






1、用TensorFlow训练一个物体检测器(手把手教学版) - 陈茂林的技术博客 - CSDN博客.html(https://blog.csdn.net/chenmaolin88/article/details/79357263)
ZC:看的是这个教程,按照步骤一步一步来,做到 训练的 地方,家里的笔记本 出现了如下的报错(公司的没报错...)
2、报错现象为:(如下图)
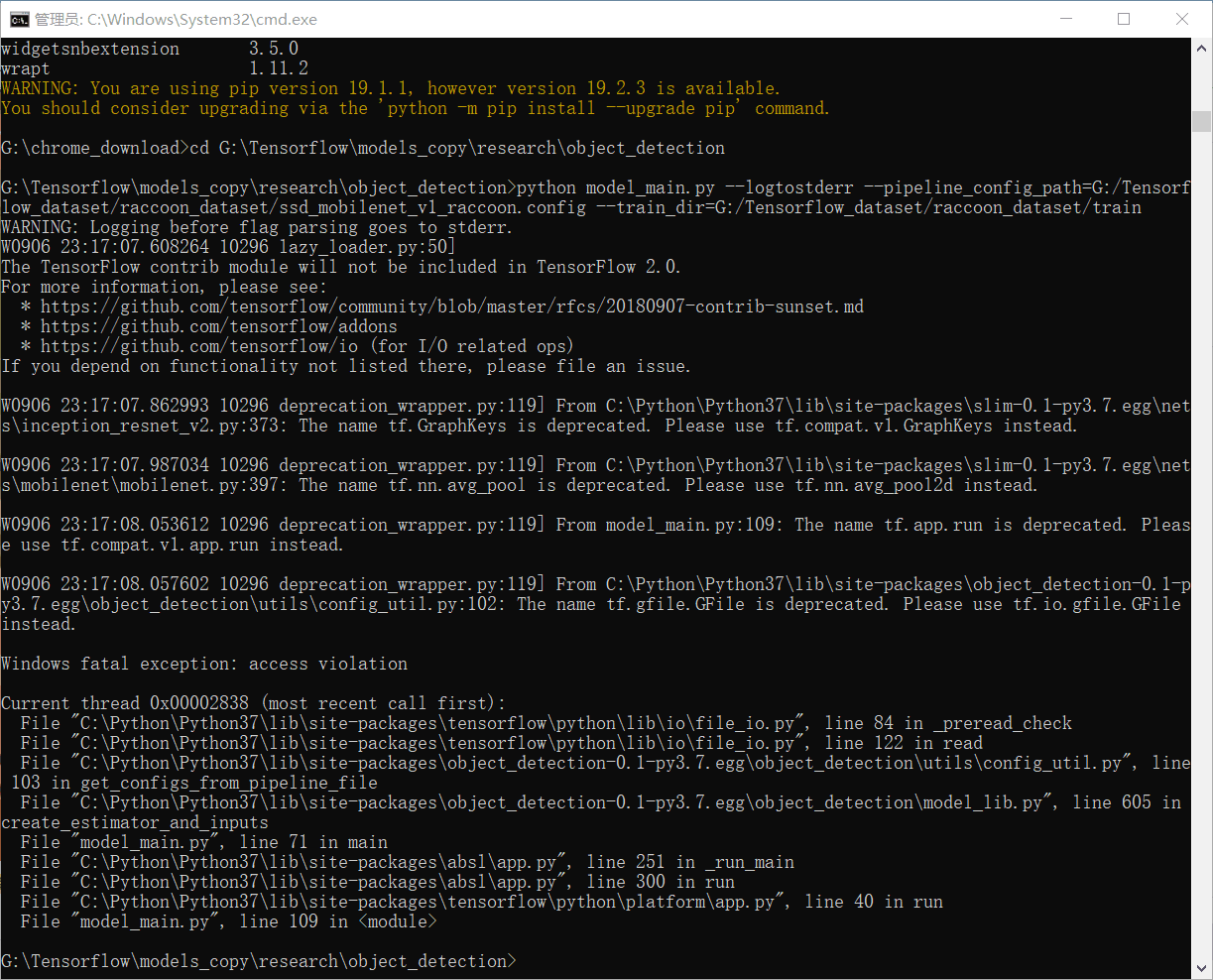
2.1、看这个报错现象,怎么看 我也想不到是 找不到文件... 于是心里 就有了第一印象:文件有,肯定是 哪个操作 出现了错误。
2.2、第一眼 看到 _pre??? 还以为是线程什么的报错... 后来仔细看 才发现是 io操作,然后网上 查资料。
资料很少,相关的倒是也有 基本现象一样 但是解决方案是 降版本&将CPU的版本换成GPU的版本;还有看到一个外文网站上倒是说 可能是 文件名 / 路径 写错了,我也查了 但是由于 第一印象不是找不到文件 就只是大概的对了一下,发现没错 就pass了这个可能性...
