






转载自http://www.cnblogs.com/jmp0xf/archive/2013/05/14/Bias-Variance_Decomposition.html
完全退化了,不会分解,看到别人的分解方法了,留存。
以下为转载:
-----我是转载的昏割线-----
设希望估计的真实函数为
但是观察值会带上噪声,通常认为其均值为0
假如现在观测到一组用来训练的数据
那么通过训练集估计出的函数为
为简洁起见,以下均使用f^(X)代替f^(X;D)
那么训练的目标是使损失函数的期望最小(期望能表明模型的泛化能力),通常损失函数使用均方误差MSE(Mean Squred Error)
注意: yi和f^都是不确定的; f^依赖于训练集D, yi依赖于xi.
下面单独来看求和式里的通项
E[(yi−f^(xi))2]=E[(yi−f(xi)+f(xi)−f^(xi))2]
=E[(yi−f(xi))2]+E[(f(xi)−f^(xi))2]+2E[(yi−f(xi))(f(xi)−f^(xi))]
=E[ϵ2]+E[(f(xi)−f^(xi))2]+2(E[yif(xi)]−E[f2(xi)]−E[yif^(xi)]+E[f(xi)f^(xi)])
=Var{noise}+E[(f(xi)−f^(xi))2]
E[yif(xi)]=f2(xi) 因为f和xi是确定的而E[yi]=f(xi)
E[f2(xi)]=f2(xi) 因为f和xi是确定的
E[yif^(xi)]=E[(f(xi)+ϵ)f^(xi)]=E[f(xi)f^(xi)+ϵf^(xi)]=E[f(xi)f^(xi)]
E[ϵf^(xi)]=0 因为测试集中的噪声ϵ独立于回归函数的预测f^(xi)
E[ϵ2]=Var{noise} 噪声方差
E[(f(xi)−f^(xi))2]=E[(f(xi)−E[f^(xi)]+E[f^(xi)]−f^(xi))2]
=E[(f(xi)−E[f^(xi)])2]+E[(E[f^(xi)]−f^(xi))2]+2E[(f(xi)−E[f^(xi)])(E[f^(xi)]−f^(xi))]
=E[(f(xi)−E[f^(xi)])2]+E[(E[f^(xi)]−f^(xi))2]+2(E[f(xi)E[f^(xi)]]−E[E[f^(xi)]2]−E[f(xi)f^(xi)]+E[E[f^(xi)]f^(xi)])
=bias2{f^(xi)}+variance{f^(xi)}
E[f(xi)E[f^(xi)]]=f(xi)E[f^(xi)] 因为f是确定的
E[E[f^(xi)]2]=E[f^(xi)]2
E[f(xi)f^(xi)]=f(xi)E[f^(xi)] 因为f是确定的
E[E[f^(xi)]f^(xi)]=E[f^(xi)]2
E[(f(xi)−E[f^(xi)])2]=bias2{f^(xi)} 偏差
E[(E[f^(xi)]−f^(xi))2]=variance{f^(xi)} 方差
最终
因此,要使损失函数的期望E[Loss(Y,f^)]最小,既可以降低bias,也可以减少variance。这也是为什么有偏的算法在一定条件下比无偏的算法更好。
偏差 bias 描述的是算法依靠自身能力进行预测的平均准确程度
方差 variance 则度量了算法在不同训练集上表现出来的差异程度
下面来自The Elements of Statistical Learning P38 Figure 2.11 的图则阐释了模型复杂度与偏差、方差、误差之间的关系:
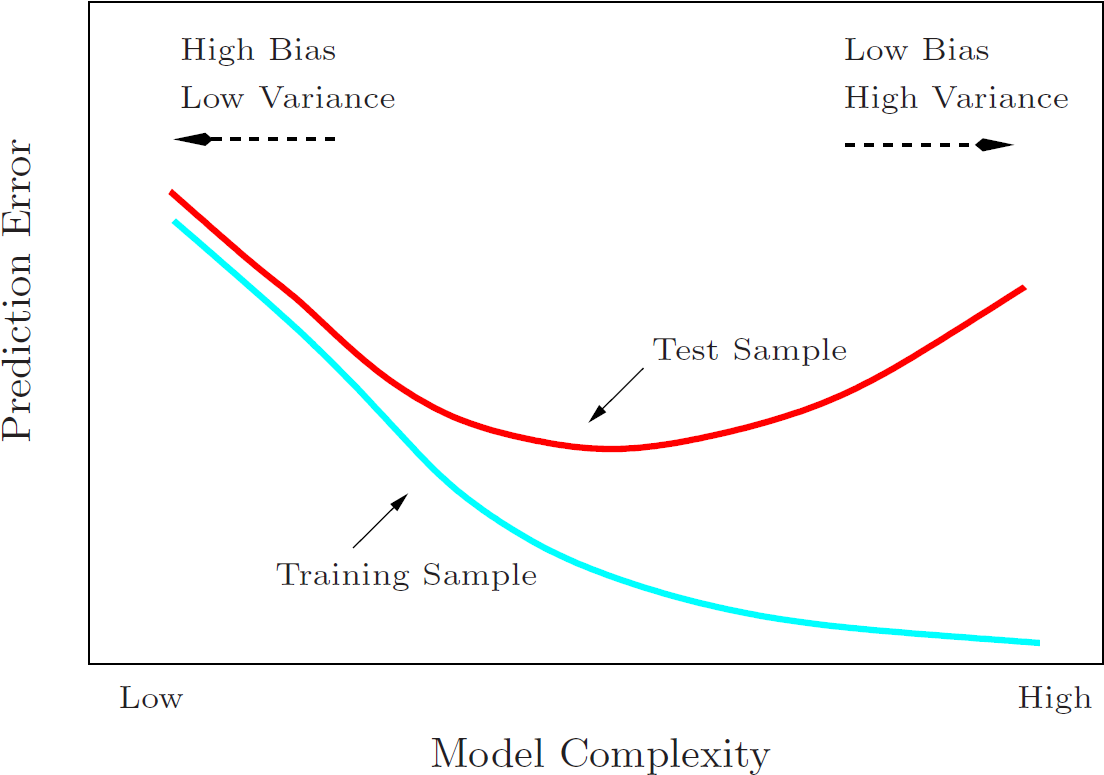
PS:
装袋算法Bagging通过bootstrap对训练集重采样来并行训练多个分类器(均匀采样),主要是降低方差 variance。
提升算法Boosting通过迭代调整样本权重来串行组合加权分类器(根据错误率采样),因而主要是降低偏差 bias(同时也减少方差 variance)。
参考资料:
http://www.inf.ed.ac.uk/teaching/courses/dme/2012/slides/ensemble.pdf
http://www.inf.ed.ac.uk/teaching/courses/mlsc/Notes/Lecture4/BiasVariance.pdf
http://www.dna.caltech.edu/courses/cns187/references/geman_etal.pdf















 5300
5300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









