







attention
以google神经机器翻译(NMT)为例
-
无attention:
encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state向量,再由state向量来循环输出序列每个字符。
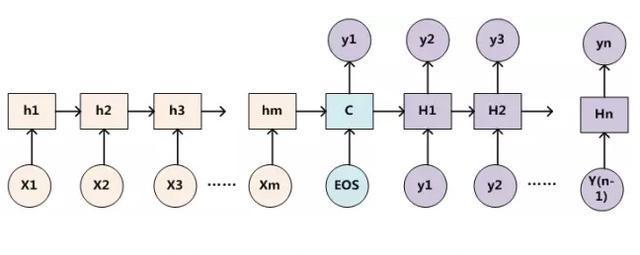
-
attention机制:
将整个序列的信息压缩在一维向量里造成信息丢失,并且考虑到输出的某个字符只与输入序列的某个或某几个相关,与其他输入字符不相关或相关性较弱,由此提出了attention机制。在encoder层将输入序列的每个字符output向量以不同权重进行组合再decode输出字符,每需要输出一个字符,encoder层权重序列都会变,这就可以理解为需要输出的字符是由哪些或那个字符影响最大,这就是注意力机制。
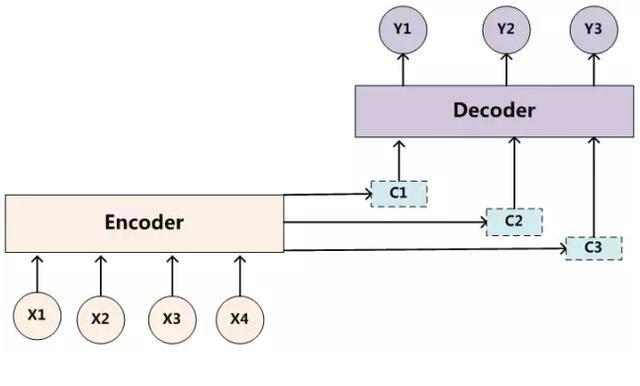
