







有监督学习:数据都有人工标注的标签
无监督学习:模型会收到某个数据集,但对于如何处理该数据集却未获得明确的指示。训练的数据集是没有特定预期结果或正确答案的示例的集合
半监督学习:同时用有标签和无标签的数据进行训练。分两阶段,先用(较小规模的)有标签数据训练一个Teacher模型,再用这个模型对(较大规模的)无标签数据预测伪标签,作为Student模型的训练数据
自监督学习:从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练。自监督的监督信号来源于数据本身的内容,也就是自己给自己监督信号。
自监督学习算法分为两种:生成式和判别式。
生成式学习如MAE,GAN
判别式如:对比学习是通过构造正负样例来学习特征。对于一个输入样本来说,存在与之相似的样本x+以及与之不相似的样本x-,对比学习要做的就是学习一个编码器f(编码器比如CNN), 这个编码器能够拉近x与其正样本间的距离,推远X与其负样本之间的距离。即:![]()
弱监督学习:用包含噪声的有标签数据训练。
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
是一种不关注像素级细节,只编码足以区分不同对象的高阶特征的表示学习算法。
是一种任务无关的,泛化能力强的方法
对比学习和代理任务
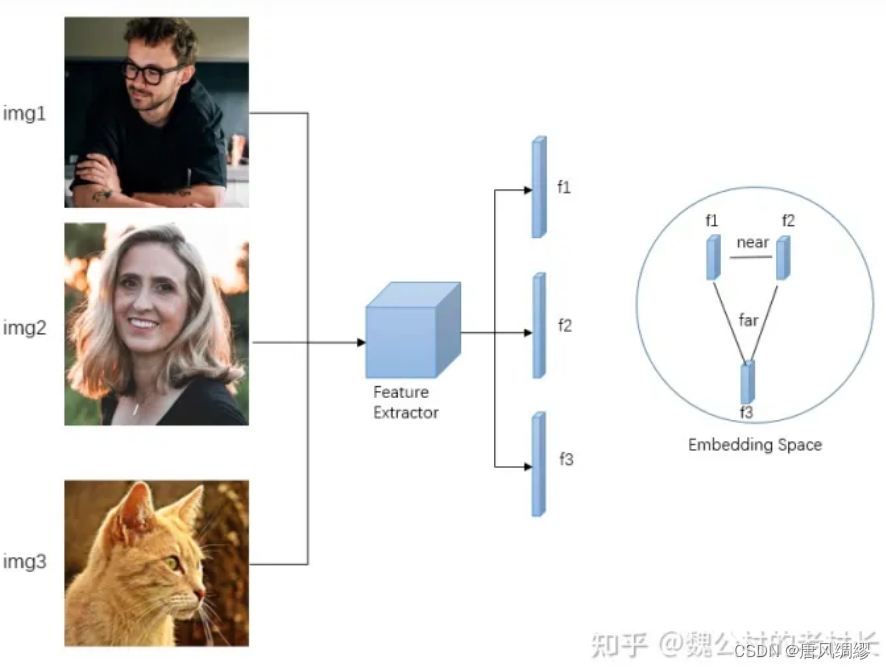
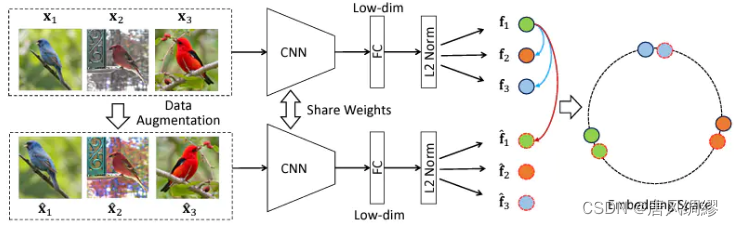
如左上:我们有三张图像,img1和img2都是person这一类,img3是cat这一类,三张图像经过同一个网络,得到三个特征向量,我们的目标是希望在训练过程中,使得f1和f2这两种相似的特征尽可能的接近,而f3尽可能得远离它俩。对比学习顾名思义就是两两比较着去学习。
