






5. 奥卡姆剃刀和信仰守恒定律
在对世界的学习,感知和思考中,我们用经验数据来拟合模型。通常情况下我们的假设空间将跨越复杂程度大不相同的多个模型:一些模型将有更多的自由参数或比其它模型自由度更高。
在传统模型拟合方法中,我们调整每个模型参数直到最符合,严格上说具有更多自由参数或可调旋钮的模式将被优先,不论实际上它是否更接近描述生成该数据的真实过程,但是,这不是我们思考的方式,我们使用奥卡姆剃刀的自然眼来评估模型,为了避免数据的“过度拟合“和确保成功的概括和预测,需要平衡数据匹配度和模型复杂度,以避免“过拟合“我们的数据和确保成功的概括和预测复杂的数据。
稀疏采样数据的拟合曲线(或平滑函数)、噪声数据的问题就是熟知的例子。

上图显示了三种多项式拟合:一个1阶(线性),一个2阶(二次),以及一个12阶多项式的。我们该如何决定上面哪些拟合最代表了数据呢?第一个模型粗略捕获了数据的趋势但似乎太粗糙,我们还可以看到一些“信号”到“噪音”的属性变化;二阶模式似乎最好的,它的复杂度刚好适合拟合数据的主要形态,免于过度匹配噪声数据;12阶模式似乎可笑地过度拟合了,它可以调整的参数,使曲线准确地通过13个数据点的每一个,这样把“噪音”也都当成了“信号”。再次我们把这个作为因果推理的一个问题:每个函数代表了一个假设的因果过程,导致了所观察到的数据,在函数输入输出中,将噪音也添加到了输出中。
在贝叶斯推理上下文中出现了奥卡姆剃刀这种优雅和强大的形式,也叫贝叶斯奥卡姆剃刀,贝叶斯奥卡姆剃刀是指“更复杂的”关于数据的假设在条件推理中会被自动抑制的,这里复杂性的概念是“灵活性”:一个假设如果灵活到足以产生许多不同的观测就是比较复杂的,也成为不太可能的。因为更复杂的假设需要更多的描述数据集,根据信仰的守恒定律,每一个就只能分配到一个较低的概率。如果在其他条件相同时,我们以一些数据为条件,那么,假设的后验分布将有利于更简单的,因为它们能更“好”的拟合观察数据。
从概率编程的角度看,贝叶斯奥卡姆剃刀是必需的,我们不会根据最佳拟合来判断模型,而是根据它们的平均表现。条件推理中本身并不进行拟合,相反,我们用每个模型最可能的情况进行条件采样,如果一个模式的平均拟合度高—能产生与数据一致的历史采样相对较多—要比只能适应几个非典型参数设置但平均情况要差很多的模型要好得多。我们有时称之为信仰守恒定律。如果信念是观测数据如何产生的因果历史而信仰程度是某些历史采样的相对频率,那么,然后一个模型在所有可能历史空间传播的信仰总和是固定的。如果你相信A非常强烈,你不太可能也相信B或C非常强烈,因为,为了强烈相信A,大部分时间必须产生A的采样。
5.1 大小原则
贝叶斯奥卡姆剃刀的一个简单例子来自于大小原则(泰拉贝尔和格里菲思,2001年):在与数据一致的许多假设中,随着观察数据的增加,最小的那个会迅速成为最有可能的假设。
下面的Church程序用一个非常简单的模型进行演示,使用了两个的符号假设集:大的有10个元素和小的有3个元素,然后随机选择一个假设,再均匀地从它里面采样一些符合。
(define samples
(mh-query
100 100
(define (hypothesis->set hyp)
(cond ((equal? hyp 'Big) '(a b c d e f g h i j))
((equal? hyp 'Small) '(a b c))))
(define hypothesis (if (flip) 'Big 'Small))
(define (observations N) (repeat N (lambda () (uniform-draw (hypothesis->set hypothesis)))))
hypothesis
(equal? (observations 1) '(a))
)
)
(hist samples "Size Principle")
只观察一个a,已经倾向于小的假设。如果我们的条件再增加数据量会发生什么呢?
