






引言:之前写了一篇《DeepSeek 核心技术大解密》,当时因为时间关系没有进一步串解各技术创新亮点。最近再细致研读论文并在原来的基础上做了细化,特别是结合每个版本迭代中的 diff 技术变更进行剖析并添加上自己的理解。希望与AI 技术爱好者一起共同进步。
DeepSeek核心技术大揭秘,尽可能通俗易懂大白话方式、以多视角剖析不同版本技术亮点以及发展历程,同时结合官方不同版本以及之前总结的前版本进行汇总剖析,最近再细致研读论文并在原来的基础上做了细化,特别是结合每个版本迭代中的 diff 技术变更进行剖析并添加上自己的理解,探索DeepSeek V1~R1 卓越之处~
注意,在多次研读官方技术论文发现:
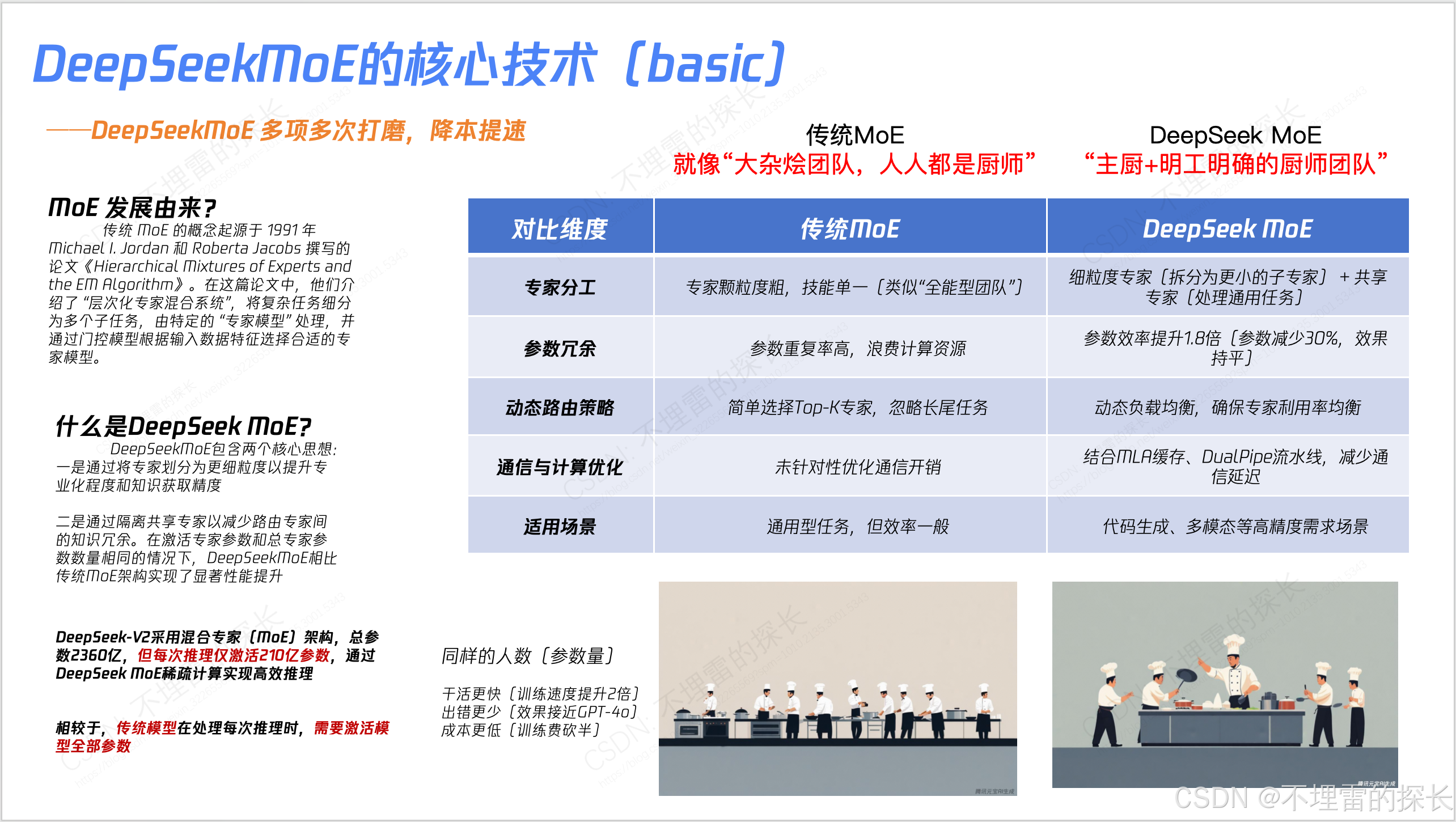
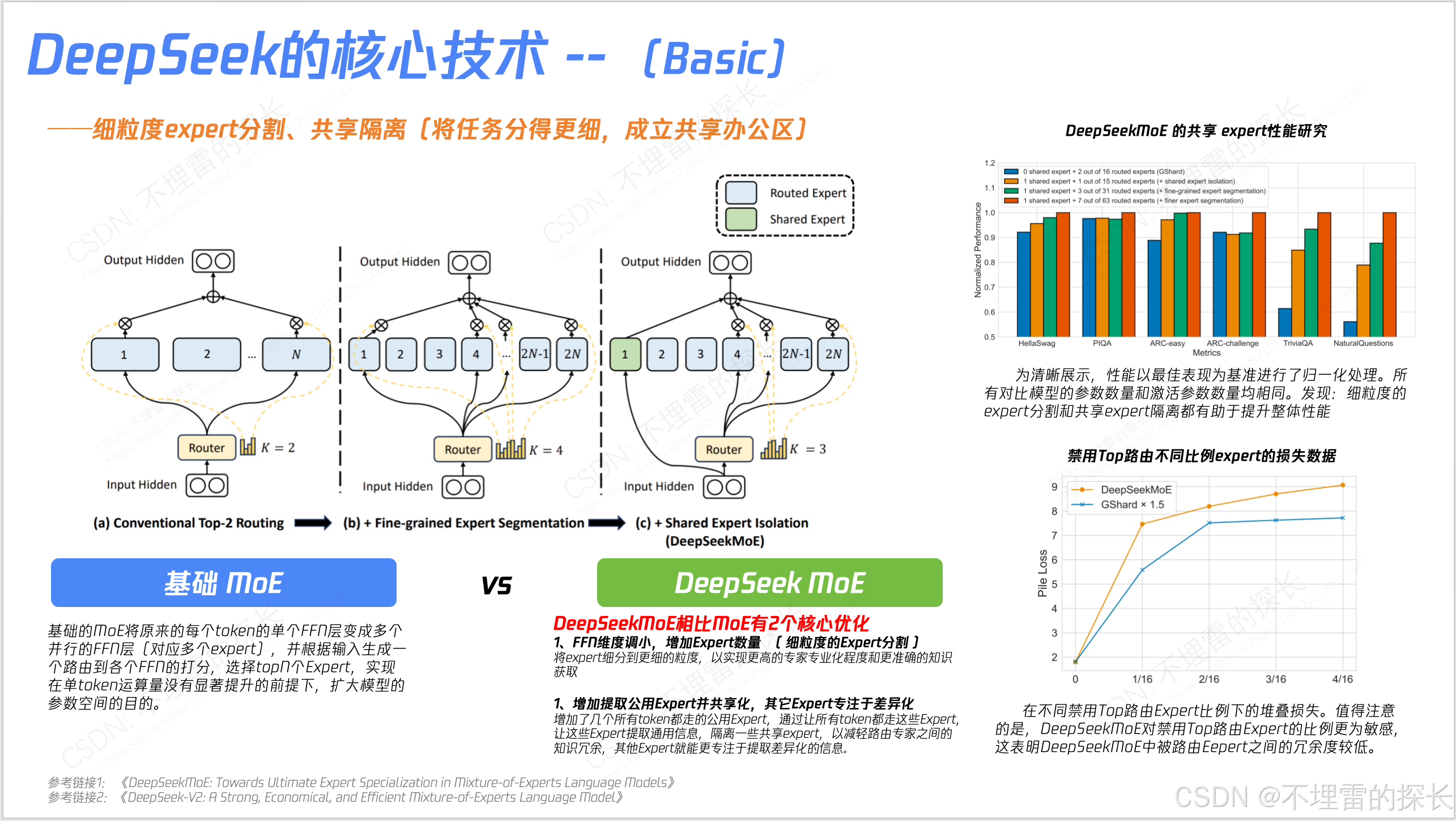
