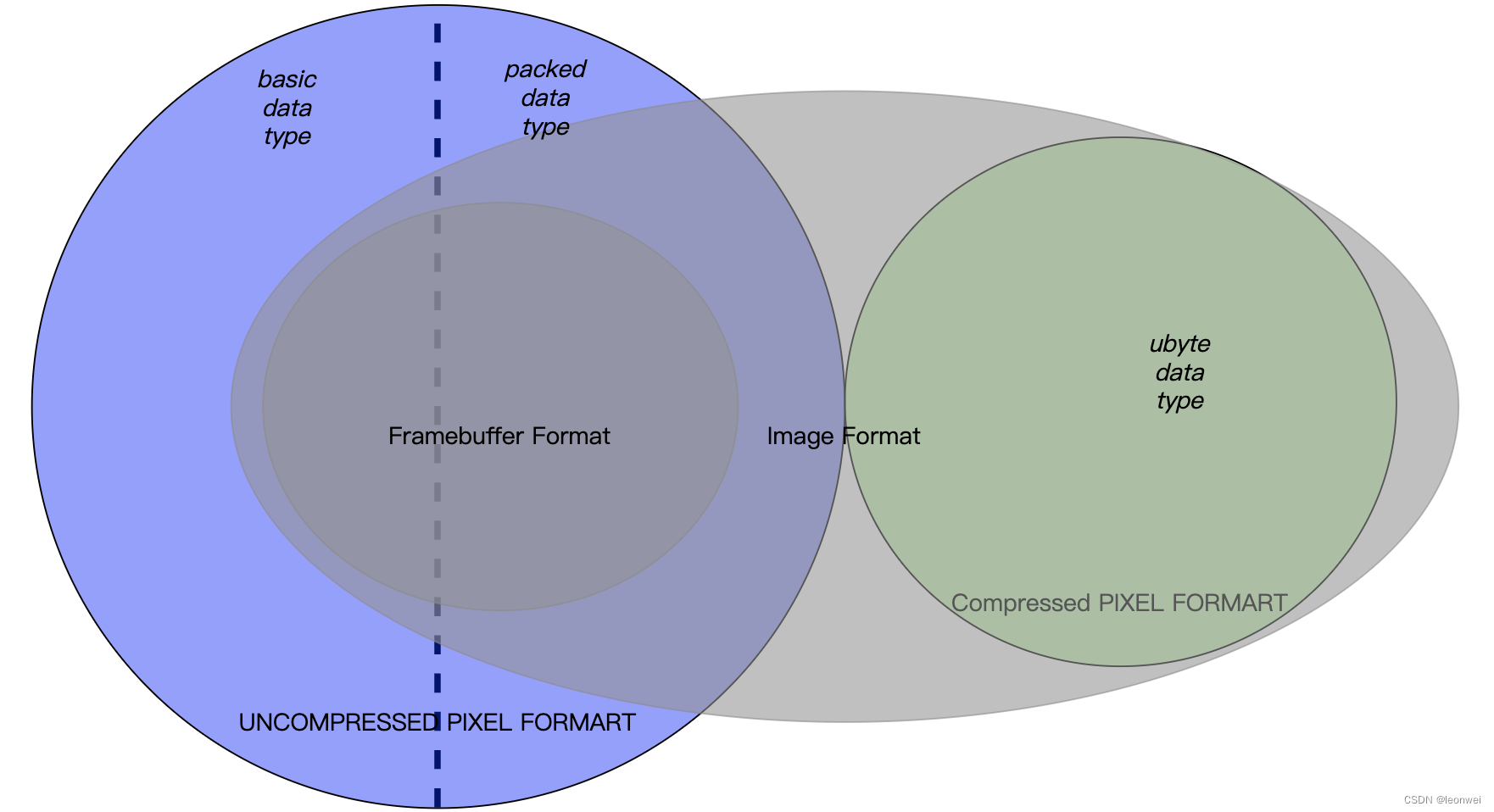
4.4.3 Pixel format的应用范围
API中定义的所有的pixel format 不是完全都能作为Image的格式来使用,他们用于image或者image的数据传输相关的API中
可作为Image格式的pixel format
可以作为image格式的pixel format仅仅是所有pixel format中的一个子集,不同的API要查询其版本的具体文档,但是绝大部分是支持的
可被用在Framebuffer上的pixel format
无论是以texture还是renderbuffer的形式提供给framebuffer渲染,它的格式就要进一步受到限制,这样的pixel format又是上面可作为Image的 pixel format中的子集,且不包括所有的压缩格式,具体要查阅相关API文档(一般会表明pixel format是否可以作为color rt或者depth stencil rt)
这些format的集合的关系大致如下:
在vulkan中,使用 vkGetPhysicalDeviceFormatProperties 可以查询某个具体format的适用范围等特性
在metal中,一般要查阅Metal-Feature-Set-Tables的文档来获得metal上每个pixle format的特性
在gles中,要查询gles的spec文档中Correspondence of sized internal color formats 的表格。
4.4.4 平台API中pixel format的定义
Vulkan
Vulkan上使用VkFormat来定义pixel的format,使用类似 VK_FORMAT_{component-format|compression-scheme}_{numeric-format} 的命名规范。
Metal
Metal上使用枚举类型MTLPixelFormat来定义,其中按照普通类型,packed类型,压缩类型,depthstencil类型等分成了几个部分
Gles
gles上的pxiel format定义比较复杂,首先这个format在gles上应该被称为Sized Internal Format。因为gles上format要分成两部分:
- Base Internal Format(有时用作参数时也叫做format)
它表示每个像素的基本布局,不考虑每个像素的位数,表达了通道数目和每个通道的意义有以下几种:
-
- RGB/RGBA/RG/RED
- RGB_INTERGER/RGBA_INTERGER/RG_INTERGER/RED_INTERGER
