






文章链接:https://arxiv.org/abs/1904.01784v1
简介
受人类视觉注意力系统的启发,文章提出了一个叫Patchwork的模型,利用了记忆和注意力之间的微妙的相互作用来进行高效的视频处理。
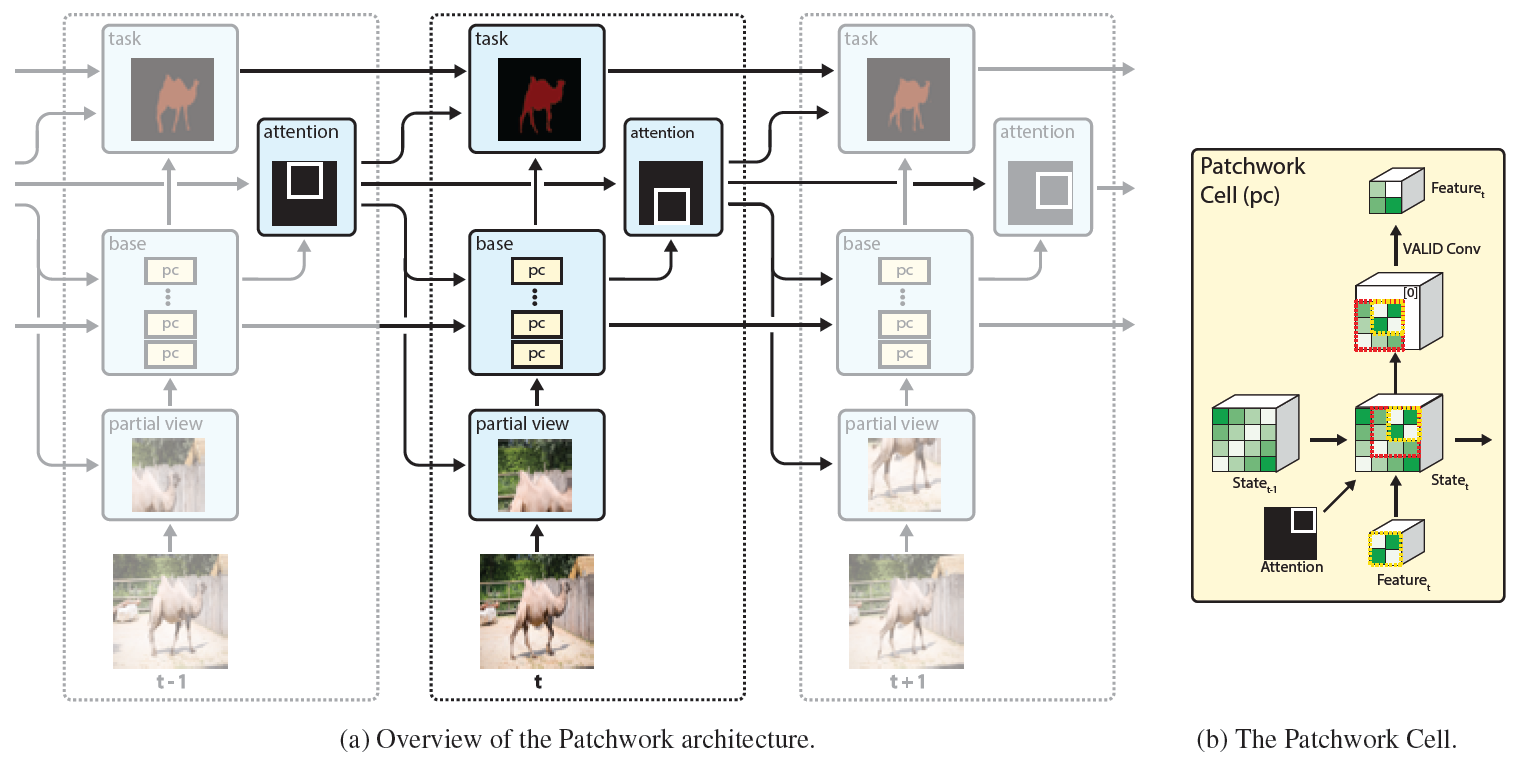
图1:a) 视频流中的每个时间步,我们的方法仅仅处理当前帧的一个小的局部窗,但由于一系列有状态的Patchwork cells,仍然能解释整张输入帧。
b) 状态patchwork cell的放大视图,通过之前状态的时间上下文特征来对当前特征进行调整。
图1a列出了Patchwork的概览。在每一个时间步,patchwork从输入帧上裁剪一个小窗送入一个特殊的特征提取网络,这个特征提取网络包含了一系列分散在网络主体中的专用记忆单元,
网络最终预测出检测结果或分割结果。此外,网络还会预测下一帧中最有可能包含有用信息的的attention window。
Patchwork的原始motivation是进行高效的视频流处理。换句话说就是在高质量地进行检测或分割任务的同时降低延迟和计算开销。在不需要考虑延迟的应用上,我们还能将节省下的资源用于提高质量。
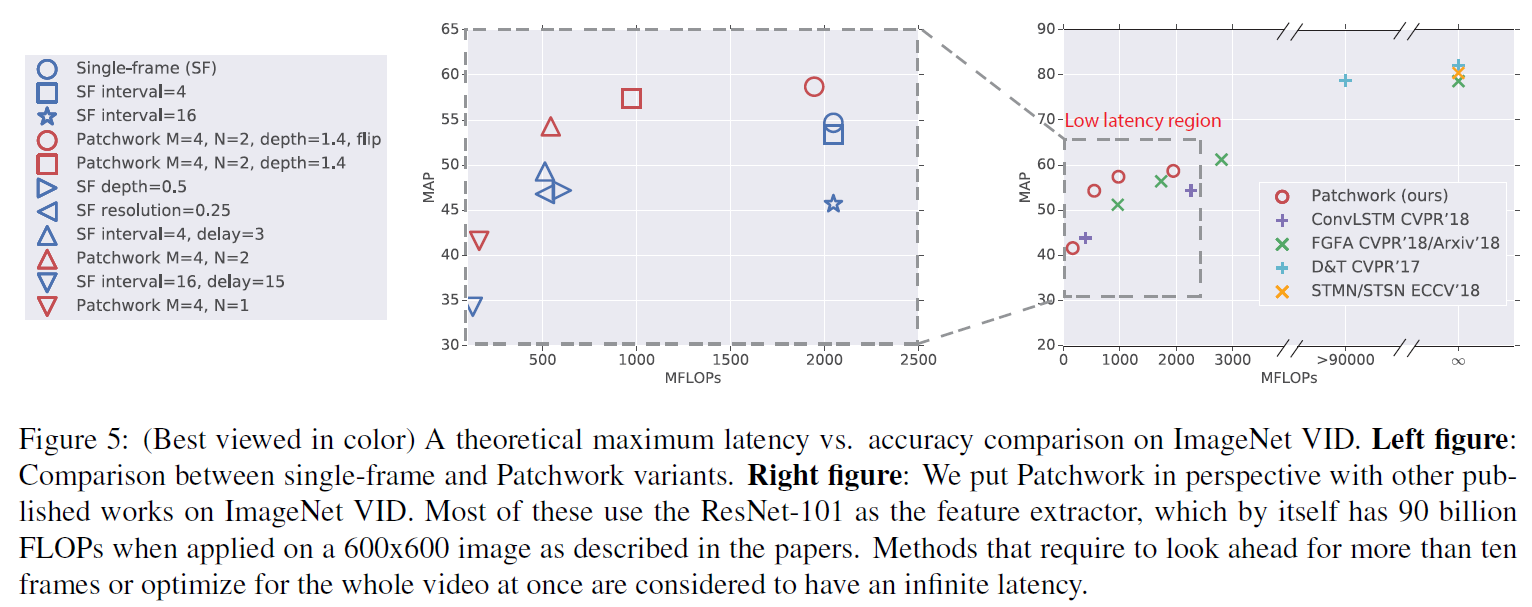
我们在两个数据集上证明了延迟下降和质量提高,分别是ImageNet VID,对应视频目标检测任务;DAVIS,对应视频目标分割。延迟的降低受一组超参数的控制。我们解释了一些超参数的选择在实验章节。
一些选择有效地降低了延迟但是对精度造成了一些影响,另一些节省了资源并且达到了相似的精度。还有一些在相当的计算量下精度得到提高的配置。
文章的贡献有三方面:1.提出了patchwork,一个受人类视觉感知系统启发的能高效处理视频流的循环结构。2.我们的方法利用Patchwork Cell作为存储单元,随时间传输环境信息。3.注意力模型可以预测下一帧中的要关注的最佳位置。
