






介绍一篇ICCV2019的#论文#。主题是
用熵解决半监督的域适应问题
Semi-supervised Domain Adaptation via Minimax Entropy
概述

在#人工智能#领域,半监督域适应是一个很常见问题。是指存在两个数据集,一个是全部标注的源域,另一个是只有少量数据有标注,大量数据无标注的目标域。要利用源域的数据训练一个在目标域上好使的模型
域适应问题的难点在于:如何找到源域与目标域的不变量,即知识。然后通过什么样的途径将知识从源域迁移到目标域。
论文作者假定分类器的参数包含了域不变的信息。论文的目标在于,通过极大极小化熵损失函数,找到合适的分类器参数。
流程
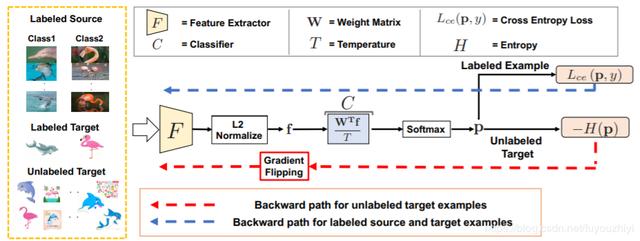
整个网络分为两个部分:
1. 特征提取器 F:采用主流的卷积神经网络,例如VGG,Resnet等,去掉最后的线性分类层
2. 分类器 C:k类别的线性分类器
数据流程:
图片x先输入到F中,得到F(x)。再计算l-2范数归一化后,得到
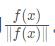
然后输入到分类器C中,得到

最后经过一个softmax层,输出

其中,分类器C的参数为 W=[w_1,w_2,...,w_K](k为类别个数)。最终的输出可以写成
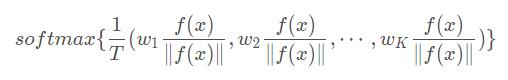
当w_i和f(x)同方向时,这一项取最大值,此时类别为第i类
注:柯西不等式:|(a,b)|≤|a||b|。当a,b同方向时,取最大值所以要想正确分类,权重向量w_i的方向必须和该类别特征的标准方向一致。所以论文视权重向量w_i为每个类别的原型。论文的目的在于估计域不变的原型。
算法#算法#
首先用有标签的数据训练出一个模型来
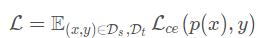
本文利用交叉熵损失函数,训练源域D_s和目标域D_t中有标签的数据。但是这并不能保证模型能学到针对整个目标域的判别性特征。所以接下来要采用对抗的思想来训练无标记数据
本文有一个基本的假设是:
存在一个简单的域不变原型,能够代表两个域的所有数据
讲过上面的交叉熵loss后,原型w_i更靠近源域的分布,作者希望原型能向目标域偏移。所以针对目标域无标记数据计算香浓熵:
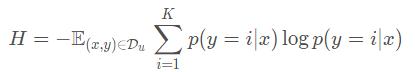
增加熵值,则每个类输出的概率值很平均。此时,固定F,更新C的参数,能让原型w_i向未标记的目标域移动。
为了在未标记数据上学到判别性特征,训练F时,要减小熵值,使得未标记数据的特征聚集在估计原型周围
训练策略总结如下
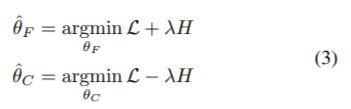
分析
看公式三,训练分两个步骤
1.固定分类器C,训练特征提取器F:利用有标记的数据训练模型提取到有用的特征。针对无标记的数据,最小化熵loss能提取到最具有判别性的特征。
关于熵loss的作用,这篇文章中有分析这里就不赘述了
https://www.toutiao.com/i6707098269777920516/
2.固定特征提取器F,训练分类器C:利用有标记的数据训练模型对特征进行正确分类。针对无标记的数据,最大化熵loss则会使
向量中的每一个分量都相似。这就迫使参数w_i向f(x)的方向靠近,也就是目标域未标记数据整体靠近。这样得到的原型w_i不仅包含了源域的信息还包含了目标域的信息。从而找到了域不变信息。
从这里我们也可以看出这篇论文的缺陷:w_i包含了有标记数据的第i类的信息,同时包含了目标域中所有无标记数据的信息。
我们期望w_i包含目标域中第i 类数据的信息,但是这并不好找到。















 5415
5415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









