







什么是FFM模型
FFM (Field-aware Factorization Machine) 模型中引入了类别的概念,即field。中文是场感知分解机。
回顾一下FM:
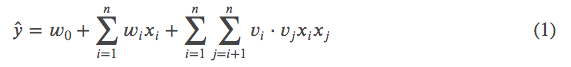
⋅ 表示向量的内积。样本 𝑥 是 𝑛 维向量, 是第 𝑖 个维度上的值。
是
对应的长度为 𝐾 的隐向量,𝑉 是模型参数,所以所有样本都使用同一个 𝑉 ,
与
即与都使用
。
在FFM(Field-aware Factorization Machines )中每一维特征(feature)都归属于一个特定的field,field和feature是一对多的关系。比如
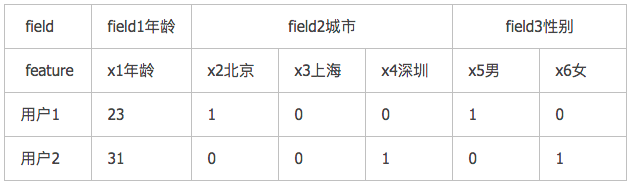
1、对于离散特征,采用one-hot编码,同一种属性的归到一个Field。
2、对于连续特征,一个特征就对应一个Field。或者对连续特征离散化,一个分箱成为一个特征。比如
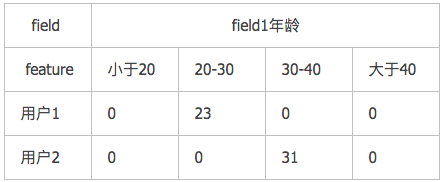
不论是连续特征还是离散特征,它们都有一个共同点:同一个field下只有一个feature的值不是0,其他feature的值都是0。
FFM模型认为 不仅跟
有关系,还跟与
相乘的
所属的Field有关系,即
成了一个二维向量
,𝐹 是Field的总个数。FFM只保留了(1)中的二次项。
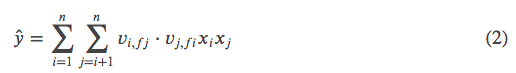
以上文的表格数据为例,计算用户1的 ,
![]()
由于 𝑥2,𝑥3,𝑥4 属于同一个Field,所以 𝑓2,𝑓3,𝑓4 可以用同一个变量来代替,比如就用 𝑓2。
![]()
我们来算一下 对
的偏导。
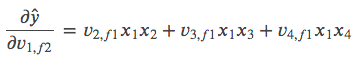
等式两边都是长度为 𝐾 的向量。
注意𝑥2,𝑥3,𝑥4 是同一个属性的one-hot表示,即 𝑥2,𝑥3,𝑥4 中只有一个为1,其他都为0。
在本例中 𝑥3=𝑥4=0,𝑥2=1,所以
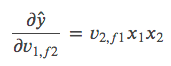
推广到一般情况:

属于Field
,且同一个Field里面的其他
都等于0。实际项目中 𝑥 是非常高维的稀疏向量,求导时只关注那些非0项即可。
- 你一定有个疑问: 𝑣 是模型参数,为了求 𝑣 我们采用梯度下降法时需要计算损失函数对 𝑣 的导数,为什么这里要计算 𝑦̂ 对 𝑣 的导数?
在实际预测点击率的项目中我们是不会直接使用公式(2)的,通常会再套一层sigmoid函数。公式(2)中的 𝑦̂ 我们用 𝑧 来取代。
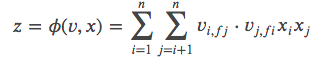
由公式(3)得
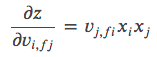
用 a 表示对点击率的预测值
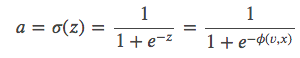
令 𝑦=0 表示负样本,𝑦=1 表示正样本,𝐶 表示交叉熵损失函数。
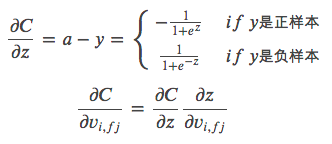
论文《Field-aware Factorization Machines for CTR Prediction》中是以 𝑦=1 代表正样本,𝑦=−1 代表负样本,所以才有了3.1节中的
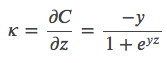
下面以一个例子简单说明FFM的特征组合方式。输入记录如下:

这条记录可以编码成5个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个field,“Price”是数值型,不用One-Hot编码转换。为了方便说明FFM的样本格式,我们将所有的特征和对应的field映射成整数编号。

那么,FFM的组合特征有10项,如下图所示。
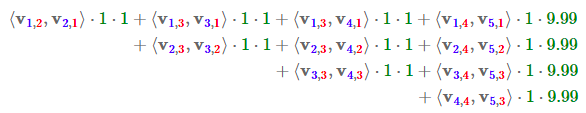
其中,红色是field编号,蓝色是特征编号。
FM与FFM模型——能够意识到特征域(Field)的存在的FM模型

