






对比loss
对比学习的 loss(InfoNCE)即以最 大化互信息为目标推导而来。其核心是通过计算样本表示间的距离,拉近正样本, 拉远负样本,因而训练得到的模型能够区分正负例。
具体做法为:对一个 batch 输入的图片,随机用不同的数据增强方法生成两个 view,对他们用相同的网络 结构进行特征提取,得到 y 和 y’,来自同一张图像的两个不同的表示构成一对正样本对,来自不同图像任意表示对为一对负样本对。随后对上下两批表示两两计算 cosine similarity,得到 N*N 的矩阵,每一行的对角线位置代表 y 和 y’的相似 度,其余代表 y 和 N-1 个负样本对的相似度。计算公式如下(T 为超参):
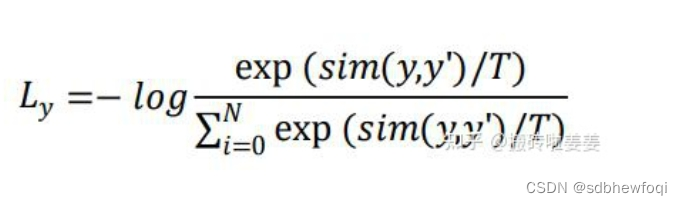
MOCO(memory bank)
MOCO 的一个核心观点是,样本数量对于对比学习很重要。从 InfoNCE loss 我们可以看出,增加负例的数量可以防止过拟合,与此同时,负例越多,这个任务的难度就越大,因而通过增加负例的方式可作为一个优化方向。但是纯粹的增加 batch size 会使得 GPU 超负荷。一个可行的方法就是增加 memory bank,把之前编码好的样本存储起来,计算 loss 的时候随机采样负例。但是这样会存在一个问题,就是存储好的编码都是之前编码计算的,而 Xq 经过误差回传后一直在更新,样本缺乏一致性,影响目标优化。因而在此基础上 Moco 提出了一种动量对比 (Mometum contrast) 的方法提高每个 mini-batch 的负样本数量。
MOCO的改进方法:动量更新,主要是为了解决引入队列维护字典之后,字典的编码器无法通过梯度反传获得参数更新的问题。
Moco就提出Momentum Contrast的方法解决Memory Bank的缺点,该方法使用一个队列来存储和采样 negative 样本,队列中存储多个近期用于训练的 batch 的特征向量。队列容量要远小于 Memory Bank,但可以远大于 batch 的容量,如下图所示。这里momentum encoder可以和encoder完全一致参与梯度下降,也可以是对query encoder的平滑拷贝。
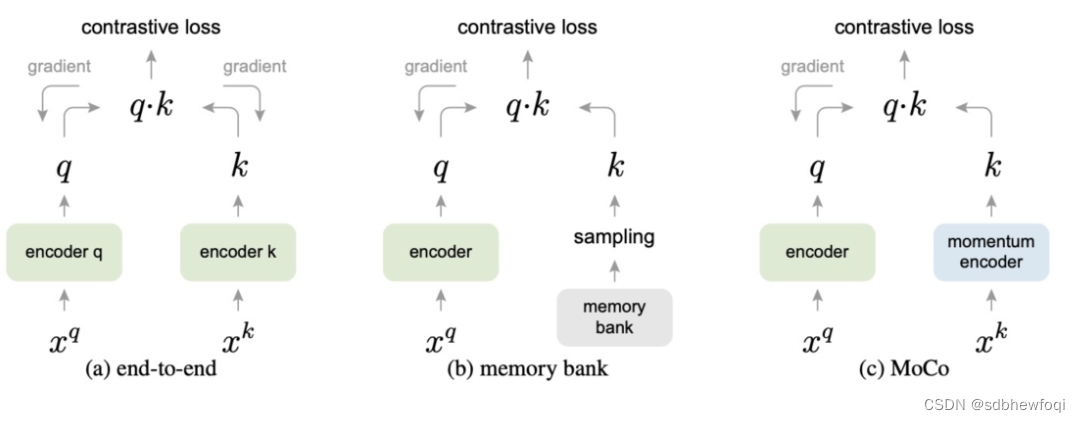
我的疑问:这样还有类似于memory bank的负采样吗?如果没有,那么bacthsize岂不是还是不能增大?这只是解决了encoder同步更新的问题。-----》以上下划线
SimCLR
在 encoder 之后增加了一个非线性映射。研究发现 encoder 编码后的 h 会保留和数据增强变换相关的信息,而非线性层的作用就是去掉这些信息,让表示回归数据的本质。















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