我们的方法通过使用了独特的目标检测和分割reward函数的Q-learning来训练。
Patchwork
如图1a中所示,patchwork结构是一个循环结构,对当前帧的预测可能会依耐于之前的所有帧。在每一个时间步,输入帧要经过四个步骤:裁剪小窗,特征提取,特定任务的预测,下一帧的attention预测。
在裁剪过程中,需要从当前帧上裁剪一个固定大小的窗,裁剪框的位置由之前帧预测。我们之所以选择固定窗的大小是考虑到计算开销同窗大小直接相关。在特征提取的stage,我们使用了mobileNetV2.我们
将其中含有大于1x1卷积核的卷积层都做了替换,换成了我们的状态patchwork单元。最后,attention和结果预测基于适当的层上面。
patchwork有两个意思。第一个是,它是PATCH-wise attention netWORK的混用词。此外,patchwork也是一个英语单词,表示将多块织物缝合在一起形成一个更大的设计,这类似推理过程中的每个patchwork单元。
recurrent attention
图1a展示了recurrent attention网络的大概结构。在之前的文章中,注意力窗使用它的中心和大小进行参数化。训练中,在边界上使用有梯度的光滑关注窗,因此可以以有监督的方式来进行端到端的训练;此外,利用好
策略梯度进行强化学习。注意,这些先前工作中的实验仅限于MNIST和Cifar等数据集,这解释了为什么我们在复杂的真实场景的目标检测和分割任务中使用这两种方法只取得了有限的成功。我们最好的结果来源于离散动作空间
的Q-learning方法。
这个离散动作空间包含了所有可能的attention局部窗,由两个整数M和N来参数化。M表示一个维度被均分的份数,即将原图均分为M x M块,每一块的长宽是[w/M,h/M];N表示构成一个attention窗的连续块数的个数,一个attention窗
