






推导了支持向量机的数学公式后,还需要对比和总结才能更深入地理解这个模型,所以整理了十一个关于支持向量机的问题。
第一问:支持向量机和感知机(Perceptron)的联系?
1、相同点:
都是一种属于监督学习的二类分类器,都属于判别模型。感知机是支持向量机的基础。
2、不同点:
(1)学习策略:感知机是用误分类损失函数最小的策略,求得分离超平面。M为误分类点个数,则目标函数为
![]()
支持向量机是用几何间隔最大化的策略,求最优分离超平面。某点的几何间隔为:
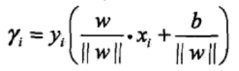
线性可分支持向量机的目标函数和优化问题为:

支持向量机的分离超平面不仅要将正负例点分开(感知机做的事情),还有对分离超平面最近的点也要有足够大的确定度把它们分开。
(2)优化算法:感知机的最优化算法是随机梯度下降法。支持向量机的最优化算法是通过拉格朗日乘子法,得对偶问题,再用求解凸二次规划的算法来做(SMO)。
(3)解的个数:感知机的解是不唯一的,而支持向量机的解是唯一的。
(4)感知机追求最大程度正确划分所有的点,最小化错误,很容易造成过拟合;支持向量机追求大致正确分类的同时,一定程度上避免过拟合。
(5)感知器能处理的问题就是二分类问题。但支持向量机不同,有了核方法的加持,处理非线性问题也是可以的。支持向量机还能解决多分类问题。另外支持向量机中的支持向量回归(SVR)还可以解决回归问题。
(6)感知机的目标函数是经验风险,而线性支持向量机带合页损失函数的目标函数是结构风险,加了L2范数的正则化项。
第二问:支持向量机和逻辑回归(LR)的联系?
1、相同点:
(1)不考虑核函数的话,都是线性分类器,都是求一个最佳分类超平面
(2)都是监督学习算法,都属于判别模型。
2、不同点:
(1)损失函数不同
逻辑回归的损失函数是交叉熵损失函数:
![]()
而支持向量机转化为拉格朗日形式的目标函数为:

从另一个角度理解,支持向量机的目标函数是加了正则化项的hinge loss 损失函数:

支持向量机自带了正则项(L2范数),是结构风险最小化的算法,而逻辑回归解决过拟合问题需要另外加正则项:
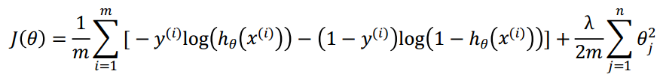
(2)支持向量机基于距离分类,逻辑回归基于概率分类
逻辑回归基于概率理论,假设样本为正样本的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值。
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面。支持向量机依赖数据表达的距离测度,所以需要对数据先做Normalization,而逻辑回归不受其影响。
(3)对数据和参数的敏感程度不同
支持向量机在决定分离超平面时只有支持向量起作用,在间隔边界以外移动、增加或减少其他实例点对分类决策函数不会有任何影响。
逻辑回归受所有数据点的影响,直接依赖数据分布,每个样本点都会影响决策面的求解结果。
(4)在解决非线性问题时,支持向量机采用核技巧,而逻辑回归不采用
在非线性分类问题中,确定分类决策函数时,支持向量机中只有少数的支持向量参与到核函数的运算,计算复杂度不高。而逻辑回归如果也运用核技巧,那么所有样本点都必须参与核计算,那么计算复杂度非常高。
第三问:支持向量机为什么采用间隔最大化?
1、间隔最大化是指支持向量机的策略是学习能够正确划分数据集并且几何间隔最大的分离超平面。间隔最大不是指函数间隔最大,而是指几何间隔最大。某点与分离超平面的几何间隔是:
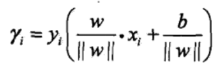
即样本点到分离超平面的距离。
2、当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。而线性可分支持向量机利用间隔最大化求得最优分离超平面,解是唯一的。
3、对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类,这样的超平面对未知的新实例有很好的分类预测能力(泛化能力强)。
第四问:为什么要转化为对偶问题?
1、对偶问题更容易求解,通过拉格朗日函数把目标函数和条件约束整合成了一个新函数,化简后转化为求解一个变量的问题。
2、非常自然地引入核函数,从而推广到非线性分类问题。
(1)线性支持向量机的对偶问题的目标函数为:
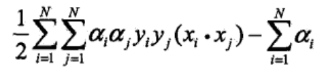
(2)将对偶问题目标函数中的內积![]() 用核函数
用核函数![]() 来代替,就成了引入核函数后的目标函数:
来代替,就成了引入核函数后的目标函数:
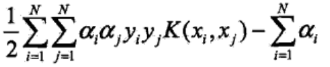
第五问:为什么要引入核函数?
1、为了解决线性不可分问题
当样本点在原始空间线性不可分时,可以将输入空间映射到更高维的特征空间,使样本在新的特征空间线性可分,从而可以用线性分类方法来求解。核技巧就属于这种方法。
2、为了解决映射函数可能带来的特征空间维度过高问题
定义了核函数K(x,y)=<ϕ(x),ϕ(y)>,那么向量在特征空间的内积等于它们在原始空间中通过核函数 K 计算的结果。那么就可以直接在低维空间计算两个向量的內积,而不需要显式地定义映射函数,求解难度降低。因为如果用映射函数,那么新特征空间的维度可能很高,甚至是无穷维,导致计算<ϕ(x),ϕ(y)>非常困难。
第六问:常见的核函数有哪些?怎么选择合适的核函数?
1、常见的核函数有:

2、只要一个对称函数所对应的的核矩阵(Gram矩阵)是半正定的,它就能作为核函数使用,这个对称函数称为正定核函数。半正定矩阵是指如果A是实对称矩阵,对任意非零列向量x有![]() ,那么称A为半正定矩阵。
,那么称A为半正定矩阵。
3、一般选择线性核和高斯核。当样本的特征很多,和样本数量差不多时,往往样本线性可分,可考虑用线性核函数;当特征较少,样本的数量很多时,可以手动添加一些特征,使样本线性可分,再考虑用线性核函数;当特征较少,样本数量一般时,考虑用高斯核函数(RBF核函数的一种,指数核函数和拉普拉斯核函数也属于RBF核函数)。
第七问:介绍一下高斯核函数?
1、高斯核函数的公式为:
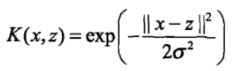
2、高斯核函数是一种局部性较强的核函数,可以将样本从原始空间映射到无穷维空间,其外推能力随着参数σ的增大而减弱。
3、如果 σ 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上相当于一个低维的子空间;反过来,如果 σ 选得很小,则可以将任意的数据映射为线性可分。因此,通过调控参数σ,高斯核具有非常高的灵活性,是使用最广泛的核函数。
第八问:为什么支持向量机对缺失数据敏感?
1、这里说的缺失数据是指缺失某些特征数据,向量数据不完整。支持向量机没有处理缺失值的策略(决策树有)。
2、支持向量机希望样本在特征空间中线性可分,所以特征空间的好坏对支持向量机的性能很重要。缺失特征数据将影响训练结果的好坏。
第九问:支持向量机怎么解决过拟合问题?如何调整惩罚参数C?
1、在完全线性可分的数据中,支持向量机没有过拟合问题。
2、在线性不可分的数据集中,异常点的存在导致支持向量机过拟合,而通过引入松弛变量,使支持向量机能够容忍异常点的存在,一定程度上解决了过拟合。线性支持向量机带有hinge loss 损失函数的目标函数为:
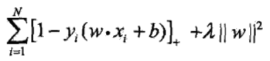
加了正则化项,采用结构风险最小化,故可解决过拟合问题。
3、而在非线性可分的情况下,非线性支持向量机是核函数+软间隔最大化的支持向量机,过拟合问题来自于核函数和允许误分类点的存在。
(1)选择的核函数过于powerful,比如多项式核函数的次数太高,高斯核函数的参数 σ太小,那么就需要调整参数来缓解过拟合问题;
(2)软间隔最大化时参数C越大,对误分类点的惩罚越大,使得被判为误分类的点越多,于是造成过拟合,C无穷大时退化为硬间隔分类器。那么通过减小C来解决。
第十问:什么是支持向量机的支持向量?
在分类问题中,分线性可分和基本线性可分两种情况讨论:
1、在线性可分支持向量机中,样本点中与分离超平面最近的向量(间隔边界上的向量)就是支持向量。支持向量满足:![]() 。
。
2、在线性支持向量机中,支持向量分三种:
(1)在分离超平面间隔边界上的向量;
(2)在分离超平面上的向量;
(3)在间隔边界和分离超平面之间的向量(包含正确分类和误分类的)。
第十一问:支持向量机的优点和缺点?
1、优点:
(1)支持向量机的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(2)稀疏性,在小样本集上分类效果通常比较好。
(3)有一套坚实完整的理论来解释原理,利用核函数代替向高维空间的非线性映射,降低了计算复杂度。
(4)少数支持向量决定了最终结果,不仅有利于抓住关键样本、剔除大量冗余样本,而且具有较好的“鲁棒”性,泛化能力较强。这种“鲁棒”性主要体现在:增、删和移动非支持向量对模型没有影响;有些成功的应用中,支持向量机对核的选取不敏感。
2、缺点:
(1)支持向量机对大规模训练样本难以实施。由于支持向量机是借助凸二次规划来求解支持向量,而求解凸二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。
(2)用支持向量机解决多分类问题存在困难。传统的支持向量机就是解决二分类问题的,尽管有不少解决多分类问题的支持向量机方法,不过各种方法都存在一定程度上的缺陷。
(3)对缺失值敏感,核函数的选择与调参比较复杂。
参考资料:
1、李航:《统计学习方法》
2、周志华:《机器学习》
3、吴恩达:《机器学习》
4、https://blog.csdn.net/szlcw1/article/details/52259668
5、https://blog.csdn.net/a857553315/article/details/79586846
6、https://blog.csdn.net/touch_dream/article/details/63748923
7、https://blog.csdn.net/jieming2002/article/details/79317496














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