attention权重的获得需要通过一个函数层获得,而该函数参数需要通过training来优化,详细理解可以参考我这篇blog
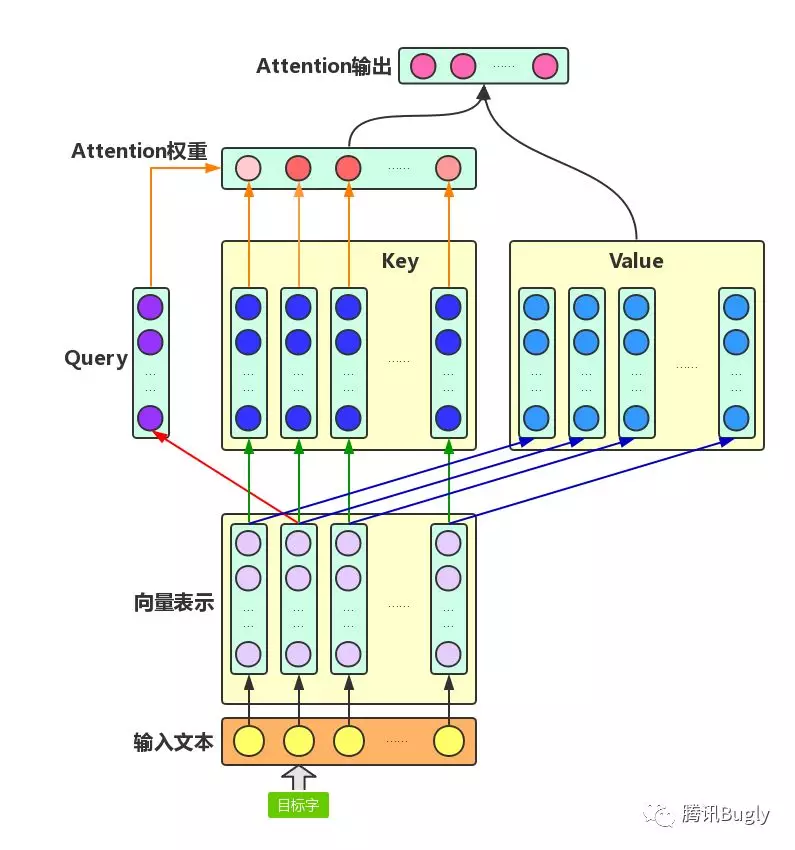
从增强字/词的语义表示这一角度来理解一下Attention机制:
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。
self-attention
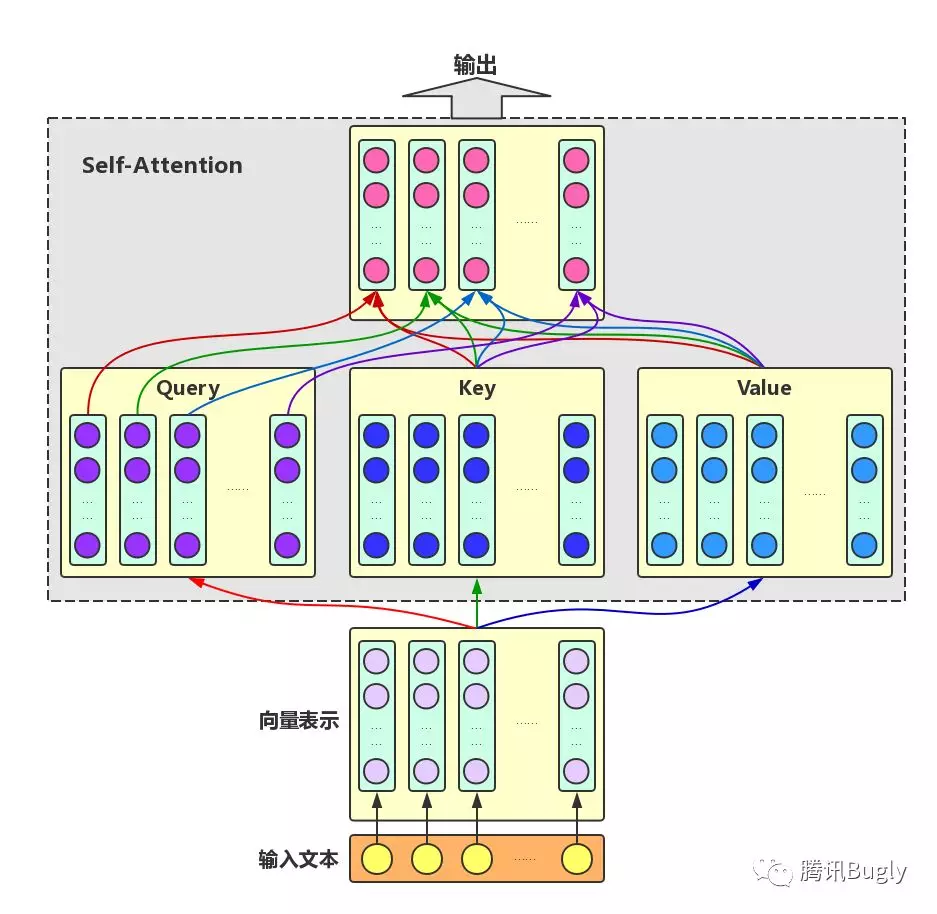
self-attention来自于google文章《attention is all you need》。 一个序列每个字符对其上下文字符的影响作用都不同,每个字对序列的语义信息贡献也不同,可以通过一种机制将原输入序列中字符向量通过加权融合序列中所有字符的语义向量信息来产生新的向量,即增强了原语义信息。
Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