- DEPTH_COMPONENT
- DEPTH_STENCIL
- STENCIL_INDEX
- LUMINANCE_ALPHA
- LUMINANCE
- ALPHA
- Sized Internal Format(有时用作参数时也叫做internalformat)
他表示基于Base Internal Format扩展出来的format,他们通常包含每个通道的位数和type信息,Sized Internal Format就是是我们通常所说的texture的格式。
gles上只有特定的type, base internal format, sized internal format这三者的结合才是合理的,gles上所有合理的pixel format要参考spec中 Valid combinations of format, type, and unsized inter- nalformat 的那张表格。
gles上的多数API需要使用pixel format的时候,都需要提供的是这个sized internal format 。
4.4 内存Alias
4.4.1 内存的复用问题
在渲染流程中,我们经常会产生较多的临时性资源(transition resources),这些资源生命期只局限在某一帧的某一个时刻,但是却要占用较多的内存分配,我们希望能够复用这些资源。
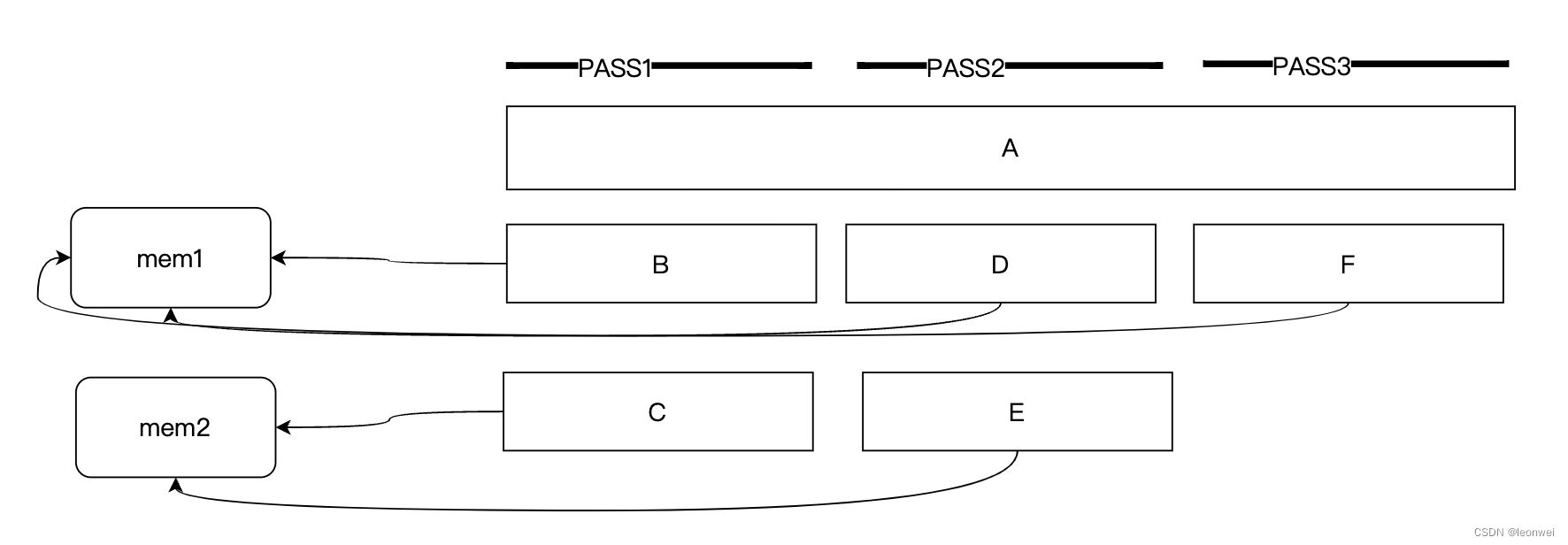
例如在如下的流程中,有3个pass,每个pass需要用到的RT资源和其生命周期如下:
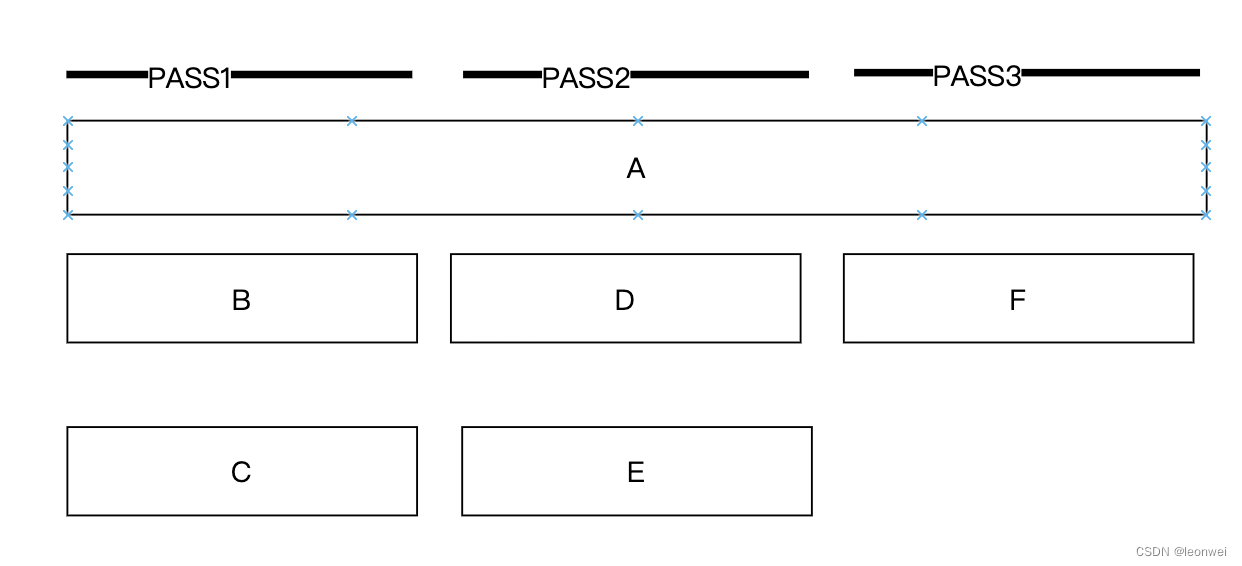
A需要一直被使用,BCDEF都是阶段性的被使用,我们最常用的做法是做一个RT池,反复利用相同尺寸格式的RT,这叫做
High-level 资源复用
例如其中的C和E是相同尺寸格式的RT,当CPU 编码pass1之后,将C回收回池,当开始编码pass2的时候,直接把C捞出来当作E放在Pass2上。
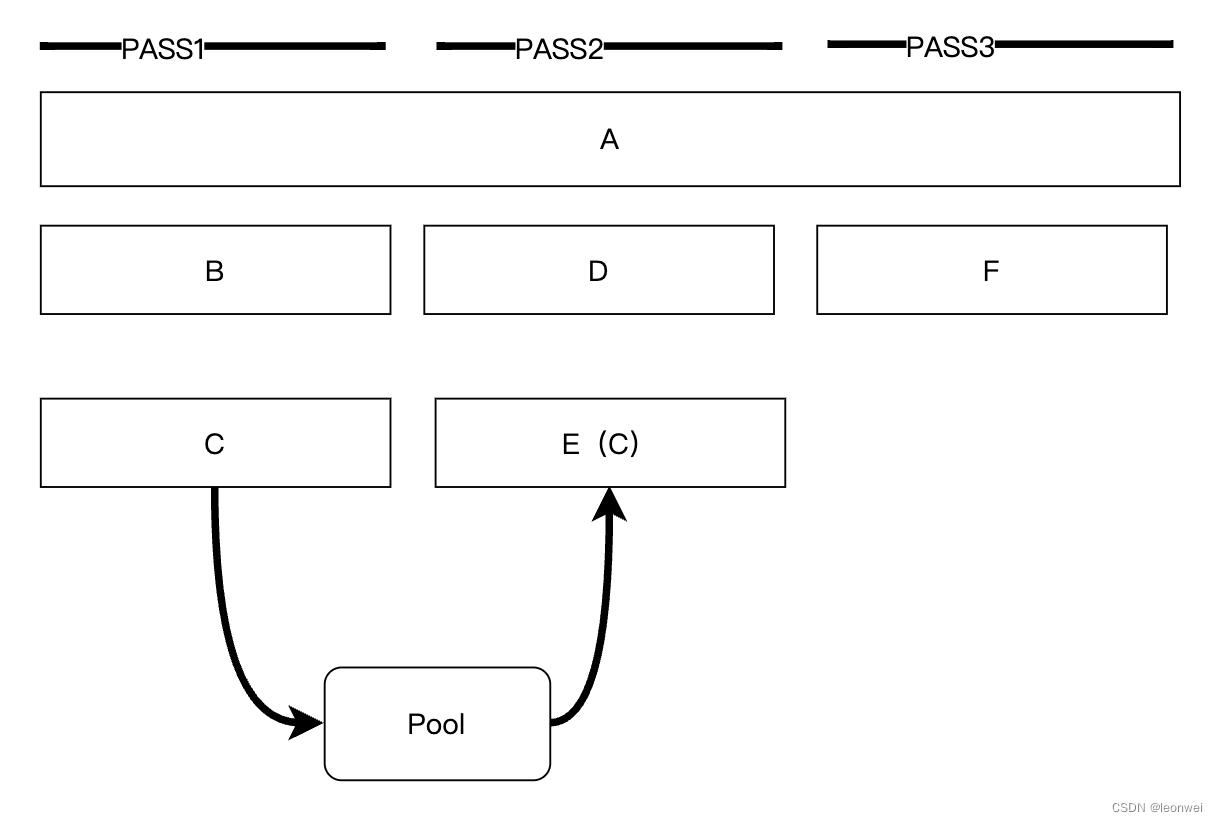
这样减少了E的内存占用。
但这个方式只能对尺寸规格完全一致的贴图起作用,如果对于大量的不一致的贴图则无能为力。对于Vulkan和Metal来说,都提供了更低级的资源复用方式,也叫做memory aliasing,它在内存的角度进行复用
low-level 资源复用
Alias的意思是一块内存可以同时绑定给多个GPU资源对象,只要这些对象能够对当前的内存解释的通,且不发生同时的读写冲突,上面的例子就会变成如下,虽然我们逻辑上还是分配了这么多对象,但是很有可能BDF overlap了同一快内存,CE也overlap的同一块,只是他们的生命周期不一样,所以互不冲突。