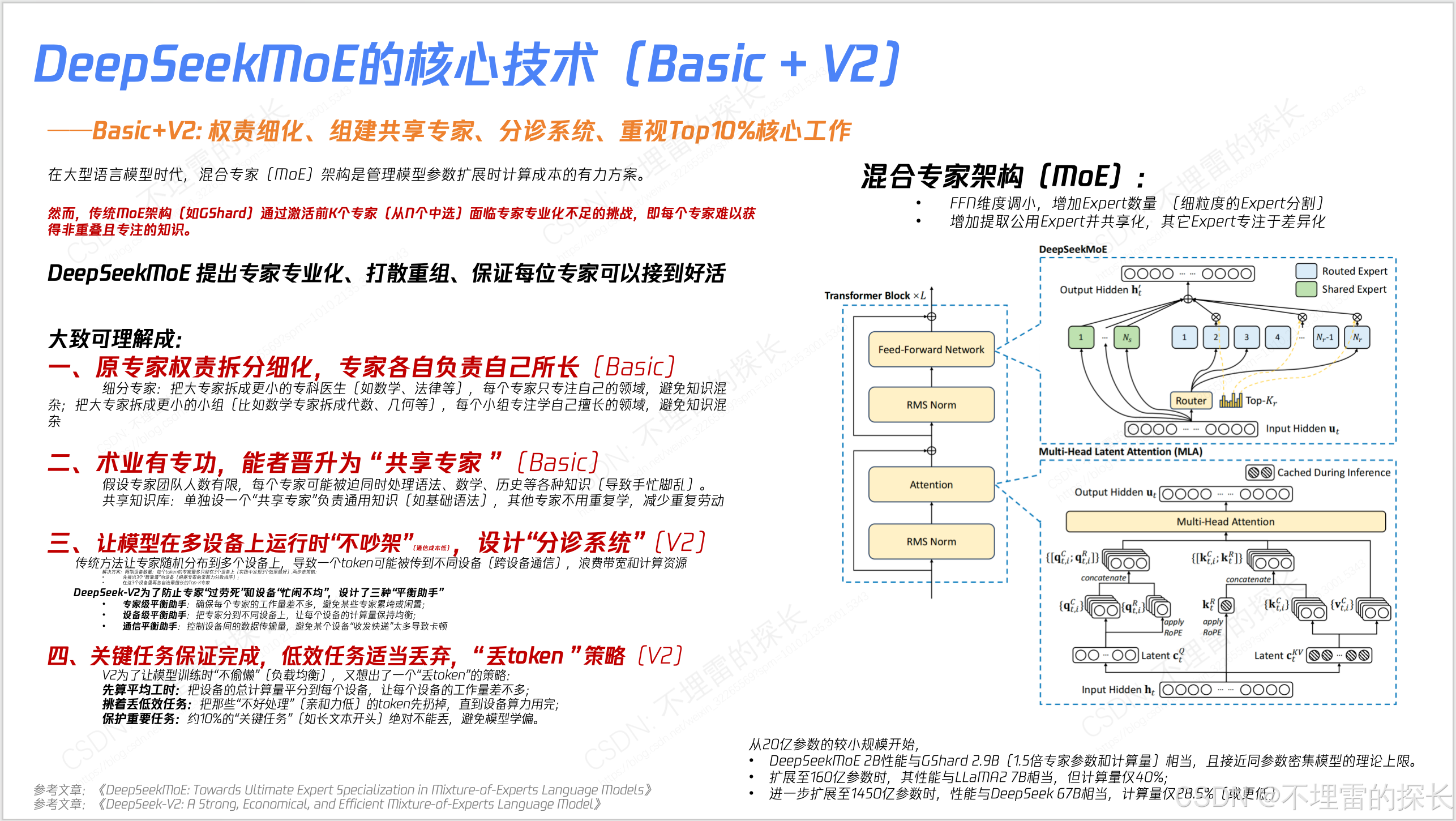
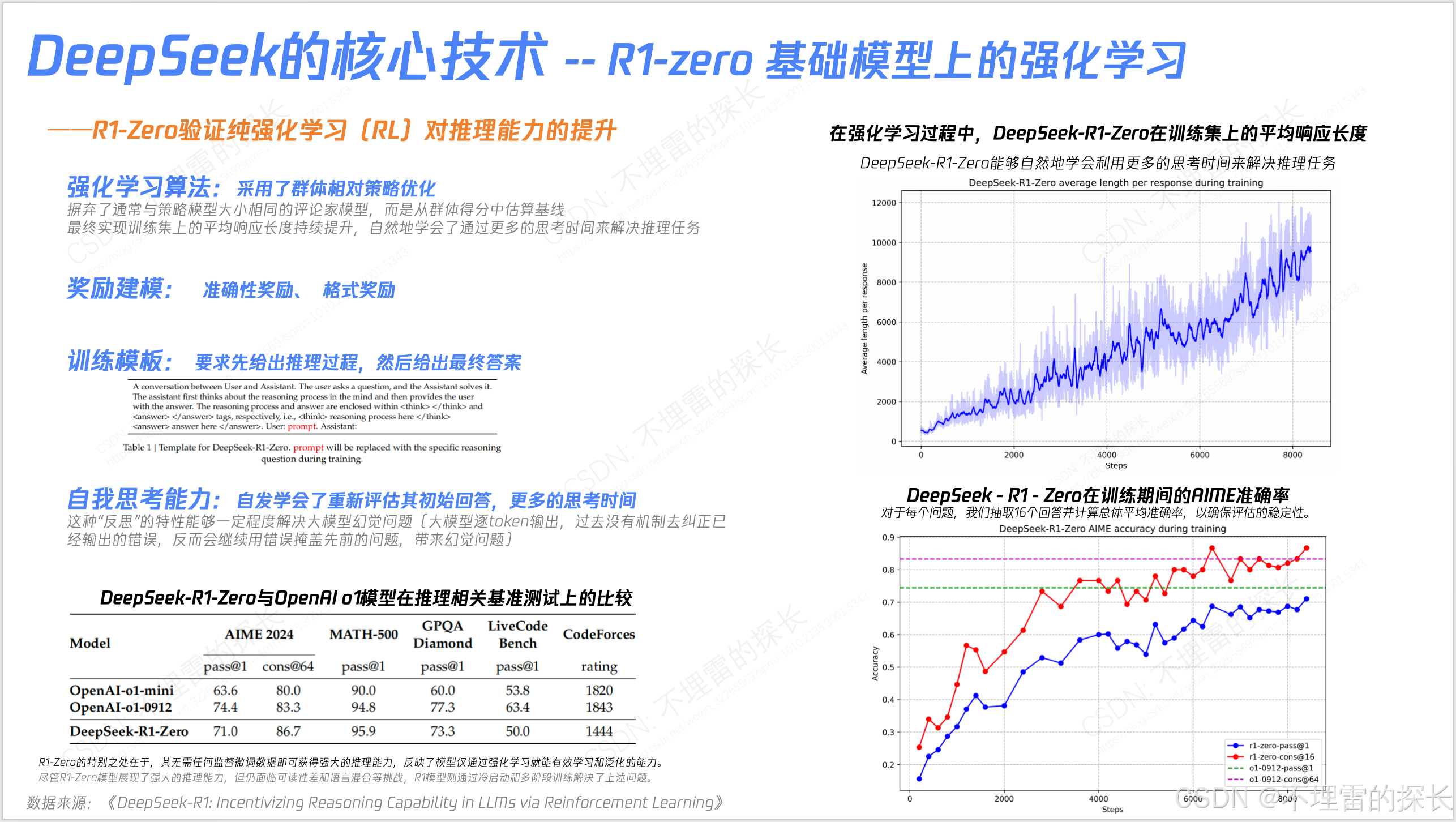
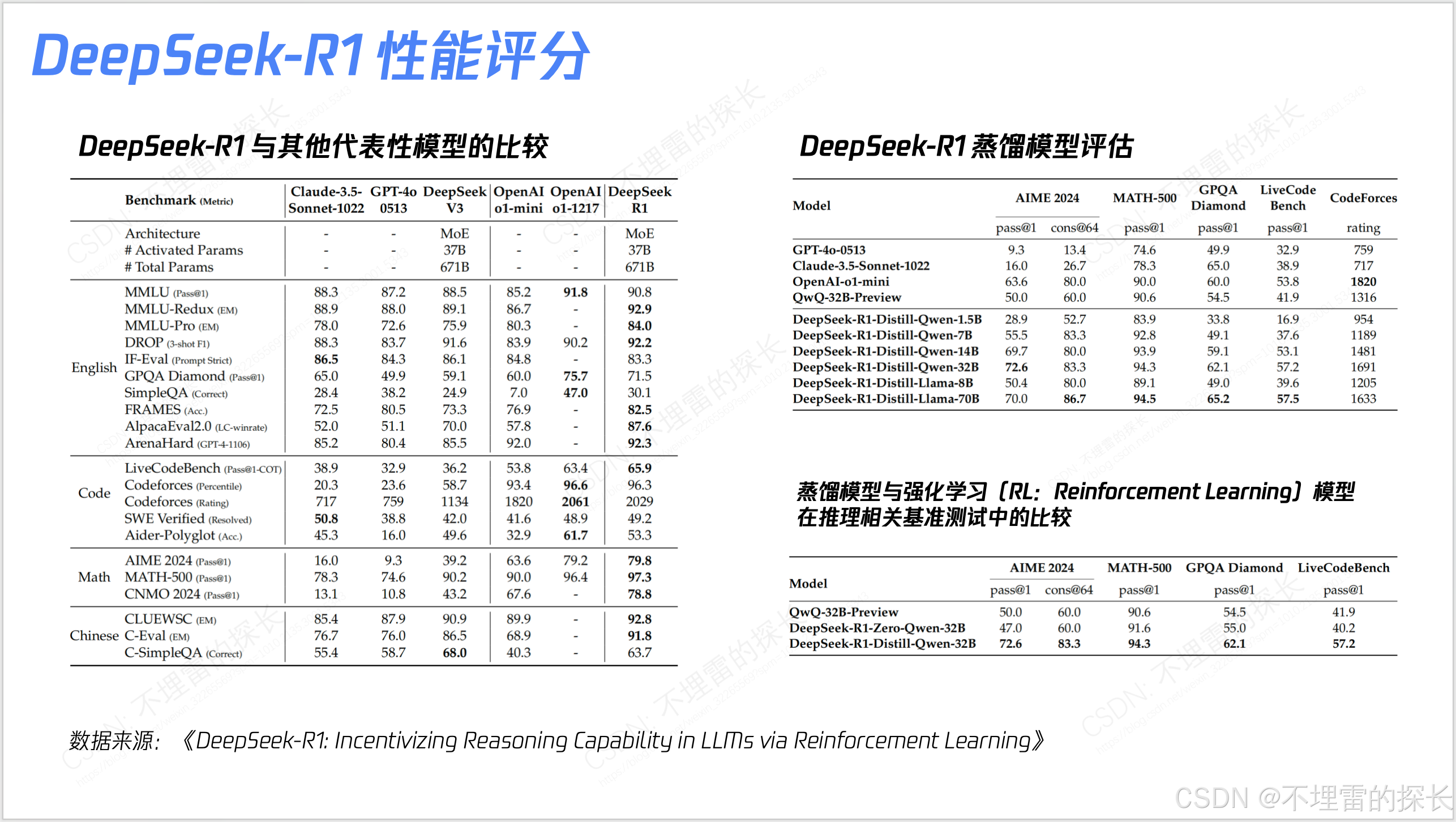
