






AI前线导读:在上周刚刚结束的IJCAI 2018大会上,中国研究人员收获颇丰,来自北京大学、武汉大学、清华大学、北京理工大学的研究均登上了杰出论文榜单。AI前线的社区编辑小伙伴、西安电子科技大学计算机视觉在读博士马卓奇也前往斯德哥尔摩参与了这一学术盛会。会后,她为AI前线的读者带来了这场AI顶级大会的参会见闻,并精选了本次大会杰出论文中的一篇进行深度解读,这也是AI前线第41篇论文导读。
\\更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
\\七月,斯堪的纳维亚半岛的阳光温暖舒适,继ICML2018后,在斯德哥尔摩这片文化氛围浓郁的土地上,召开了同为人工智能顶级会议的IJCAI2018。本届IJCAI(International Joint Conference on Artificial Intelligence,人工智能国际联合大会)与ECAI(European Conference on Artificial Intelligence,人工智能欧洲会议)合办,所以全称为IJCAI-ECAI2018。
\\我有幸参与这一学术盛会,在过去一周的时间里,与学界和业界人士进行了各种交流,今天便给大家带来会议见闻,以及IJCAI的杰出论文解读。本次会议主题为:人工智能的进化图景(The Evolution of the Contours of AI),鼓励人们围绕人工智能的发展趋势进行深入讨论。
\\会议在斯德哥尔摩会展中心举行,13号-15号为Workshop和Tutorial。13日,蒙特利尔大学教授Yoshua Bengio带来了主题为《Deep Learning for AI》的报告。主要介绍了卷积神经网络、循环神经网络、注意力机制、生成模型、迁移学习以及强化学习等深度学习方法,以及他们在各个不同场景的应用;并且探讨了未来无监督学习、强化学习的挑战。
\\在16号早晨的开幕式中,大会以一段人与机器人的舞蹈开场,随后FaceBook首席人工智能科学家、纽约大学教授Yann LeCun做了以《Learning world models: the next step towards AI》为主题的演讲。回顾了过去几年监督式学习和强化学习取得的成功。Yann LeCun谈到当前深度学习缺乏推理能力,因此未来的一个重点发展方向就是深度学习和推理的结合。目前AI系统缺乏关于世界运行的通用背景知识,所以为系统建立完整的世界表征才是真正需要的。
\\在上午的开幕式中,大会公布了杰出论文(Distinguished Paper)。与往届不同,今年的 IJCAI 大会未颁发“最佳论文”、“最佳学生论文“等奖项,而是 7 篇杰出论文。本文选择了北京大学计算机科学技术研究所的《SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks》进行解读。
\\
摘要