(define samples
(mh-query
100 100
(define (hypothesis->set hyp)
(cond ((equal? hyp 'Big) '(a b c d e f g h i j))
((equal? hyp 'Small) '(a b c))))
(define hypothesis (if (flip) 'Big 'Small))
(define (observations N) (repeat N (lambda () (uniform-draw (hypothesis->set hypothesis)))))
hypothesis
(equal? (observations 3) '(a b a))
)
)
(hist samples "Size Principle")
可以从这个例子看出,随着数据量的增加,小的假设迅速占据了后验分布。为什么会这样呢?当我们均匀地从假设空间采样时,信仰守恒定律告诉我们从大的集合一个采样的概率是1/10而小的集合是1/3,因此,随着观察数的变化,大的集合的概率的变化幅度1/10,而小的集合的概率变化幅度是1/3,显然,随着观察数的增加,后者概率的减少速度远远慢于前者。上述后验分布为:
因为我们的假设是等可能的,所以可简化为:
因此,我们看到在这种情况下假设的后验分布是在给定假设下观测数据的归一化的可能性,因为小的是“简单“的而且迅速主宰了后验分布。
我们注意到,大小原则与语言学的颇有影响的理念—子集原则—是相关的,直觉上子集原则建议:当两个语法都符合相同的数据时,生成语言规模较小的语法言应该是首选。
5.1.1 例子:概念学习
这个矩形学习游戏说明了大小原则在概念学习中的作用。采样数据假定为从未知矩形中的随机样本。如果给定采样数据,能确定它们来自什么样的长方形吗?研究一下学习到的概念如何随采样点数量和采样点分布变化:
(define true-noise-var 0.01)
(define true-lower-bound-x (uniform 0 1))
(define true-upper-bound-x (uniform 0 1))
(define true-lower-bound-y (uniform 0 1))
(define true-upper-bound-y (uniform 0 1))
(define num-examples 5)
(define true-concept (lambda () (list (uniform true-lower-bound-x true-upper-bound-x) (uniform true-lower-bound-y true-upper-bound-y))))
(define true-data (repeat num-examples true-concept))
(define obs-data (map (lambda (x) (map (lambda (y) (gaussian y true-noise-var)) x)) true-data))
(define obs-data-a '((0.2 0.6) (0.2 0.8) (0.4 0.8) (0.4 0.6) (0.3 0.7)))
(define obs-data-b '((0.4 0.7) (0.5 0.4) (0.45 0.5) (0.43 0.7) (0.47 0.6)))
(define obs-data-2 '((0.4 0.7) (0.5 0.4)))
(define obs-data-4 '((0.4 0.7) (0.5 0.4) (0.46 0.63) (0.43 0.51)))
(define obs-data-6 '((0.4 0.7) (0.5 0.4) (0.46 0.63) (0.43 0.51) (0.42 0.45) (0.48 0.66)))
(define obs-data obs-data-4)
(define num-examples (length obs-data))
(define samples
(mh-query
500 100
(define lower-bound-x (uniform 0 1))
(define upper-bound-x (uniform 0 1))
(define lower-bound-y (uniform 0 1))
(define upper-bound-y (uniform 0 1))
(define noise-var true-noise-var)
(define (noisy-equals? x y)
(= 0.0 (gaussian (- x y) noise-var)))
(define concept (lambda () (list (uniform lower-bound-x upper-bound-x) (uniform lower-bound-y upper-bound-y))))
(define recon-data (repeat num-examples concept))
(list lower-bound-x
upper-bound-x
lower-bound-y
upper-bound-y)
(fold (lambda (x a) (and x a))
true
(map (lambda (y z) (and (noisy-equals? (first y) (first z)) (noisy-equals? (second y) (second z))))
recon-data obs-data))
))