但与有监督不同,有监督学习我们通过数据的label就能知道img里对应的classname是什么,而对比学习我们不需要知道样本里的类别具体是什么,只需要知道1和2相似,“相似”这个特性就是对比学习里的监督信号。我们通过什么方式能知道1和2相似,1,2和3不相似呢,换言之,我们如何构造自监督的监督信号呢,实际上是通过学习一个pretext task(代理任务)。代理任务就是我们通过人为地制定一些规则和策略,规定哪些样本是相似的,哪些样本是不相似的,去提供这么一个监督信号训练。
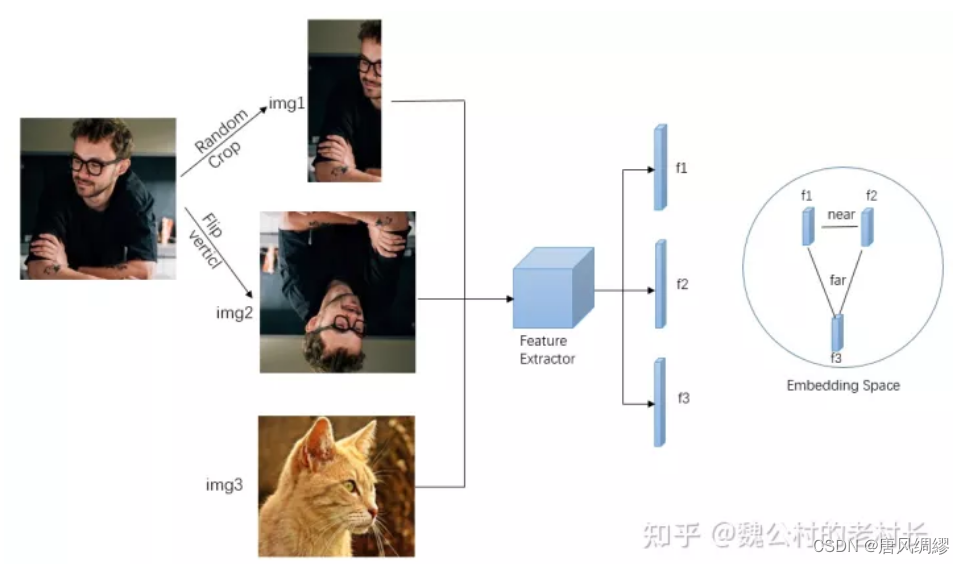
对比学习的巧妙之处就在于正负样本规定的策略(即代理任务)是多样的。最常见的代理任务之一就是“个体判别”,如右上图,大多通过一张图片数据增强得到的两张图像作为正样本,其它图像都是负样本。
将对比学习转化为字典查询问题
moco提出对比学习都可以看作一个字典查询任务
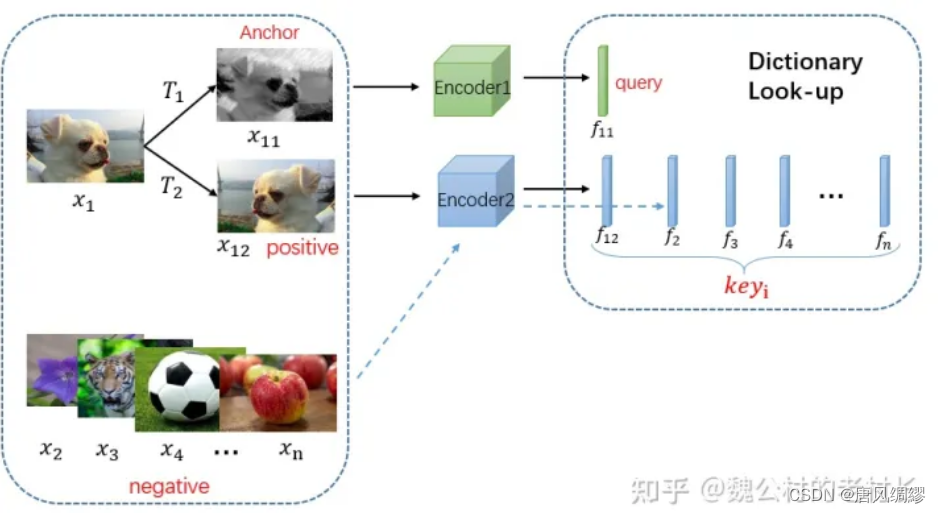
在一个数据集N里,x1经过增强得到x11和x12,其中x11我们叫它anchor,x12为正样本,剩下的所有样本为负样本,Encoder1将x11编码为f11,Encoder2将x12编码为f12,剩下的样本也被编码器2编码成fi。f11和f12尽可能相似,和fi尽可能远离。
于是建模成一个字典查询的问题:f11是query,剩下的特征向量都是key,要在字典里找到和query对应的key。为保证泛化能力,字典需要两个具有特性:字典需要具备两个特性:
1. 字典要尽可能大
数据肯定越多越好,当我们拿query与key做对比的时候我们尽可能的把图像特征区分开,如果字典非常小的话模型容易学到一个捷径(ShortCut Solution),使得预训练模型不具备很好的泛化性。但字典的大小会受到硬件内存限制。
即我们得到的特征需要用相似的编码器得到,当你在跟query做比对的时候,才能保证对比的一致性。不然也是变向的引入了“捷径”。
对比学习介绍(按发表时间顺序总结,很优秀)
对于一个输入样本来说,存在与之相似的样本x+以及与之不相似的样本x-,对比学习要做的就是学习一个编码器f(编码器比如CNN), 这个编码器能够拉近x与其正样本间的距离,推远X与其负样本之间的距离。即:![]()