\\在自然语言生成领域,不同情感文本的生成受到越来越广泛的关注。近年来,生成对抗网(GAN)在文本生成中取得了成功的应用。然而,GAN所产生的文本通常存在质量差、缺乏多样性和模式崩溃的问题。在本文中,我们提出了一个新的框架——SentiGAN,包含有多个生成器和一个多类别判别器,以解决上述问题。在我们的框架中,多个生成器同时训练,旨在无监督环境下产生不同情感标签的文本。我们提出了一个基于惩罚的目标函数,使每个生成器都能在特定情感标签下生成具有多样性的样本。此外,使用多个生成器和一个多类判别器可以使每个生成器专注于准确地生成自己的特定情感标签的例子。在四个数据集上的实验结果表明,我们的模型在情感准确度和生成文本的质量方面始终优于几种最先进的文本生成方法。
\\背景介绍
\\情感智能是人工智能的重要分支,理解和生成情感文本不仅仅可以让机器更亲近人类,更可以使他们看起来更智能。如今,情感分类已经取得了良好的进展,但是情感文本生成依然是一大挑战。生成对抗网络是解决这一问题的好方法,它使用判别器而不是某个特定目标函数来指导生成器。主要的想法在于,由于文本情感分类已经十分成熟,我们可以利用分类器来引导情感文本的生成。
\\在这篇文章中,我们的目标是利用GAN生成具有高质量、多样性的情感文本。也就是说,在缺少语料的情况下,我们可以自动生成大量可控的情感文本。然而,在应用GAN来生成情感文本时,需要解决几个问题。首先,文本的离散特性使采样步骤是不可微的,因此也无法让梯度通过判别器传递给生成器。其次,GAN的主要缺点在于“模式崩溃”,经验表明,GAN更倾向于围绕某几个模式生成样本,而忽略其他模式。因此在生成文本中缺乏多样性。
\\我们提出的SentiGAN解决了上述问题。首先,我们提出新的目标函数,通过最小化整体损失而不是最大化奖励来优化模型。其次,判别器使用多类别分类目标函数,可以让生成器更关注于生成他们情感标签的样本,而不与其他标签混淆,这一点提高了生成文本的情感准确性。我们使用一个情感分类器作为评价方法,来验证生成文本的情感准确度,以及其他指标(流畅度、新颖度、多样性、智能性)。
\\论文贡献
\\(1) 我们提出了一个新的框架SentiGAN来生成多样性的、高质量的、具有不同情感类别的文本。
\\(2) 我们提出了一个新的基于惩罚的目标函数,让SentiGAN的每个生成器都能为特定情感标签产生多样性的文本。
\\(3) 我们在四个数据库上进行大量实验,证明了所提方法的有效性和先进性。
\\SentiGAN
\\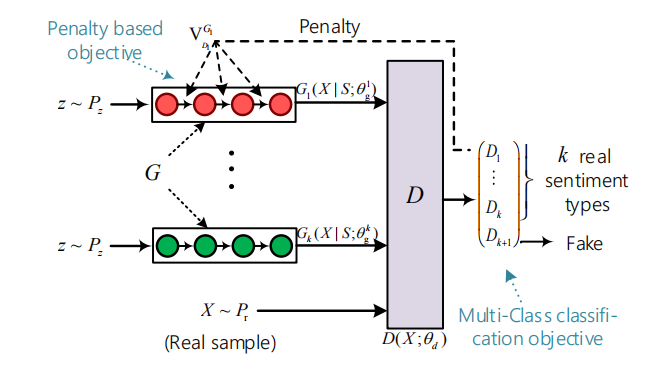
图1 SentiGAN,由k个生成器和一个多类别判别器。
\\算法框架
\\假设我们想生成k类情感文本,我们则使用k个生成器和一个判别器。整个框架可以分为两个对抗学习目标:生成器的学习目标和判别器的学习目标。第i个生成器Gi的目标是生成具有第i类情感类型的文本,尽量欺骗判别器。而判别器的目标,是区分生成文本和k类真实文本,因此我们采用多类别分类目标函数。在实验中,我们将k设置成2,使SentiGAN生成两类情感文本(积极情感和消极情感)。
\\生成器学习