由N x N个小块组成(个人感觉这个地方原文表述不太清楚)。我们的实验中包含了下面三种配置。M=2,N=1,则有4个可能的窗,每个相对原图的大小为[1/2,1/2]。将这些窗用左上角开始编号,[i/2,j/2],i=0,1;j=0,1.M=4,N=2有9个可能的窗,每个相对原图大小为[1/2,1/2]。将这些窗用左上角开始编号,[i/4,j/4],i=0,1,2;j=0,1,2。M=4,N=1有16个可能的窗,每个相对大小为[1/4,1/4],,用左上角编号,[i/4,j/4],i=0,1,2,3;j=0,1,2,3。
注意M和N控制了计算推理的计算量。举个例子,M=2,M=1的配置将每个attention窗的大小控制为原图的25%,总的计算量也粗略地降为原来的25%。
接下来,我们构建了attention网络,从时间t的网络中得到一系列特征并将它们映射到用于deep Q-learning(DQN)的的Q值\(Q(S_t,A_t;\Theta)\).attention网络构建于patchwork记忆单元之上,而这一记忆单元拥有对全帧的view。此外,我们同样也希望attention网络能够了解历史动作,以此来激发其动作多样性。最后,我们设计了一个简单的指数衰减的动作历史函数 \(F_t\):
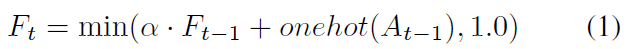
其中\(A_{t-1}\)是上一时间步的动作,即attention窗选择,\(\alpha\)是衰减系数。
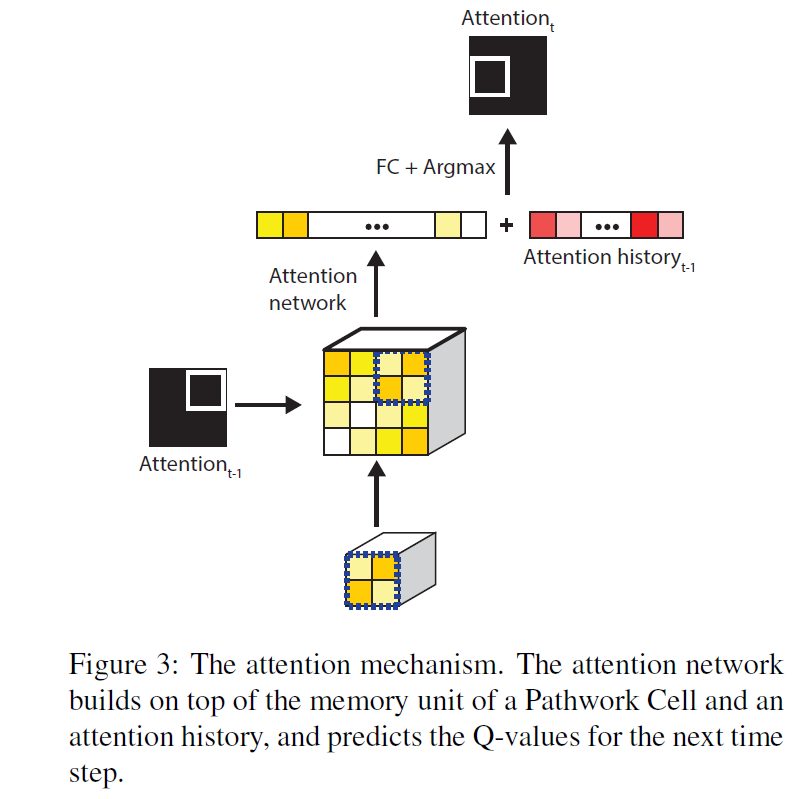
如图3所示,一个patchwork记忆单元被映射至一个一维特征向量,并和动作历史concat在一起,最后通过一个全连接层来计算Q值。
patchwork cell
现在的深层卷积网络拥有比输入图片大小还要大的感受野,这些大感受野对之后使用上下文信息是非常重要的。但是recurrent attention 模型隔断了这些感受野,对输入帧的裁剪会损失掉一些上下文信息。
我们在表2的实验结果显示了如果不能合理的处理这种信息丢失,会带来结果的显著下降。我们引入了patchwork cell来进行补救,见图1b。