一、 第一阶段 百花齐放
1. InstDisc
该文章属于个体判别任务,对比学习的开山鼻祖,使用的是memory bank的方法,将每个instance(每个图片)当成一个类别进行分类。具体流程如下图所示:
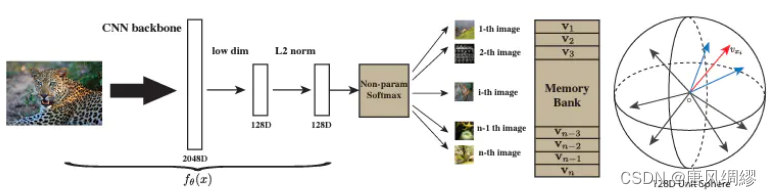
将所有的图片通过卷积神经网络将其编成128维的特征,希望这些特征在128维(不能太高否则不好存储)的空间特征里面能尽可能的分开,因为每个图片都属于自己的类别,每个图片应该和别的图片尽量分开,这里的正样本为数据本身,负样本为数据集其他图片。该方式将1万张图片也就是将128万个特征存储到MemoryBank中,这里的负样本每次抽取4096个负样本进行学习。可以理解为MOCO的前身。
2. InvaSpread
该文章可以理解为是simCLR的前身,它没有使用额外的数据结构存储大量的负样本,该负样本为同一个min-batch,且只有唯一的编码器。核心思想就是同样的图片编码特征应该很类似,不同图片编码特征应该不类似,如下图所示:
下面这张画详细解释了该模型原理,假设我们的batch-size为256,这样我们就有256张图片数据,通过数据增强操作我们得到256张增强图片,对于图片x1来说x1’为正样本,剩下的图片都是负样本(包括原始的图片以及数据增强后的图片,也就是说你的正样本图片是256,但是你的负样本数量为((256-1)*2), 最后如下所示,我们希望最后相同颜色的球离得更近。
缺点:这里使用的是GPU而非TPU(人工智能专用的张量计算处理器),batch-size不大,也没有mlp projector导致训练效果没有simCLR(之后介绍)效果好。
二、第二阶段CV双雄
1.SimCLR
网络结构:
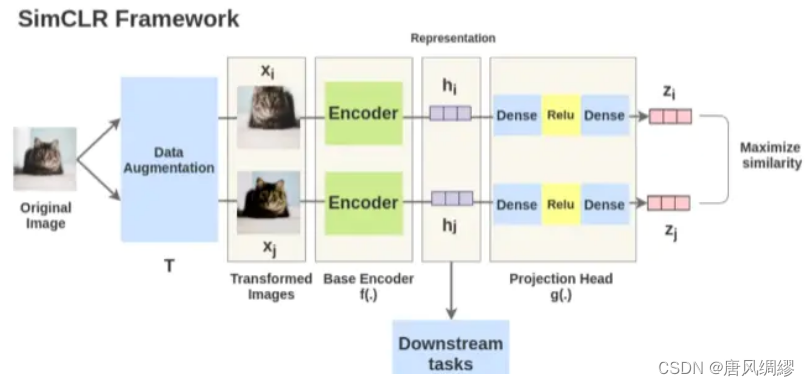
通过上述图片,我们可以很清楚的了解这里的SimCLR是如何做自监督学习的。首先我们选取任意一个图片作为anchor图(例如小猫),之后分别选取其增广后的图片(如旋转变化等增广的小猫)以及非该图片(其他小猫或者其他动物等)分别与这个anchor图做相似度,如果是增广的图片则希望其与anchor图相似度最大,如果是非该图片则希望与anchor图片相似度最小。