(truehist (append '(0.0 1.0) (map first samples)) 10 "lower-bound-x")
(truehist (append '(0.0 1.0) (map second samples)) 10 "upper-bound-x")
(truehist (append '(0.0 1.0) (map third samples)) 10 "lower-bound-y")
(truehist (append '(0.0 1.0) (map fourth samples)) 10 "upper-bound-y")
(define mean-bounds (map mean (list (map first samples) (map second samples) (map third samples) (map fourth samples))))
(define var-bounds (map variance (list (map first samples) (map second samples) (map third samples) (map fourth samples))))
(display obs-data)
(display mean-bounds)
(display var-bounds)
(define (adjust points)
(map (lambda (p) (+ (* p 150) 25))
points))
(define paper (make-raphael "my-paper" 200 200))
(raphael-points paper
(adjust (map first obs-data))
(adjust (map second obs-data)))
(raphael-lines
paper
(adjust (list (first mean-bounds) (first mean-bounds) (second mean-bounds) (second mean-bounds) (first mean-bounds)))
(adjust (list (third mean-bounds) (fourth mean-bounds) (fourth mean-bounds) (third mean-bounds) (third mean-bounds))))
(raphael-lines paper
(adjust (list 0 0 1 1 0))
(adjust (list 0 1 1 0 0)))
'done
5.1.2 大小原理和隐性否定证据
理解大小原理的一种方法就是在概率推理中考虑隐含的负面否定证据。更灵活的假设能产生更多的观测。因此,如果这些假设是真的,那么,我们会看到更多不同数据变化;如果数据没有包含它们的话,那么,就是对这些假设的否定的证据形式。重要的是大小原则告诉我们,假设的先验分布没有必要进行复杂的惩罚办法,假说本身的复杂性就会使它成为不受欢迎的后验分布。
5.2信仰的守恒定律
这里需要强调概率模型的一个看似微不足道的,但在推理上经常被重复想到的方面。在贝叶斯统计中,我们将概率想成是信仰的程度。我们的生成模型反映了世界的知识,而分配给采样空间值的概率反映我们相信一个可能性的强烈程度。概率理论的法则保证了我们的信念在我们推理时仍然是一致的。
信仰一致的维护结果称为信仰守恒定律(LCB),下面是这一原则的两个等价形式:
1、一个分布的抽样选择有且只有一个可能(这样它隐含地拒绝了所有其它的可能的值)。
2、一个分布的概率的总和必须等于1,也就是说,我们只有一个信念可以流传。
从第二个形式可产生讨论生成模型的一个公用隐喻:通常我们可以将信仰看作“钱“,它在样本采样时会根据概率被“化掉“的,如果一种结果的构造更贵的话,那就是不太可能的。
信仰守恒定律的一个推论是,在其它所有条件相同的情况下,两个命题的相关信仰保持不变。更确切地说,当以一个命题为条件时,有些以前可能的事件会变成不可能的事件(即有概率0);除非为了是命题为真去改变概率,但其它命题的概率占比将保持不变。理解何时概率“必须改变“微妙的,因为它是一个生成模型完整依赖结构的属性。
5.3大小原则的推广:贝叶斯奥卡姆剃刀
前面我们说明贝叶斯奥卡姆剃刀的例子都严格基于所涉及假设的大小,然而这个原则还要更普遍。贝叶斯奥卡姆剃刀可以这样说,在所有其它条件相同的情况下,数据似然性最高的假设将将主导后验分布。根据信仰守恒定律,观测数据更高的似然性就意味着其它可能数据的低似然性。请看下面的例子:
(define observed-letters '(a b a b c d b b))
(define samples
(mh-query
100 100
(define (hypothesis->parameters hyp)
(cond ((equal? hyp 'A) (list '(a b c d) '(0.375 0.375 0.125 0.125)))
((equal? hyp 'B) (list '(a b c d) '(0.25 0.25 0.25 0.25)))))
(define hypothesis (if (flip) 'A 'B))
(define (observe) (apply multinomial (hypothesis->parameters hypothesis)))
hypothesis
(equal? observed-letters (repeat (length observed-letters) observe))
)
)
(hist samples "Bayes-Occam-Razor")
