






一种轻量级高效的视觉Transformer模型,名为DualToken-ViT,它充分利用了CNNs和ViTs的优势。DualToken-ViT通过有效融合基于卷积结构获取的局部信息和基于自注意力结构获取的全局信息的Token,以实现高效的注意力结构。超越LightViT和MobileNet v2,实现更强更快更轻量化的Backbone
论文链接:https://arxiv.org/abs/2309.12424
自注意力(self-attention)视觉Transformer(ViTs)已经成为计算机视觉领域一种非常有竞争力的架构。与卷积神经网络(CNNs)不同,ViTs能够进行全局信息共享。随着ViTs各种结构的发展,它们在许多视觉任务中的优势日益显现。然而,自注意力的二次复杂性使ViTs计算密集型,并且它们缺乏局部性和平移等变性的归纳偏见,因此需要比CNNs更大的模型规模才能有效学习视觉特征。
在本文中,作者提出了一种轻量级高效的视觉Transformer模型,名为DualToken-ViT,它充分利用了CNNs和ViTs的优势。DualToken-ViT通过有效融合基于卷积结构获取的局部信息和基于自注意力结构获取的全局信息的Token,以实现高效的注意力结构。此外,作者在所有阶段都使用了具有位置感知的全局Token,以丰富全局信息,进一步增强了DualToken-ViT的效果。位置感知的全局Token还包含图像的位置信息,使作者的模型更适用于视觉任务。
作者在图像分类、目标检测和语义分割任务上进行了大量实验,以展示DualToken-ViT的有效性。在ImageNet-1K数据集上,作者不同规模的模型分别在只有0.5G和1.0G FLOPs的情况下实现了75.4%和79.4%的准确率,而作者的1.0G FLOPs模型超越了使用全局Token的LightViT-T模型0.7%。
