







1、首先得先知道KMeans算法原理:
K-means算法,也被称为k-平均或k-均值算法,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优(平均误差准则函数E )。下面用一个直观的图和相应文字来解释。
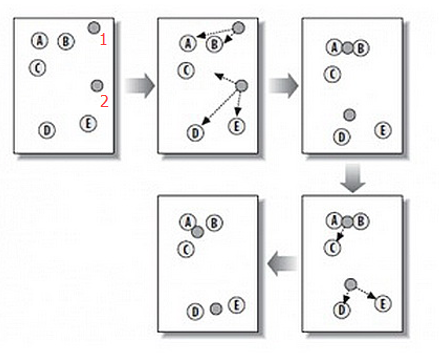
上图中,其中A, B, C, D, E 是五个在普通点,而灰色的点是种子点,即种子点共2个,所以K=2。
然后,K-Means的算法如下:
1) 随机在图中取K(这里K=2)个种子点。
2) 对图中的其他所有点求到这K个种子点的距离,若点A离种子点S1最近,那么A属于S1点 群。如上图, A,B属于种子点1,C,D,E属于种子点2。
3) 移动种子点到属于它的“点群”的中心。如上图中第三幅。
4) 重复上述第2)和第3)步骤,直至种子点未移动,得到最终结果。
求点群中心的算法:
Minkowski Distance (闵可夫斯基距离)
Euclidean Distance(欧几里得距离)
Manhattan Distance( 曼哈顿距离)
由于欧几里得距离最易理解,此文我们选用此算法来计算点群中心。
2、准备数据kmeans.txt:

3、获取种子点,此处K=3,则可取最大最小值作为其中两个种子点,然后再去均值作为第三个种子点。代码如下:
/**
* 计算种子点
* @author ZD
*
*/
public class ClusterPoint {
private static class ClusterPointMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
for (int i = 1; i <= strs.length; i++) {
context.write(new Text("c"+i), new IntWritable(Integer.parseInt(strs[i-1])));
}
}
}
private static class ClusterPointReducer extends Reducer<Text, IntWritable, Text, Text> {@Override
protected void reduce(Text value, Iterable<IntWritable> datas,
Reducer<Text, IntWritable, Text, Text>.Context context) throws IOException, InterruptedException {
int min = Integer.MAX_VALUE;
int max= Integer.MIN_VALUE;
for (IntWritable data : datas) {
if(data.get() < min){
min = data.get();
}
if(data.get() > max){
max = data.get();
}
}
context.write(value, new Text(min+", "+max));
}
}
public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
Job job = Job.getInstance(cfg);
job.setJobName("ClusterPoint");
job.setJarByClass(ClusterPoint.class);
job.setMapperClass(ClusterPointMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(ClusterPointReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/input/kmeans.txt"));
FileOutputFormat.setOutputPath(job, new Path("/ClusterPoint/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}}
获得种子点后将结果手动写入文件clusterPoint.txt,保存至hdfs的/kmeans/output1/下。如图:
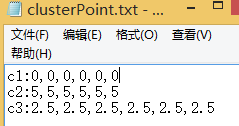
因为我们需要知道kmeans.txt中所有点和种子点c1,c2,c3的距离,并找出其每个点和三个种子点距离最近的种子点,即属于那个点群。然后重新计算三个点群的新种子点,即找到点群的中心点。不断重复上述步骤,得到最终的种子点。
将上述原理转换为MapReduce过程,即在Mapper层找到每个点距离最近的种子点,然后以(种子点名,点)形式传入Reducer层;Reducer层计算该点群的中心点并写入文件,且格式与clusterPoint.txt格式相同。
4、迭代获取最终种子点。原理已经解释清楚,接下来就是具体代码实现:
/**
* 迭代计算生成新种子点
*
* @author ZD
*
*/
public class KMeansExer {private static Configuration cfg = HadoopCfg.getConfigration();
private static class KMeansExerMapper extends Mapper<LongWritable, Text, Text, Text> {
private Map<String, Vector<Double>> map = new HashMap<String, Vector<Double>>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSystem fs = FileSystem.get(cfg);
Path path = new Path(cfg.get("seed"));
RemoteIterator<LocatedFileStatus> rt = fs.listFiles(path, false);
while (rt.hasNext()) {
LocatedFileStatus status = rt.next();
Path filePath = status.getPath();
// 每次迭代是迭代新生成的种子点文件
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(filePath)));
String line = "";
while ((line = br.readLine()) != null) {
String[] strs = line.split(":");
map.put(strs[0], KMeansUtil.str2Vector(strs[1], ",")); //KMeansUtil是自己写的工具类,str2Vector是将字符串按照规定字符分割,并将其保存至Vector中。
}
br.close();
}
}@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
if (fileName.equals("kmeans.txt")) {
Vector<Double> pVector = KMeansUtil.str2Vector(value.toString(), ",");
String center = "";
// 第一次距离是最大的值
double distance = Double.MAX_VALUE;
Set<String> keys = map.keySet();
for (String ckey : keys) {
double temp = KMeansUtil.getDistance(pVector, map.get(ckey)); //getDistance获得pVector中存的value这个点与所有种子点的距离
if (temp < distance) {
distance = temp;
center = ckey;
}
}
context.write(new Text(center), value); //将距离最近的种子点和该种子点传入Reducer层
}
}}
private static class KMeansExerReducer extends Reducer<Text, Text, Text, NullWritable> {
@Override
protected void reduce(Text value, Iterable<Text> datas, Reducer<Text, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
List<Vector<Double>> list = new ArrayList<Vector<Double>>();
int size = 0;
for (Text data : datas) {
Vector<Double> v = KMeansUtil.str2Vector(data.toString(), ",");
size = v.size();
list.add(v);
}
context.write(new Text(value.toString() + ":" + avgDistance(list, size)), NullWritable.get());
}}
public static String avgDistance(List<Vector<Double>> list, int size) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < size; i++) {
double sum = 0.0;
for (Vector<Double> v : list) {
sum += v.get(i);
}
double avg = sum / list.size();
sb.append(avg).append(",");
}
return sb.toString();
}public static void run(int i) throws Exception {
Job job = Job.getInstance(cfg);
cfg.set("seed", "/kmeans/output" + i);
job.setJobName("KMeansExer");
job.setJarByClass(KMeansExer.class);
job.setMapperClass(KMeansExerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(KMeansExerReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/kmeans.txt"));
FileInputFormat.addInputPath(job, new Path("/kmeans/output" + i));
FileOutputFormat.setOutputPath(job, new Path("/kmeans/output" + (i + 1)));
job.waitForCompletion(true);
}public static void main(String[] args) {
try {
for (int i = 1; i <= 10; i++) {
run(i);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
我们可以发现上述程序,迭代到第5次时,结果未发送改变了。但是值得注意的是,结果丢失了一个种子点。如图:

所以,最初选种子点时,是非常重要的。稍作更改,将初始种子点改为:

我们会发现在第8次时,结果稳定,得到最终的种子点。如图:

5、获得最终结果。虽然已获得稳定种子点,但是还未知道每个点属于哪一个点群。实现如下:
/**
* 获得最终三个点群
* @author ZD
*
*/
public class KMeansResult {private static class KMeansResultMapper extends Mapper<LongWritable, Text, Text, Text> {
private Map<String, Vector<Double>> map = new HashMap<String, Vector<Double>>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
Configuration cfg = HadoopCfg.getConfigration();
FileSystem fs = FileSystem.get(cfg);
Path path = new Path(cfg.get("seed"));
RemoteIterator<LocatedFileStatus> rt = fs.listFiles(path, false);
while (rt.hasNext()) {
LocatedFileStatus status = rt.next();
Path filePath = status.getPath();
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(filePath)));
String line = "";
while ((line = br.readLine()) != null) {
String[] strs = line.split(":");
map.put(strs[0], KMeansUtil.str2Vector(strs[1], ","));
}
br.close();
}
}@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
if (fileName.equals("kmeans.txt")) {
Vector<Double> pVector = KMeansUtil.str2Vector(value.toString(), ",");
String center = "";
double distance = Double.MAX_VALUE;
Set<String> keys = map.keySet();
for (String ckey : keys) {
double temp = KMeansUtil.getDistance(pVector, map.get(ckey));
if (temp < distance) {
distance = temp;
center = ckey;
}
}
context.write(new Text(center), value);
}
}}
private static class KMeansResultReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text value, Iterable<Text> datas, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
for (Text data : datas) {
context.write(value, data);
}
}}
public static String avgDistance(List<Vector<Double>> list, int size) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < size; i++) {
double sum = 0.0;
for (Vector<Double> v : list) {
sum += v.get(i);
}
double avg = sum / list.size();
sb.append(avg).append(",");
}
return sb.toString();
}public static void main(String[] args) {
try {
Configuration cfg = HadoopCfg.getConfigration();
cfg.set("seed", "/input/kmeans/output8/");
Job job = Job.getInstance(cfg);
job.setJobName("KMeansResult");
job.setJarByClass(KMeansResult.class);
job.setMapperClass(KMeansResultMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(KMeansResultReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/input/kmeans.txt"));
FileOutputFormat.setOutputPath(job, new Path("/kmeans/result/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);} catch (Exception e) {
e.printStackTrace();
}
}
}
获得最终结果,部分结果展示:
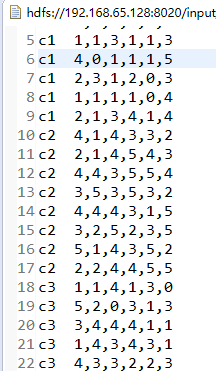
写在最后:本人也是正在学习阶段,若有错误,望指出纠正。下一次将与大家分享KNN算法,也是一个比较古老的算法,但是原理较为简单。















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