4.4.2 平台实现
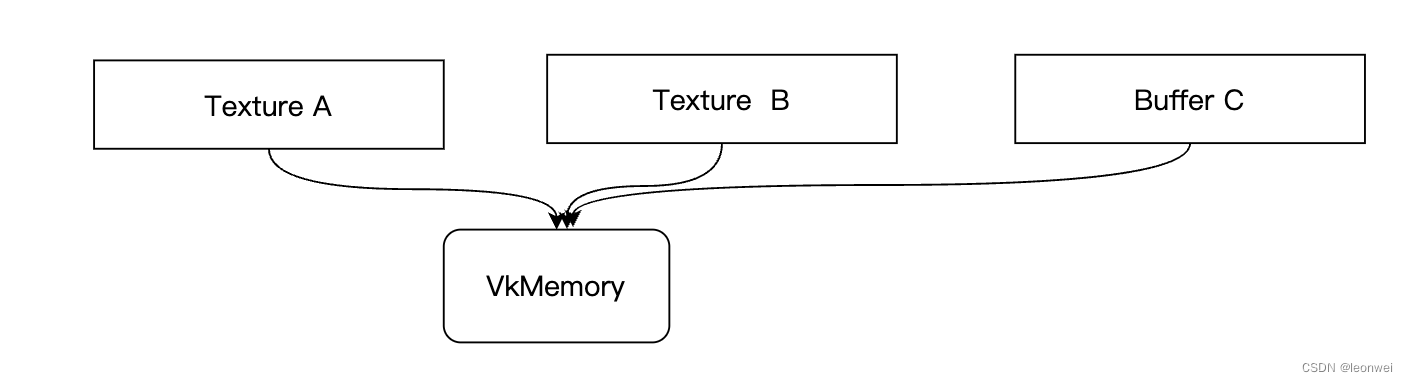
Vulkan
Vukan的实现比较直接,因为Vulkan上的texture 和buffer对象必须显示的调用mapmemory通资源对象VkMemory绑定,因此可以直接将多个对象绑定到相同的VkMemory上。甚至这里可以是buffer和texture混合的alias。
- 单独访问
对于alias的memory,如果你不考虑对同一份内存,多个对象都可以同时解释的情况,例如上面的渲染管线的例子,那么没有太多限制,只要用barrier等机制保证不同时访问就行
- 共同访问
如果多个对象可能同时解释一份数据,有一些限定:需要是buffer,或者linear tilling mode的并且处于preinitialized和genral的layout下的Image,并且他们对数据的解释相同,并且要设置image的创建flag VK_IMAGE_CREATE_ALIAS_BIT
上面的例子在Vulkan下,直接将BDF,CE分别用VkMapMemory到同一个VkMemory上就行了
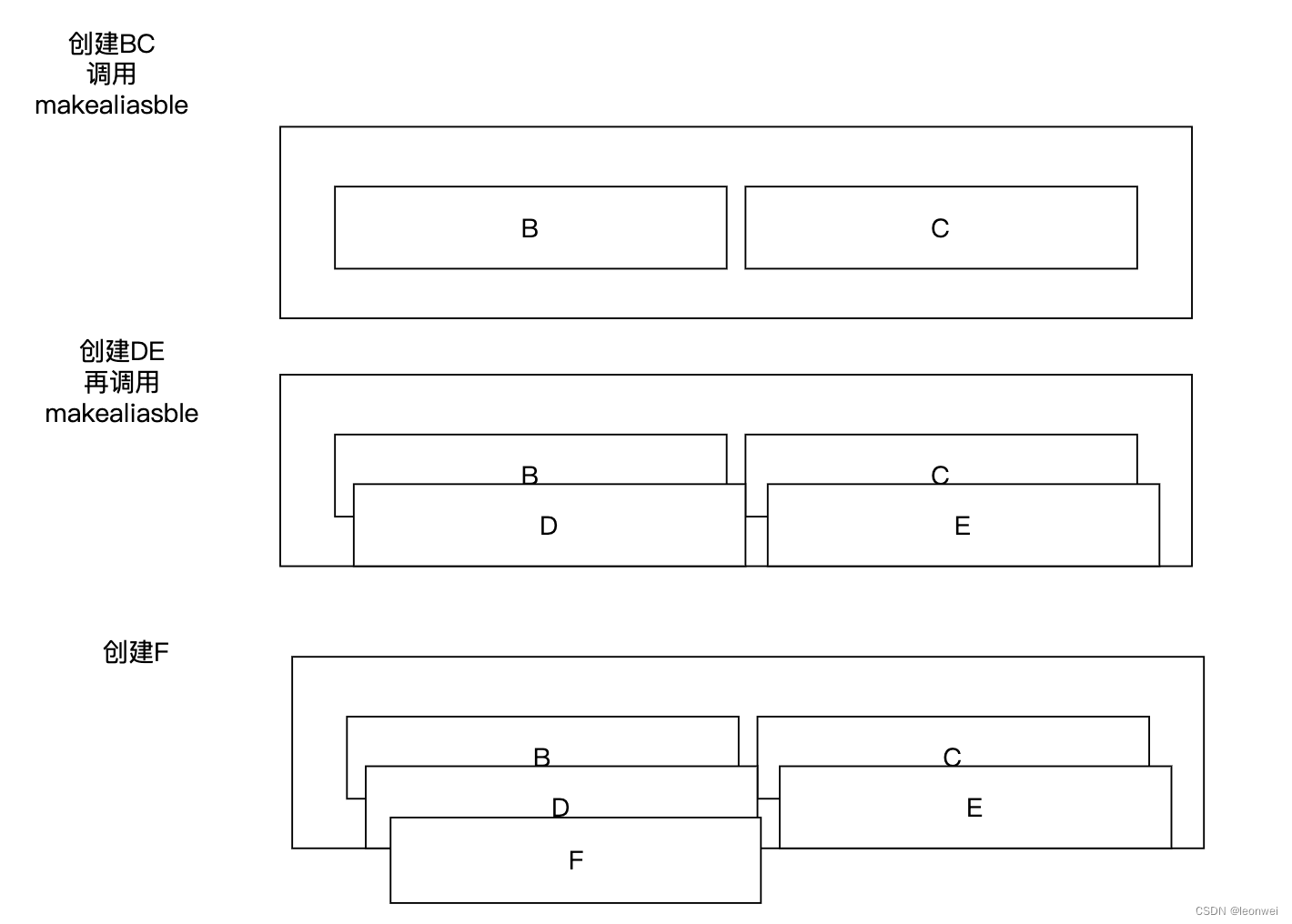
Metal
Metal下,需要首先保证资源是从MetalHeap创建的,创建好后,调用它的makeAliasable()标志着它可以被其他Resource复用内存,一旦变成aliasable之后不可逆。
这个机制可以解读成:
- 资源必须用MetalHeap创建,而不能直接从MTLDevice创建。
- 一个对象被标记成aliasable之后,其内存只能再被overlap一次,如果需要多次overlap,那需要在后面的资源上再次调用makeAliasable
- 我们不能直接指定哪些对象overlap到哪个内存上,只能通知某个对象的内存可以被其他对象占用,如同它的内存被丢进回收池一样
所以在这个机制下,你需要能够自己规划好那些能够互相overlap的对象让他们在同一个heap上,不同的heap是相互不能overlap的内存。我们需要把生命周期一致的对象放在一个heap中。
在上面的例子中,需要分配两个Heap,一个Heap创建A,因为它通其他所有资源有交叠,再另外一个Heap复用BCDEF,流程如下
4.5 Sparse Resource
在CPU上,虚拟内存可以远大于物理内存,因为虚存只在使用时才映射真正的物理内存,在GPU上,为了解决对超大资源的存储,也引入了类似的概念,这类超大资源叫做 sparse resource。
