






协同过滤,之所以协同是因为该方法是基于其他用户进行推荐的。工作流程如下:假设我们的任务是向你推荐一本书。我们会在网络上搜索与你相似兴趣的用户。一旦找到了这个用户,就看看这个用户喜欢的书,然后将其推荐给你。
如何寻找相似用户?一般而言,通过计算两个用户的距离,两个用户距离越小则相似度越高。先来看距离的定义。
1 曼哈顿距离(Manhattan Distance)N维下,表示为:d(x,y)=sigma(|xk-yk|) (k=1...n)
2 欧氏距离 (Euclidean Distance) N维下,表示为:d(x,y)=(sigma((xk-yk)2))1/2 (k=1,2...n)
3 明氏距离 (Minkoeski Distance) N维下,表示为:d(x,y)=(sigma(|xk-yk|r))1/r ,可见,当r=1时,即为曼哈顿距离,r=2时为欧氏距离,r=∞时,为上确界距离(Supermun Distance)
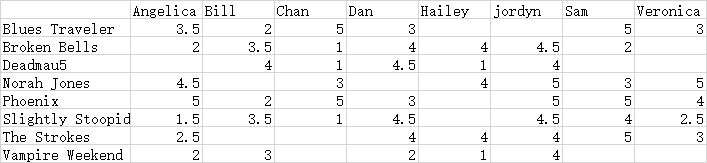
以下是8个用户对8个音乐的评分。通过计算两个人的明氏距离来实现推荐
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果'
import xlrd
import json
def load_datas(filepath):
wb = xlrd.open_workbook(filepath)
table = wb.sheet_by_name('Sheet1')
users = {} # 用户字典
for c in range(1,table.ncols): # 循环每一列
name = table.cell_value(0,c) # 用户名
users[name] = {} # 建立空字典
for r in range(1,table.nrows): # 循环每一列
if table.cell_value(r,c): # 如果当前值不空
key = table.cell_value(r,0)
value = float(table.cell_value(r,c)) #建立字典
users[name][key] = value
return users
def minkowski(rating1,rating2,r):
"""
Compute the minkowski diatance between tow uses
"""
distance = 0.0
for key in rating1:
if key in rating2:
distance += pow((abs(rating1[key]-rating2[key])),r)
return pow(distance,1./r)
def find_nearest_neighber(username,users):
"""
Create a sorted list bsaed on their distance
"""
neighbers = []
for user in users:
if username != user:
d = minkowski(users[username],users[user],2)
neighbers.append((d,user))
# sort by distance
neighbers.sort(cmp)
return neighbers # 返回最近的人
def recommend(username,users):
"""
Give list of recomends
"""
recommends = []
neighber = find_nearest_neighber(username,users)[0][1]
for artist in users[neighber]:
if artist not in users[username]:
recommends.append((artist,users[neighber][artist]))
return sorted(recommends,key = lambda artist_tupe:artist_tupe[1],reverse = True)
def test():
filepath = r'C:\Users\TD\Desktop\PythonProject\records.xlsx'
users = load_datas(filepath)
print recommend('Chan',users)
print recommend('Hailey',users)
if __name__ == '__main__':
test()
用户评级差异
对用户评级结果进行考察发现,单个用户的评级行为差距很大。上表中,Bill想避免极端结果,它的评级都在2到4之间,而Jordy好像喜欢任何乐队,他的评级都在4到5.而Hailey只有两种选择,不是1就是4.解决这个问题的方法是考虑皮尔逊相关系数(Pearson Correlation Coefficient) 。皮尔逊相关系数是度量两个变量的相关性指标,取值区间为[-1,1]
值越接近1表示相关性越好。皮尔逊计算公式如下:
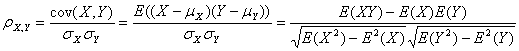
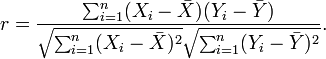
但是一般而言,上述公式计算复杂度达到O(n2)。实际应用时采用以下近似公式:

有这样一个列子,在音乐播放器上有1.5亿首歌曲,现在来考虑歌曲播放的次数问题。对于个人而言,播放的歌曲数有限,可能就4000首,也就是说其他歌曲播放次数为0,于是对于个人来说,得到的数据信息是很稀少的。而在1.5亿首个上去比较2个人时,绝大部分公共为0.这种情况下,无论使用明氏距离还是皮尔逊相关系数都是不明智的。我们还有一种选择,那就是余弦相似度,公式如下:
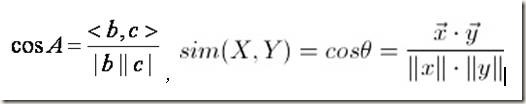
也就是欧氏空间中两个N维向量的夹角的余弦。余弦相似度取值在1到-1之间,1表示完全相似,-1表示完全不相似。
那么问题来了。上面说了三个相似度,在时间问题中如何选择呢?可以按照以下规则:
1 如果数据稠密(几乎所有的属性搜没有0值),那么使用明氏距离比较合适
2 如果数据受到分数贬值(即为不同用户使用不同的评价范围),则使用皮尔逊相关系数比较合理
3 如果数据稀疏(很多0出现),那么考虑使用余弦相似度是合理的
一些怪异的事情:
当我们在依赖最相似的用户进行推荐时,该用户的个人怪癖也会被推荐,而这些怪癖别是可能是不喜欢的。一种解决的办法是基于多个相似用户进行推荐。这里采用k近邻法。在协同过滤的k近邻法中,我们用k个最相似的用户来确定推荐结果。每一个用户根据相似度大小获得一个权重。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果'
import json
import sys
from math import sqrt
from pprint import pprint
class Recommender(object):
def __init__(self, data,k = 1,n = 5):
"""
initialize recomender,data is dict
k is the value for k nearest neighbor
n is the maximum number recommendations to make
"""
self.k = k
self.n = n
if type(data).__name__ == 'dict':
self.data = data
else:
raise Exception('输入数据类型必须是字典')
sys.exit(1)
def pearson(self,rating1, rating2):
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += x ** 2
sum_y2 += y ** 2
if n == 0:
return 0
denominator = sqrt(sum_x2 - (sum_x ** 2) / n) * sqrt(sum_y2 - (sum_y ** 2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - sum_x * sum_y / n) / denominator
def find_nearest_neighbors(self, username):
neighbors = []
for user in self.data:
if username != user:
per = self.pearson(self.data[user],
self.data[username])
neighbors.append((user,per))
return sorted(neighbors,key = lambda element:element[1],reverse = True)
def recommend(self,username):
neighbors = self.find_nearest_neighbors(username)
tol_distance = 0
for i in range(self.k):
tol_distance += neighbors[i][1]
recommends = {}
user_ratings = self.data[username]
for i in range(self.k):
name = neighbors[i][0]
neighbor_ratings = self.data[name]
weight = neighbors[i][1]/tol_distance
for artist in neighbor_ratings:
if artist not in user_ratings:
try:
recommends[artist] += weight*neighbor_ratings[artist]
except KeyError:
recommends[artist] = weight*neighbor_ratings[artist]
recommends = [(item[0],item[1]) for item in recommends.items()]
recommends.sort(key = lambda element:element[1],reverse = True)
return recommends[:self.n]
def test():
filepath = r'C:\Users\TD\Desktop\PythonProject\records.json'
with open(filepath,'rb') as f:
data = json.load(f)
instance = Recommender(data)
print instance.recommend('Hailey')
if __name__ == '__main__':
test()















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