近年来,视觉Transformer(ViTs)已经成为各种视觉任务的强大架构,如图像分类和目标检测。这是因为自注意力能够从图像中捕获全局信息,提供充足且有用的视觉特征,而卷积神经网络(CNNs)受到卷积核大小的限制,只能提取局部信息。
随着ViTs的模型规模和数据集规模的增加,性能仍然没有出现饱和迹象,这是CNNs在大型模型和大型数据集方面不具备的优势。然而,在轻量级模型方面,CNNs比ViTs更具优势,因为CNNs具有某些ViTs缺乏的归纳偏见。由于自注意力的二次复杂性,ViTs的计算成本也可能很高。因此,设计基于轻量级的高效ViTs是一项具有挑战性的任务。
为了设计更高效和轻量级的ViTs,PvT和TWin提出了一个金字塔结构,将模型分为多个阶段,每个阶段的Token数量减少,通道数量增加。Separable self-attention和Hydra attention着重于通过简化和改进自注意力结构来减少自注意力的二次复杂性,但它们牺牲了注意力的有效性。减少涉及自注意力的Token数量也是一个常见的方法,例如,[PvT v1, PvT v2, Hilo Attention]对自注意力中的Key和Value进行了降采样。一些基于局部分组自注意力的作品通过分别对分组Token执行自注意力来降低总体注意力部分的复杂性,但这种方法可能会破坏全局信息的共享。
一些作品还通过添加一些额外的可学习参数来丰富主干的全局信息,例如,[Vision transformer with super token sampling, Mobile-former, Dual vision transformer]添加了贯穿所有阶段的全局Token分支。这种方法可以为局部注意力(例如基于局部分组自注意力和基于卷积的结构)提供全局信息的补充。然而,这些现有方法使用全局Token时仅考虑全局信息,而忽略了对于视觉任务非常有用的位置信息。