4.5.1 Sparse Bind, Residency, Alias
Device上的正常资源对象,它需要在使用前就绑定给一个连续完整的分配好的内存对象。
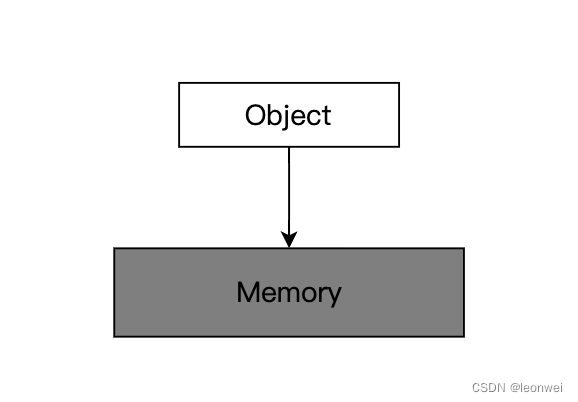
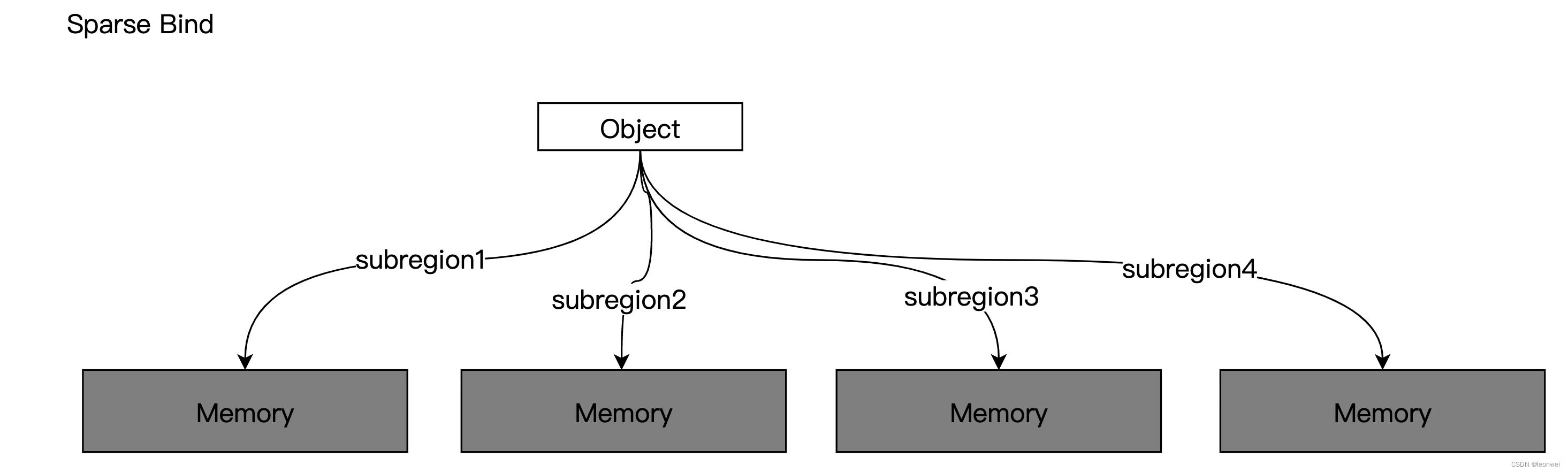
如果这个资源对象可以绑定在多个离散的已经分配好的内存对象上,我们就称它具有sparse bind能力。如一个Image它的不同的mip的不同的子区域的内存绑定给不同的memory。
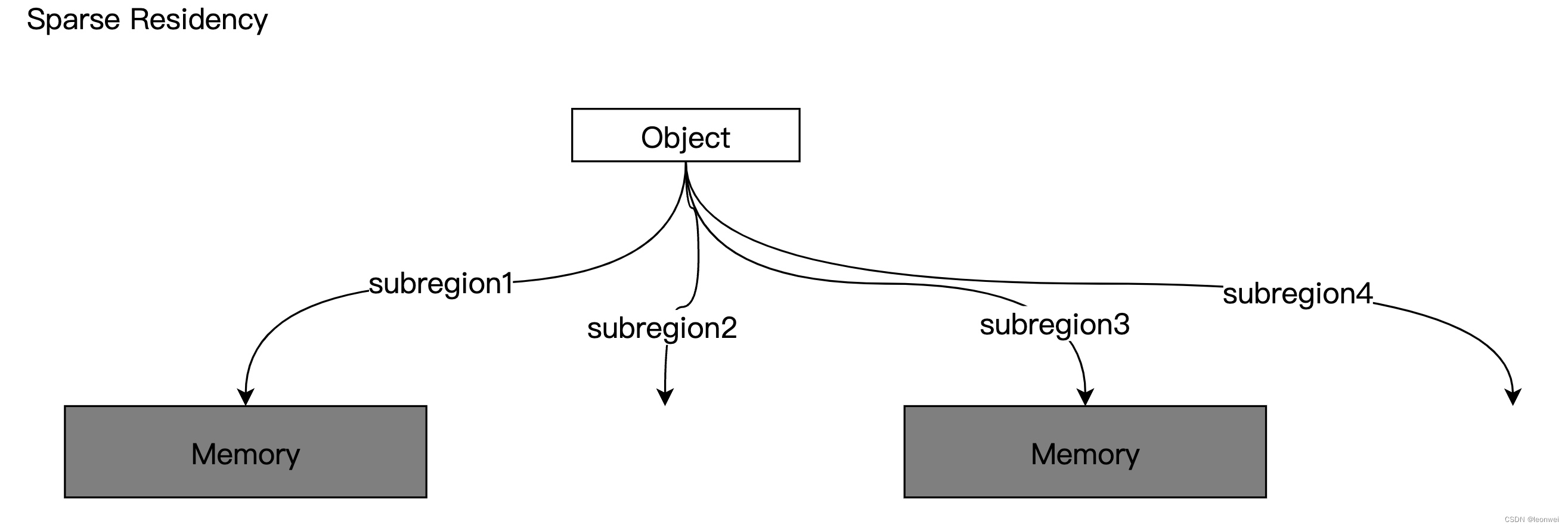
如果在上面的基础上,这个资源对象的某些区域可以不绑定一个内存对象,这个对象就可以被正常使用,且每个子区域可以动态的重新绑定内存对象,卸载内存对象,就称它具有sparse residency能力
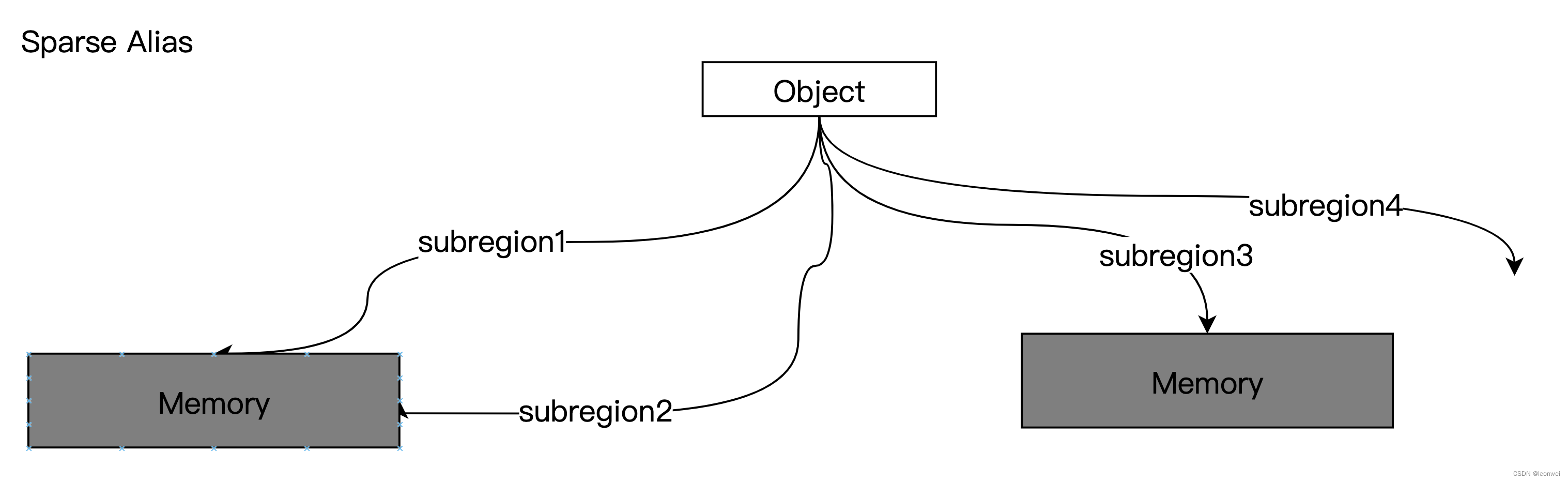
在residency的基础上,如果其中某些子区域的内存绑定可以复用(memory alias),复用范围包括单个资源内或者跨资源,那么就称它具有sparse alias能力。
实际上我们至少需要Sparse Residency来实现我们的需求,例如我们把一张超大的贴图做成Sparse Texture,会根据运行时的需要,动态的bind和unbind你当前要访问部分的贴图内容对应的内存,这就是硬件级别支持的Virtual Texture。
4.5.2 Sparse Resource的使用
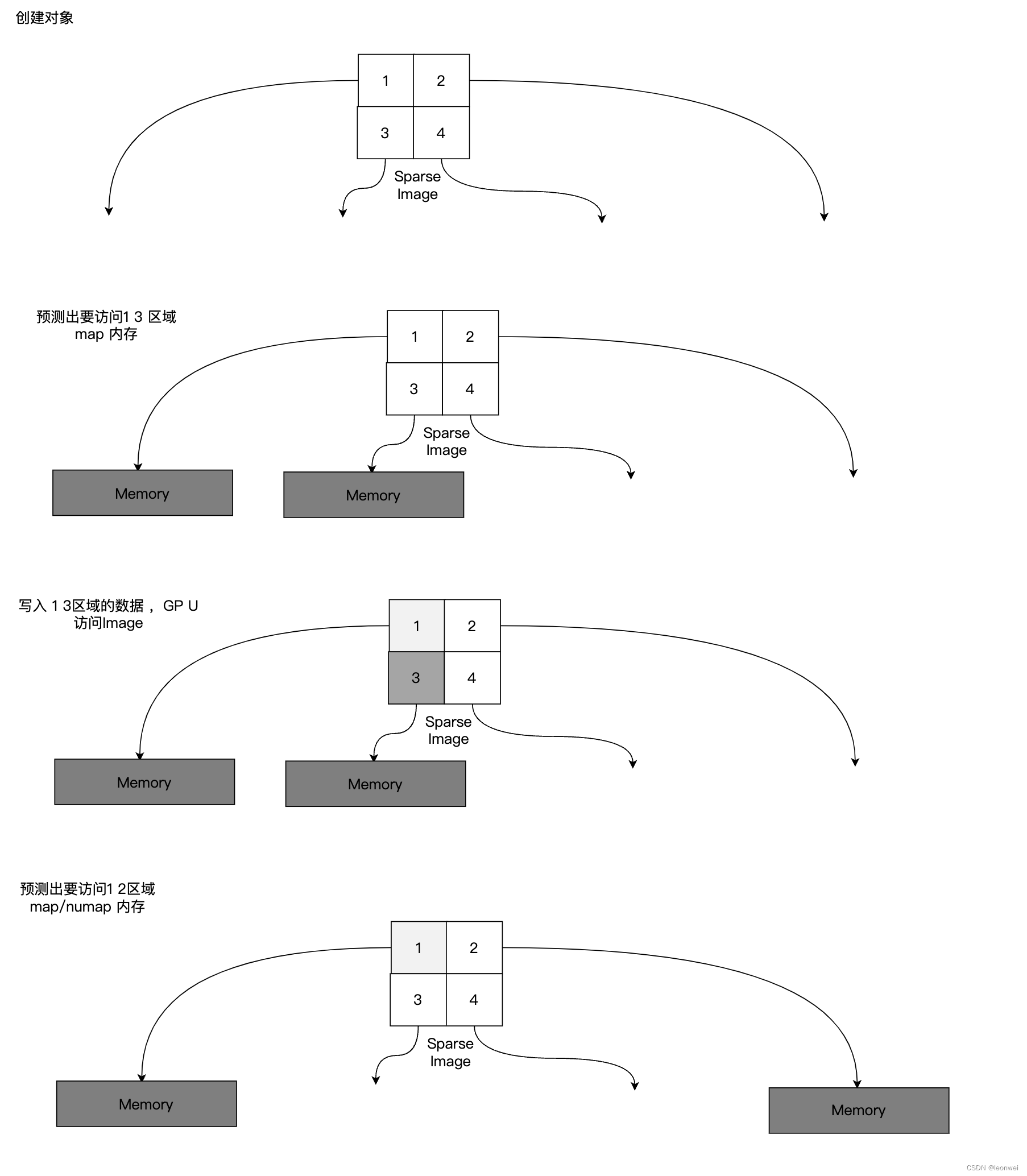
Sparse Resource可以帮助我们实现硬件级别支持的虚拟贴图(即不用自己软实现页表)等机制,使用Sparse Reousce的常用流程是,通常可以初始化不为他绑定任何memory,但是需要将资源做规划,拆分成N个子部分,并且能为每个子部分单独的map/unmap memory,当需要访问这个资源前,需要明确待访问的子部分范围,确保其对应的memory被map,而不被访问的子部分对应的memory可以被unmap节省内存。同时平台实现要能够保证及时访问到没有内存映射的区域也不会出错,可以返回特定值。
如下图是对一个spase texture 的常用访问流程。
Sparse Resource同CPU上虚拟内存的一个重要不同点是,Sparse Resource在unmap时不会负责备份数据到其他文件中,只是单纯的将内存释放,下次同一个区域的map之后需要重新填充这一块的数据。