这个例子与以往的大小案例不同,两种假设的大小一样,但是,假设A偏向A和B--虽然它可以产生C和D,但可能性不大,在这个意义上假设A没有B灵活。两个假设的所有元素在观测数据中都有,但是由于有更多的样本倾向于假设A,后验分布就会倾向于该假设。贝叶斯奥卡姆剃刀的出现是自然的,我们往往可以通俗地说它倾向于不灵活的假设。
如果假设B不再均匀分布,但与假设A的偏向不同:
(define observed-letters '(a b a c d))
(define samples
(mh-query
100 100
(define (hypothesis->parameters hyp)
(cond ((equal? hyp 'A) (list '(a b c d) '(0.375 0.375 0.125 0.125)))
((equal? hyp 'B) (list '(a b c d) '(0.125 0.125 0.375 0.375)))))
(define hypothesis (if (flip) 'A 'B))
(define (observe) (apply multinomial (hypothesis->parameters hypothesis)))
hypothesis
(equal? observed-letters (repeat (length observed-letters) observe))
)
)
(hist samples "Bayes-Occam-Razor")
试着改变观察到字母为d c d a b,推理会如何变化?请注意,当B是均匀分布时只需要少量的证据就可以支持倾向于假设A,但比那个大小的例子仍需要更多证据(那儿假设A根本不能生成C或D)--但大小原则会无法处理的“例外“的观测数据C和D。可通过这个例子从另外一个角度来理解贝叶斯奥卡姆剃刀:后验分布将倾向于数据集更简单更“容易”生成的假设,这里“容易“生成意味着生成的概率更高。我们将在本教程的结尾部分看到组合模型的一个更惊人的例子。
5.3.1 例子:封闭
在语言理解和生成中,封闭是自然包含贝叶斯奥卡姆剃刀原理的一种基本现象。
5.4使用贝叶斯奥卡姆剃刀的 模型选择
当我们考虑内部结构复杂的模型时,信仰守恒定律将清晰地变成奥卡姆剃刀:一些不同设置的连续或离散参数确定了模型产生的数据有多少和我们的观察一致。模型的选择我们只需要将每个模型描述成为概率程序,并写一个更高级别的程序来生成这些假设。Church查询将在两个抽象级别中采样,判断哪个模型最有可能与观测数据一致以及这些模型的内部参数最有可能的设置。
5.4.1 例子:公平还是不公平的硬币?
在上一节中,我们讲了硬币权重的学习,并指出权重的简单的先验分布似乎无法捕捉到离散的直觉,我们首先需要判断硬币是否公平,如果不公平才考虑它的权重。这个例子说明了我们可以用贝叶斯奥卡姆剃刀来指导硬币投掷的模型选择。
想象一枚你刚从银行的一卷硬币中取出的25分硬币,几乎可以肯定那是公平的硬币。。。但是当你看到多少的异常投掷结果才会改变这个观念呢?同时的,我们可以要问,硬币是否公平?权重多少?
(define observed-data '(h h t h t h h h t h))
(define num-flips (length observed-data))
(define num-samples 1000)
(define fair-prior 0.999)
(define pseudo-counts '(1 1))
(define prior-samples
(repeat num-samples
(lambda () (if (flip fair-prior)
0.5
(first (beta (first pseudo-counts) (second pseudo-counts)))))))
(define samples
(mh-query
num-samples 10
(define fair-coin? (flip fair-prior))
(define coin-weight (if fair-coin?
0.5
(first (beta (first pseudo-counts) (second pseudo-counts)))))
(define make-coin (lambda (weight) (lambda () (if (flip weight) 'h 't))))
(define coin (make-coin coin-weight))
(list (if fair-coin? 'fair 'unfair) coin-weight)
(equal? observed-data (repeat num-flips coin))
)
)
(hist (map first samples) "Fair coin?")
(truehist (append '(0) '(1) prior-samples) 10 "Coin weight, prior to observing data")
(truehist (append '(0) '(1) (map second samples)) 10 "Coin weight, conditioned on observed data")
试试这些例子,看看是否与你的直觉推断一致:
(h h t h t h h h t h) -> fair coin, probability of H = 0.5
(h h h h h h h h h h) -> ?? suspicious coincidence, probability of H = 0.5 ..?