\\为了解决离散输出情况下,梯度无法传递回生成模型的问题,我们将文本生成问题转化为序列决策步骤。在每一个时间点t,我们训练一个生成器Gi来产生一个序列:
\\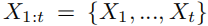
其中Xt代表给定词典C中的一个词向量。
\\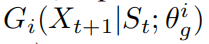 代表基于之前生成词语
代表基于之前生成词语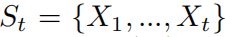 来选择第t+1个词条的概率。基于此,我们定义一个新的基于惩罚的损失函数:
来选择第t+1个词条的概率。基于此,我们定义一个新的基于惩罚的损失函数:
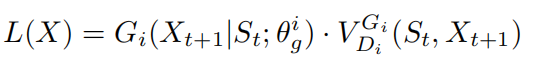
其中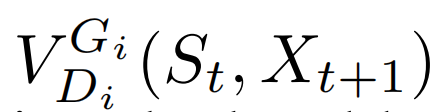 是序列
是序列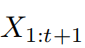 的惩罚项,由判别器进行计算。最后,第i个生成器的目标是最小化整体惩罚项:
的惩罚项,由判别器进行计算。最后,第i个生成器的目标是最小化整体惩罚项:
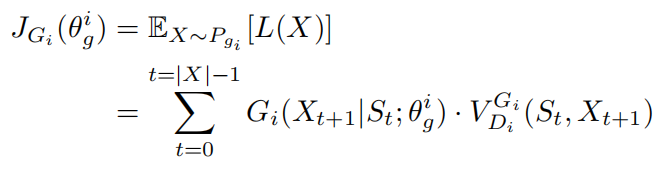
由于判别器只能鉴别一个完整的句子,因此我们采用蒙特卡洛搜索和roll-out策略对剩下的X-t个未知单词进行采样。因此,我们的第i个生成器的惩罚函数计算如下:
\\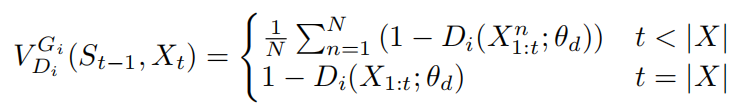
除此之外,我们的生成器是LSTM的简化层,根据如下分布生成第t个单词:
\\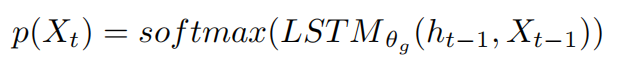
判别器学习
\\我们使用多类别分类目标函数,使判别器能够区分各类情感的真实文本与生成文本。假设有k个生成器,判别器则对k+1个类别计算softmax概率分布。第i个分数代表属于真实第i类情感文本的概率,第k+1个分数代表样本是由生成器生成的概率。判别器的目标函数是最小化:
\\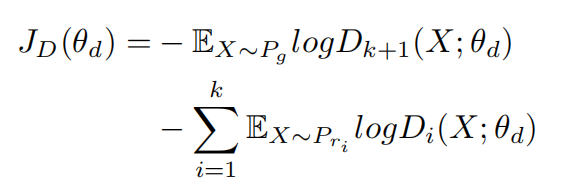
其中Pg是生成器产生的文本,Pri是真实的第i类情感文本。
\\我们采用CNN的一层网络作为判别器。我们对生成器和判别器进行对抗训练,算法总结如下:
\\
多类分类目标函数
\\本节主要介绍多类分类目标函数如何使生成器之间互相不混淆,从而提高生成文本的情感准确度。
\\首先,最优的第i个生成器可以学习第i类情感的真实文本分布。通过利用判别器,生成器的目标为最小化如下函数:
\\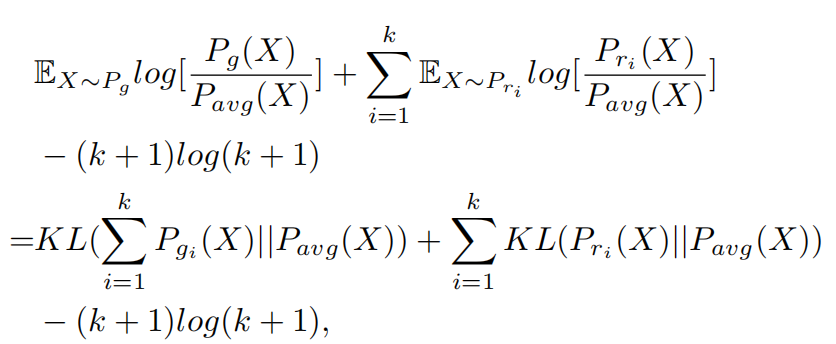
当Pgi=Pri时,上述目标函数可以得到全局极小值。
\\其次,为了从判别器得到更低的惩罚,第i个生成器生成的文本需要与第i个情感类型更一致,并且与其他情感类型距离更远。
\\基于惩罚的目标函数
\\这里我们介绍惩罚项如何使生成器产生多样性的样本,而不是仅仅产生重复的且“安全”的样本,从而帮助提升生成文本的多样性和质量。我们对比了GAN、SeqGAN和SentiGAN的生成器目标函数:
\\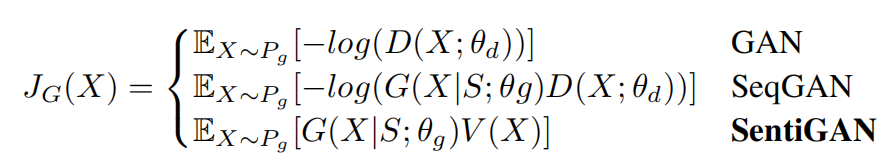
可以看出,我们的目标函数的提升主要有两个方面。首先,我们的基于惩罚的目标函数可以被视为对wasserstein距离的衡量,可以提供有意义的梯度,而另外两个损失函数则不能做到这一点。其次,我们使用损失项而不是奖励项。我们的基于惩罚的损失函数方程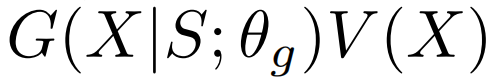 可以看作是在给基于奖励的损失函数
可以看作是在给基于奖励的损失函数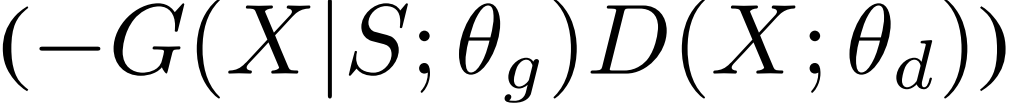 加上
加上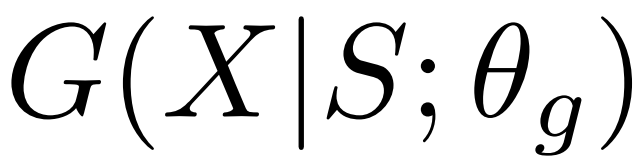 。
。
因此可以生成更有多样性的样本,而不是重复性的“好”样本。
\\实验
\\实验设置
\\我们主要在三个真实数据库上进行实验。
\\Movie Reviews(影评)。我们使用斯坦福情感分析数据库,包含两类情感文本。原始数据集一共有9613个句子。我们选择了最多15个词的句子,最终数据库包含2133个积极情感的句子和2370个消极情感的句子。
\\Beer Reviews(啤酒评价)。我们使用BeerAdvocate的数据,包含1437767条积极评价,和11202条消极评价。
\\Customer Reviews(用户评价)。我们收集了各类产品的用户评价,包含1024条积极评价和501条消极评价。
\\我们分别在每个数据库上训练模型,然后随机初始化词嵌入,维度为300。在预训练中,生成器训练120步,判别器训练50步。在对抗训练中,生成器为5步,判别器为1步。优化方法为RMSProp。我们用Tensorflow实现模型,然后使用TITAN X图像处理器。
\\生成文本的情感准确度
\\我们使用先进的情感分类器来自动评价生成文本的情感准确度。我们与多个文本生成网络进行比较,包括RNNLM、SeqGAN、VAE、C-GAN和S-VAE。为了说明用多个生成器和单个生成器的区别,我们也对比了SentiGAN(k=1)。
\\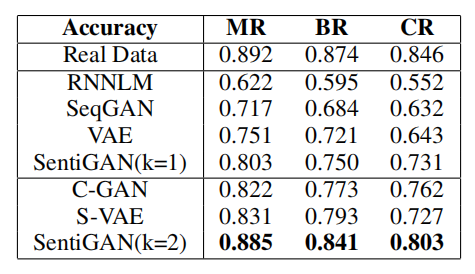
表1 生成文本的情感准确度对比。
\\可以看出我们所提的模型表现超过了所有其他方法,说明带有多个生成器和一个多类判别器的框架可以让每个生成器更好的生成自己的情感文本。除此之外,SentiGAN(k=1)和SentiGAN(k=2)的对比说明多生成器极大提高了生成文本的情感准确度。
\\生成文本的质量
\\我们使用4个评价指标来衡量生成句子的质量。
\\流畅度:我们使用语言建模工具箱-SRILM来评价生成语言的流畅度。结果如下所示。
\\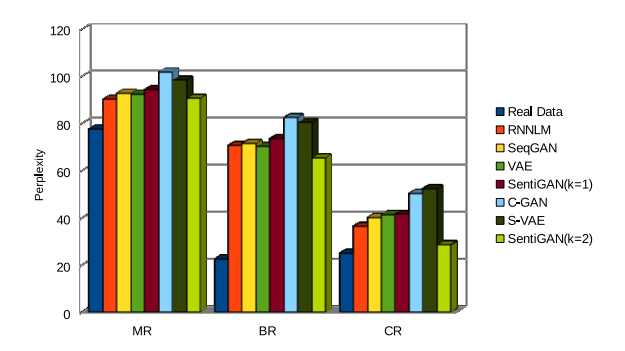
图2 生成文本的流畅度(困惑度)对比,低困惑度=高流畅度。