在本文中,作者提出了一种轻量级和高效的视觉Transformer模型,称为DualToken-ViT。作者提出的模型具有更高效的注意力结构,旨在替代自注意力。作者结合了卷积和自注意力的优点,分别利用它们提取局部和全局信息,然后融合两者的输出,以实现高效的注意力结构。虽然窗口自注意力也能够提取局部信息,但作者观察到它在作者的轻量级模型上效率不如卷积。为了减少全局信息广播中自注意力的计算复杂性,作者通过逐步降采样来降低产生键和值的特征图,这可以在降采样过程中保留更多的信息。
此外,作者在所有阶段都使用了具有位置感知的全局Token,以进一步丰富全局信息。与普通的全局Token不同,作者的位置感知全局Token还能够保留图像的位置信息并传递,这可以使作者的模型在视觉任务中具有优势。

如图1所示,图像中的关键Token与位置感知全局Token中相应Token的相关性更高,这证明了作者的位置感知全局Token的有效性。总之,作者的贡献如下:
- 作者设计了一种轻量级和高效的视觉Transformer模型,称为DualToken-ViT,它通过融合包含局部和全局信息的局部和全局Token,结合卷积和自注意力的优点,实现了高效的注意力结构。
- 作者进一步提出了包含图像位置信息的位置感知全局Token,以丰富全局信息。
- 在相同FLOPs数量的视觉模型中,作者的DualToken-ViT在图像分类、目标检测和语义分割任务上表现最佳。
方法论
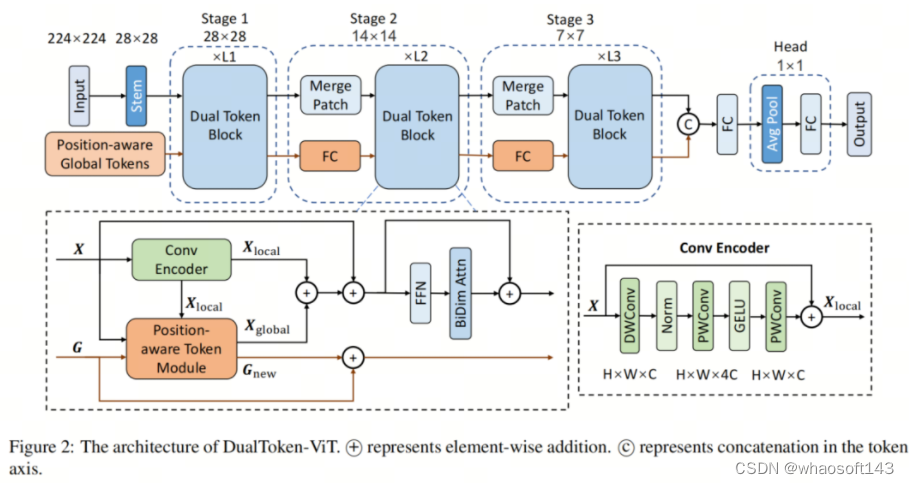
如图2所示,DualToken-ViT基于LightViT的3阶段结构设计。作者模型中的干和合并块的结构与LightViT中相应部分相同。FC表示全连接层。
作者的模型有两个分支:图像Token分支和位置感知全局Token分支。图像Token分支负责从位置感知全局Token中获取各种信息,而位置感知全局Token分支负责通过图像Token分支更新位置感知全局Token并传递信息。在每个Dual Token块的注意力部分,作者从位置感知全局Token中获取信息并融合局部和全局信息。在FFN之后,作者还添加了LightViT提出的BiDim Attn(双向注意力)。