现在的深层卷积网络中的使用same padding的2d卷积是无状态的,而patchwork单元要对其进行一个有状态的改进。2d卷积定义是\(SameConv2d(X,\Theta)\to Y\),其中X是输入的feature map,\(\Theta\)是一个大小为\((2k+1)^2\)的
卷积核的权重。不失一般性地,我们设stride为1,\(X_t\)和\(Y_t\)具有相同地空间分辨率[H,W].
patchwork单元增加了两个状态量,记忆单元\(S_t\),动作变量\(A_t\),定义为\(Patchwork(X_t,A_t,S_t,\Theta)\to Y_t\),其中下标t表示时间步。这一cell包含三个部件:状态更新,特征传播和使用VALID padding的2d卷积。
State update. 在时间步t从初始的裁剪窗提取的特征用于更新记忆状态\(S_{t-1}\),并计算新的状态\(S_{t}\)。
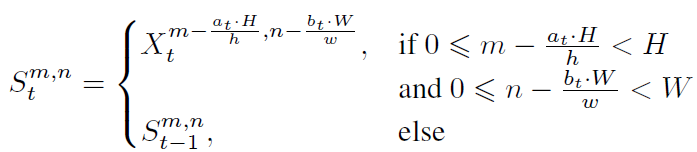
![]() 上标表示坐标,\([a_t,b_t]\)是相对左上角的位置的attention窗。[h,w]是窗的相对高度和宽度,我们的实验中设为[0.5,0.5]和[0.25,0.25]。
上标表示坐标,\([a_t,b_t]\)是相对左上角的位置的attention窗。[h,w]是窗的相对高度和宽度,我们的实验中设为[0.5,0.5]和[0.25,0.25]。
feature propagation:我们通过过去的状态\(S_{t-1}\)来调整输入特征\(X_t\).这个操作相当于从当前状态\(S_{t}\)中裁剪一个稍大一点的特征\(\hat{X_t}\):
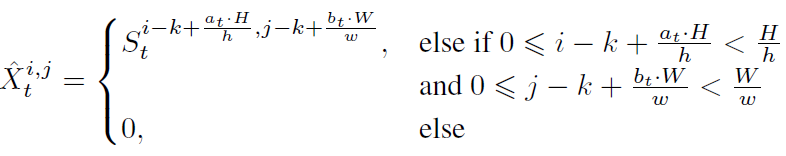
其中![]()
最后,利用valid padding的2d卷积得到\(Y_t\),\(Y_t=ValidConv2d(\hat{X_t},\Theta)\).