- MoE 实际是从 Basic版本 --> V2版本 --> V3版本,逐步迭代并不是一上来就干全了,是反复权衡;
- MoE 在V2 是有丢低效Token策略;但在V3上因为更有效的负载均衡策略 从“丢低效Token策略” ---> "无Token丢弃";
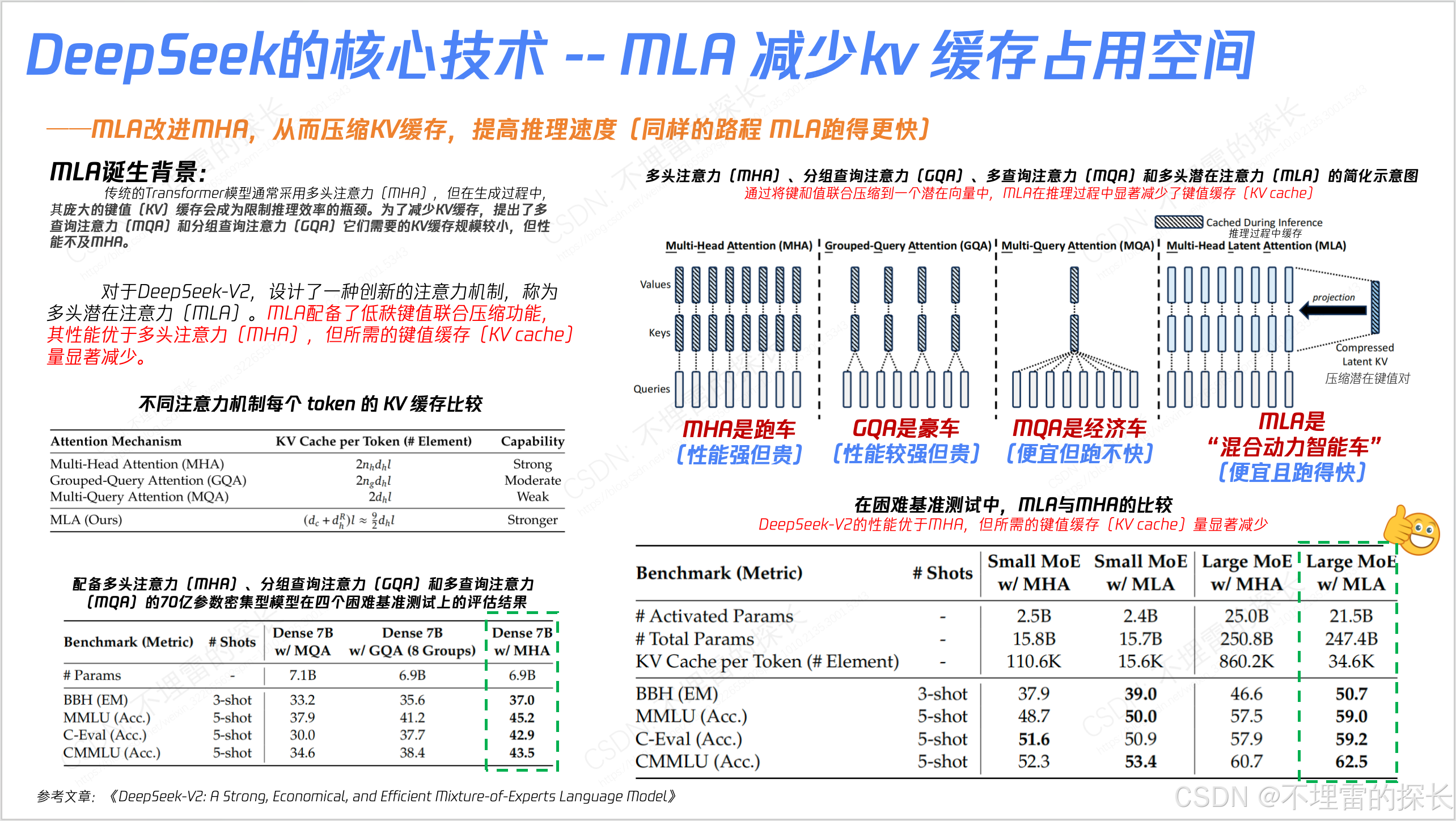
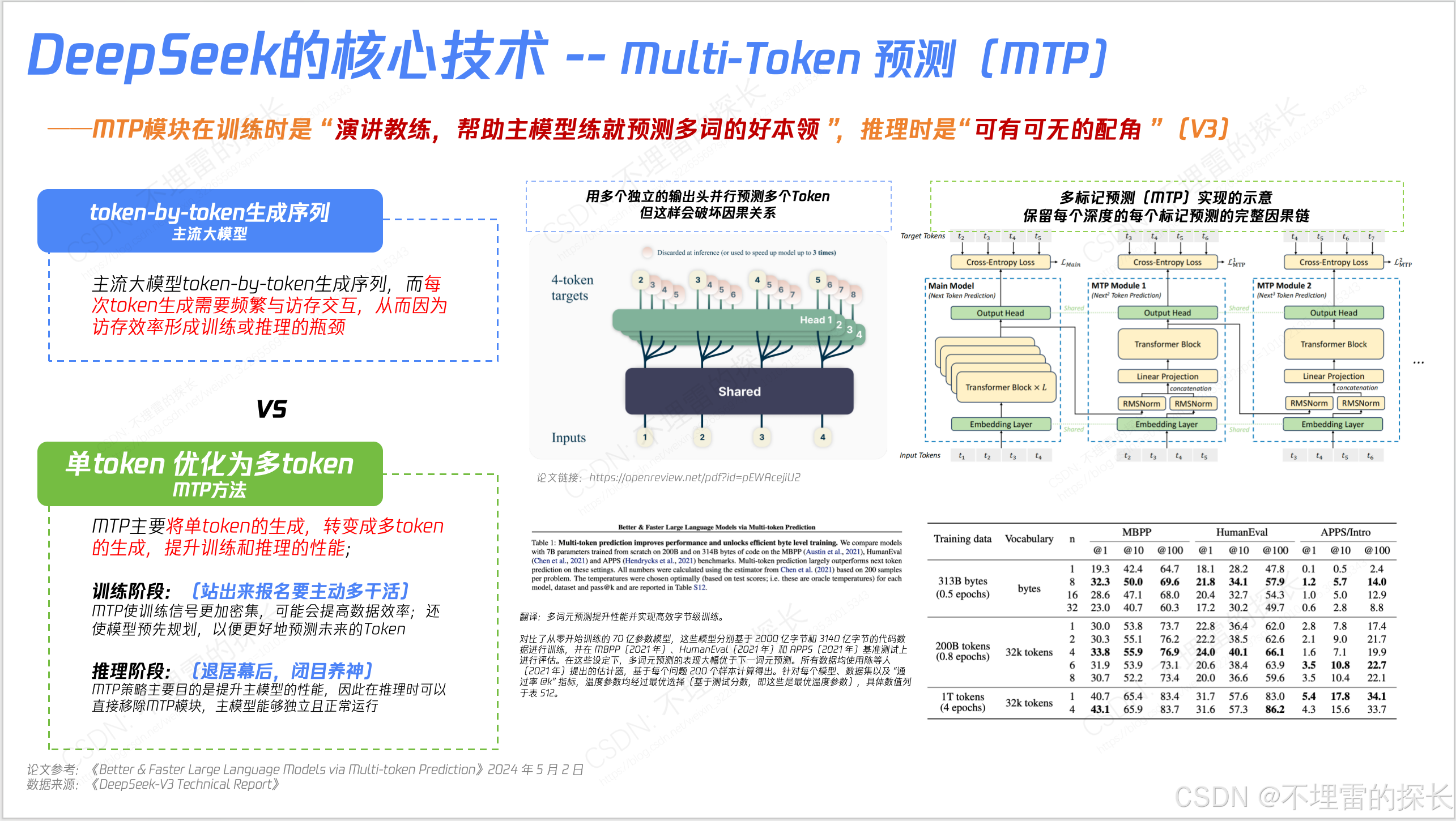
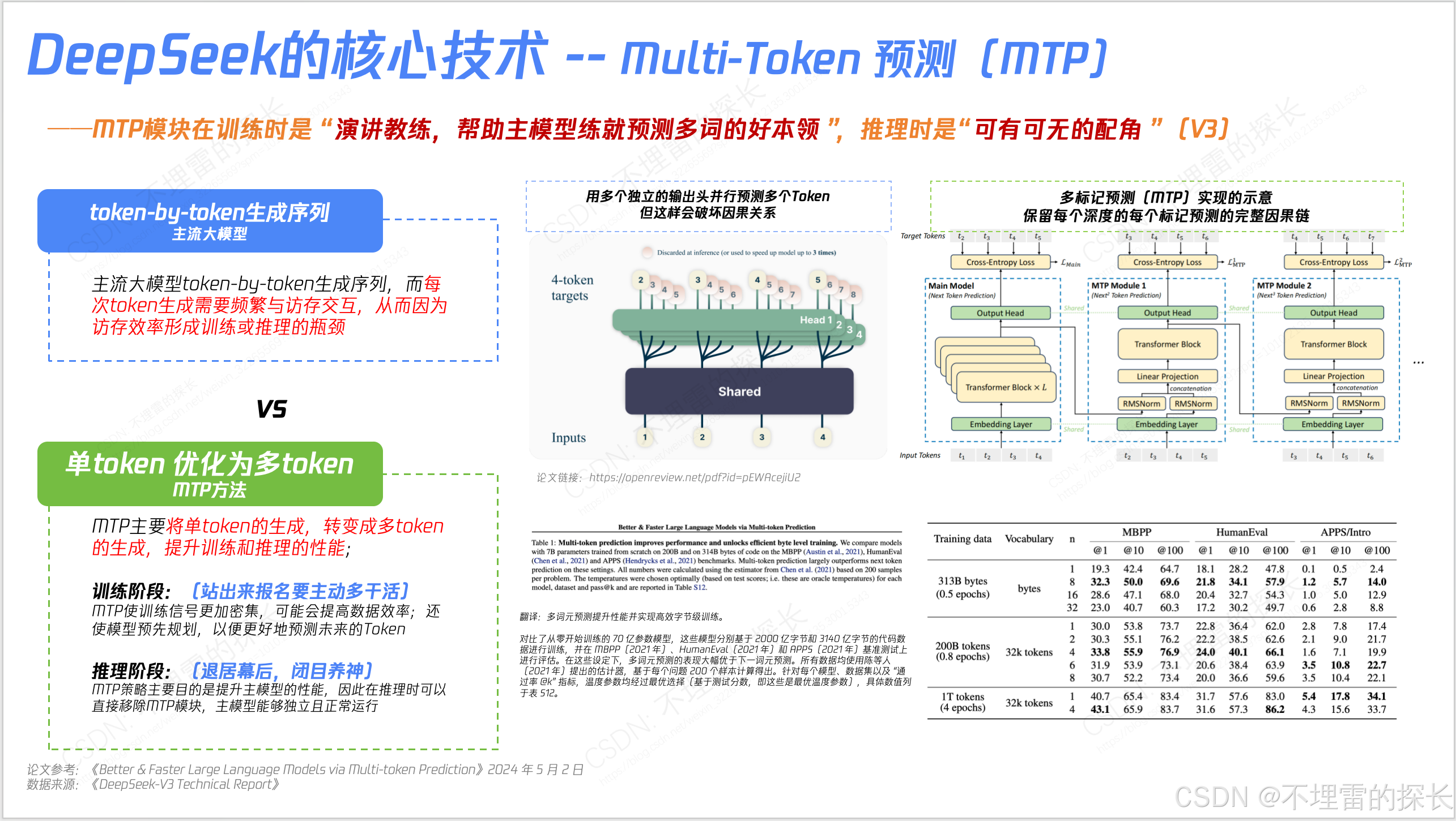