(h h h h h h h h h h h h h h h) -> probably unfair coin, probability of H near 1
(h h h h h h h h h h h h h h h h h h h h) -> definitely unfair coin, probability of H near 1
(h h h h h h t h t h h h h h t h h t h h h h h t h t h h h h h t h h h h h
h h h h t h h h h t h h h h h h h h) -> unfair coin, probability of H = 0.85
5.4.2 例子:曲线拟合
这个例子说明了如何利用贝叶斯奥卡姆剃刀来选择一个正确的拟合多项式,在我们预定义的两个多项式true-coeffs-1和true-coeffs-2中间选一个,
这个程序将从x-vals数据中采样并考察一个包含0次到3次多项式的模型空间。
(define (make-poly c)
(lambda (x) (apply + (map (lambda (a b) (* a (expt x b))) c (iota (length c))))))
(define x-vals (map (lambda (x) (/ x 1)) (range -5 5)))
(define true-coeffs-1 '(1 0.75))
(define true-coeffs-2 '(-.5 1 .5))
(define true-y-vals (map (make-poly true-coeffs-1) x-vals))
(define true-obs-noise 0.2)
(define obs-y-vals (map (lambda (x) (gaussian x true-obs-noise)) true-y-vals))
(define samples
(mh-query
500 10
(define coeff-mean 0)
(define coeff-var 2)
(define noise-mean 0)
(define noise-var true-obs-noise)
(define poly-order (sample-integer 4))
(define coefficients (repeat (+ poly-order 1) (lambda () (gaussian coeff-mean coeff-var))))
(define (noisy-equals? x y)
(= 0.0 (gaussian (- x y) noise-var)))
(define y-vals (map (make-poly coefficients) x-vals))
(list poly-order coefficients)
(fold (lambda (x a) (and x a)) true (map noisy-equals? y-vals obs-y-vals))
)
)
(begin
(hist (map first samples) "Polynomial degree")
(define coeffs-each-order (map (lambda (x) (map second (filter (lambda (y) (= x (first y))) samples))) '(0 1 2 3)))
(define avg-coeffs (map (lambda (z) (if (null? z) '()
(map (lambda (t) (/ t (length z)))
(fold (lambda (a b) (map + a b))
(make-list (length (first z)) '0) z)))) coeffs-each-order))
(display (list "Average coefficients:" avg-coeffs))
(define fit-error-each-order (map (lambda (s) (sum (map (lambda (u v) (expt (- u v) 2)) s obs-y-vals)))
(map (lambda (cc) (map (make-poly cc) x-vals)) avg-coeffs)))
(display (list "Sum squared error with average coefficients:" fit-error-each-order))
(define plot-x-vals (map (lambda (x) (/ x 20)) (range -100 100)))
(define plot-0-y-vals (map (make-poly (list-ref avg-coeffs 0)) plot-x-vals))
(define plot-1-y-vals (map (make-poly (list-ref avg-coeffs 1)) plot-x-vals))
(define plot-2-y-vals (map (make-poly (list-ref avg-coeffs 2)) plot-x-vals))
(define plot-3-y-vals (map (make-poly (list-ref avg-coeffs 3)) plot-x-vals))
(define (adjust points)
(map (lambda (p) (+ (* (+ p 5) 25) 25))
points))
;; 0th order polynomial
(define paper-0 (make-raphael "polynomial-0" 250 250))
(raphael-points paper-0 (adjust x-vals) (adjust obs-y-vals))
(raphael-lines paper-0 (adjust plot-x-vals) (adjust plot-0-y-vals))
;; 1st order polynomial
(define paper-1 (make-raphael "polynomial-1" 250 250))
(raphael-points paper-1 (adjust x-vals) (adjust obs-y-vals))
(raphael-lines paper-1 (adjust plot-x-vals) (adjust plot-1-y-vals))
;; 2nd order polynomial
(define paper-2 (make-raphael "polynomial-2" 250 250))
(raphael-points paper-2 (adjust x-vals) (adjust obs-y-vals))
(raphael-lines paper-2 (adjust plot-x-vals) (adjust plot-2-y-vals))
;; 3rd order polynomial
(define paper-3 (make-raphael "polynomial-3" 250 250))
(raphael-points paper-3 (adjust x-vals) (adjust obs-y-vals))
(raphael-lines paper-3 (adjust plot-x-vals) (adjust plot-2-y-vals))
'done)
5.5 例子:场景推理
想象一下颜色块的世界,通常看起来像这样:

某天,你看到一块1x2的红色补丁...它是一个1x2块还是两个1x1块呢?