上图是一个人造的广告CTR的数据例子,代表的意思是在某个网站(Publisher)上刊登一则广告(Advertiser),某个用户(用户性别特征Gender)是否会点击某条广告的数据。这个例子中假设包含三个特征域(Field):网站Publisher(可能的特征值是ESPN、Vogue、NBC)、广告(可能的特征值是Nike、Adidas、Gucci)和性别特征Gender(可能的特征值是Male、Female)。由这个例子可以看出组合特征的重要性:如果在体育网站ESPN上发布Nike的广告,那么100次展现,80次会被点击,而20次不会被点击。意味着组合特征(Publisher=”ESPN” and Advertiser=”Nike”)是个很强的预测用户是否点击的二阶组合特征。上图同时展示了一条用户点击记录。
我们用这个例子来说明FFM的基本思想,FM模型可以看做是FFM模型的一个特例,所以在说明FFM模型思想之前,我们先用上述例子说明FM的思想,然后通过和FM模型的对比,很容易理解FFM模型的基本思路。

FM模型在做二阶特征组合的时候,对于每个二阶组合特征的权重,是根据对应两个特征的Embedding向量内积,来作为这个组合特征重要性的指示。当训练好FM模型后,每个特征都可以学会一个特征embedding向量,参考上图。当做预测的时候,比如我们接收到上面例子的数据,需要预测用户是否会点击这条广告,则对三个特征做两两组合,每个组合特征的权重,可以根据两个对应的特征embedding内积求得,对所有组合特征求和后,套接Sigmoid函数即可做出二分类预测。

对于FM模型来说,每个特征学会唯一的一个特征embedding向量,注意,在这里,和FFM的最大不同点冒出来了。为了更容易向FFM模型理解过渡,我们可以这么理解FM模型中的某个特征的embedding:拿Vespn这个特征作为例子,当这个特征和其它特征域的某个特征进行二阶特征组合的时候,不论哪个特征域的特征和Vespn特征进行组合,Vespn这个特征都反复使用同一个特征embedding去做内积,所以可以理解为Vespn这个特征在和不同特征域特征进行组合的时候,共享了同一个特征向量。
沿着这个思路思考,我会问出一个问题:我们可以改进下FM模型吗?怎么改进?下图给个提示。

如果你对算法敏感的话,你可以这么回答我:既然FM模型的某个特征,在和任意其它特征域的特征进行组合求权重的时候,共享了同一个特征向量。那么,如果我们把这个事情做地更细致些,比如Vespn这个特征,当它和Nike(所属特征域Advertiser)组合的时候用一个特征embedding向量,而当它和Male(所属特征域Gendor)组合的时候,使用另外一个特征embedding向量,这样是否在描述特征组合的时候更细腻一些?也就是说,当Vespn这个特征和属于Advertiser这个域的特征进行组合的时候,用一个特征embedding;和属于Gendor这个特征域的特征进行组合的时候,用另外一个特征embedding。这意味着,如果有F个特征域,那么每个特征由FM模型的一个k维特征embedding,拓展成了(F-1)个k维特征embedding。之所以是F-1,而不是F,是因为特征不和自己组合,所以不用考虑自己。??
这其实就是FFM模型的基本思想。所以从上面两个图的示意可以看出,为何说FM模型是FFM模型的特例。

我们再回头看下刚才那个点击数据的例子,看看在FFM场景下是怎样应用的,上图展示了这个过程。因为这个例子有三个特征域,所以Vespn有两个特征embedding,当和Nike特征组合的时候,用的是针对Advertisor这个特征域的embedding去做内积;而当和Male这个特征组合的时候,则用的是针对Gendor这个特征域的embedding去做内积。同理,Nike和Male这两个特征也是根据和它组合特征所属特征域的不同,采用不同的特征向量去做内积。而两两特征组合这个事情的做法,FFM和FM则是完全相同的,区别就是每个特征对应的特征embedding个数不同。FM每个特征只有一个共享的embedding向量,而对于FFM的一个特征,则有(F-1)个特征embedding向量,用于和不同的特征域特征组合时使用。
从上面的模型演化过程,我们可以推出,假设模型具有n个特征,那么FM模型的参数量是n*k(暂时忽略掉一阶特征的参数),其中k是特征向量大小。而FFM模型的参数量呢?因为每个特征具有(F-1)个k维特征向量,所以它的模型参数量是(F-1)*n*k,也就是说参数量比FM模型扩充了(F-1)倍。这意味着,如果我们的任务有100个特征域,FFM模型的参数量就是FM模型的大约100倍。这其实是很恐怖的,因为现实任务中,特征数量n是个很大的数值,特征域几十上百也很常见。另外,我们在上一篇介绍FM模型的文章里也讲过,FM模型可以通过公式改写,把本来看着是n的平方的计算复杂度,降低到 。而FFM无法做类似的改写,所以它的计算复杂度是
,这明显在计算速度上也比FM模型慢得多。所以,无论是急剧膨胀的参数量,还是变慢的计算速度,无论从哪个角度看,相对FM模型,FFM模型是略显笨重的。
正因为FFM模型参数量太大,所以在训练FFM模型的时候,很容易过拟合,需要采取早停等防止过拟合的手段。而根据经验,FFM模型的k值可以取得小一些,一般在几千万训练数据规模下,取8到10能取得较好的效果,当然,k具体取哪个数值,这其实跟具体训练数据规模大小有关系,理论上,训练数据集合越大,越不容易过拟合,这个k值可以设置得越大些。
FM中
是
的向量;
FFM中
的向量,其中
是field个数。
🍄我的疑问:到底是F*K,还是(F-1)*K?
参考:
推荐系统召回四模型之二:沉重的FFM模型 - 张俊林的文章 - 知乎
FM、FFM、DeepFM (未)















 2535
2535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