4.5.3 平台实现
Metal
在Metal中,只有Image对象能够支持Sparse Residency能力,buffer还不能。
需要从一个特殊的Heap类型创建
MTLHeapDescriptor* descriptor = [MTLHeapDescriptor new];
descriptor.type = MTLHeapTypeSparse;
sparseHeap = [_device newHeapWithDescriptor: descriptor];
id<MTLTexture> sparseTexture = [_sparseHeap newTextureWithDescriptor:textureDescriptor];
SparseTexture的基本划分单位是tile,tile是一个mip上的一块子区域,获取特定格式贴图的一个tile能装下多少pixels,可以使用[_device sparseTileSizeWithTextureType]查询
Map和Unmap操作:
Sparse Resource的Map和Unmap操作都不是立即执行式的API,都需要写入到指令流缓存里面,发送给gpu执行。这里encoder 指令也需要一个特殊的encoder MTLResourceStateCommandEncoder,它的接口是
- (void)updateTextureMapping:(id<MTLTexture>)texture
mode:(const MTLSparseTextureMappingMode)mode
region:(const MTLRegion)region
mipLevel:(const NSUInteger)mipLevel
slice:(const NSUInteger)slice;
其中的Mode有两种map和unmap
region,miplevel,slice则指定了操作的子区域。
对于unmap的区域的GPU读取将得到0,写入则会被忽略。
通常一些很小的mip可以合并起来共用一个tile,叫做tail mipmaps,如果上面的miplevel设置为texture.firstMipmapInTail,那么整个tail的mip会作为集体一起map/unmap
Vulkan
在Vulkan中,对于Image和Buffer两种对象,根据硬件和驱动的能力,最多支持到sparse alias。首先需要查询VkPhysicalDeviceFeatures 来得到当前device对sparse resource的支持程度,如 sparseBinding 、sparseResidencyBuffer 、sparseResidencyImage2D 、sparseResidencyAliased 等