局部和全局信息的融合
在每个Dual Token块的注意力部分,作者通过两个分支提取局部和全局信息,分别为Conv编码器(卷积编码器)和位置感知Token模块,然后融合这两部分。
局部注意
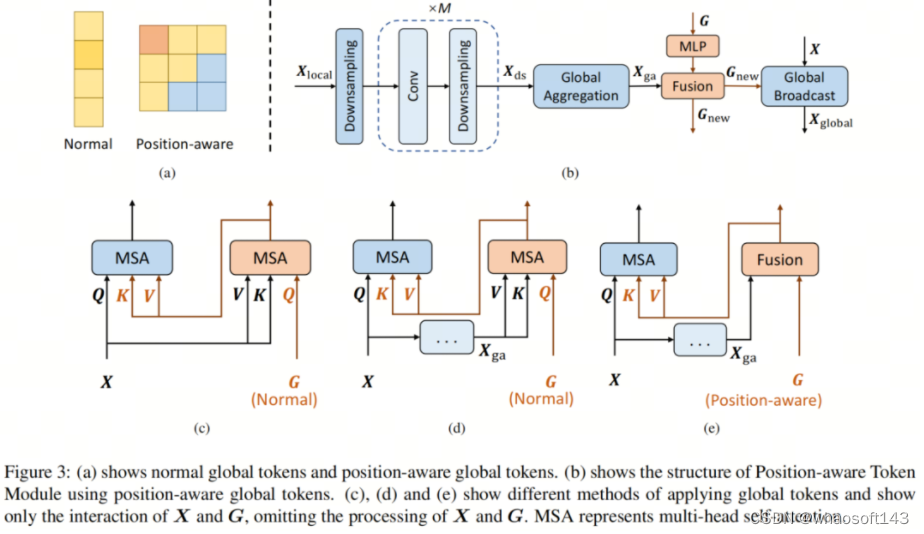
作者在模型的每个块中使用Conv编码器来提取局部信息,因为对于轻量级模型,使用卷积提取局部信息的性能将优于窗口自注意。Conv编码器的结构与ConvNeXt块相同,表示如下:

位置感知Token模块


位置感知全局Token

其中Transpose表示空间和通道轴的转置。作者将这个过程称为Mix MLP。
架构
作者设计了两个不同规模的DualToken-ViT模型,它们的宏观结构如表1所示。

实验
图像分类
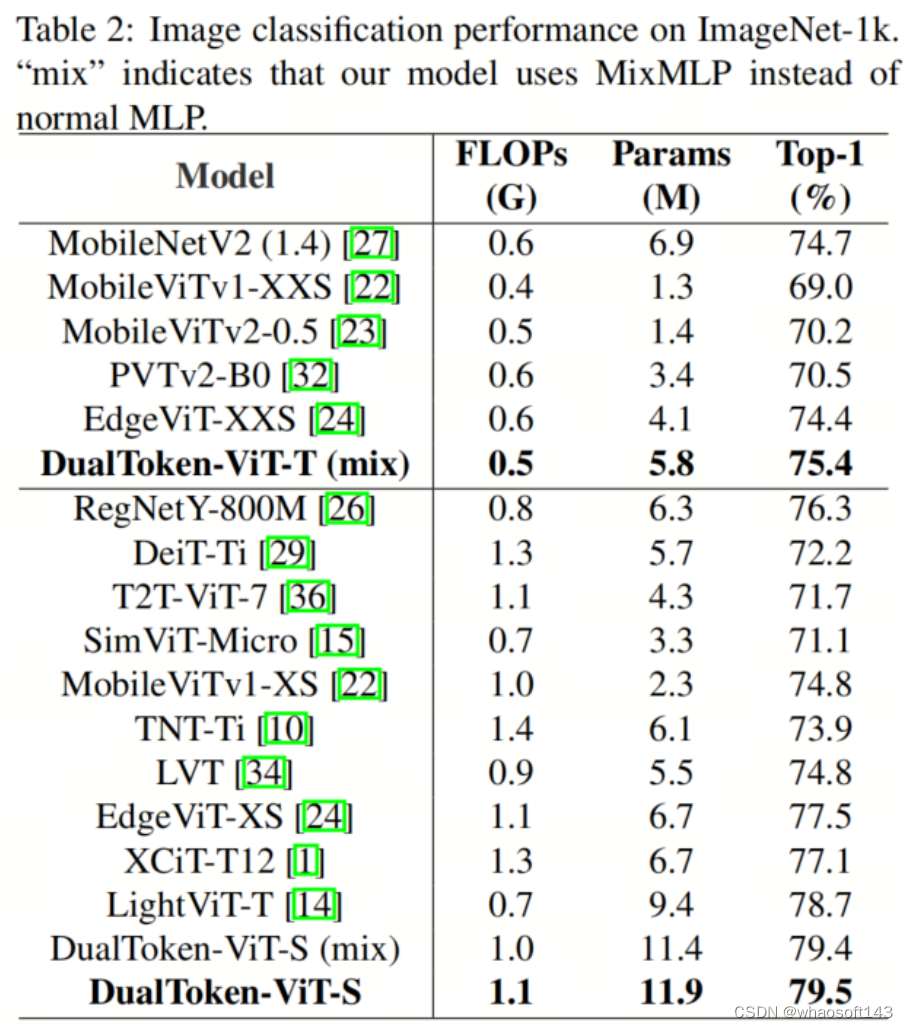
将DualToken-ViT与其他两种FLOPs规模的视觉模型进行比较,实验结果如表2所示,作者的模型在两个规模上均表现最佳。例如,DualToken-ViT-S(mix)在1.0G FLOPs的情况下实现了79.4%的准确率,超过了当前的SoTA模型LightViT-T。并且在将MixMLP替换为普通MLP后,作者将准确率提高到了79.5%。
目标检测与实例分割
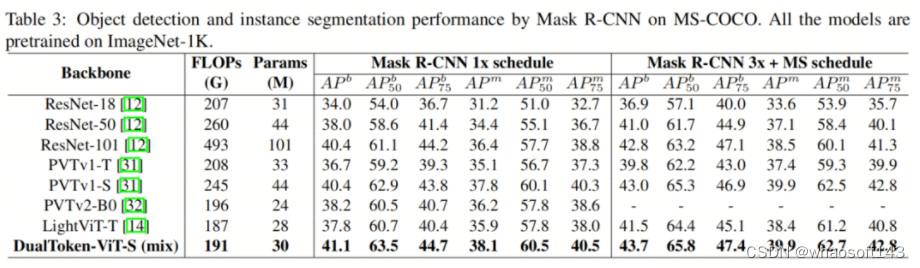
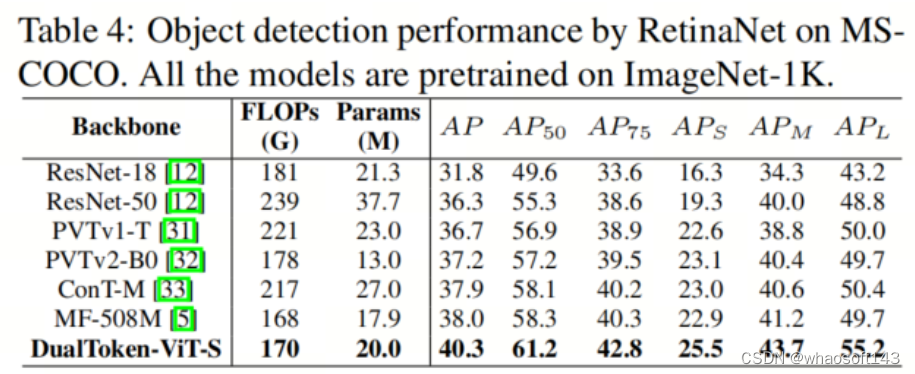
作者比较了作者模型在Mask R-CNN和RetinaNet架构上与其他模型的性能,实验结果如表3和表4所示。尽管作者的Backbone网络仅有三个阶段,但在相同FLOPs规模的模型中,没有最大分辨率阶段的DualToken-ViT-S仍然表现出色。特别是在使用1×的训练计划的Mask R-CNN架构实验中,作者的Backbone网络在191G FLOPs下实现了41.1%的APb和38.1%的AP m,远远超过了具有相似FLOPs的LightViT-T。这可能与作者的位置感知全局Token有关。