patchwork cell被放置在网络中的很多位置,在全局操作之前,在每一个same padding且卷积核大于1的卷积之前都放一个patchwork cell。
注意由patchwork cell提供的上下文信息并不是准确的,是估计得到的:1)单元中存储的特征是从过去的帧中提取的用于增强当前帧的陈旧的特征。当场景变化时这个估计错误会更加严重。
2)patchwork cell提供的上下文信息和自然感受野不一样。
Q-Learning reward
之前已经定义好了state,action和Q-function,我们需要选择一个合适的reward来训练这个attention网络。一个好的time-difference(TD(0)) reward应当连续,一个中庸的action应当得到一个比优秀的action更小的reward。
同时它还应当具有较小的方差,reward还应当与action更多的关联而不是和场景。因此,mAP和mIOU就不适合作为一个reward 函数了,因为他们很大程度上取决于场景的难易。
本文从原始的reward中去掉了fixed baseline来减小方差。对于视频,我们可以轻易地用之前帧地预测结果来得到当前的action来作为baseline.也就是说,我们定义TD(0) reward \(R_t\)为:
![]()
其中gt和p分别是groundtruth和预测结果,\(f(gt,p)\)是metric,t是时间步。直觉告诉我们,只有当新的attention窗对对metric有贡献时才会给一个reward,否则什么都不给。我们设定reward为非负的,因为任何负的reward都表明对场景有了一个较大变化,这对于解释场景是不利的,这一变化严格来说应当是由噪声引起的。
至于任务地metric f,对于分割,我们使用frame-wide mIoU metric(J-measure in DAVIS). 同时,对于目标检测,mAP度量已经不合适了,因为它是量化的且不能反应增量改进。我们从分割任务中得到启发,定义了一个average box overlap度量来作为目标检测的reward:\(f(gt,p)=\frac{1}{K}\sum_{1}^K IoU(gt_k,\widetilde{p_k})\)
其中每一个分数高于0.5的预测都匹配一个groundtruth框来得到\(\widetilde{p_k}\).然后我们呢将所有K个groundtruth框的IoU分数求平均。注意,为了简单起见我们省略了类别标签。
我们使用DDQN来训练Q-function估计\(Q(S_t,A_t;\Theta)\)中的权重\(\Theta\):
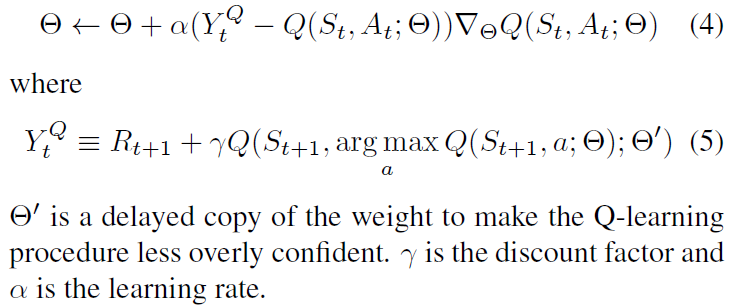
实验结果:
MobileNet V2+SSD















 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