朝着 函数出错的方向来找:根据上面的 报错信息 一步一步的 debug跟到 函数_preread_check(...)中 发现它调用的是 pywrap_tensorflow.CreateBufferedInputStream(...) 再stepin是 _pywrap_tensorflow_internal.CreateBufferedInputStream(...) 再想往里就 进不去了。度搜“_pywrap_tensorflow_internal.CreateBufferedInputStream” 倒也有相关信息 但是它的问题是dll找不到,要下载 VC++相关版本的 可再发行组件包(Redistributable Package)(vc_redist???.exe)。
但是 我不知道 这个函数对应的 dll是哪个啊... 于是 没办法的情况下 瞎试,想到 我用的 tensorflow whell 是 vs2019编译的,于是 下载了 vs2019的可再发行组件包,发现还是不行,然后 把机子里面所有的 可再发行组件包都删掉,vs2017也删掉(排除干扰,我当时的想法是:我怕是使用了 早期版本的DLL,而没有使用vs2019的DLL。老版的dll可能是缺少了什么 才导致出错的),反正能删的都删了,重新安装 vs2019的 可再发行组件包,重启OS,报错依旧... 然后 又尝试将所有相关的 可再发行组件包&vs 等软件都删掉的情况下,安装 vs2019社区版,下载好 安装后,报错依旧... 此路暂时不通了...
上面不通了,函数出错的另一个想法是 DLL应该都对了,那可能是 哪里出错呢?肯定是 tensorflow调用的时候出错了,但是 源码跟不进去了,然而 在源码注释的地方 看到 源码的编译时通过 swig的,于是查了&下载了相关swig,想自己编译tensorflow,看看 到底是使用了哪个WindowsDLL,到底是哪里出错了。但是 查了 一下 看到有人说 比较麻烦,且我想 不一定成功,于是 此路 先放放...
现在 没办法了啊,又想到 降版本的方案:虽然我的笔记本不是N卡 无法用GPU的版本,但是 会不会 tensorflow版本不同 调用的WindowsAPI有所差异??关键是 貌似 重装tensorflow在之前弄过,很方便,一点都不麻烦。于是 试试,将1.14.0的Py37.CPU(AVX2)版本 降到 1.13.0的Py37.CPU(AVX2)版本,然后再跑 Py程序,还是出错(绝望?No!报错信息 不同了!),如下图:
C:\Python\Python37\python.exe G:/Tensorflow/models_copy/research/object_detection_zz/model_main_zz.py --logtostderr --pipeline_config_path=G:\Tensorflow_dataset\raccoon_dataset\ssd_mobilenet_v1_raccoon.config --train_dir=G:/Tensorflow_dataset/raccoon_dataset/train
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
Traceback (most recent call last):
File "G:/Tensorflow/models_copy/research/object_detection_zz/model_main_zz.py", line 139, in <module>
tf.app.run()
File "C:\Python\Python37\lib\site-packages\tensorflow\python\platform\app.py", line 125, in run
_sys.exit(main(argv))
File "G:/Tensorflow/models_copy/research/object_detection_zz/model_main_zz.py", line 71, in main
FLAGS.sample_1_of_n_eval_on_train_examples))
File "C:\Python\Python37\lib\site-packages\object_detection-0.1-py3.7.egg\object_detection\model_lib.py", line 605, in create_estimator_and_inputs
pipeline_config_path, config_override=config_override)
File "C:\Python\Python37\lib\site-packages\object_detection-0.1-py3.7.egg\object_detection\utils\config_util.py", line 103, in get_configs_from_pipeline_file
proto_str = f.read()
File "C:\Python\Python37\lib\site-packages\tensorflow\python\lib\io\file_io.py", line 125, in read
self._preread_check()
File "C:\Python\Python37\lib\site-packages\tensorflow\python\lib\io\file_io.py", line 85, in _preread_check
compat.as_bytes(self.__name), 1024 * 512, status)
File "C:\Python\Python37\lib\site-packages\tensorflow\python\framework\errors_impl.py", line 528, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: NewRandomAccessFile failed to Create/Open: G:\Tensorflow_dataset\raccoon_dataset\ssd_mobilenet_v1_raccoon.config : ϵͳ\udcd5Ҳ\udcbb\udcb5\udcbdָ\udcb6\udca8\udcb5\udcc4\udcceļ\udcfe\udca1\udca3
; No such file or directory