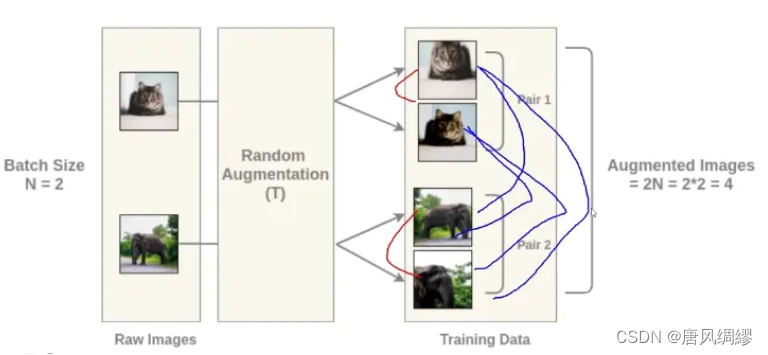
batch为2时的网路结构:
损失函数: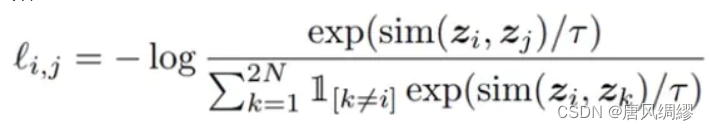 这里公式中分子表示同类,分母表示非同类;τ小于1,使得梯度放大,收敛更快;N为batch size,2N为增广后的批大小、
这里公式中分子表示同类,分母表示非同类;τ小于1,使得梯度放大,收敛更快;N为batch size,2N为增广后的批大小、
训练示意图: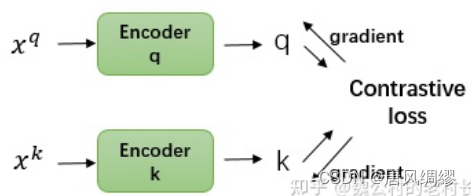
注意:该模型中Batch 大小比较重要,原文这里使用的是8192(相当于一个正样本与其他图片互为负样本), 即一个正样本需要与多个负样本对进行匹配,否则模型很难收敛
其V2版本改进:加了更大的骨干模型;多加一层mlp;用了动量编码器
第三阶段:不使用负样本
- BYOL
大部分的自监督训练都是通过约束同一张图的不同形态之间的特征差异性来实现特征提取,不同形态一般通过指定的数据增强实现。那么如果只是这么做的话(只有正样本对),网络很容易对所有输入都输出一个固定值,这样特征差异性就是0,完美符合优化目标,但这不是我们想要的,这就是训练崩塌了。因此一个自然的想法是我们不仅仅要拉近相同数据的特征距离,也要拉远不同数据的特征距离,换句话说就是不仅要有正样本对,也要有负样本对,这确实解决了训练崩塌的问题,但是也带来了一个新的问题,那就是对负样本对的数量要求较大,因为只有这样才能训练出足够强的特征提取能力。
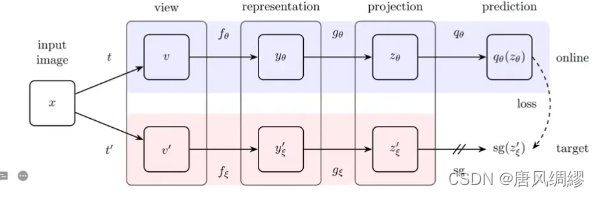
该对比学习无需负样本就可以进行训练,训练思路图如下所示:















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









