







1.motivation
半监督域自适应(SSDA)最简单的策略,通常称为S+T。当前方法通常旨在通过特征空间映射和伪标签分配将目标数据与标记的源数据对齐。然而,这种面向源的模型有时会将目标数据与错误类的源数据对齐,从而降低分类性能。本文提出了一种新的源自适应范式,该范式调整源数据以匹配目标数据。关键思想是将源数据视为理想目标数据的噪声标记版本。本文提出的模型借助于从目标角度设计的强大的清洁器组件来动态地清除标签噪声。由于该范式与现有SSDA方法背后的核心思想非常不同,本文提出的模型可以很容易地与它们相结合,以提高它们的性能。对两种最先进的SSDA方法的经验结果表明,所提出的模型有效地清除了源标签内的噪声,并在基准数据集上表现出优于这些方法的性能。
本文贡献总结如下:
- 经典的面向源的方法可能仍然受到从S+T导出的有偏差的特征空间的影响。为了摆脱这种困境,本文建议通过修改原始源标签来使源数据适应目标空间。
- 本文将DA视为NLL噪声标签学习问题的一个特例,并提出了一种新的源自适应范式。本文的SLA框架可以很容易地与其他现有算法相结合,以提高它们的性能。
- 当与最先进的SSDA算法相结合时,证明了本文提出的SLA框架的有用性。该框架在两个主要基准上显著改进了现有算法,为解决DA问题开辟了新的方向。
2. Related Work
问题设置。在SSDA中,对来自源域的标记源数据S、目标域的标记目标数据L和来自目标域上未标记目标数据U进行采样。通常,|L|比|S|和|U|小得多,例如每个类一个或三个示例。本文的目标是训练具有S、L和U的SSDA模型g,使其在目标域上表现良好。
半监督域自适应(SSDA)。SSDA算法通常包括三个损失函数:
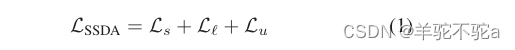
其中Ls代表由源数据得到的损失。Ll,Lu表示标记的和未标记的目标数据的损失。在本文的研究中,注意到,从目标数据的角度来看,源标签可能会显得有噪声。因此,开发了一个源自适应框架,以逐步使源数据适应目标空间。由于本文正在解决这个问题的一个新方面,本文的框架可以很容易地应用于上面提到的几种SSDA算法,从而进一步提高整体性能。
噪声标签学习(NLL)。机器学习算法的有效性在很大程度上取决于所收集标签的质量。关于目前的深度神经网络设计,上述问题可能会恶化,因为深度模型能够以看似随机的方式拟合数据集,而与标签的质量无关。为了清除噪声标签,[20]提出了一种将噪声标签与自预测相混合的平滑机制。[26]将干净标签建模为可训练参数,并设计联合优化算法来交替更新参数。[17,25,32]估计转换矩阵以校正损坏的标签。然而,学习全局转移矩阵通常需要对噪声标签的来源进行强有力的假设,这在现实世界中很难验
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3209
3209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









