







本文来自cvpr 2022 :
https://openaccess.thecvf.com/content/CVPR2022/papers/Yin_A-ViT_Adaptive_Tokens_for_Efficient_Vision_Transformer_CVPR_2022_paper.pdf![]() https://openaccess.thecvf.com/content/CVPR2022/papers/Yin_A-ViT_Adaptive_Tokens_for_Efficient_Vision_Transformer_CVPR_2022_paper.pdf介绍了一种名为A-ViT(Adaptive Vision Transformer)的新方法,旨在通过自适应调整Vision Transformer的推理成本来适应不同复杂度的图像。
https://openaccess.thecvf.com/content/CVPR2022/papers/Yin_A-ViT_Adaptive_Tokens_for_Efficient_Vision_Transformer_CVPR_2022_paper.pdf介绍了一种名为A-ViT(Adaptive Vision Transformer)的新方法,旨在通过自适应调整Vision Transformer的推理成本来适应不同复杂度的图像。
1,动机
传统的Transformer模型计算成本是固定的,与输入图像的复杂性无关。作者认为这导致在处理简单图像时可能会有不必要的计算浪费。A-ViT旨在根据输入图像的复杂性自适应地调整计算量。此外,作者认为这样的改进还能提高模型的泛化能力。
2,相关工作
现有的提高Transformer效率的方法:
1)权重共享 2)动态控制注意力范围 3) 使用线性注意力机制来减少自注意力层的计算复杂度。4)剪枝 5)自适应计算时间 6)通过随机方法或强化学习来决定何时停止网络层的计算。7)动态ViT:使用额外的控制门和Gumbel-softmax技巧来学习停止token的时机。8)稀疏注意力 9)Transformer的变体,降低Transformer模块本身的复杂度 10)分辨率自适应网络 11)深度自适应网络等
3,模型整体结构
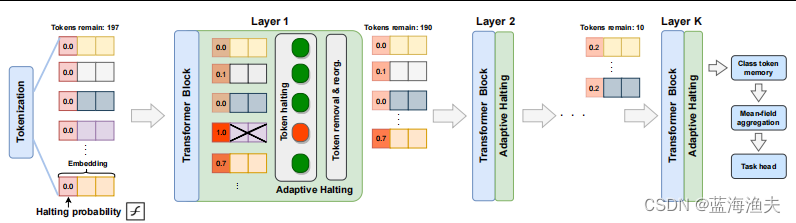
可以看出来,整体结构和正常的多层ViT模型一致。关键在于每个Transformer层都有自适应停止模块。
自适应停止模块为每个token计算一个停止概率。该模块使用现有transformer块中的参数,通过借用每个块中最后一个密集层的单个神经元来实现,不增加额外的参数。对于每个token,停止概率的公式如下:
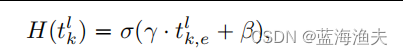
其中是在层
的token
的第e维,
是logistic sigmoid函数,γ 和 β 是两个可学习的参数,它们对嵌入向量进行平移和缩放。
当一个token的累积停止分数超过某个阈值时,该token将停止进一步的处理。一旦token满足停止条件,就会通过mask操作从后续层的计算中移除,以减少计算量。
众所周知,ViT模型中通过class token计算最终分类概率,对于这些class token也应用自适应停止机制。
4,损失函数
本文的损失函数是多种损失函数的组合:
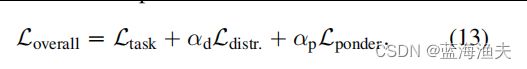
其中1) 是跟任务有关的损失函数;
2) 是分布先验正则化损失,这个损失用于将token的停止概率分布正则化到一个预定义的目标分布,通常是一个高斯分布,中心位于期望的停止深度,公式如下
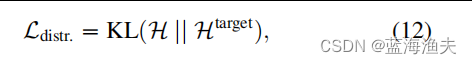
使用KL散度来正则化停止概率分布,H 是模型学习到的停止概率分布,是目标分布。通过最小化这个损失,模型学习在期望的深度停止token的计算。
3) 是跟token停止机制有关的损失函数,用于鼓励模型尽早停止对token的计算。这个损失通过一个辅助变量(reminder,r)来计算,旨在减少整体计算量,同时保持模型性能。公式如下:
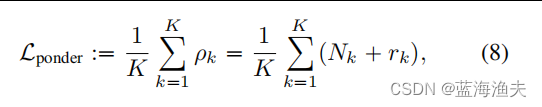
其中,是token
满足停止条件的层数。
是token
的余数(remainder),它是在达到停止条件之前累积的停止概率的剩余部分。
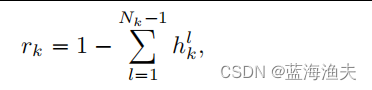
其中, 是在层
上token
的停止概率。
5,实验
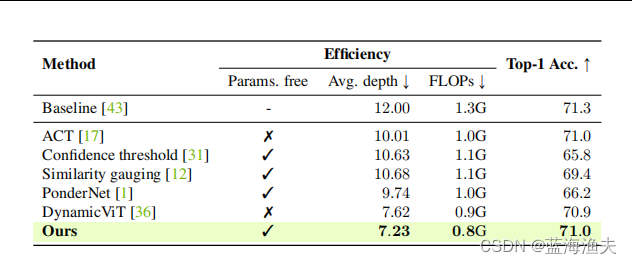
1)比较了A-ViT与其他几种动态推理停止机制的性能。
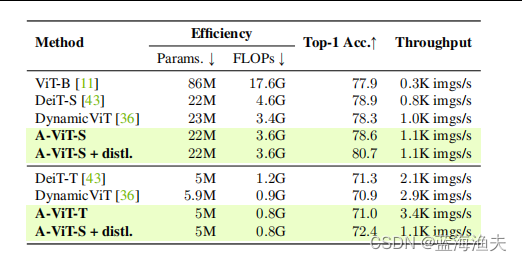
2)展示了A-ViT用在不同模型上的吞吐量改进。+ distil表示用上了蒸馏

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











