







上一篇 从Attention到Bert——2 transformer解读
文章目录
Bert介绍
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
Bert模型结构
bert的模型结构在预训练阶段和Finetune阶段有细微的不同,这里介绍预训练阶段的模型结构。

内部结构就是:

- L来表示BertLayer的层数,即BertEncoder是由L个BertLayer所构成;L=12
- H用来表示模型的维度;H=768
- A用来表示多头注意力中多头的个数。A=12
有两种bert模型。分别是Bertbase(L=12,H=768,A=12)和Bertlarge(L=24,H=1024,A=16)
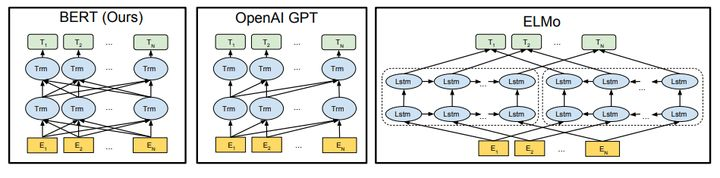
1 与GPT,ELMO结构对比
bert和gpt以及ELMO的模型对比如下,可以看出,Bert,ELMO都是双向的,而GPT是单向的,直观上双向的可能会好一些。
因为GPT的单向,所以在NLU任务上表现可能不太好,比如,单向只能从左到右或者从右到左,下图。

对于这句样本来说,无论是采用left-to-right还是right-to-left的方法,模型在对“it”进行编码时都不能够很好的捕捉到其具体的指代信息。这就像我们人在看这句话时一样,在没有看到“tired”这个词之前我们是无法判断“it”具体所指代的事物(例如把“tired”换成“wide”,则“it”指代的就是“street”)。如果采用双向编码的方式则从理论上来说就能够很好的避免这个问题,如图

对比ELMo,虽然都是 “双向”,但目标函数其实是不同的。
-
ELMo是分别以 P ( w i ∣ w 1 , … w i − 1 ) P\left(w_{i} \mid w_{1}, \ldots w_{i-1}\right) P(wi∣w1,…wi−1) 和 P ( w i ∣ w i + 1 , … w n ) P\left(w_{i} \mid w_{i+1}, \ldots w_{n}\right) P(wi∣wi+1,…wn) 作为目标函数,独立训练处两个 representation然后拼接。
-
BERT则是以 P ( w i ∣ w 1 , … , w i − 1 , w i + 1 , … , w n ) P\left(w_{i} \mid w_{1}, \ldots, w_{i-1}, w_{i+1}, \ldots, w_{n}\right) P(wi∣w1,…,wi−1,wi+1,…,wn) 作为目标函数训练 L M \mathrm{LM} LM 。
2 Bert的输入

-
Bert的输入是每个token的表征(representation),token对应红块,表征对应黄块。
-
单词字典vocab.txt采用wordpiece算法进行构建。
-
CLS: 为了完成分类任务,在句子前加入特定的分类token(CLS),在最后一层的transformer输出,用来表征整个序列信息。所以可以用cls的表征作为分类特征。
-
SEP: 为了区别sentence1和2,中间采用分割token(SEP)进行隔断。
token的表征主要分为三部分:token,分割和位置的embeddings(维度:768)。然后依次进行叠加。关于为什么三个embeddings可以相加,可以看为什么Bert的三个Embedding可以进行相加,数学证明及代码
这里的位置编码和attention里面的不同。这里采用的是可训练的参数表示,而attention里面采用了固定的公式来计算,也就是三角函数。

3 Bert的输出
transformer的特点就是输入和输出维度一样,所以对应输入,就可以得到对应的输出,

- C: 分类token([CLS])对应最后一个Transformer的输出
- Ti: 其他token对应最后一个Transformer的输出
到此预训练任务就已经结束了,至于下游任务。就是将这些C或者ti作为输入,经过其他层进行分类或者序列标注任务。
Bert两大预训练任务MLM, NSP
Bert本质上是一个自编码器模型,通过两个子任务来实现对输入的特征向量表示,Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
为了能见多识广,BERT 使用 3 亿多词语训练,采用 12 层双向 Transformer 架构。注意,BERT 只使用了 Transformer 的编码器部分,可以理解为 BERT 旨在学习庞大文本的内部语义信息。
1 CV的预训练任务
CV的预训练任务已经很成熟了,而且应用广泛,一般是采用ImageNet分类数据集,抽取出良好的图像特征,同时ImageNet数据集有规模大、质量高的优点,因此常常能够获得很好的效果。
虽然NLP领域没有那么多高质量的人工标注数据,但是大规模文本数据的自监督性质可以构建预训练任务。
2 Masked language model, MLM 掩码语言模型
通过MLM来进行词语间的语义建模。对于MLM任务来说,
- 做法1:是随机掩盖掉输入序列中15%的Token(即用"[MASK]"替换掉原有的Token),然后在BERT的输出结果中取对应掩盖位置上的向量进行真实值预测。
- 缺点:由于在fine-tuning时,输入序列中并不存在”[MASK]“这样的Token,因此这将导致pre-training和fine-tuning之间存在不匹配的问题。
因此进行改进,即先选定15%的Token,
- 80%替换为"[MASK]"
- 10%随机替换为其它Token
- 10%不变
最后取这15%的Token对应的输出做分类来预测其真实值。
不同策略对比:

3 Next sentence predict,NSP,上下文预测模型
由于很多下游任务需要依赖于分析两句话之间的关系来进行建模,例如问题回答等。为了使得模型能够具备有这样的能力,又提出了二分类的下句预测任务。
每个样本来说都是由A和B两句话构成,其中50%的情况B确实为A的下一句话(标签为IsNext),另外的50%的情况是B为语料中其它的随机句子(标签为NotNext),然后模型来预测B是否为A的下一句话。
Bert四大下游任务Finetune
Bert可以在四个下游任务进行finetune,分别是句子对分类任务,单句分类任务,问答任务和序列标注任务。
其中,前两者属于句子级的分类任务,后两者属于句子内的分类任务(标注任务)

1 分类
对于句子级的分类任务,取最后一层transformer的CLS的输出,作为输入进入softmax层,即可预测label:
p
=
s
o
f
t
m
a
x
(
C
W
T
)
p=softmax(CW^T)
p=softmax(CWT)
2 序列标注
对于token级的分类,就是1序列标注任务,所有token的最有一层transformer输出,喂进softmax层,进行多分类。
总结
对于BERT来说,如果单从网络结构上来说的话,并没有太大的创新,这也正如作者所说”BERT整体上就是由多层的Transformer Encoder堆叠所形成“,并且所谓的”Bidirectional“其实指的也就是Transformer中的self-attention机制。
真正让BERT表现出色的应该是基于MLM和NSP这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。
1 优点
- 基于transformer的架构,相比较其他RNN,具备更长距离信息的捕获能力,而且是上下文的语义信息。
2 缺点
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
refer:
















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