Vulkan需要使用带有VK_QUEUE_SPARSE_BINDING_BIT的queue来记录sparse resource相关的操作,有一个API用来做map和unmap
VkResult vkQueueBindSparse(
VkQueue queue,
uint32_t bindInfoCount,
const VkBindSparseInfo* pBindInfo,
VkFence fence);
typedef struct VkBindSparseInfo {
VkStructureType sType;
const void* pNext;
uint32_t waitSemaphoreCount;
const VkSemaphore* pWaitSemaphores;
uint32_t bufferBindCount;
const VkSparseBufferMemoryBindInfo* pBufferBinds;
uint32_t imageOpaqueBindCount;
const VkSparseImageOpaqueMemoryBindInfo* pImageOpaqueBinds;
uint32_t imageBindCount;
const VkSparseImageMemoryBindInfo* pImageBinds;
uint32_t signalSemaphoreCount;
const VkSemaphore* pSignalSemaphores;
} VkBindSparseInfo;
这个API不是通过记录在cmdbuffer中的方式,而是直接将这个操作提交给queue,这不是一个command的record操作,而是一个submit操作。
此外这个操作不保证GPU上的执行顺序,因此相关的资源依赖的操作必须同这里的fence和semaphore做同步。
另外同这个API绑定的buffer或image创建时必须要有flag VK_IMAGE/BUFFER_CREATE_SPARSE_BINDING_BIT,另外如果为了支持sparse residency,还要有flag VK_IMAGE/BUFFER_CREATE_SPARSE_RESIDENCY_BIT
API里面的VkSparseBufferMemoryBindInfo 、VkSparseImageOpaqueMemoryBindInfo、VkSparseImageMemoryBindInfo都是包含了sparse map和unmap的信息,分别用于buffer和两种情况下的image