语义分割
作者比较了作者的模型在DeepLabv3和PSPNet架构上与其他模型的性能,实验结果如表5所示。在相同FLOPs规模的模型中,DualTokenViT-S在这两种架构上表现最佳。

消融研究
MLP
作者比较了应用于位置感知全局Token上的两种MLP:普通MLP和MixMLP。DualToken-ViT-S的实验结果如表2所示。普通MLP比MixMLP准确率高0.1%,但会增加一些额外的FLOPs和参数。这是因为MixMLP提取了空间维度上的信息,它可能会损坏位置感知全局Token上的一些位置信息。
不同的全局Token应用方法
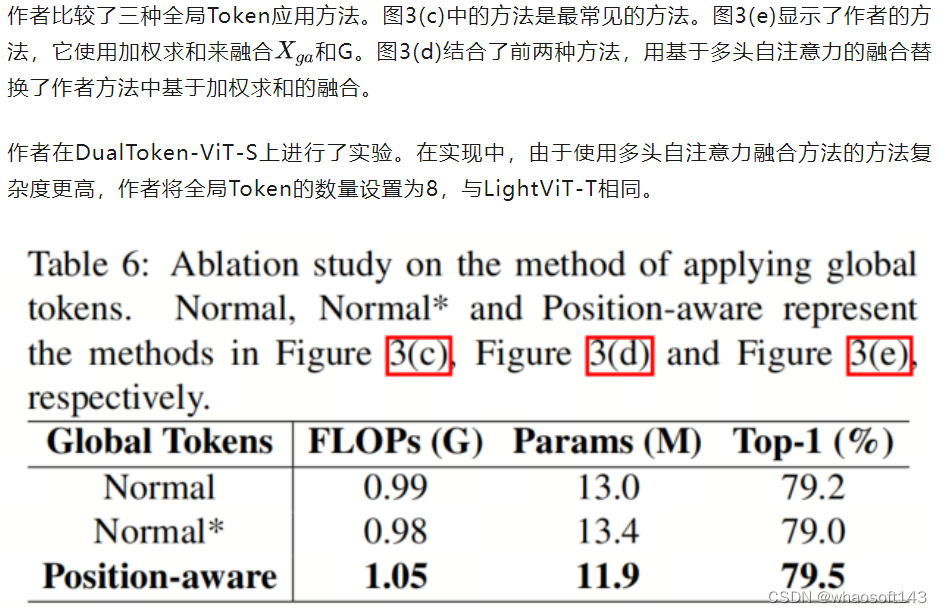
实验结果如表6所示,表明基于位置感知的方法性能最佳,且比普通方法少了1.1M个参数,仅多了0.06G的FLOPs。由于其他两种方法使用了需要许多参数的基于多头自注意力的融合方法,而作者的方法使用了基于加权求和的融合,所以作者的方法具有最小的参数。这证明了位置感知全局Token的优越性。
位置感知全局Token中的Token数量
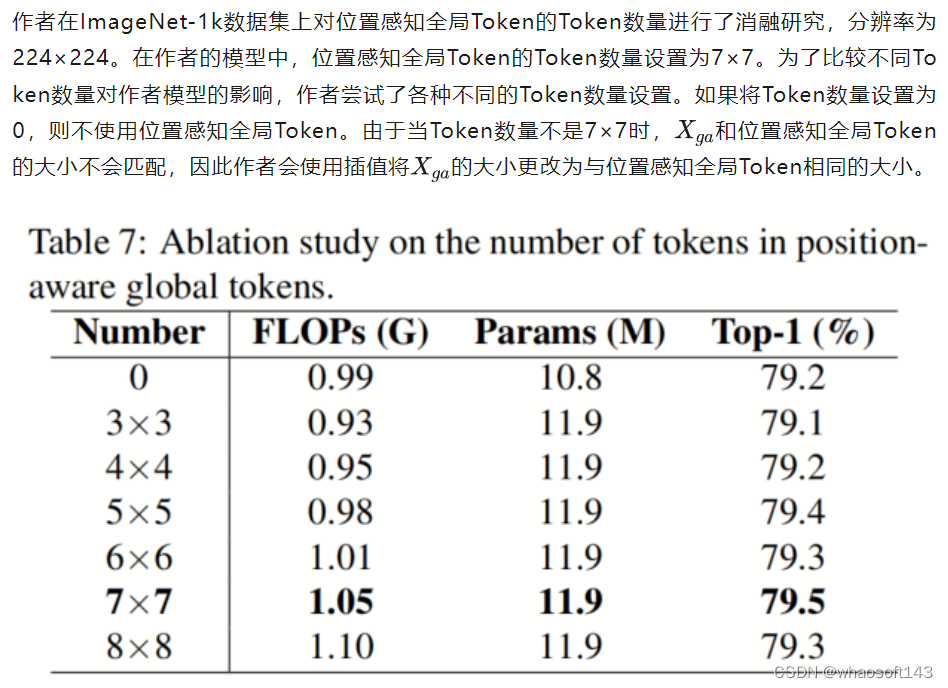
在DualToken-ViT-S上的实验结果如表7所示。将Token数量设置为7×7的模型性能最佳,因为Token数量足够,并且不会因插值方法而损害信息。与将Token数量设置为0的情况相比,作者的设置准确率提高了0.3%,仅增加了0.06G的FLOPs和1.1M的参数,这证明了作者的位置感知全局Token的有效性。
局部注意力
作者比较了Conv Encoder和窗口自注意力在作者模型中的作用。作者将窗口自注意力的窗口大小设置为7。DualToken-ViT-S(mix)的实验结果如表8所示。