\\可以看出C-GAN和S-VAE方法不能很好的保持句子的流畅度,相反,我们的模型在生成不同情感表情的文本时保持了较好的流畅度,甚至在CR这种小数据库上也超过了现有方法。
\\创新性:我们想探究生成文本和训练语料的区别。换言之,我们想看看生成器是生成了新的文本,还是仅仅抄了语料库中的文本。我们对每个生成的文本用如下方法计算创新性:
\\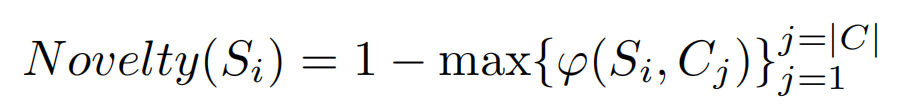
生成文本的平均值如表2所示:
\\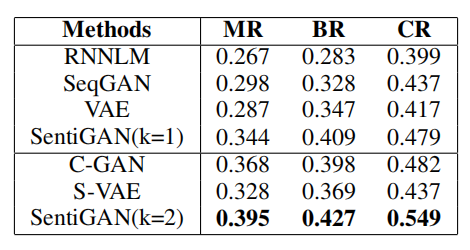
表2 生成文本的创新性对比。
\\可以看出,RNNLM、SeqGAN和VAE不能产生新的文本。对比之下,我们的模型表现十分好,能够生成与训练语料库不同的文本。
\\多样性:我们希望生成器能够生成具有多样性的句子。给定生成句子集合S,我们定义句子Si的多样性如下:
\\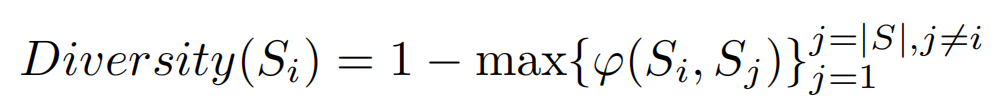
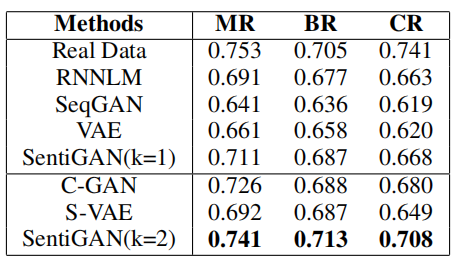
表3 生成文本的多样性对比
\\从表3中可以看出,我们的模型能够生成多样的语句,而其他模型不能保证生成文本的多样性。
\\智能性:我们用人为评价来衡量生成文本的智能性。我们从生成句子中随机提取了100个句子,然后让三个研究生根据其智能性对它们进行评价。分数从1到5,5分为最高。
\\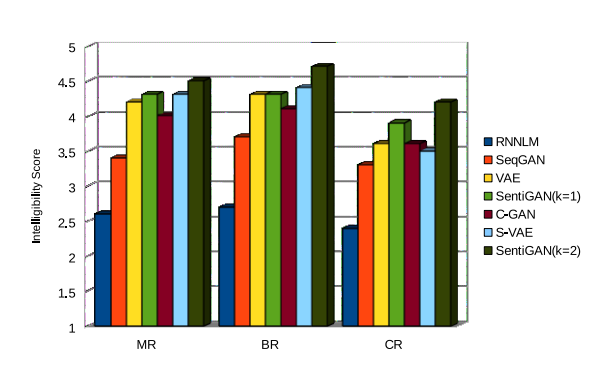
图3 生成句子的智能性评价
\\基于惩罚项的目标函数效果验证
\\这里我们使用合成数据来评测我们提出的基于惩罚项的目标函数的效果(SentiGAN(k=1))。
\\
表4 不同方法在合成数据上的表现对比,采用NLL(负对数似然)分数评价。
\\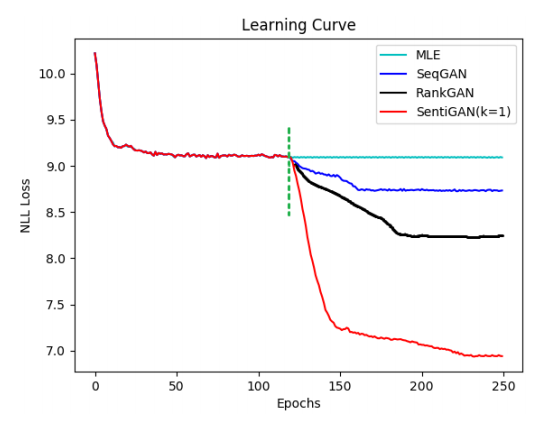
图4 学习曲线。点画线为预训练的结束点。
\\结果显示了采用基于惩罚的损失函数的有效性,我们的模型在捕捉序列词条的依赖性上优于其他模型。
\\样例研究
\\
表5 SentiGAN和C-GAN在MR训练数据集上生成的样例语句
\\从样例中,可以看到C-GAN生成的语句存在一些问题(无法阅读、太短、情感错误),而我们提出的模型产生的语句可读性更强,情感更准确,并且质量更高,而且语句长度也比C-GAN长。
\\结论与未来工作
\\在这篇文章中,我们提出了SentiGAN,能够生成不同情感类别表情的多样高质量文本。大量实验表明了SentiGAN的有效性。在未来工作中,我们将利用更复杂的生成器来增强生成文本的质量,尤其是长文本生成。我们也会将该模型应用到其他类标文本的生成(例如不同写作风格)。
\\查看论文原文:SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks
\\感谢蔡芳芳对本文的审校。














 3395
3395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









