






今天有点空,聊个IT监控系统中常见的小细节:主机热力图。
所谓主机热力图,就是采用矩阵热力图的方式,来展现环境内一批主机的健康状态。类似的界面应该大家都比较熟悉。我这先贴几个业内最有名的实现:
- 阿里云的容器服务热力图:
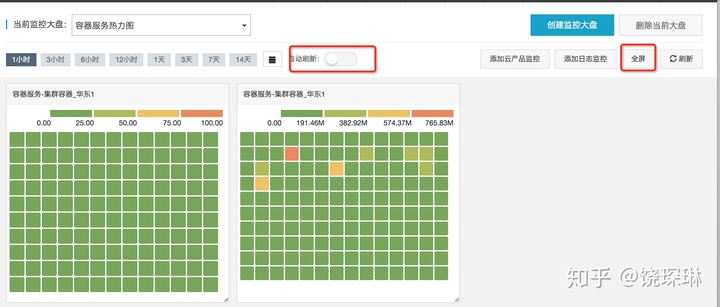
2. datadog的主机热力图:

3. SignalFx的基础设施概览图:
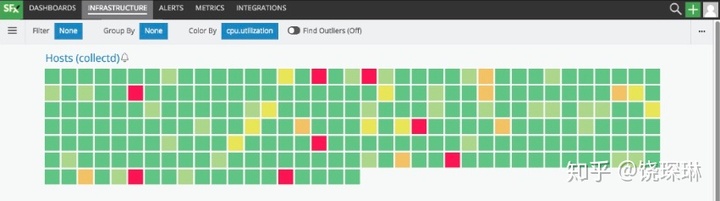
国内外例子太多,就不一一例举了。从这些图例里,可以看到他们的用法和功能设计有几点共性:
- 用颜色深浅来表示负载程度,一般而言越深的负载越高,越可能不太健康。
- 支持采用某些固定维度进行分组展示,一般来说,比如机房啊,设备类型啊等。
- 负载程度的具体指标是可选的。通常会采用:内存使用率、CPU使用率、磁盘使用率、带宽使用率等可以有比较明确对比意义的百分比指标。
看似很不错,基础运维需求就是一眼了解全局的运行状态嘛。但是问题来了:实际主机上跑的业务类型各不一样,一个MySQL主机和一个LVS主机,能用同一个指标来衡量自己的工作负载情况么?
第二个问题:就算按照datadog那样,按业务和机型做分组,保证每个组里的主机确实可以用相同的指标衡量。你又怎么确定到底多深的颜色是「有点忙」,多深的颜色是「注意,要挂了」,多深的颜色是「完蛋,喊人」呢?
SignalFx的应对办法是:额外加了一条规则,如果这台主机有关联的告警产生,就把对应的色块直接置为红色。
实在是简单粗暴啊——但是告警本身也有轻有重有误报,这又怎么办?
事实上,AIOps领域还真的有些研究,在尝试用算法解决这个问题——按照综合情况,而不是单一的指标/告警,来评定主机的负载健康状态。
注意:一般我们说健康度,大家听过更多的都是业务层面的,因为业务层面可以选取最最重要的某个指标作为代表,然后其他指标作为该指标的不同维度,做个分类算法,就能判断业务健康了。
但是主机,谁也说不好用哪个指标来代表啊?就必须要「无中生有」了。
今天这里稍微介绍一下的,是北卡州立大学顾晓晖教授在2012年发表的一篇论文:
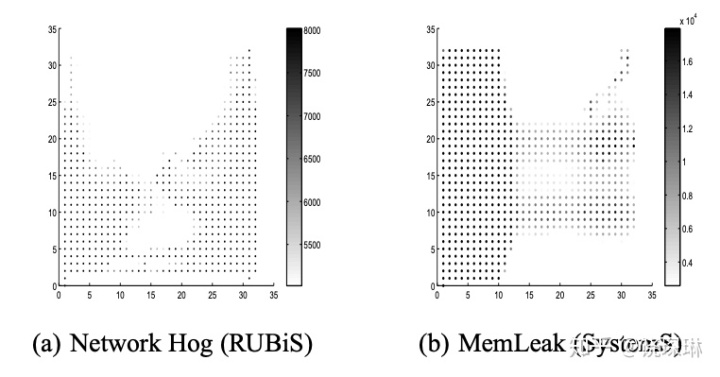
UBL: Unsupervised Behavior Learning for Predicting Performance Anomalies in Virtualized Cloud Systemsdance.csc.ncsu.edu论文中,对IaaS云主机采集了各种基础性能指标,采用自组织映射神经网络算法(Self Organizing Map, SOM),聚类并构成一个 32*32 维的 1024 神经元的拓扑图。
接着,如何表示图上每个节点代表的系统健康状态呢?办法是计算它邻近区域的大小,并以此作为节点的颜色深浅的值。
由于训练数据都是正样本,在算法做过一些权重调整以后,聚类之间的距离比较合适,那么每个节点的邻近区域大小也都差不多,换而言之,这张拓扑图上的颜色深浅看起来也就都差不多。
等模型上线运行以后,如果实际数据体现在拓扑图上,某个节点颜色过深,那就代表这片区域的系统状态有问题了。如下图,是论文中两个场景举例:
作为热力图的部分,其实就这样了。但是作为UBL,显然还可以把热力图代表的异常情况,作为告警发出,并进行一定的根因分析推荐。
分析推荐过程也非常简单:既然已经有了颜色最深的那个节点,依次往外扩散找邻居节点,但是要找的是颜色依然正常的。如果邻居都不正常,就找隔一跳的邻居,直到凑够了5个正常邻居。然后把这5个节点所代表的主机性能指标集拿出来,挨个和异常节点的做5次相关性排序。然后简单多数投票,得到最终的top5的根因指标推荐。
SOM是个特偏门的算法,具体过程就留给读者自己阅读论文吧。
注1:UBL系统已经被顾教授申请专利了哦:U.S. Patent Application No. 14/480,270。包括国内,也有类似做「无中生有」型设备健康度的专利申请,比如:国防科大的CN201410690233.9。大家核心思想,都是认定稳态下,所有设备的健康度应该趋向一致。
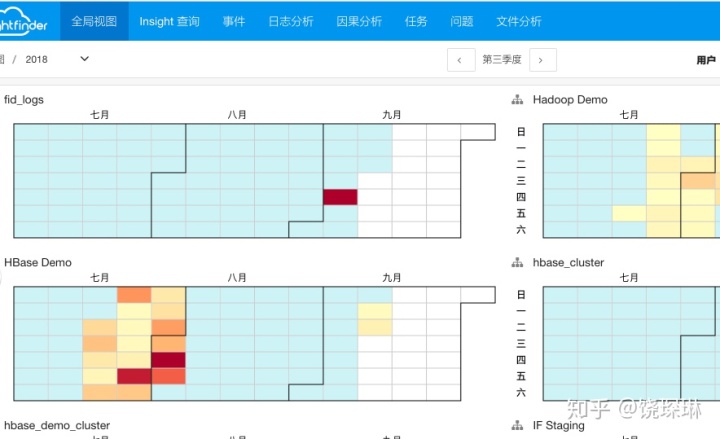
注2:主机热力图加上时间变化趋势,就可以变种为分面日历热力图,也是一种不错的监控可视化方法。下图是顾教授做的产品效果:














 7013
7013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









