







今天是八月2号,自学python爬虫已经一整个月了。不学不理解,真正学了才发现,python不愧是一门博大精深的高级编程语言,我学到现在也才只见识到它冰山一脚,python应用的范围即便相比于c、c++、java等老牌语言也不逞多让;爬虫只是它庞大功能体系的一种,而我一个月来的学习单论爬虫这一块来说也只能说堪堪入门,距离熟练使用再到掌握还有很遥远的路程。
虽然爬虫的路途依旧遥远,但一个月的努力也不可能白费,想起来还没有尝试过股票数据的抓取,为了检测进度,也算打磨打磨暑期时间,just do it!
既然要爬取网站的股票信息,那就要选好目标网站,根据网络爬虫的robots协议的协定和大站优先的爬虫策略,在观察了多家股票大头网站后,我最终选定了——‘东方财富网’进行数据爬取,该网站robots.txt文件信息如下

可以看见,该网站允许所有搜索引擎按照robots协议合理的抓取网站中的所有文件、目录。那么我就可以放心大胆的进行爬虫了!
进入该网站找到沪深A股所有个股的列表界面,方便爬虫爬取信息
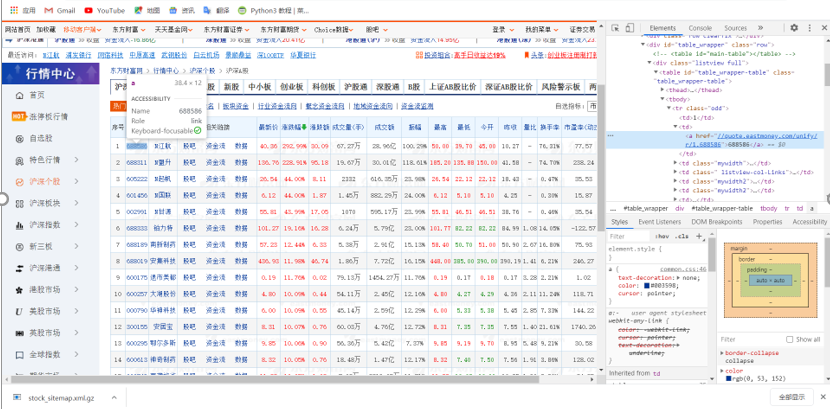 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









