







BLIP
数据预处理
CapFilt:标题和过滤
由于多模态模型需要大量数据集,因此通常必须使用图像和替代文本 (alt-text) 对从互联网上抓取这些数据集。然而,替代文本通常不能准确描述图像的视觉内容,使其成为噪声信号,对于学习视觉语言对齐而言并非最佳选择。因此,BLIP 论文引入了一种标题和过滤机制 (CapFilt)。它由一个深度学习模型(可过滤掉噪声对)和另一个为图像创建标题的模型组成。这两个模型都首先使用人工注释的数据集进行微调。他们发现,使用 CapFit 清理数据集比仅使用网络数据集可产生更好的性能。
BLIP 架构
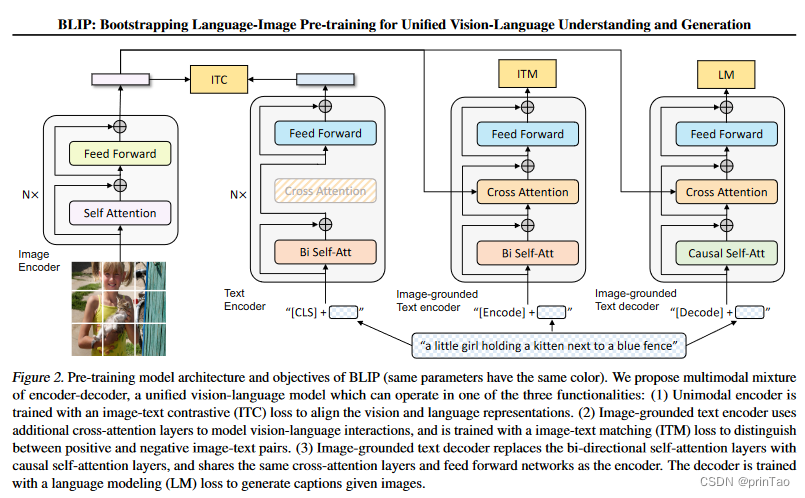
BLIP 架构结合了视觉编码器和多模态编码器-解码器混合 (MED),可实现对视觉和文本数据的多功能处理。其结构如下图所示,其特点是(具有相同颜色的块共享参数):
视觉变换器 (ViT):这是一个普通视觉变换器,具有自注意力、前馈块和用于嵌入表示的 [CLS] 标记。
单峰文本编码器:类似于 BERT 的架构,它使用 [CLS] 标记进行嵌入,并采用类似 CLIP 的对比损失来对齐图像和文本表示。
基于图像的文本编码器:这将 [CLS] 标记替换为 [Encode] 标记。交叉注意层可以集成图像和文本嵌入,从而创建多模态表示。它采用线性层来评估图像-文本对的一致性。
基于图像的文本解码器:用因果自注意力取代双向自注意力,该解码器通过交叉熵损失
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3393
3393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









