






我们在上一篇文章中通过一个简单的样例算是入门卡尔曼滤波了。本文将以此为基础讨论一些技术细节。
卡尔曼滤波(Kalman Filter)
http://blog.csdn.net/baimafujinji/article/details/50646814在上一篇文章中。我们已经对HMM和卡尔曼滤波的关联性进行了初步的讨论。參考文献【3】中将二者之间的关系归结为下表。
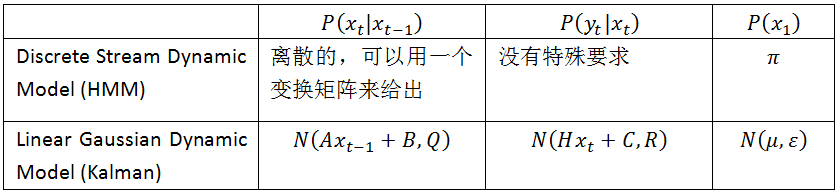
上表是什么意思呢?我们事实上能够以下的式子来表示,当中,w 和 v 分别表示状态转移 和 測量 过程中的不确定性,也即是噪声,既然是噪声就能够假设它们服从一个零均值的高斯分布。这事实上跟我们在上一篇文章中所给出的形式是一致的。也就是说我们觉得过去的状态假设是 xt-1。那么当前状态xt应该是 xt-1的一个线性变换。而这个预计过程事实上是有误差的,用一个零均值的高斯噪声(概率分布)来表达。
相似地,当前的測量值yt应该是真实值 xt 的一个线性变换。而这个測量过程仍然是有误差的,也用一个零均值的高斯噪声(概率分布)来表达。
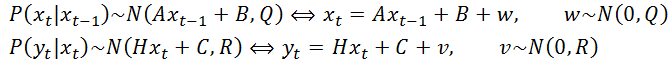
上一节中我们还讲过,在 [t0, t1] 时间段内的測量为Y,对应的预计为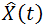
依据条件概率的链式法则以及马尔科夫链的无记忆性,再去掉常值系数的情况下,就能够得到以下的结论(假设你对有关数学公式记得不是非常清楚能够參考http://blog.csdn.net/baimafujinji/article/details/50441927)

当中,P( xt | y1, … , yt-1)就是Prediction(预測),由于它表示的意义是已知从1到t-1时刻的观測值y1, … , yt-1的情况下求 t 时刻的状态值xt。
还有一方面,P( xt | y1, … , yt)就是Update,由于它表示当我们已经获得yt时。再对xt 进行的一个更新(或修正)。
依据马尔科夫链的无记忆性,可知P( yt | xt, y1, … , yt-1) = P( yt | xt) 。
就预測部分而言。我们希望引入xt-1。所以能够採用以下的方法(这事实上就是我们在处理普通贝叶斯网络时所用过的方法)

到此为止。事实上你应该能够看出来卡尔曼滤波就形成了一个递归求解的过程。也就是说。我们欲求P( xt | y1, … , yt-1),就须要先求P( xt-1 | y1, … , yt-1),而欲求P( xt-1 | y1, … , yt-1),就要先求P( xt-2 | y1, … , yt-1) ……结合上一篇文章介绍的内容,事实上能够总结卡尔曼滤波的步骤例如以下

也就是说当t = 1时。我们依据观測值y1去预计真实状态x1,这个过程服从一个高斯分布。
然后。当t = 2时,我们依据上一个观測值y1去预測当前的真实状态x2,在获得该时刻的真实观測值y2后,我们又能够预计出一个新的真实状态x2。这时就要据此对由y1预測的结果进行修正(Update),如此往复。
接下来,我们引入一个服从零均值高斯分布的(噪声)变量 Δxt-1。

然后试着将Δxt和Δyt以Δxt-1的形式来给出,并且处于方便的考虑。我们忽略掉公式(1)中的控制项 B 和 C。于是有

依据独立性假设,还可知例如以下结论(这些都是兴许计算推导过程中所须要的准备):
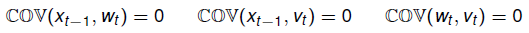
以下我们要做的事情就是推导卡尔曼滤波的五个公式,在上一篇文章中,我们很多其它地是从感性的角度给出了这些公式。并没有给出具体的数学推导,接下来我们就要来完毕这项任务。



综上我们已经完整地给出了卡尔曼滤波的理论推导。
对于结论性的东西。你当然能够直接拿来使用。
在一些软件包中,卡尔曼滤波无非是一条命令或者一个函数就能搞定。
我们之所以还在这里给出它的具体推导,主要是鉴于这样的思想事实上在机器学习中也被广泛地用到,所以了解这些技术细节仍然十分有意义。
===================================================================================================
假设你是图像处理的同道中人,欢迎增加图像处理算法交流群(单击链接查看群号)。
參考文献:
【1】Stuart Russell and Peter Norvig. Artificial Intelligence: A Modern Approach. 3rd Edition.
【2】秦永元,张洪钺,汪叔华,卡尔曼滤波与组合导航原理,西北工业大学出版社
【3】徐亦达博士关于卡尔曼滤波的公开课,http://v.youku.com/v_show/id_XMTM2ODU1MzMzMg.html
【4】卡尔曼滤波的原理以及在MATLAB中的实现,http://blog.csdn.net/revolver/article/details/37830675















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