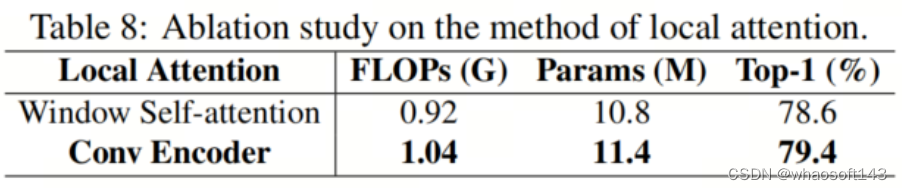
使用Conv Encoder作为局部注意力的模型表现更好,准确率比使用窗口自注意力高0.8%,而FLOPs和参数的数量并没有增加很多。Conv Encoder的性能优越有两个原因。一方面,对于轻量级模型,基于卷积的结构比基于Transformer的结构更有优势。另一方面,窗口自注意力破坏了位置感知全局Token中的位置信息。这是因为基于Transformer的结构没有局部性的归纳偏差。在窗口自注意力中,窗口边缘的特征会因特征图被分割成多个小部分而受损。
降采样

作者对位置感知Token模块的逐步降采样部分进行了消融研究。对于一步降采样的设置,作者直接对进行降采样以获得所需的大小,然后将其输入到全局聚合中。DualToken-ViT-S(mix)的实验结果如表9所示。逐步降采样比一步降采样准确率高0.2%,而FLOPs和参数仅增加了0.03G和0.1M。这是因为逐步方法在降采样过程中可以通过卷积保留更多信息。
可视化

为了更直观地感受位置感知全局Token中包含的位置信息,作者可视化了DualToken-ViT-S(mix)中最后一个块的全局广播的注意力图,结果如图4所示。在每一行中,第二和第三张图显示了第一张图中的关键Token与位置感知全局Token中相应Token生成更高的相关性。在每一行的第二张图中,第一张图中的非关键Token与位置感知全局Token的每个部分生成更均匀的相关性。每一行的第四张图显示了整体位置感知全局Token与第一张图的关键Token具有更高的相关性。这些结果表明作者的位置感知全局Token包含位置信息。















 2546
2546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