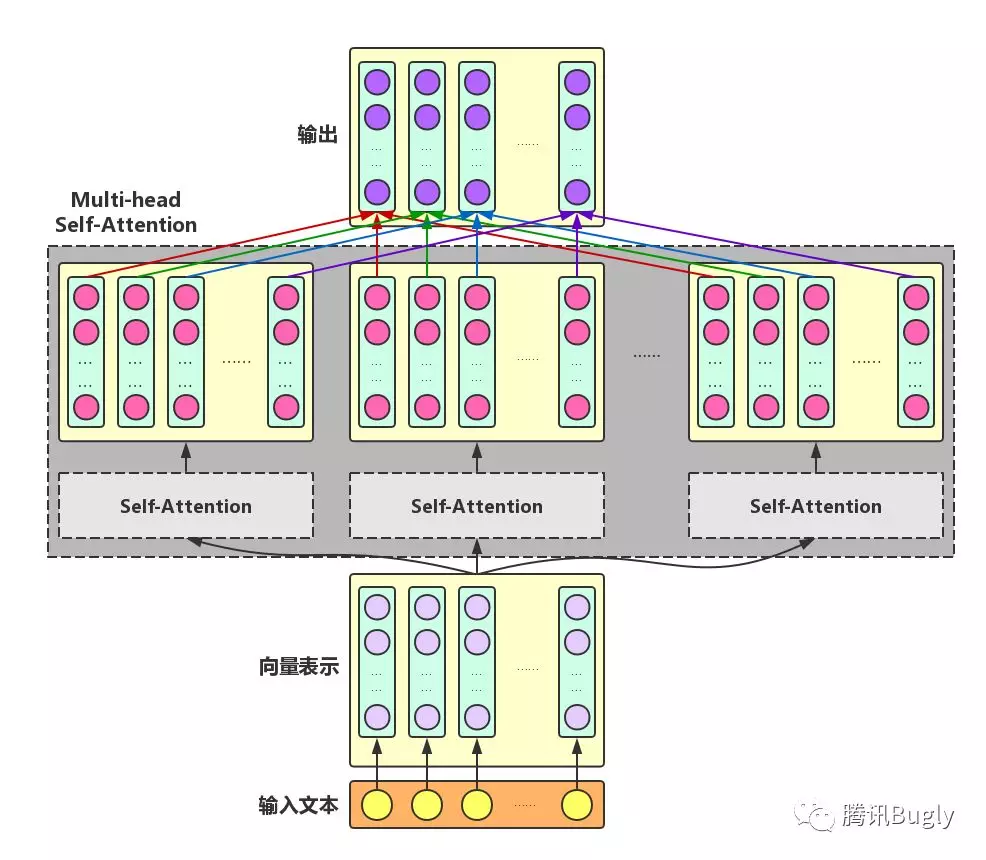
Multi-head Self-Attention
为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。
Transformer
在Multi-headSelf-Attention的基础上再添加一些“佐料”,就构成了大名鼎鼎的Transformer Encoder。实际上,Transformer模型还包含一个Decoder模块用于生成文本,但由于BERT模型中并未使用到Decoder模块,因此这里对其不作详述。下图展示了Transformer Encoder的内部结构,可以看到,Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
-
残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