- Buffer里面描述buffer的每个子区域的内存绑定
typedef struct VkSparseBufferMemoryBindInfo {
VkBuffer buffer;
uint32_t bindCount;
const VkSparseMemoryBind* pBinds;
} VkSparseBufferMemoryBindInfo;
typedef struct VkSparseMemoryBind {
VkDeviceSize resourceOffset;
VkDeviceSize size;
VkDeviceMemory memory;
VkDeviceSize memoryOffset;
VkSparseMemoryBindFlags flags;
} VkSparseMemoryBind;
- fully-residency image
即这个image不支持sparse residency,那么他相当于需要预先绑定到一块连续的内存对象上才能被使用的
这个绑定信息描述为结构
typedef struct VkSparseImageOpaqueMemoryBindInfo {
VkImage image;
uint32_t bindCount;
const VkSparseMemoryBind* pBinds;
} VkSparseImageOpaqueMemoryBindInfo;
这里传入的参数类似Buffer
- partially-residendy image
即这个image支持sparse residency,他可以对每个子区域动态绑定内存对象,这个绑定信息描述为
typedef struct VkSparseImageMemoryBindInfo {
VkImage image;
uint32_t bindCount;
const VkSparseImageMemoryBind* pBinds;
} VkSparseImageMemoryBindInfo;
typedef struct VkSparseImageMemoryBind {
VkImageSubresource subresource;
VkOffset3D offset;
VkExtent3D extent;
VkDeviceMemory memory;
VkDeviceSize memoryOffset;
VkSparseMemoryBindFlags flags;
} VkSparseImageMemoryBind;
这个传入的参数可以描述每个子区域绑定的meomory。
如何计算出来每个子区域需要占用的内存大小?