Process finished with exit code 1
ZC: 可以看到,同样是 报的函数_preread_check(...)出错,但是报错信息 已经 明确指出:“No such file or directory”。
ZC:此时才确认 真的是 文件找不到的缘故,此时再次核对 文件名&路径,发现 命令行中用的是 ssd_mobilenet_v1_raccoon.config,而我文件夹里面的文件名是 ssd_mobilenet_v1_reccoon.config ...... 改了,就好了... ... (公司的文件名是raccoon 没想到家里的是reccoon... 两边用的一样的命令行... )(原本还想,如果还是核对不出来的话,就再看看 有没有大小写区分,用代码 枚举所有文件夹&文件名 用以检查 里面有没有 Explorer中看不见的怪异字符)
PS:中间 还有人说到 是 protobuf踩到了不该踩的虚拟内存地址 才报的错,于是 把原来安装的 protobuf 卸载了,又用"pip install protobuf" 装了一遍,没用
3、
4、
5、测试时使用的 "G:\Tensorflow\models_copy\research\object_detection_zz\model_main_zz.py"(文件夹"object_detection_zz" 是直接复制的 文件夹"object_detection",然后改名的;文件"model_main.py" 也是直接复制的 文件"model_main_zz.py",然后改名的)
5.1、得到 文件夹"object_detection_zz" 后,直接使用 PyCharm 打开 文件夹"object_detection_zz",然后 用 PyCharm来 run/debug model_main_zz.py 。
5.2、model_main_zz.py的内容:
# Copyright 2017 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== """Binary to run train and evaluation on object detection model.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function from absl import flags import tensorflow as tf from object_detection import model_hparams from object_detection import model_lib flags.DEFINE_string( 'model_dir', None, 'Path to output model directory ' 'where event and checkpoint files will be written.') flags.DEFINE_string('pipeline_config_path', None, 'Path to pipeline config ' 'file.') flags.DEFINE_integer('num_train_steps', None, 'Number of train steps.') flags.DEFINE_boolean('eval_training_data', False, 'If training data should be evaluated for this job. Note ' 'that one call only use this in eval-only mode, and ' '`checkpoint_dir` must be supplied.') flags.DEFINE_integer('sample_1_of_n_eval_examples', 1, 'Will sample one of ' 'every n eval input examples, where n is provided.') flags.DEFINE_integer('sample_1_of_n_eval_on_train_examples', 5, 'Will sample ' 'one of every n train input examples for evaluation, ' 'where n is provided. This is only used if ' '`eval_training_data` is True.') flags.DEFINE_string( 'hparams_overrides', None, 'Hyperparameter overrides, ' 'represented as a string containing comma-separated ' 'hparam_name=value pairs.') flags.DEFINE_string( 'checkpoint_dir', None, 'Path to directory holding a checkpoint. If ' '`checkpoint_dir` is provided, this binary operates in eval-only mode, ' 'writing resulting metrics to `model_dir`.') flags.DEFINE_boolean( 'run_once', False, 'If running in eval-only mode, whether to run just ' 'one round of eval vs running continuously (default).' ) FLAGS = flags.FLAGS def main(unused_argv): flags.mark_flag_as_required('model_dir') flags.mark_flag_as_required('pipeline_config_path') config = tf.estimator.RunConfig(model_dir=FLAGS.model_dir) train_and_eval_dict = model_lib.create_estimator_and_inputs( run_config=config, hparams=model_hparams.create_hparams(FLAGS.hparams_overrides), pipeline_config_path=FLAGS.pipeline_config_path, train_steps=FLAGS.num_train_steps, sample_1_of_n_eval_examples=FLAGS.sample_1_of_n_eval_examples, sample_1_of_n_eval_on_train_examples=( FLAGS.sample_1_of_n_eval_on_train_examples)) estimator = train_and_eval_dict['estimator'] train_input_fn = train_and_eval_dict['train_input_fn'] eval_input_fns = train_and_eval_dict['eval_input_fns'] eval_on_train_input_fn = train_and_eval_dict['eval_on_train_input_fn'] predict_input_fn = train_and_eval_dict['predict_input_fn'] train_steps = train_and_eval_dict['train_steps'] with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print("estimator :\t", estimator) print("train_input_fn :\t", train_input_fn) print("eval_input_fns :\t", eval_input_fns) print("eval_on_train_input_fn :\t", eval_on_train_input_fn) print("predict_input_fn :\t", predict_input_fn) print("train_steps :\t", train_steps) print() print("FLAGS.model_dir :\t", FLAGS.model_dir) print("FLAGS.pipeline_config_path :\t", FLAGS.pipeline_config_path) print("FLAGS.num_train_steps :\t", FLAGS.num_train_steps) print("FLAGS.eval_training_data :\t", FLAGS.eval_training_data) print("FLAGS.sample_1_of_n_eval_examples :\t", FLAGS.sample_1_of_n_eval_examples) print("FLAGS.sample_1_of_n_eval_on_train_examples :\t", FLAGS.sample_1_of_n_eval_on_train_examples) print("FLAGS.hparams_overrides :\t", FLAGS.hparams_overrides) print("FLAGS.checkpoint_dir :\t", FLAGS.checkpoint_dir) print("FLAGS.run_once :\t", FLAGS.run_once) # print("FLAGS. :\t", FLAGS.) print() print("FLAGS.model_dir :\t", FLAGS.model_dir) print("FLAGS.hparams_overrides :\t", FLAGS.hparams_overrides) print("FLAGS.pipeline_config_path :\t", FLAGS.pipeline_config_path) print("FLAGS.num_train_steps :\t", FLAGS.num_train_steps) print("FLAGS.sample_1_of_n_eval_examples :\t", FLAGS.sample_1_of_n_eval_examples) print("FLAGS.sample_1_of_n_eval_on_train_examples :\t", FLAGS.sample_1_of_n_eval_on_train_examples) # if FLAGS.checkpoint_dir: # if FLAGS.eval_training_data: # name = 'training_data' # input_fn = eval_on_train_input_fn # else: # name = 'validation_data' # # The first eval input will be evaluated. # input_fn = eval_input_fns[0] # if FLAGS.run_once: # estimator.evaluate(input_fn, # steps=None, # checkpoint_path=tf.train.latest_checkpoint( # FLAGS.checkpoint_dir)) # else: # model_lib.continuous_eval(estimator, FLAGS.checkpoint_dir, input_fn, # train_steps, name) # else: # train_spec, eval_specs = model_lib.create_train_and_eval_specs( # train_input_fn, # eval_input_fns, # eval_on_train_input_fn, # predict_input_fn, # train_steps, # eval_on_train_data=False) # # # Currently only a single Eval Spec is allowed. # tf.estimator.train_and_evaluate(estimator, train_spec, eval_specs[0]) if __name__ == '__main__': tf.app.run()
6、
7、
8、
9、















 6163
6163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