-
Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
-
线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
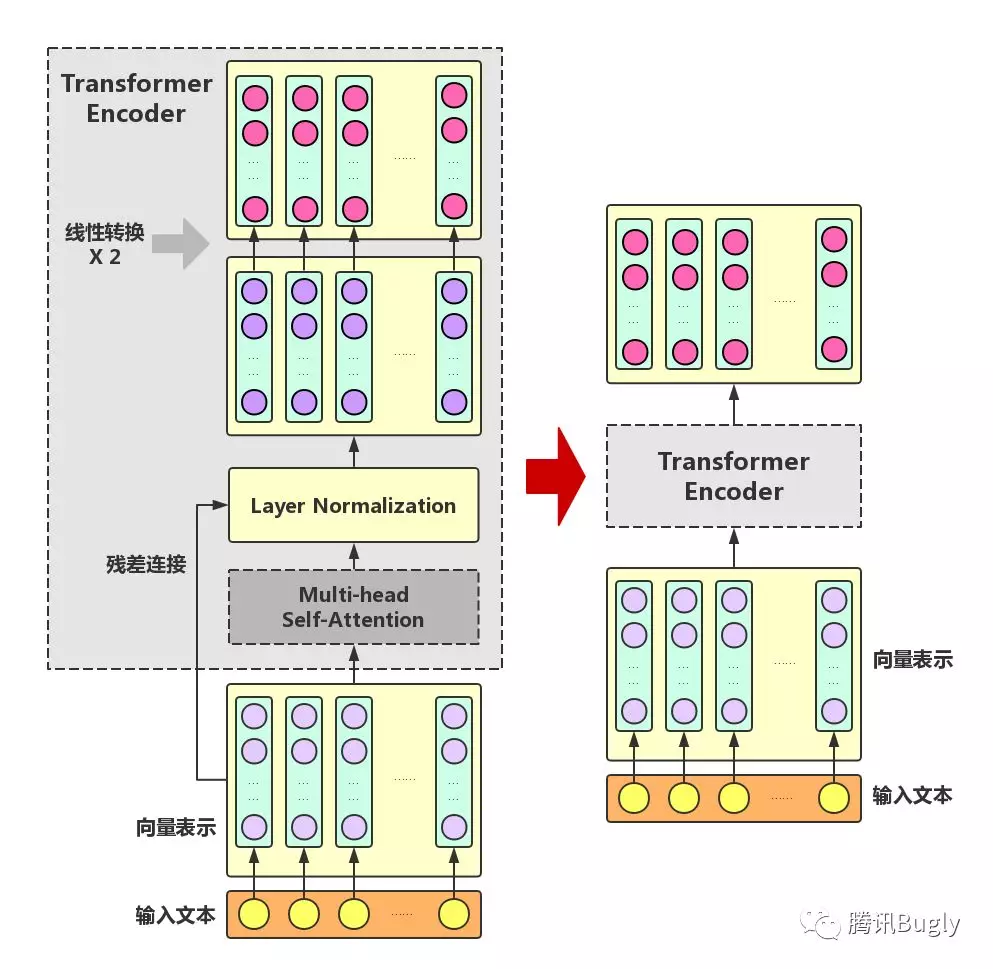
可以看到,Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
bert
把Transformer Encoder模块一层一层的堆叠起来就是大名鼎鼎的bert了 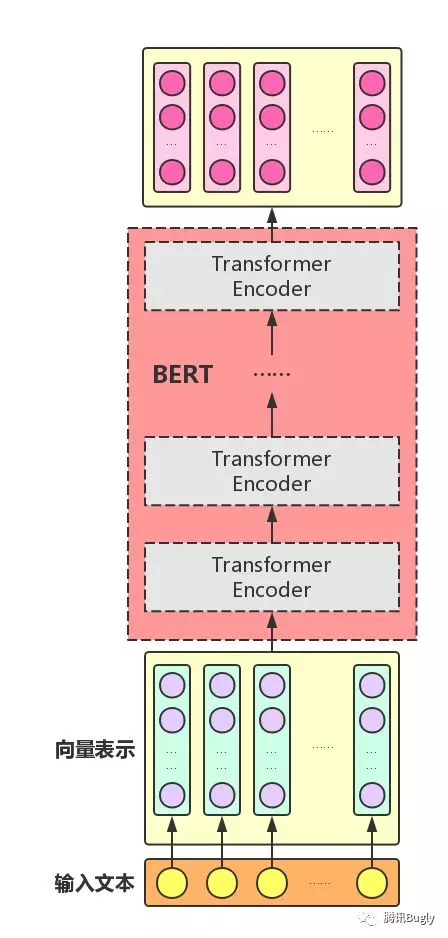
参考1:https://mp.weixin.qq.com/s/HOt11jG0DhhVuFWYhKNXtg 参考2:https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