我们可以通过建立场景生成模型来为这一推理建模。为此,我们利用几何物体和几何物体的渲染(分层情况下)的简单模型:
(define (object-appearance location-x location-y v-size color)
(map (lambda (pixel-y)
(map (lambda (pixel-x) (if (or (< pixel-x location-x)
(<= (+ location-x 1) pixel-x)
(< pixel-y location-y)
(<= (+ location-y v-size) pixel-y))
0 color))
'(0 1 2 3)))
'(0 1)))
(define (sample-location-x) (sample-integer 4))
(define (sample-location-y) (sample-integer 2))
(define (sample-v-size) (+ 1 (sample-integer 2)))
(define (sample-color) (+ 1 (sample-integer 3)))
(define (layer object image) (map (lambda (obj-row im-row)
(map (lambda (o i) (if (= 0 o) i o))
obj-row im-row))
object image))
(define samples
(mh-query 1000 10
(define num-objects (if (flip) 1 2))
(define object1-x (sample-location-x))
(define object1-y (sample-location-y))
(define object1-size (sample-v-size))
(define object1-color (sample-color))
(define object2-x (if (= num-objects 1) 0 (sample-location-x)))
(define object2-y (if (= num-objects 1) 0 (sample-location-y)))
(define object2-size (if (= num-objects 1) 0 (sample-v-size)))
(define object2-color (if (= num-objects 1) 0 (sample-color)))
(define image1 (layer (object-appearance object1-x object1-y object1-size object1-color) (object-appearance object2-x object2-y object2-size object2-color)))
(- num-objects 1)
(equal? image1 '((0 1 0 0)(0 1 0 0)))) )
(hist samples "Number of objects, moving image")
结果轻微地偏好于1x2块。
如果我们看到了两个“一半“移动到一起会如何呢?我们用一个简单的随机移动模型:一个对象随机移动位置或左或右或停留,关键是,每个物体的移动与其它对象无关。
(define (object-appearance location-x location-y v-size color)
(map (lambda (pixel-y)
(map (lambda (pixel-x) (if (or (< pixel-x location-x)
(<= (+ location-x 1) pixel-x)
(< pixel-y location-y)
(<= (+ location-y v-size) pixel-y))
0 color))
'(0 1 2 3)))
'(0 1)))
(define (sample-location-x) (sample-integer 4))
(define (sample-location-y) (sample-integer 2))
(define (sample-v-size) (+ 1 (sample-integer 2)))
(define (sample-color) (+ 1 (sample-integer 3)))
(define (next-location location) (+ location (multinomial '(-1 0 1) '(0.3 0.4 0.3))))
(define (layer object image) (map (lambda (obj-row im-row)
(map (lambda (o i) (if (= 0 o) i o))
obj-row im-row))
object image))
(define samples
(mh-query 1000 10
(define num-objects (if (flip) 1 2))
(define object1-x (sample-location-x))
(define object1-y (sample-location-y))
(define object1-size (sample-v-size))
(define object1-color (sample-color))
(define object2-x (if (= num-objects 1) 0 (sample-location-x)))
(define object2-y (if (= num-objects 1) 0 (sample-location-y)))
(define object2-size (if (= num-objects 1) 0 (sample-v-size)))
(define object2-color (if (= num-objects 1) 0 (sample-color)))
(define image1 (layer (object-appearance object1-x object1-y object1-size object1-color) (object-appearance object2-x object2-y object2-size object2-color)))
(define image2 (layer (object-appearance (next-location object1-x) object1-y object1-size object1-color) (object-appearance (next-location object2-x) object2-y object2-size object2-color)))
(- num-objects 1)
(and (equal? image1 '((0 1 0 0)(0 1 0 0)))
(equal? image2 '((0 0 1 0)(0 0 1 0))))) )
(hist samples "Number of objects, moving image")
我们看到更倾向于一个对象的解释。两个不连接的一半移动到一起要比两个连接的一半保持相对静止需要更大的巧合(用贝叶斯奥卡姆剃刀来计算的话)。
从这些例子可以看到,知觉组合形式中从概率场景推理中得出的一些完整原则(在这个例子中是“良好的延续性“和“共同命运“)。然而这些是分级的推论,而不是硬规则:本例中,静态图像比移动图像所携带的信息要少(从而“良好的延续性”要比“共同命运”弱)。这种效应可能具有重要开发含义:心理学家伊丽莎白斯派克发现,婴幼儿是不会以任何静态特征组合对象的(如良好的延续性),他们通过共同运动来进行组合。















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










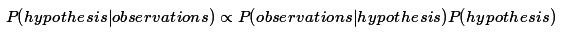{kind=link}
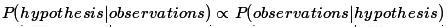{kind=link}