对于Buffer和fully-residency 的Image来说,这个子区域的大小时固定的,通过查询内存大小的接口vkGetImageMemoryRequirements/ vkGetBufferMemoryRequirements 中的
VkMemoryRequirements::alignment 从系统中查询到,它即是对齐大小,也是块的大小。
对于partially-residency的image,通过 vkGetImageSparseMemoryRequirements 查询,它将返回一组 VkSparseImageMemoryRequirements ,每个表示这个image的其中一个aspect(指depthstencil这种两个逻辑image放在一起的情况)上的每个mip的子区域大小。
4.6 Metal Purgeable Resource
对于Texture和Buffer这种资源对象,因为涉及到较大的内存分配和释放负担,我们常常需要在应用中使用各种池机制来复用,以减少他们的内存分配,释放操作。
在metal的框架内,它额外在底层给我们提供了一个特殊的内存池机制,使应用可以直接使用。
其实相当于Metal在操作系统范围内提供了一个内存池,它维护所有的MtlResource对象(mtlbuffer,mtltexture),应用通过API往里面回收和捞取资源对象,这提供了两个好处:
- 系统为我们实现了池的管理策略,何时收缩池,何时扩张池,且策略同当前操作系统的总体情况有关。
- 处于池中被回收的资源不计入具体APP的footprint,即你没有实际使用的资源再多也不会导致APP的out-of-memory,因为操作系统知道何时去释放这些没有的资源
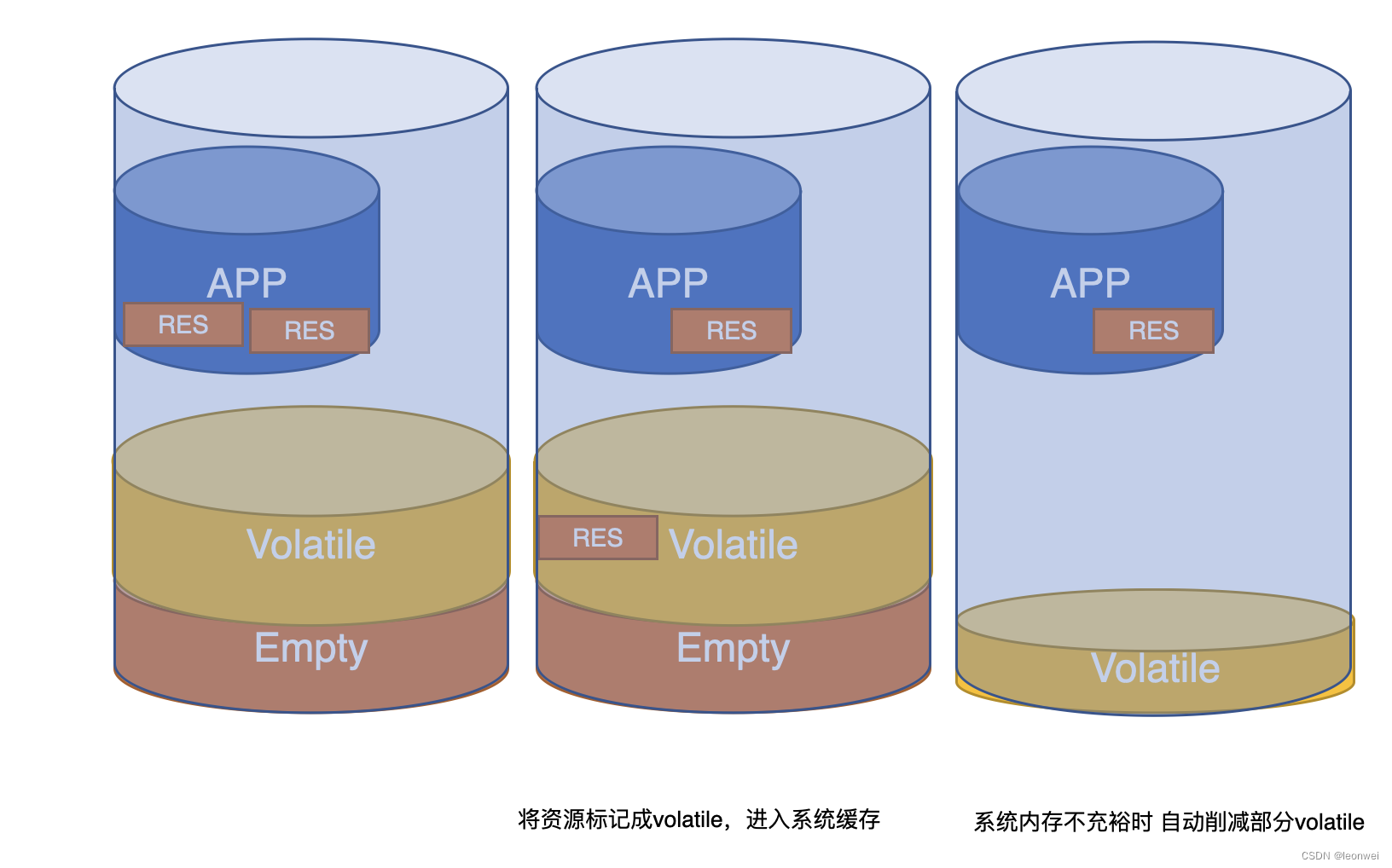
Metal这套内存池的机制叫做purgeable resource,具体使用方法如下:
MTLResource有一个属性purgeable state,他可能是三种状态:
- Volatile:该内存资源是暂时不被使用的,系统将在内存吃紧的时候回收掉它,使用这种类型资源前要查询该资源是否已经无效了(变成empty状态)。
- Non_volatile:该内存资源一直有用,不能被回收
- Empty:该内存资源明确不用了,需要立即释放。
当我们不用这个资源就把他标记为volatile的,相当于回收进入池;
我们想用就从池拿出来,判断它是否为empty,这里有两种可能,需要先判断是否已经被释放,如果被释放了就重新创建,否则就能直接用。
这里面涉及到的API只有一个setPurgeableState,可以设置上面3中状态,如果传入
KeepCurrent,则为查询当前的state。
如下图是 APP使用系统内存池的过程。
Buffer和Texture只是用户直接可操纵到内存的图形API对象,实际上Device上还有许许多多种对象,本章节的重点在内存操作这一侧的事情,下一章节将详细讨论这些对象及其在管线中如何被使用。
















 1836
1836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