- 训练框架上除了DualPipe外,还有很多创新 如“高效并行策略、跨节点通信优化、内存管理”;
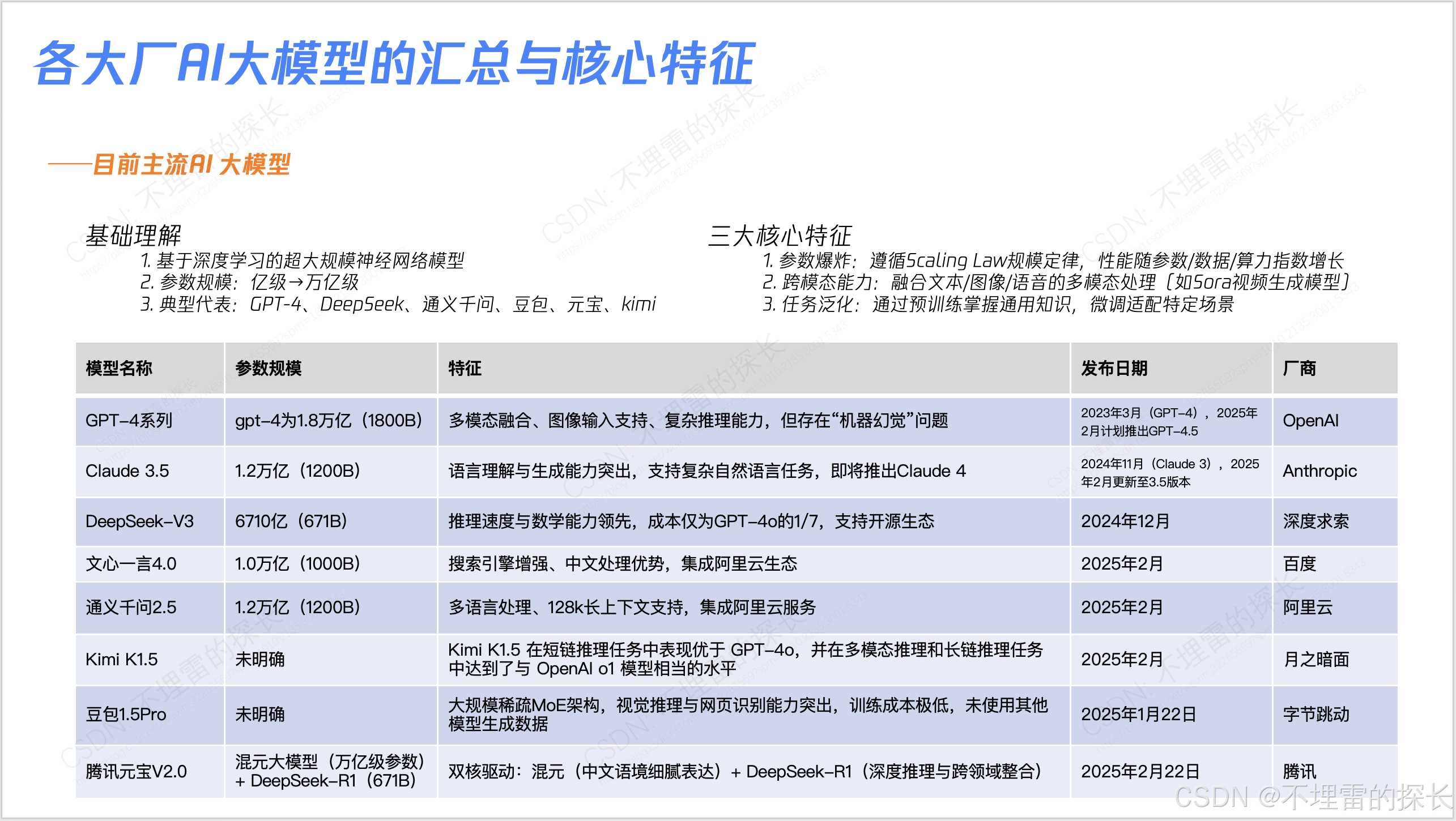
- DeepSeek众多创新背后有非常大吸收国外、国内比较前沿的技术论文,迭代跟进快、落地迅速;


























 80
80

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











