








分组(Group)的理解
处理数据时,在一个数据列表中会以某一列的元素作为参考基点,统计该列中每个不重复元素对应其他列的相关数据,这里可能我描述的比较复杂,可以通过下面两张表格数据处理前后帮助理解:
源数据为5列,分别为 age、gender、occupation、zip_code;
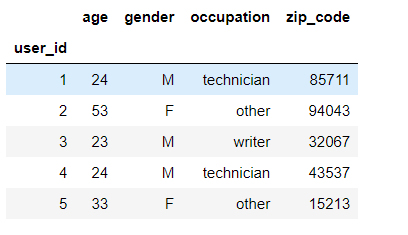
下面我需要对 occupation (职业)这一列进行分组分析、统计一下每类职业对应 gender、age 的最大、最小、平均值,处理结果如下:
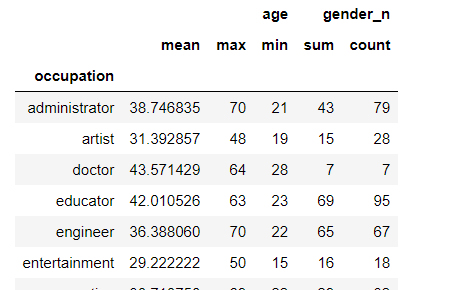
以上就是聚类分组的简单介绍,Pandas 包里提供了函数 goupby 进行日常操作,本文将基于 Pandas 的 groupby
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7957
7957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









